Datawhale 科大讯飞AI大赛(模型蒸馏)
文章目录
- 目标
- 实现过程
- 数据集构建
- 模型微调
- 参考任务
目标
使用教师模型蒸馏学生模型(小模型),使得学生模型尽可能在数学推理任务中表现更好,评分标准由4个指标组成:Overall Score=0.4×AS+0.3×CQS+0.2×ES+0.1×MLS
- AS(答案准确率):正确答案比例,映射至 0–100;
- CQS(CoT推理质量):推理链逻辑性与合理性;
- ES(解题效率):每条题目推理所用 token 数,token数量越小越好;
- MLS(模型轻量化):模型整体文件大小,模型文件越小越好。
实现过程
数据集构建
这里构建的数据集包含3个部分,分别是:
- 任务一中的微调数据集200条
- 任务二中的训练数据集
- 任务二中的测试数据集,使用教师模型进行批量推理(参考星火平台的批量推理功能),得到包含思考过程的输出,作为测试数据集
这里需要注意存在以下几个问题:
- 任务一中的微调数据集包含
<think></think>内容,考虑到模型中评分标准包含推理所用token数量,这里将think标签中的内容删除,减少token生成数量 - 各个数据集中,有存在output结果为空的情况,此时删除该条数据
- 微调数据时,需要符合包含instruction、input和output字段,这里将系统提示词放在instruction中,input为问题,output为结果
- 为了保证模型针对英文和中文有不同的提示词,这里分别设置了对应语言的系统提示词
english_prompt = "Please think through the following math problem step by step and generate the answer. The problem is as follows:"
chinese_prompt = "请你一步一步思考下面的数学问题并生成答案,问题如下:"def remove_think_tags(text):return re.sub(r'<think>.*?</think>', '', text, flags=re.DOTALL)if input_text.isascii():data["instruction"] = english_prompt
else:data["instruction"] = chinese_promptif len(data["output"]) == 0:continue
通过上述方法构建了3个对应的数据集,目前想要对最终的模型使用的数据集进行消融实验,训练及评分过程较慢。三个数据集合并后共包含2126条数据。
模型微调
使用星火平台上传数据集后,构建微调任务,对应的部分微调参数如下:
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 学习率 | 8e-5 | 训练次数 | 3 |
| LoRA秩 | 8 | Dropout | 0.1 |
| LoRA 缩放系数 | 16 |
微调中间过程的loss指标:
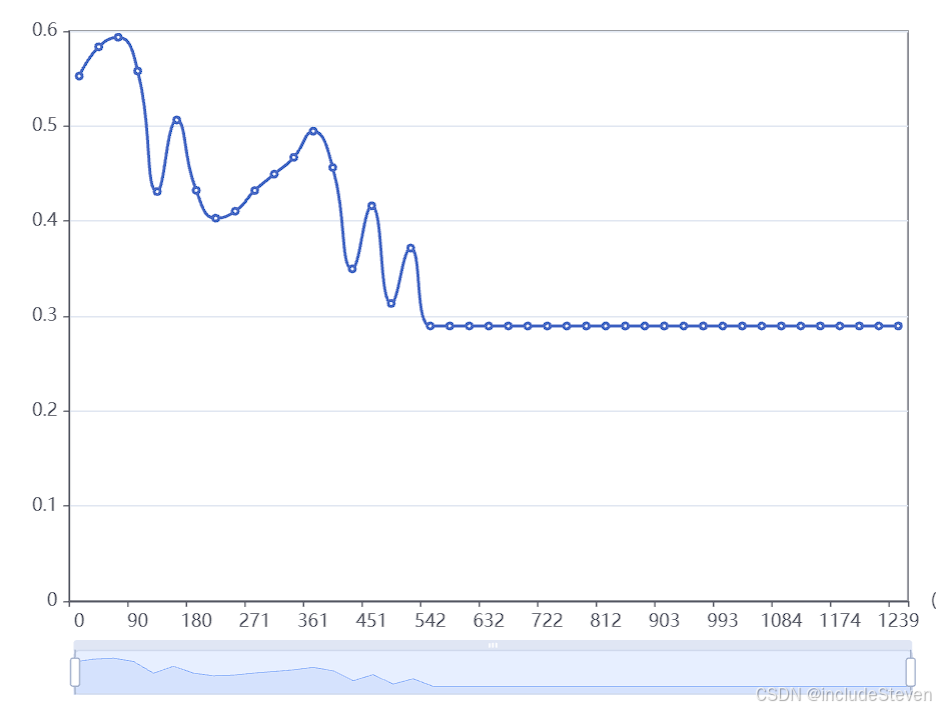
模型微调后,创建应用,发布服务即可提交赛题,目前赛题评分中,待更新最后分数。。。
参考任务
- Datawhale科大讯飞AI大赛(模型蒸馏)
- 讯飞星火平台
- 讯飞开放平台模型蒸馏比赛