模型评估的介绍
🌟 欢迎来到AI奇妙世界! 🌟
亲爱的开发者朋友们,大家好!👋
我是人工智能领域的探索者与分享者,很高兴在CSDN与你们相遇!🎉 在这里,我将持续输出AI前沿技术、实战案例、算法解析等内容,希望能和大家一起学习、交流、成长!💡
🔥 为什么关注AI?
人工智能正在重塑世界!🌍
🚀 深度学习让机器拥有“视觉”“听觉”
🤖 **大模型(如GPT、文心一言)**改变人机交互方式
📊 数据科学赋能商业决策
🏥 AI医疗助力精准诊断
🛒 智能推荐优化用户体验
无论你是AI新手👶,还是资深极客👨💻,这里都有适合你的内容!📌 你将在这里看到什么?
✅ AI基础入门(Python、TensorFlow/PyTorch)
✅ 实战项目(图像识别、NLP、推荐系统)
✅ 论文解读(CVPR、NeurIPS最新研究)
✅ 行业动态(AI政策、大模型进展)
✅ 避坑指南(训练技巧、调参经验)💬 期待与你互动!
📢 评论区随时交流,欢迎提问!
💌 私信开放,一起探讨技术难题!
🤝 关注我,AI学习路上不迷路!最后,送上一句AI圈的经典名言:
“人工智能不会取代人类,但会用AI的人会取代不用AI的人。”
让我们一起拥抱AI时代,用代码改变未来!🚀
点击关注👉,开启AI之旅! 🔥🔥🔥
目录
一.模型评估的方法
1.分类模型评估
2.回归模型评估
二.欠拟合、过拟合发生的情况
1.欠拟合(under-fitting)
2.过拟合(over-fitting)
小结
一.模型评估的方法
模型评估是模型开发过程不可或缺的一部分,它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。
按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
1.分类模型评估
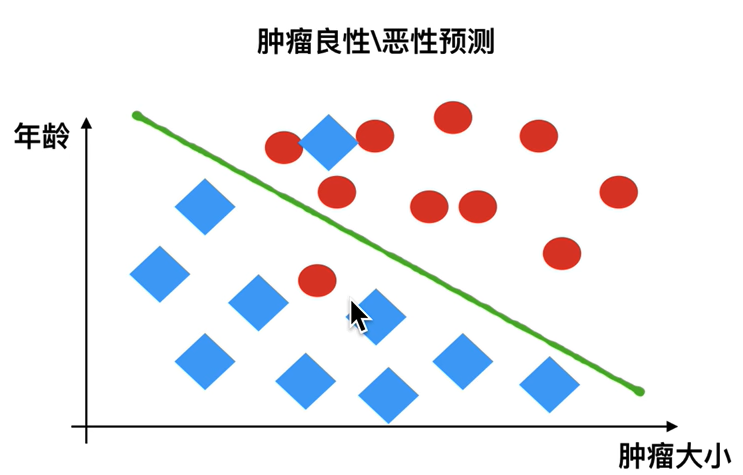
- 准确率:预测正确的数,占样本总数的比例。
- 其他评价指标:精确率、召回率、F1-score、AUC指标等。
2.回归模型评估
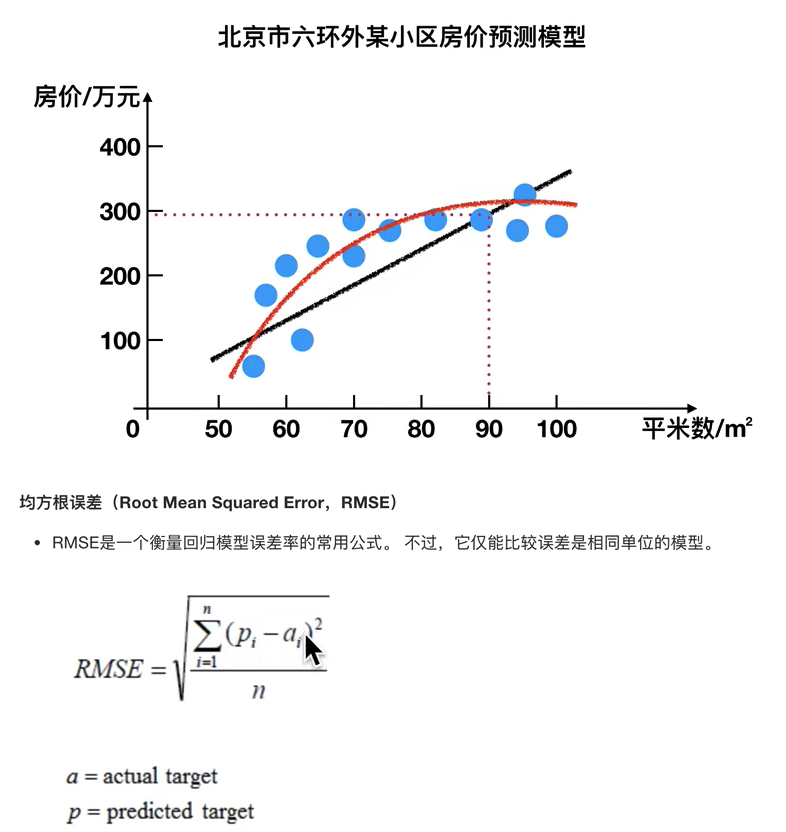
举例

二.欠拟合、过拟合发生的情况
模型评估,是用来评价训练好的模型的表现效果的。
其表现效果大致可以分成两类:过拟合、欠拟合。
在训练过程中,你可能会遇到这种问题:明明训练数据训练的很好,误差也不大,但却在测试集上面有问题。当算法在某个数据集当中出现了该情况,可能就出现了拟合问题。
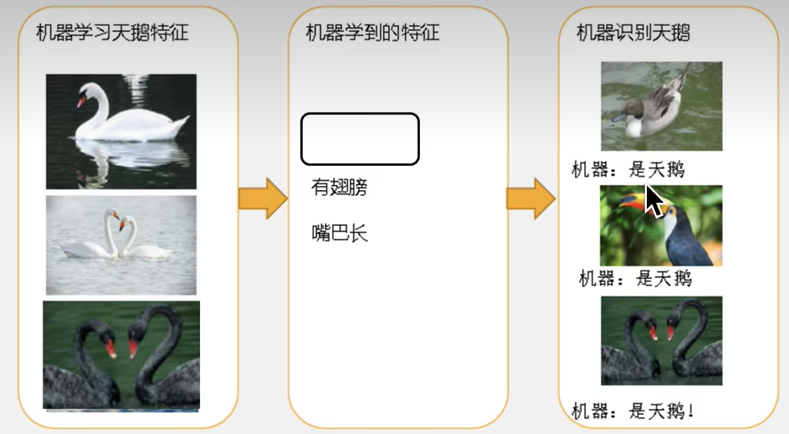
1.欠拟合(under-fitting)
因为机器学到的特征太少了,从而导致区分标准太粗糙,不能准确识别。
欠拟合(under-fitting):模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学明白。
举例:
2.过拟合(over-fitting)
机器已经能基本区别天鹅和其他动物了。然后很不巧,已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到的羽毛是黑的天鹅,就会认为那不是天鹅。
过拟合(over-fitting):所训练的模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。(说白了就是,模型不应该学习白羽毛这一特征,就能识别出来黑天鹅了)
- 欠拟合,就是训练好的模型学特征学少了;
- 过拟合,就是训练好的模型学特征学多了。
小结

举例:识别是不是人类
- 欠拟合:我们训练的模型,学到的特征是有四肢、有嘴巴,那么识别一只猫,也会认为猫是人,因为模型学到的特征太少了,因此应该再加上一条身高特征。
- 过拟合:我们训练的模型,学到的特征有一条是黄皮肤(这一个特征明显不应该学),那么在识别非洲同胞时,就会认为不是人类,这显然是不正确的。这就是因为模型学特征学多了,根本不应该学皮肤颜色这个特征。
以上就是欠拟合、过拟合的例子,应该还是很好理解的。
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~