GRPO强化学习缓解多模态大模型OCR任务的幻觉思路及数据生成思路
多模态大模型在“看不清”文字时瞎编答案,称为“OCR幻觉”,如下图,主要有几点:(1)预训练阶段缺乏相关数据:关键信息提取(KIE)数据以及退化视觉场景的清晰标注显著不足,限制了模型处理复杂视觉输入的能力。指令微调阶段忽视退化场景:现有研究通常假设 OCR 任务输入为非退化图像,导致模型缺乏处理真实世界退化文档(如模糊、遮挡、低对比度)所需的推理能力。
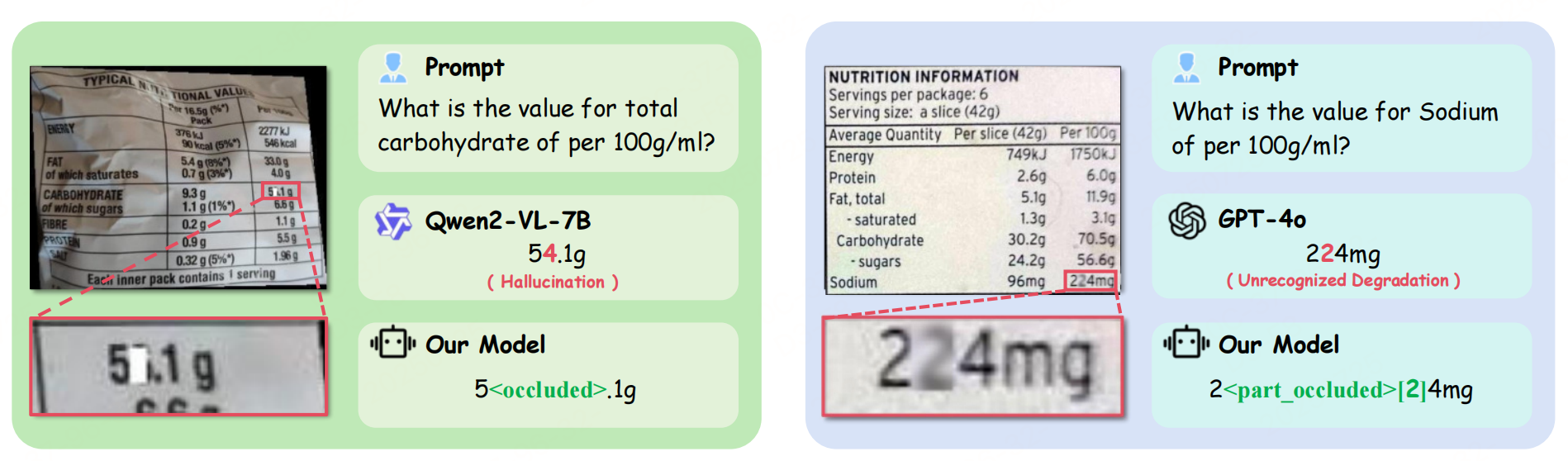
下面来看看一个思路。供参考。
数据集
![KIE-HVQA数据集中三类数据的可视化展示。[Q] 代表问题,[G] 表示真实值,[P] 则是由 Qwen2.5-VL 模型在 zero-shot 提示下生成的预测。这些数据呈现出不同程度的退化,如模糊或损坏,影响了模型的预测准确率。](https://i-blog.csdnimg.cn/img_convert/368fdd0bb6e8d510493543b4643193bc.jpeg)
数据生成方法
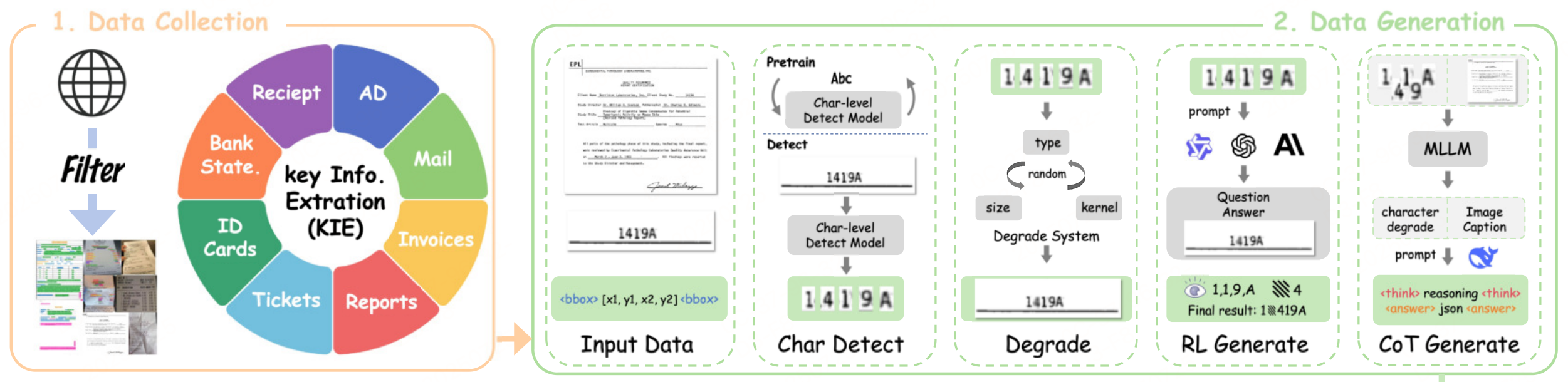
主要思路如下:
数据生成方法分三步走,目的是构造一个专门用于训练模型“看清模糊文字、不乱编答案”的冷启动数据集,核心逻辑是:用现有模型生成“人类式思考”的链式推理(CoT)数据,再与图像配对,形成多模态训练样本。流程如下:
Step 1:图像→文本描述(借助GPT-4o)
输入一张退化文档图像(如模糊的发票)+ 问题(如“这张发票的总金额是多少?”),用GPT-4o将图像内容转为纯文本描述(包括文字内容、退化情况、空间位置等)。 目的是把多模态信息“翻译”成语言模型能理解的文本。
- 例如:GPT-4o会描述“图像中‘总金额’一栏的数字‘100’被污渍遮挡,仅能看到‘1’和‘00’的轮廓”。
Step 2:文本→链式推理(借助DeepSeek-R1)
输入Step 1中生成的纯文本描述 + 问题,用推理模型DeepSeek-R1生成人类式的思考链(CoT),模拟人如何一步步判断,让模型学会“看不清时不硬猜”,而是用逻辑推理标记不确定部分。
- 示例CoT:
“观察到‘总金额’栏的数字有污渍遮挡,但‘1’的竖线清晰,‘00’的轮廓部分可见,结合上下文‘人民币符号¥’,推断金额为‘100元’,但需标记‘00’为不确定区域。”
Step 3:合成多模态数据
输入原始图像(带退化)和Step 2生成的CoT文本(含推理和不确定标记),输出一个完整的多模态训练样本(图像+问题+CoT答案)。
数据增强:
- 对图像随机添加退化(模糊、遮挡、低对比度)。
- 用OCR模型(如Qwen2.5-VL-72B)验证退化后的字符是否仍可见,确保标注准确。
最终效果生成的数据集覆盖身份证、发票、处方等场景。每个样本都附带:
- 像素级退化标注(哪些字符被遮挡)
- OCR可靠性得分(模型对字符可见性的置信度)
- CoT推理链(如何从不确定信息中得出结论)
方法
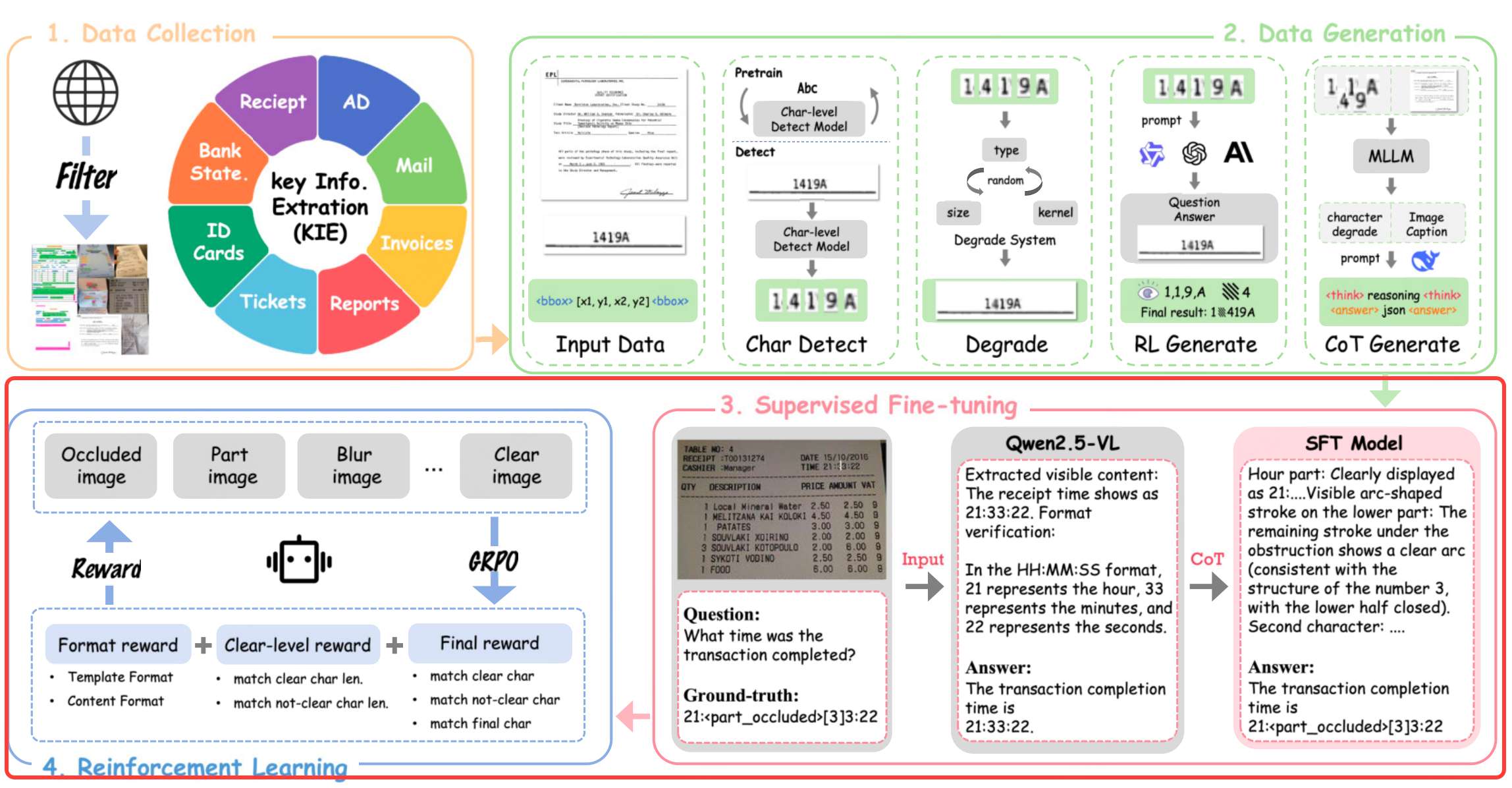
基于GRPO强化学习+多目标奖励函数的框架,解决OCR幻觉问题。
奖励函数设计
带OCR奖励的强化学习:设计基于规则的三级奖励函数,强制模型根据视觉可见性输出答案,避免幻觉。

奖励函数设计:
将字符按可见性分为三类,不同处理策略:
- 清晰字符(如“B, a, u”):必须准确识别,奖励高。
- 部分遮挡字符(如“e”被污渍盖住30%):需标记为异常(如“e[部分可见]”),保留但提示不确定。
- 完全不可见字符(如“t, i”被完全遮挡):必须输出空格,避免幻觉。

奖励计算流程:
对模型预测和真实值计算编辑距离,生成三个指标:
clear_metric:清晰字符的准确率not_clear_metric:模糊/遮挡字符的处理合理性final_metric:最终答案与真实值的匹配度
复合奖励:
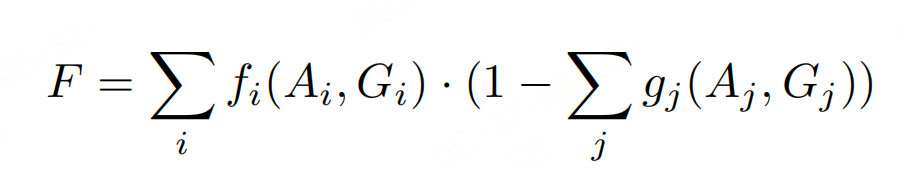
其中c₁, c₂, c₃为权重,确保模型优先视觉忠实度,而非盲目追求字符准确率。
训练阶段
冷启动SFT:用前文生成的CoT数据微调Qwen2.5-VL-7B,学习“退化场景下的推理范式”。
GRPO强化学习:
- 输入退化图像(如模糊处方),模型生成多个候选答案。
- 奖励函数评估每个答案是否**“不幻觉”**(如遮挡区域是否输出空格)。
- 通过GRPO优化策略,使模型逐渐学会**“无法识别时拒绝回答”**。
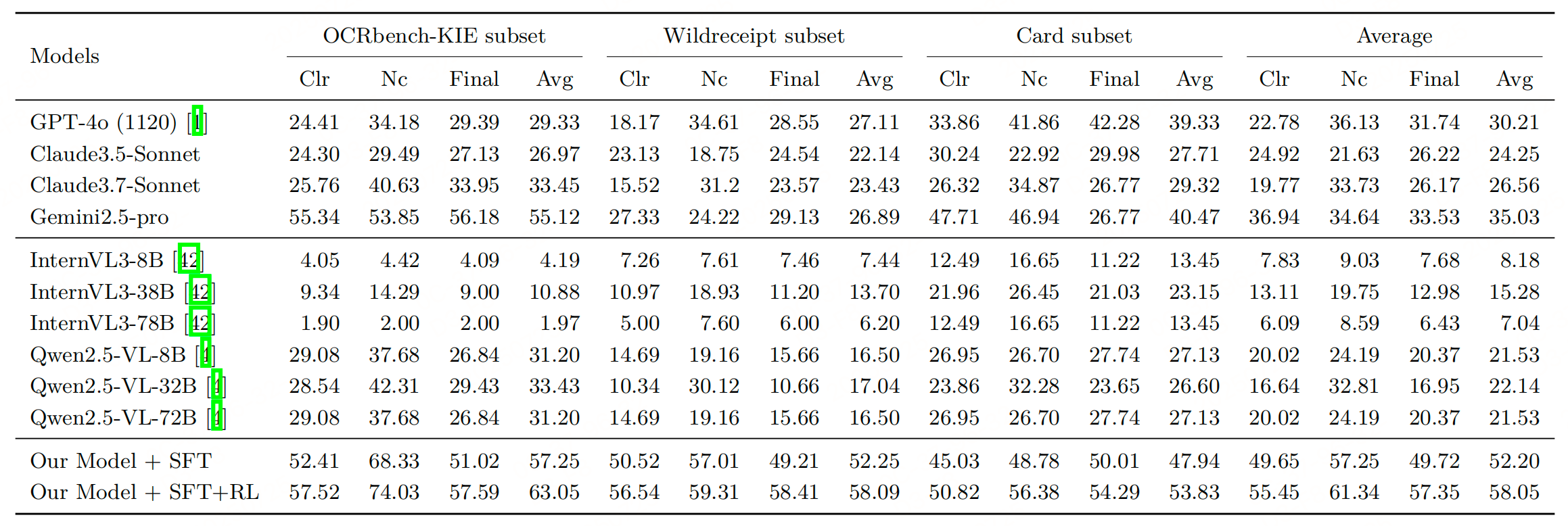
实验性能
参考文献:Seeing is Believing? Mitigating OCR Hallucinations in
Multimodal Large Language Models,https://arxiv.org/pdf/2506.20168v1