【优先级高,先补充】基于文本增强跨模态特征交互注意网络的多模态情感分析
一、核心重点概括
研究目标:针对视频中“内隐情绪”(隐含、甚至与真实情绪相反的表达)进行多模态情感分析。
问题背景:现有方法多分析外显情感,忽视文本等模态中隐含表达;多模态特征常被简单映射与粗糙融合,噪声大、鲁棒性差。
方案:提出跨模态特征交互注意网络(ISAFIA)。用“标签提示句+原文本”减弱文本隐含性;以文本为中心的多头交互注意学习声学/视觉特征;双交叉注意融合机制抑制噪声、提升特征有效性。
效果:在四个公共数据集上优于现有方法,并可解释各模态与标签的贡献。
二、作者指出的缺陷 / 现有不足
只聚焦外显情感,忽略内隐情绪。
文本模态虽关键,却常含反讽、反问、模糊表达,导致特征学习被误导。
跨模态信息处理简单(“简单映射”),缺乏深度交互,信息提取不足。
多模态融合引入大量噪声/冗余信息,降低模型鲁棒性与准确率。
单一模态或粗暴融合无法有效推理深层隐含情绪。
现有问题/缺陷 具体表现 对应解决方案(ISAFIA组件) 忽略内隐情感 模型将含负词的正情绪句判负、将反问式负情绪判中性 标签提示句融合文本:基于标注标签构建提示句,引导模型显化情感线索 文本隐含性误导特征学习 文本语义深、含蓄,视觉/声学难对齐 文本中心的多头交互注意:以文本为Query,学习与文本语义相关的声学/视觉特征,增强跨模态相关性 跨模态简单映射,信息提取不足 缺乏深层次互动与对齐 跨模态特征交互注意网络整体框架:在多层次上建模模态间依赖与互动 噪声与冗余信息影响鲁棒性 视觉/声学及其交互特征中噪声大 双交叉注意融合机制:文本/交互特征互为Q-K-V,交替注意,筛除噪声、保留语义最相关的情感特征 单一模态融合不足 仅靠某一模态或简单拼接无法推断隐情绪 多模态深度融合:综合文本、视觉、声学及其交互信息,提高推理能力
目前看来,最重要的创新点仅在文本上做文章
abstract:
情感分析是实现人机交互和个性化服务的基础。随着网络社交平台的快速发展,人们更倾向于通过视频(文字、声音和视觉)来表达自己的观点。为了分析视频中表达的情感倾向,多模态情感分析研究越来越受到研究者的关注。现有的多模态情感分析方法主要侧重于对显性情感的分析。然而,为了避免引发社会对信息的敏感,人们往往会在视频中含蓄地表达情感,尤其是在关键的情态文本中,这种表达具有丰富的语义和准确性。目前很少有研究考虑到内隐情绪的存在,但只对多模态信息进行简单的映射,导致信息提取不足,受噪声影响较大。为了解决这个问题,我们提出了一种基于跨模态特征交互注意网络的内隐情感分析方法,该方法利用标签、视觉和声学信息来帮助推断出内隐情感。具体而言,我们基于标注标签构建提示句,并将其与原文融合,以减轻文本情感的深层隐含性,增加原文中的情感线索。同时设计了基于文本的多头互动注意机制,学习与文本相关的听觉和视觉特征。考虑到噪声或冗余信息对模型鲁棒性的影响,设计了以文本为中心的双跨模态深度融合机制,以减弱视觉、听觉和跨模态交互带来的噪声,获得有效的多模态情感特征。我们在四个公共多模态数据集上进行了广泛的实验。结果表明,我们的方法优于现有的方法,可以解释标签、视觉和声学在多模态内隐情感分析中的贡献。
intro:
多模态情感分析旨在识别人们在包含两种或两种以上模态的数据源(如视频数据)中发表的评论的情感取向。它在智能客户服务、政治选举、企业改进、疾病预测等领域发挥着不可或缺的作用。目前,对多模态情感分析的研究成果较多,但大多侧重于传统的外显情感分析,而忽视了多模态内部存在的特殊性。目前关于多模态情感分析的研究基本上可以概括为三类:基于特征学习的方法[1-3]、基于特征融合的方法[4-8]和以文本为中心的分析方法[9-12]。
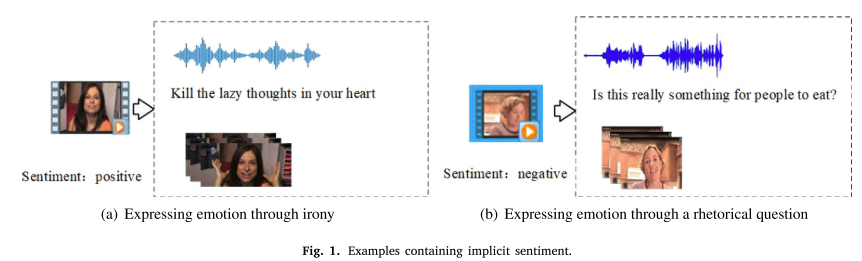
表1提供了各种研究工作的方法和局限性的描述。事实上,研究[11,12]表明,在视频片段中,文本情态是一个关键的情态,也是语义表达最准确的情态。然而,为了避免引发社会敏感,在语篇情态中总是存在含蓄的情感表达。内隐情绪表达是指缺乏明确的情绪信息或存在与真实情绪相反的情绪信息。这些事实误导了情感特征的学习,导致了不真实的特征表征,进而导致情感分析的准确率较低。例如,如图1(a)所示,由于文本中包含了“kill”、“lazy”等负面词汇,大多数多模态情感分析模型即使在视觉信息的辅助下,也总是将其分析为负面情绪。然而,事实上,这种情绪是积极的。在图1(b)的例子中,文本使用反问句形式来表达负面情绪,然而大多数多模态模型仍然错误地将其分析为中性,即使有声学的帮助。很少有研究[13,14],虽然考虑了内隐情绪的存在,但只对多模态信息进行了简单的映射,导致信息提取不足,受噪声影响较大。
综上所述,对于深层的含蓄情感表达,单纯地融合任何单一的情态特征都是不够的。只有通过降低情绪内隐性,融合各种形式的相关信息,才能有效地提高对内隐情绪的推理能力。为此,我们提出了一种基于跨模态特征交互注意网络(ISAFIA)的多模态内隐情感分析方法。
具体来说,我们设计了基于标签的提示,并将其融合到原始文本中,以减轻深层隐含性带来的误导。考虑到文本情态在特征学习过程中的重要指导作用,我们设计了一种基于文本的多头交互注意机制来学习与文本相关的听觉和视觉特征,并增强内隐文本与视觉/听觉特征之间的语义相关性。
此外,为了消除噪声对模型鲁棒性的影响,增强情感特征表征,我们设计了双交叉注意融合机制。该机制将文本/交互特性作为查询矩阵,将交互/文本特性作为键和值矩阵。通过在两个注意层之间交替,最大程度地减少了噪声信息,同时融合了与语义最相关的情感特征。
本文的主要贡献总结如下:
•提出了一种基于跨模态特征交互注意网络的多模态内隐情感分析模型。该模型充分利用标签来减轻文本的深度隐含性,确保对后续特征学习的正确指导。通过设计基于注意力的特征学习和融合机制来降低噪声,保证模型的鲁棒性。
•基于文本的多头互动注意机制,旨在学习与文本相关的视觉和听觉特征,加强内隐文本与视觉/听觉的相关性。设计双交叉注意融合机制,消除噪声对模型鲁棒性的影响,增强情感特征表征。
•在四个公共数据集上进行的大量实验表明,我们的模型可以有效地利用标签和多模态信息来提高模型的性能,优于其他基线模型
related work
早期的多模态情感分析研究主要集中在外显情感上。研究的核心问题是多模态特征的学习和融合方法[15]。例如,Chen et al.[16]设计了一种注意机制来学习不同模态之间的时空特征。为了捕捉更丰富的特征,Mai等人提出了一个用于三模态混合学习的HyCon框架,以探索模态之间的相互作用并减少模态差距。基于以上工作,Li et al.[18]设计了一个多级相关挖掘框架MCMF来提取模态之间的相关特征。同时,Fu等人提出了混合跨模态交互学习(Hybrid Cross-Modal Interaction Learning, HCIL)框架来学习模态之间的综合交互特征。随后,Zeng等人([20])引入了一种带有Slack重构的解纠缠翻译网络(Disentanglement Translation Network, DTN),深入探讨了模态之间的共性和多样性特征。这些方法旨在从单峰、双峰和三峰数据中提取特征;然而,他们平等地对待这三种模态,忽略了每种模态对情绪的差异贡献,这阻碍了他们获得情绪特征的有效表征。
为了增强多模态情感表达[21],多模态融合[22,23]是一种常用且重要的策略。例如,Zadeh等人引入了张量融合网络(TFN),它可以学习和融合模态内部和模态之间的信息。Liu et al.[24]提出了一种低秩多模态融合方法,以缓解TFN的维数指数增长和计算复杂度。为了增强多模态情感特征表征,Mai等人提出了一种局部限制模态融合网络(LMFN)来融合局部和全局信息。Wu等人设计了一种基于多头注意力的融合网络,融合了模态之间的交互特征,适当地减轻了LMFN中噪声的干扰。为了解决与LMFN类似的问题,Zhao等人引入了一个多模态异构融合网络来融合各种模态特征。为了优化多模态特征,Chaudhari等人提出了一种基于元启发式驱动网络(GCM-Net)的图增强跨模态注入方法,实现了更好的多模态特征表示。然而,这些方法主要侧重于三种模态之间关联特征的融合,而忽视了三种模态之间文本模态的重要性和复杂性。
Yang等人[27]发现,在多模态数据中,文本情态因其丰富而准确的语义而起主导作用。因此,研究者提出了一些以文本为中心的多模态特征学习和融合方法。例如,Chen等人b[28]提出了一种情感词感知融合网络(SWAFN),该网络利用外部情感词知识来辅助和指导三种模态的深度融合。为了避免外部无关词的干扰,Huang等人提出了以文本为中心的跨模态注意融合网络(TeFNA),进一步提高了融合特征的表征。然而,这些方法忽略了语篇情态中隐含的情感表达,这种深层隐含会误导特征的学习和融合。
当然,也有一些研究关注多模态中的内隐情感表达。如Zhang等人[13]利用面部表情特征和文本特征分析隐喻表达中的情感。这种方法主要针对特定的隐喻情感,具有相对单一的形象特征。后来,Chen等人提出了TTP (Text To Picture)方法,该方法结合了文本和视觉信息,利用情感极性的差异作为线索推断内隐情绪。由于声情态中还包含情感特征,研究者开始将声特征整合到文本中。例如,Alalem等人使用声学辅助文本来分析情感。这些方法表明,将视觉特征或声学特征整合到文本中有利于内隐情感分析。然而,在融合过程中,这些方法只进行了简单的模态映射,而没有考虑文本情感的深度隐含性和噪声信息对模型鲁棒性的影响。
上述方法从不同的维度解决了多模态情感分析中的一些问题。然而,这些方法忽略了模态内部的深层情感隐含性可能导致错误的分析结果,也没有全面考虑各种类型的噪声对模型鲁棒性的影响。这些限制影响了情感分析的准确性。因此,我们提出了一种ISAFIA方法来推理隐式情感,该方法有效地利用了标签[30]、视觉和声学信息来提高多模态情感分析的准确性。
文本特征表示:
1、用标签做提示模板(Prompt)
- 原始标签L属于「positive、negative...」
- 构造一句话模板Sp:如“the sentiment is L”
- 这样的到的新文本信息Sp可以显式带入情感极性,缓解文本模态隐式情感表达导致的学习困难
2、BERT编码与去噪
得到一个提示文本和一个原始文本
3、提示引导的注意力对齐
- 以Xp为Query,Xtd为Key/Value做注意力,接着与原文本特征相加得到最终文本特征Xt
1、声学用LibROSA提取、视觉用MTCNN做人脸检测,OpenFace2.0提取表情特征
2、BiLSTM编码上下文
3、线性+ReLU统一维度
统一之后得到的是X't
1、文本感知的声学/视觉特征学习,目的是让声学、视觉中特别与文本相关的部分被强调。这一步,以文本位Q,分别对视觉和声学做多头注意力。多头拼接后线性映射
1、文本中心的双阶段跨模态深度融合,由于单模态特征与交互特征有重叠且含噪,想突出有用信息并抑制噪声。采用“不对称、两阶段的cross- attention”。文本始终是目标中心
2、阶段一:
上一步得到的“文本->视觉/声学”注意力结果为
,以X't为Q,
3、阶段二:
以阶段一结果为Q,文本为K/V做深度融合(X't为K和V)
1、把两阶段得到的不同文本相关空间的特征拼接后线性变换。最后concat,得到最终的融合文本表示。
1、分类与损失
分类器是全连接和softmax
2、损失主要使用交叉熵

ISAFIA模型
本文提出了一种基于标签、声学和视觉信息的隐式情感推理模型ISAFIA。整体模型框架如图2所示。从图中可以看出,ISAFIA模型由四个部分组成:单模态特征表示(SMR)、文本感知视觉和声学特征学习(VAL)、内隐情感表示增强(ISE)和内隐情感分类。其中,SMR是对特定的模态进行建模,得到它们的特征表示。特别是对于文本情态,为了减轻其深层隐含性,我们设计了基于标签的提示,并利用注意机制将其整合到原始文本中,从而获得特征表示。VAL以文本作为查询获取文本感知的视觉和听觉信息。ISE通过双交叉注意融合来减弱噪声,增强文本语义表示。ISE的输出作为情绪预测层的输入。
单峰特征表示