大模型蒸馏理论概述
概述
模型蒸馏,即知识蒸馏,Knowledge Distillation,KD,连接着大型模型的强大能力与小型模型的高效便捷。知识蒸馏已从最初的模型压缩技术发展成为强大的知识转移方法。
在LLMs时代,知识蒸馏不再仅仅关注于表面的输出模仿,而是致力于转移教师模型的内部推理模式、对齐策略和领域特定见解。这种转变使得知识蒸馏成为一种强大的方法,能够显著提升小型模型的效率、准确性和领域适应性。
应用:
- 模型压缩:尽管知识蒸馏最初是作为模型压缩工具而提出的,但它在LLMs时代仍然发挥着重要作用。通过知识蒸馏,可将大型LLMs压缩为小型模型,从而降低推理成本和提高部署效率。
- 领域特定优化:允许学生模型专注于特定领域,而不是学习所有内容。这有助于提升学生模型在特定任务上的性能和准确性;
- 多教师蒸馏:让学生模型从多个教师模型中学习。可合并不同教师模型的推理风格,提高学生模型的泛化能力和鲁棒性;
- 自蒸馏和多级学习:自蒸馏,让模型通过生成解释或附加训练数据来精炼自己。多级蒸馏则涉及使用一系列模型(从大到小)进行逐级知识传递,以逐步优化学生模型。
优势
- 模型压缩效果显著:通过将教师模型的知识迁移到学生模型,可大幅减少模型参数量和计算复杂度,且保持较高性能;
- 提高模型泛化能力:教师模型的软标签包含丰富的类别区分信息,学生模型通过学习这些信息,能够更好地泛化到新的数据上;
- 灵活性高:可应用于各种类型的模型和任务。
局限
- 依赖教师模型:学生模型的性能在很大程度上依赖于教师模型的质量;
- 训练复杂性:蒸馏训练需要同时考虑教师模型和学生模型的训练过程,增加训练的复杂性和计算资源需求;
- 精度损失:但在某些复杂任务中,学生模型的精度可能会略低于教师模型;
- 模型选择困难:选择合适的教师和学生模型是一个挑战,不同的模型组合可能会导致不同的蒸馏效果。
挑战
- 伦理和法律约束:知识蒸馏可能引发知识产权和数据许可方面的法律问题。缺乏透明度使得验证蒸馏过程的合法性和伦理性变得困难;
- 性能权衡:虽然蒸馏模型在计算效率方面表现出色,但它们可能在某些方面牺牲性能,如复杂的推理能力和领域覆盖广度。找到效率和性能之间的最佳平衡仍然是一个开放的问题;
- 架构挑战:为了实现接近教师模型的性能,需要精心设计学生模型、匹配中间表示以及使用强大的数据增强技术;
- 能源效率和可持续性:虽然小型学生模型的推理成本较低,但频繁的重新蒸馏过程可能是资源密集型的。因此,在考虑知识蒸馏的可持续性时,需要权衡重复蒸馏事件与大规模推理节省之间的利弊。
未来发展方向
- 联邦知识蒸馏:随着隐私保护意识的增强,联邦知识蒸馏(Federated Knowledge Distillation, FedKD)将成为一种重要的方法,允许多个去中心化节点在不共享原始数据的情况下相互蒸馏知识。这将有助于在隐私敏感行业中实现知识共享;
- 多代理知识蒸馏:多代理知识蒸馏涉及多个学生和教师模型之间的迭代知识精炼。这种方法可以创建一个更健壮、共识驱动的知识库,并可能导致模型从多样化视角中学习到的涌现推理能力;
- 与参数高效微调的结合:参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术与知识蒸馏的结合有望进一步提高模型效率和域适应性。通过先对教师模型进行域特定微调,然后将这些知识蒸馏到学生模型中,可以实现高性能和轻量级模型的完美结合;
- 合规性蒸馏:通过蒸馏过程去除个人信息或确保遵守GDPR、HIPAA等法律框架,组织可以构建既合法又高效的AI模型。
原理
工作原理:核心在于让教师模型将其学到的知识以一种易于理解的方式传授给学生模型,涉及步骤:
- 教师模型训练:首先使用一个大型数据集训练一个高性能的教师模型;
- 软标签生成:教师模型对输入数据生成软标签(即概率分布),包含关于不同类别之间关系的丰富信息;
- 学生模型训练:使用这些软标签以及(可能)原始硬标签(即真实标签)来训练学生模型。学生模型的目标是尽可能地复制教师模型的输出(如软标签、中间特征等);
- 损失函数优化:通过最小化学生模型输出与教师模型输出之间的差异(通常使用交叉熵损失或其他定制的损失函数),来优化学生模型。
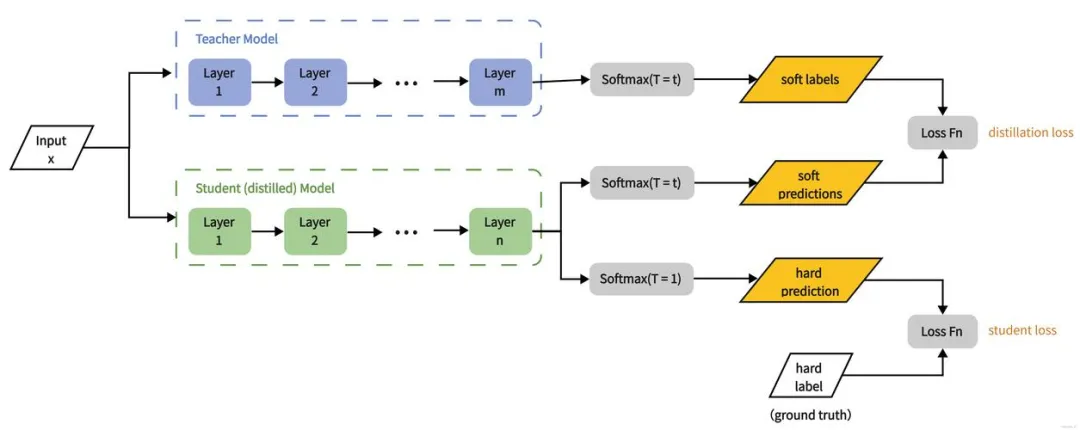
分类:
- 训练方案流程:离线蒸馏、在线蒸馏和自蒸馏;
- 算法更新:对抗蒸馏、多教师蒸馏。
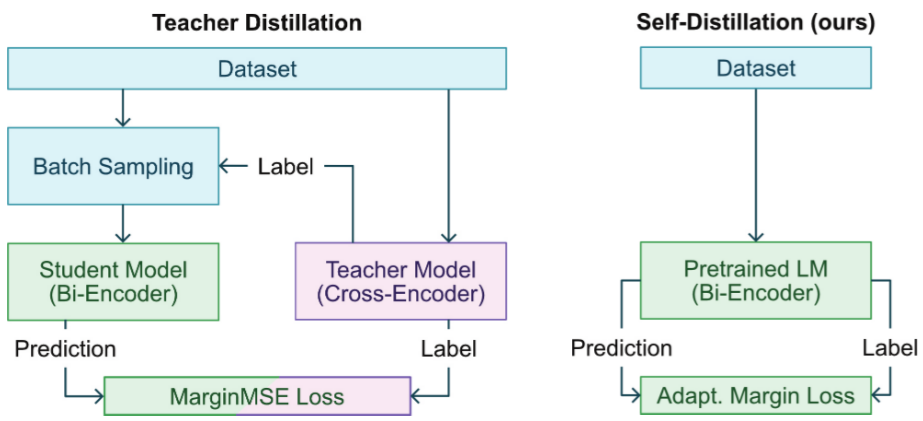
还可以根据是否将LLM的涌现能力(EA)提炼成小语言模型(SLM)来对这些方法进行分类:
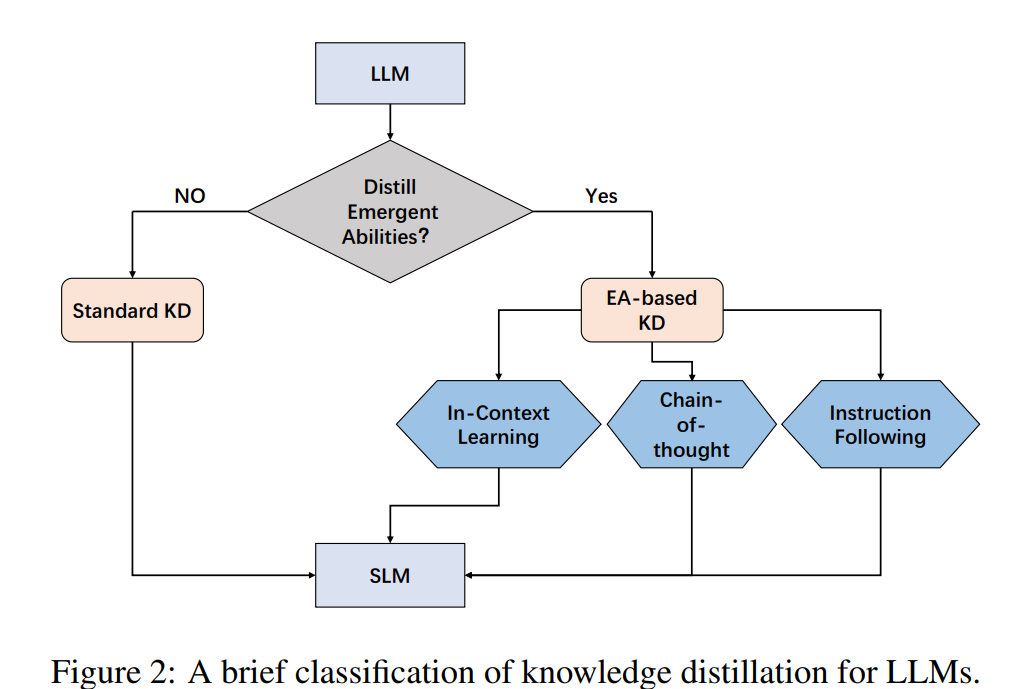
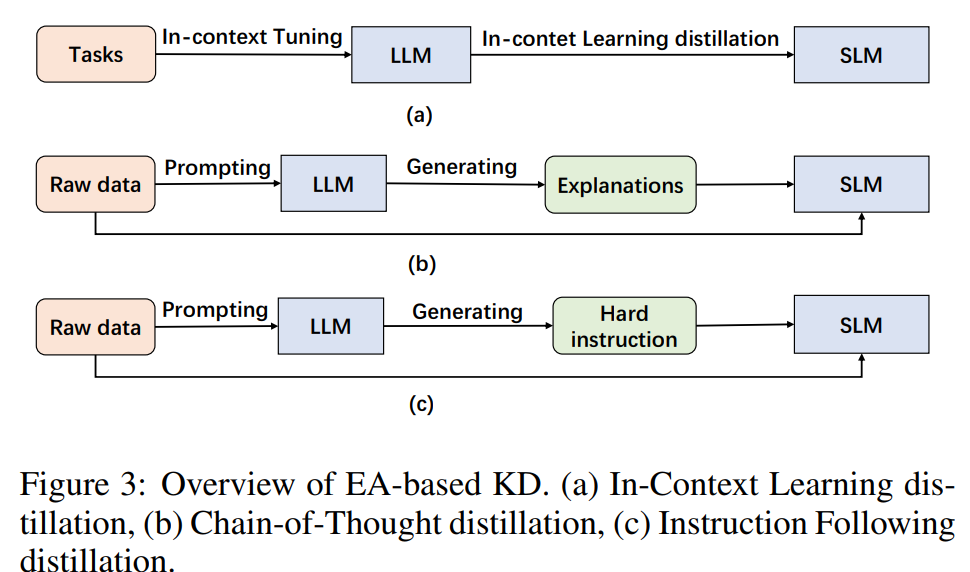
涌现能力包含三个方面:上下文学习 (ICL)、思维链 (CoT) 和指令遵循 (IF)。
模型蒸馏并不能直接避免过拟合,但它可以在一定程度上缓解过拟合问题。
DeepSeek-R1-Distill-Qwen-1.5B
以DeepSeek-R1-Distill-Qwen-1.5B为例,教师模型是DeepSeek-R1-70B,学生模型Qwen-1.5B。
如何构建蒸馏数据集?
选择一个与R1模型训练时相似或相关的数据集,应该包含足够的样本,以覆盖R1模型所擅长的各种任务和场景。
- 数学推理:meta-math/GSM8K_zh(中文数学题);
- 通用问答:m-a-p/COIG-CQIA(逻辑推理、生活场景);
- 代码生成:HuggingFace BigCode(编程问题与解决方案);
- 科学知识:Haijian/Advanced-Math(高阶数学证明)
数据集统一为结构化JSON格式,包含指令(instruction)和带推理链的响应(response),如:
{"instruction": "解方程√(5−√(5+x))=x","response": "<think> 首先平方两边得到5−√(5+x)=x²,再次平方整理得x⁴−2ax²−x+(a²−a)=0... <answer>解的和为1</answer>"
}
如何进行知识蒸馏?
在配备RTX 4090显卡(24GB显存)并使用支持4位量化训练的Unsloth工具环境下,将原始数据转为带推理链的JSON格式后,加载Qwen-1.5B学生模型、配置LoRA微调并启用DeepSeek-R1-70B教师模型输出引导,在低显存消耗下完成知识蒸馏。
使用unsloth库的FastLanguageModel,配置LoRA(仅训练0.1%参数)进行微调:
from unsloth import FastLanguageModel
# 4位量化加载模型(显存节省70%)
model, tokenizer = FastLanguageModel.from_pretrained(model_name = "Qwen/Qwen-1.5B",max_seq_length = 2048,load_in_4bit = True,
)
# 配置LoRA训练(仅训练0.1%参数)
model = FastLanguageModel.get_peft_model(model,r = 8, # LoRA秩target_modules = ["q_proj", "v_proj"], # 仅改注意力层
)
# 启动训练(RTX4090可运行)
model.train(training_data = "data.jsonl",epochs = 3,learning_rate = 2e-5,batch_size = 4,use_teacher_logits = True, # 启用教师模型输出引导teacher_model = "DeepSeek-R1-70B" # 指定教师模型
)
PyTorch
除了unsloth,PyTorch也可用于模型蒸馏,示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader# 定义教师模型
class TeacherModel(nn.Module):def __init__(self):super(TeacherModel, self).__init__()self.fc = nn.Sequential(nn.Linear(784, 512),nn.ReLU(),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 10))def forward(self, x):return self.fc(x)# 定义学生模型
class StudentModel(nn.Module):def __init__(self):super(StudentModel, self).__init__()self.fc = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 10))def forward(self, x):return self.fc(x)# 蒸馏损失函数
def distillation_loss(student_logits, teacher_logits, labels, T=2.0, alpha=0.5):soft_loss = nn.KLDivLoss()(nn.functional.log_softmax(student_logits/T, dim=1),nn.functional.softmax(teacher_logits/T, dim=1)) * (T * T)hard_loss = nn.CrossEntropyLoss()(student_logits, labels)return alpha * soft_loss + (1 - alpha) * hard_loss# 训练过程
teacher = TeacherModel()
teacher.load_state_dict(torch.load('teacher_model.pth')) # 预训练教师模型
student = StudentModel()optimizer = optim.Adam(student.parameters(), lr=0.001)
for epoch in range(10):for images, labels in train_loader:optimizer.zero_grad()teacher_logits = teacher(images.view(-1, 784)).detach()student_logits = student(images.view(-1, 784))loss = distillation_loss(student_logits, teacher_logits, labels)loss.backward()optimizer.step()
基本过程:
- 训练教师模型,并使用其logits作为软标签;
- 训练学生模型,并通过KL散度计算损失;
- 通过优化器使学生模型逐渐学习教师模型的特征。
数据增强
通过生成技能特定、领域丰富的训练数据,数据增强(Data Augmentation,DA)可显著增强知识蒸馏的有效性。数据增强不仅扩大数据集大小,更提高数据集质量,确保学生模型能够捕捉到教师模型的深层认知策略和领域专业知识。
在知识蒸馏过程中,数据增强和数据蒸馏是相辅相成的。数据增强提供更丰富的训练样本,而知识蒸馏则确保这些样本中的有用信息能够被有效地传递给学生模型。
TinyBERT
TinyBERT是一种轻量级的预训练蒸馏语言模型,由华为和华中科技大学提出。提出两阶段Transformer蒸馏方案:在大规模语料上首先进行通用MLM任务的蒸馏;在下游任务时,先学好老师模型,再进行蒸馏:
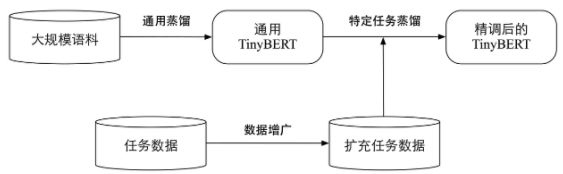
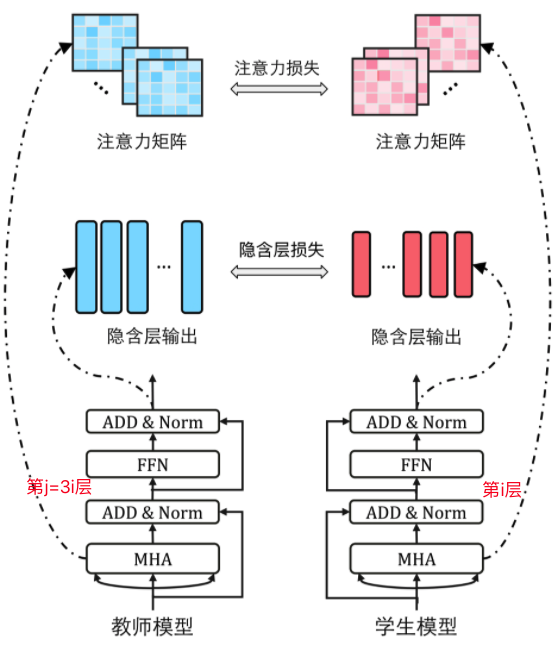
Transformer层蒸馏,主要包括注意力和隐藏层的蒸馏:
参考
- 大模型知识蒸馏指南
- 大模型知识蒸馏概述
- 蒸馏