单表查询-or优化
1、测例数据准备
create table t1 (id varchar2(20) primary key,c1 varchar2(20),c2 varchar2(20),ttime timestamp,c3 varchar2(4))
partition by list(c3)(
PARTITION P_1 values('1'),
PARTITION P_2 values('2'),
PARTITION P_3 values('3'),
PARTITION P_4 values('4'),
PARTITION P_5 values('5'),
PARTITION P_6 values('6'),
PARTITION P_7 values('7'),
PARTITION P_8 values('8'),
PARTITION P_9 values('9'),
PARTITION P_10 values('10'),
PARTITION P_11 values('11'),
PARTITION P_12 values('12'),
PARTITION P_13 values('13'),
PARTITION P_14 values('14'),
PARTITION P_15 values('15'),
PARTITION P_16 values('16'),
PARTITION P_17 values('17'),
PARTITION P_18 values('18'),
PARTITION P_19 values('19'),
PARTITION P_20 values('20'),
PARTITION P_DEFAULT values(default)
);
insert into t1 select 'A'||level,'B'||to_char(round(dbms_random.value(1,10000),0)),'C'||to_char(round(dbms_random.value(1,10000),0)),sysdate-round(dbms_random.value(1,900),0),to_char(round(dbms_random.value(1,20),0))
from dual connect by level<=500000;
commit;insert into t1 select 'A'||level+500000,'B'||to_char(round(dbms_random.value(1,10000),0)),'C'||to_char(round(dbms_random.value(1,10000),0)),null,to_char(round(dbms_random.value(1,20),0))
from dual connect by level<=1000;
commit;
CREATE OR REPLACE INDEX "SYSDBA"."IDX_DM_T1" ON "SYSDBA"."T1"("TTIME" DESC)global STORAGE(ON "MAIN", CLUSTERBTR) ;dbms_stats.gather_table_stats(USER,'T1',null,100);
2、 问题
SELECT * FROM(SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUM FROM (SELECT t1.* FROM ( SELECT * FROM T1 where (ttime<=to_date(?,'YYYY-MM-DD')orttime is null) ) t1 WHERE 1 = 1 ORDER BY T1.C2 DESC)INNER_TABLE ) OUTER_TABLE WHERE OUTER_TABLE_ROWNUM<=25AND OUTER_TABLE_ROWNUM >0
参数:2025-07-27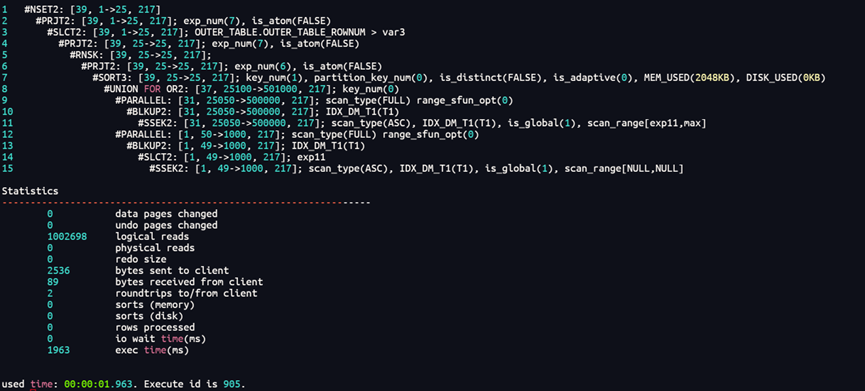
该语句or条件是同一列,但计划对表扫描两次,且可以看到使用索引后回表较大,这个计划的生成主要是受两个因素的影响
一是optimizer_or_nbexp参数,二是索引。
3、索引
什么时候使用索引优化,一般都是条件能够过滤出少量的数据用索引才会达到优化索引。这里因为条件是?,相当于未知的,优化器认为它使用索引会过滤出少量的数据更好。
那我们把索引不可见再看看计划
alter index IDX_DM_T1 invisible;
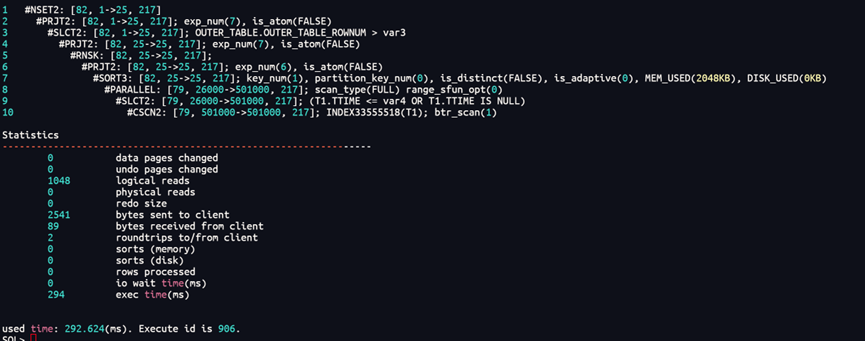
实际上它就做成全表扫描了。而且会比原来快很多。
4、 OPTIMIZER_OR_NBEXP
OR 表达式的优化方式。
0:不优化;
1:生成 UNION_FOR_OR 操作符时,优化为无 KEY 比较方式;
2:OR 表达式优先考虑整体处理方式;
4:相关子查询的 OR 表达也优先考虑整体处理方式;
8:OR 布尔表达式的范围合并优化;
16:同一列上同时存在常量范围过滤和 IS NULL 过滤时的优化,如 C1 > 5 OR C1 IS NULL。
这里可以看到16是对应优化该场景的。我们把索引可见后看看不优化和优化的效果
alter index IDX_DM_T1 visible;
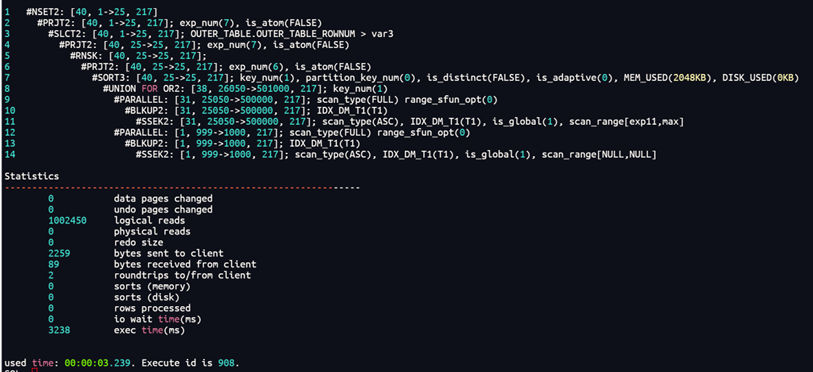
Optimizer_or_nbexp=0时
SELECT /*+OPTIMIZER_OR_NBEXP(0)*/* FROM(SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUM FROM (SELECT t1.* FROM ( SELECT * FROM T1 where (ttime<=to_date(?,'YYYY-MM-DD')orttime is null) ) t1 WHERE 1 = 1 ORDER BY T1.C2 DESC)INNER_TABLE ) OUTER_TABLE WHERE OUTER_TABLE_ROWNUM<=25AND OUTER_TABLE_ROWNUM >0
Optimizer_or_nbexp=16时
SELECT /*+OPTIMIZER_OR_NBEXP(16)*/* FROM(SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUM FROM (SELECT t1.* FROM ( SELECT * FROM T1 where (ttime<=to_date(?,'YYYY-MM-DD')orttime is null) ) t1 WHERE 1 = 1 ORDER BY T1.C2 DESC)INNER_TABLE ) OUTER_TABLE WHERE OUTER_TABLE_ROWNUM<=25AND OUTER_TABLE_ROWNUM >0
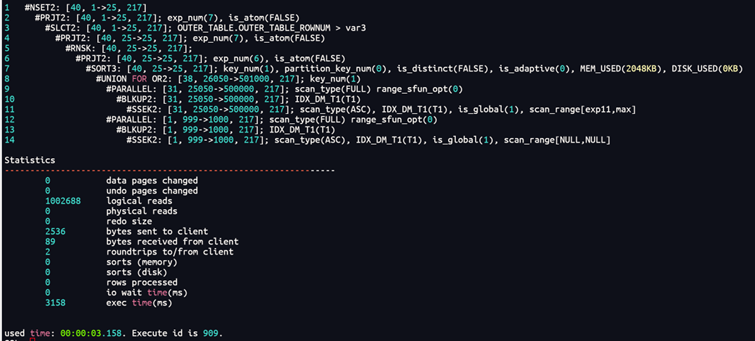
没啥区别,说明优化器认为索引的优化是最佳的
但我们从计划上可以看到计划的10行回表量是全表的数据,造成了性能问题。此时我们可能更希望它做成全表扫的方式会更好。那我们可以加上optimizer_or_nbexp=2,相当于18再试试
SELECT /*+OPTIMIZER_OR_NBEXP(18)*/* FROM(SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUM FROM (SELECT t1.* FROM ( SELECT * FROM T1 where (ttime<=to_date(?,'YYYY-MM-DD')orttime is null) ) t1 WHERE 1 = 1 ORDER BY T1.C2 DESC)INNER_TABLE ) OUTER_TABLE WHERE OUTER_TABLE_ROWNUM<=25AND OUTER_TABLE_ROWNUM >0
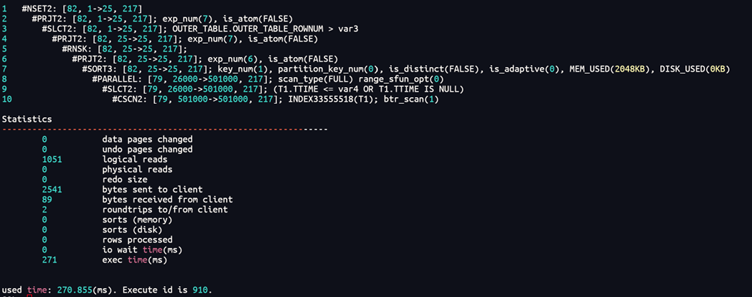
是不是效果很明显啊。这里的计划是把or合并整体做了。Or是一种逻辑运算。理解如下:
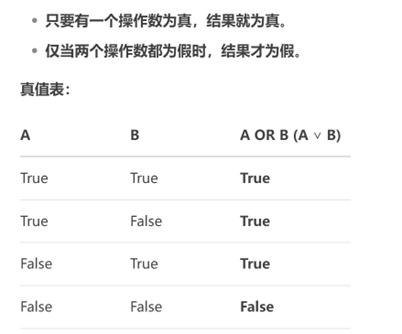
那语句其实求的是ttime<=?,或者is null的数据,相当于两个子集的数据都要取得,那如何合并呢?这里可能我们还需要理解null
5、 Null值
Nul值:代表某个变量、字段或数据点没有指向任何有效的对象或值,即"无值"或"缺失值"的状态。这不仅仅是数值上的0、布尔值上的false或字符串上的空字符串(“”),而是一种特殊的"空"状态。
那其实它可以是任何值,或者可以不是任何值,所以它不能比较(=,<,>),对于缺失值可以用nvl赋予实际值便于比较计算。因此呢我们如果把null转换成传入的值nvl(ttime,?)就可以用比较计算获取。
6、整体改写如下:
SELECT * FROM(SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUM FROM (SELECT t1.* FROM ( SELECT * FROM T1 where (nvl(ttime,?)<=to_date(?,'YYYY-MM-DD')) ) t1 WHERE 1 = 1 ORDER BY T1.C2 DESC)INNER_TABLE ) OUTER_TABLE WHERE OUTER_TABLE_ROWNUM<=25AND OUTER_TABLE_ROWNUM >0
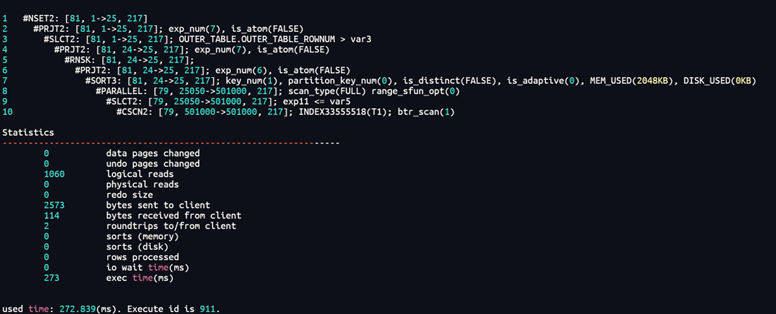
这样也能达到优化效果
7、小结
当我们遇到同一列or is null时,首先判断它是否可以过滤少量数据,可以的话就使用索引优化,另外optimizer_or_nbexp是or条件的优化参数。如果or条件是过滤大量的数据的话,可以考虑改写成nvl(列,参数)(</>/=……)参数方式,这样就不受索引和参数影响,能一下子达到我们想要的效果。