Qwen3安装使用教程:引领推理型大模型新时代
不久前,阿里云发布了 Qwen3,作为流行的 Qwen 系列最新型号,它在性能上超越了 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级思维大模型。
与传统语言模型输出平面文本不同,Qwen3 是一系列专为推理构建的思维型 LLM。它能在针对棘手问题的深思熟虑模式和针对日常任务的闪电般快速非思考模式之间灵活切换,且无需使用两种不同模型,一个模型即可胜任两项任务。其核心优势在于巧妙的 Mix-of-Experts 架构、覆盖 119 种语言的海量多语言支持,以及带有思维预算的思维开关(/think & /no_think),让用户能精准控制成本和延迟。
推理法学硕士的当前趋势
几年前,人工智能领域的头条都在追捧“第一个万亿参数模型”,似乎模型越大就越好。但到了 2025 年,风向变了,能否思考、给出更智能准确的回答成为衡量大模型的关键。
-
从规模到周到
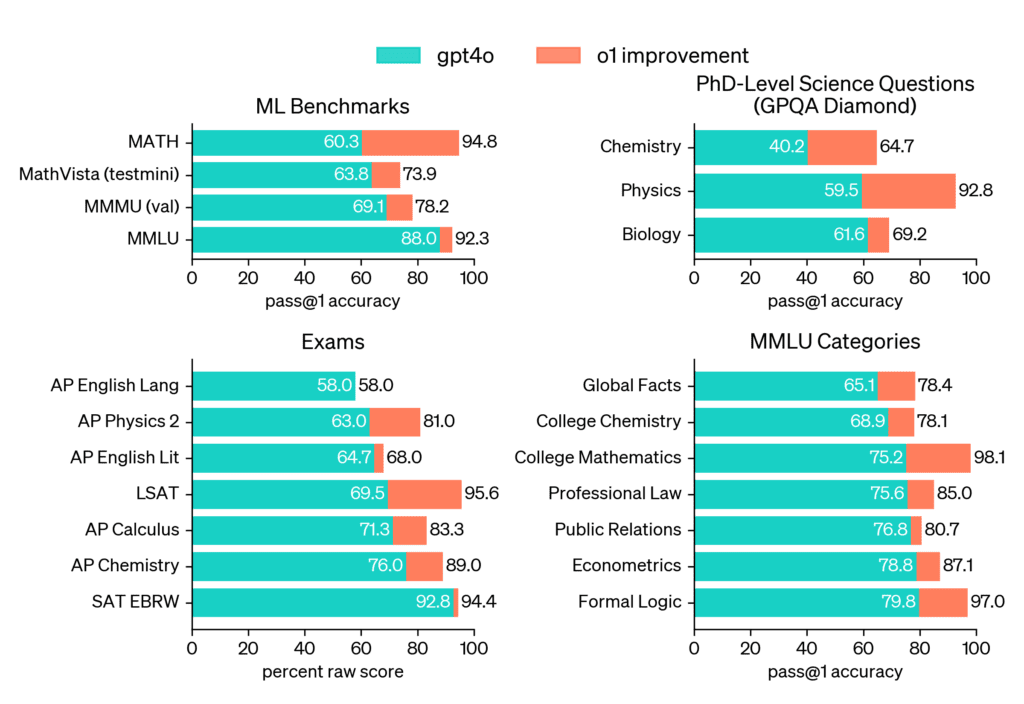
OpenAI 的 o 系列(o1、o3)开启了这一浪潮,证明当中型模型能够“大声思考”时,其表现可以击败 gpt4o。o1 在棘手的 GPQA-Diamond 基准测试中达到 78.0% 的成绩,在 2727 Codeforces Elo 排名中也表现出色,这表明:当问题变得复杂时,深思熟虑比模型规模更重要。
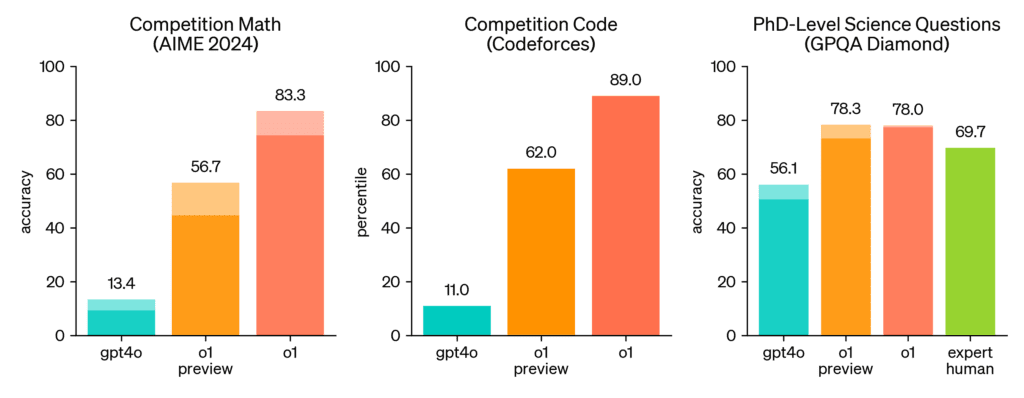
-
在需要时进行计算
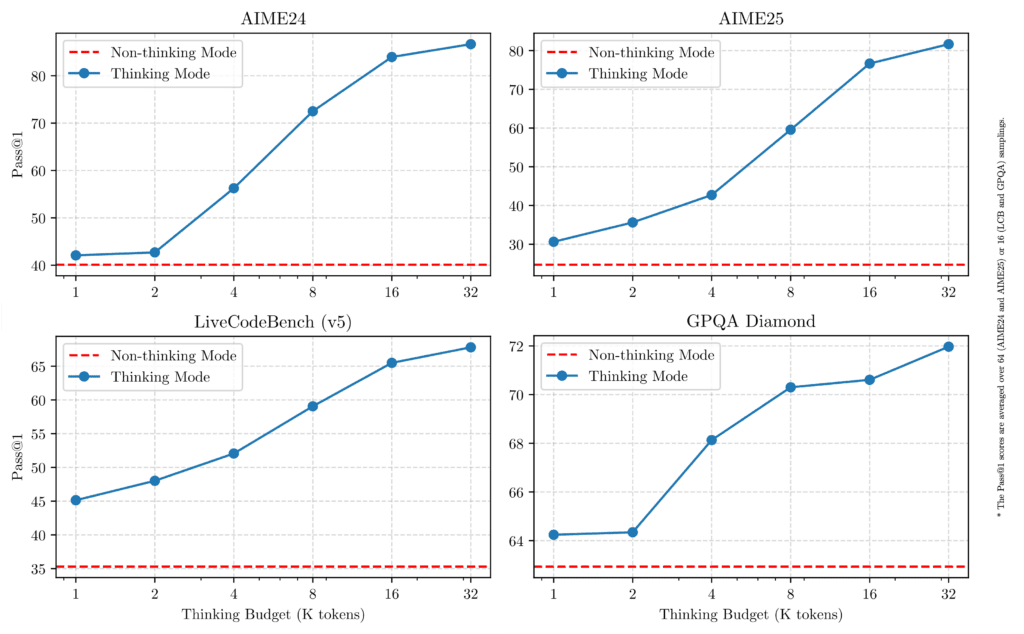
新式部署越来越多地采用推理时计算缩放。运行时不会在每个提示上消耗峰值 FLOP,仅当输入被归类为复杂时,才会分配额外的注意力头、搜索广度或专家路由。
o3 和 DeepSeek-R1 等模型适用于使用长 COT 上下文和内存的复杂推理任务;而 GPT4o 和 Gemini 则适用于快速通用 QA 任务,所需计算更少,推理更快。Qwen3 的精妙之处在于将这两种功能整合到一个模型中,通过其\think切换和可调整的思维预算,无需重新训练就能实现细粒度的成本与准确性权衡。
-
新标杆,新冠军
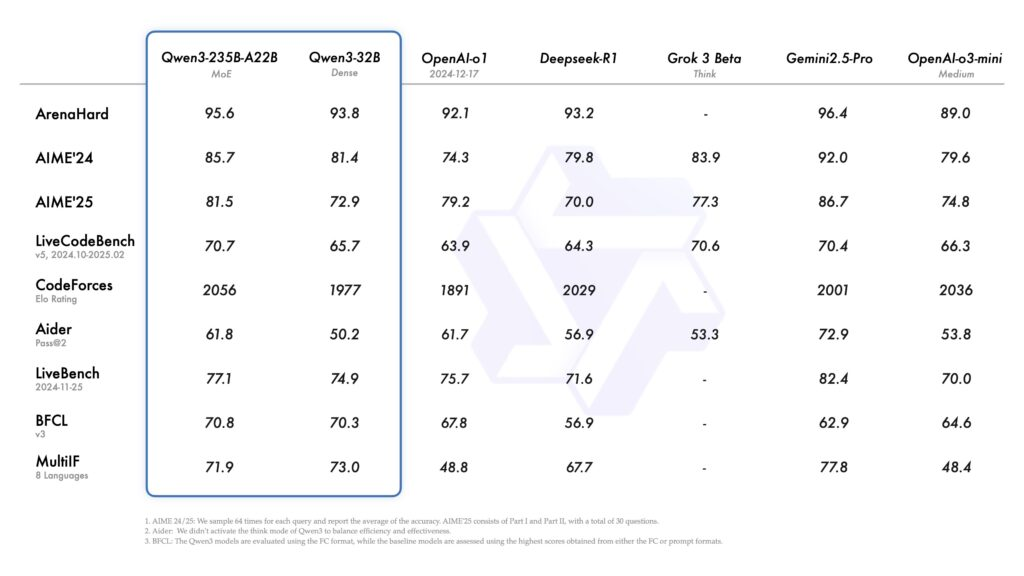
随着建模技术的进步,评估集也更加严格。LiveCodeBench 和 AIME’25 等数据集对形式证明、长上下文推演和跨学科推理进行了深入探讨。Qwen3-235B-A22B 目前在多个套件中领先,这表明专家混合(MoE)架构能提供最先进的逻辑能力,同时仅激活总参数的一小部分。
什么是法学硕士推理?法学硕士如何“思考”?
当人们说 Qwen3、DeepSeek-R1、OpenAI o 系列或 Claude Opus 等模型具有“推理能力”时,并非指它们启动了符号逻辑引擎。从本质上讲,其底层仍是相同的 Transformer 架构,即预测下一个标记的线性代数层。
变化的是,通过巧妙的训练和运行时技巧,引导预测过程的方式发生了改变,使模型能够推导出答案,而非背诵答案。
可以把法学硕士比作解决数学问题的学生:
- 常规模型试图直接跳到答案。
- 推理模型会先一步步演算,检查自己的思路,然后得出答案。这里的一步步演算就是我们所说的模型的 COT(思维链)。
| 两种“思维”发生在哪里 | 模型的作用 | 为什么有帮助 |
|---|---|---|
| 内部(隐藏) | 尝试一些想法,放弃坏想法,保留最好的 | 减少愚蠢错误 |
| 外部(显示给您) | 在特殊标签(如 `.< | FunctionCallBegin |
小例子
问题:“一列火车以 60 英里/小时的速度行驶 3 小时。那有多远?”
- 快速模式:180 miles
- 思维模式:
<|FunctionCallBegin|>
distance = speed × time
= 60 × 3 = 180
</think>
So the train travels 180 miles.
两者答案相同,但思维模式展示了计算过程。
模型如何学会思考?
- 监督思维链(CoT)微调:为模型提供数千个问题及完整的分步解决方案。
- 具有结构化奖励的强化学习(RL):通过编译代码、求解算术或检查 JSON 格式来评分,而非人工对每个答案评分。正确的逻辑获得更高回报,草率的逻辑会受到惩罚。
- 蒸馏或“强弱”转移:巨大的教师模型创建 CoT 答案,较小的学生模型模仿学习,在体型较小的情况下保留大部分推理能力。
- 自我游戏和反思:一些模型(如 OpenAI o 系列)会进行多次隐藏尝试,对最佳答案投票,或使用内部批评者发现矛盾。
通过这些信号,网络的权重会对“在给出距离之前将速度乘以时间”“在使用变量之前声明变量”等模式进行编码。
何时使用思维模式
打开它的好时机:
- 多步数学或逻辑谜题
- 需要仔细推理的大型代码更改
- 希望模型解释原因的课程
关闭它的时间:
- 速览(如“法国首都?”)
- 简短的摘要或翻译
- 简单的是/否或情绪检查
PS:当额外的清晰度值得花费额外时间时,使用思考模式。
Qwen3 代码管道 – Ollama
要在本地运行 Qwen3 模型,我们可以使用 Ollama。Ollama 是一款能让我们通过一行命令或代码在本地运行模型的工具。
安装 Ollama
在终端运行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
运行 Qwen3 模型
安装完成后,运行任何 Qwen3 模型只需执行:
ollama run qwen3:the_model_varient
Qwen3 能在思考和不思考模式间无缝切换,只需在输入提示后传递简单标志 \think 或 \no_think 即可切换模式。
通过 Python API 使用
首先安装 pip 包:
pip install ollama
然后使用以下简单 Python 脚本运行 Qwen 模型:
import ollamaresponse = ollama.chat(model="qwen3:8b",messages=[{"role": "user", "content": " Give me a short introduction of OpenCV. /no_think"}]
)
print(response["message"]["content"])
PS:Ollama 会启动一个兼容 OpenAI API 标准的后台 API 服务器(通常为 http://localhost:11434),方便进行编程交互。运行模型需要良好的硬件支持,至少 8GB 的 GPU(VRAM)来运行 8B 型号,更大的型号(如 32GB)则需要更高的内存。
中转API统一大模型API网关
如果打算经常使用 Qwen3,推荐使用 API,价格比官方便宜 80%。
中转官网:https://api.jisuai.top/
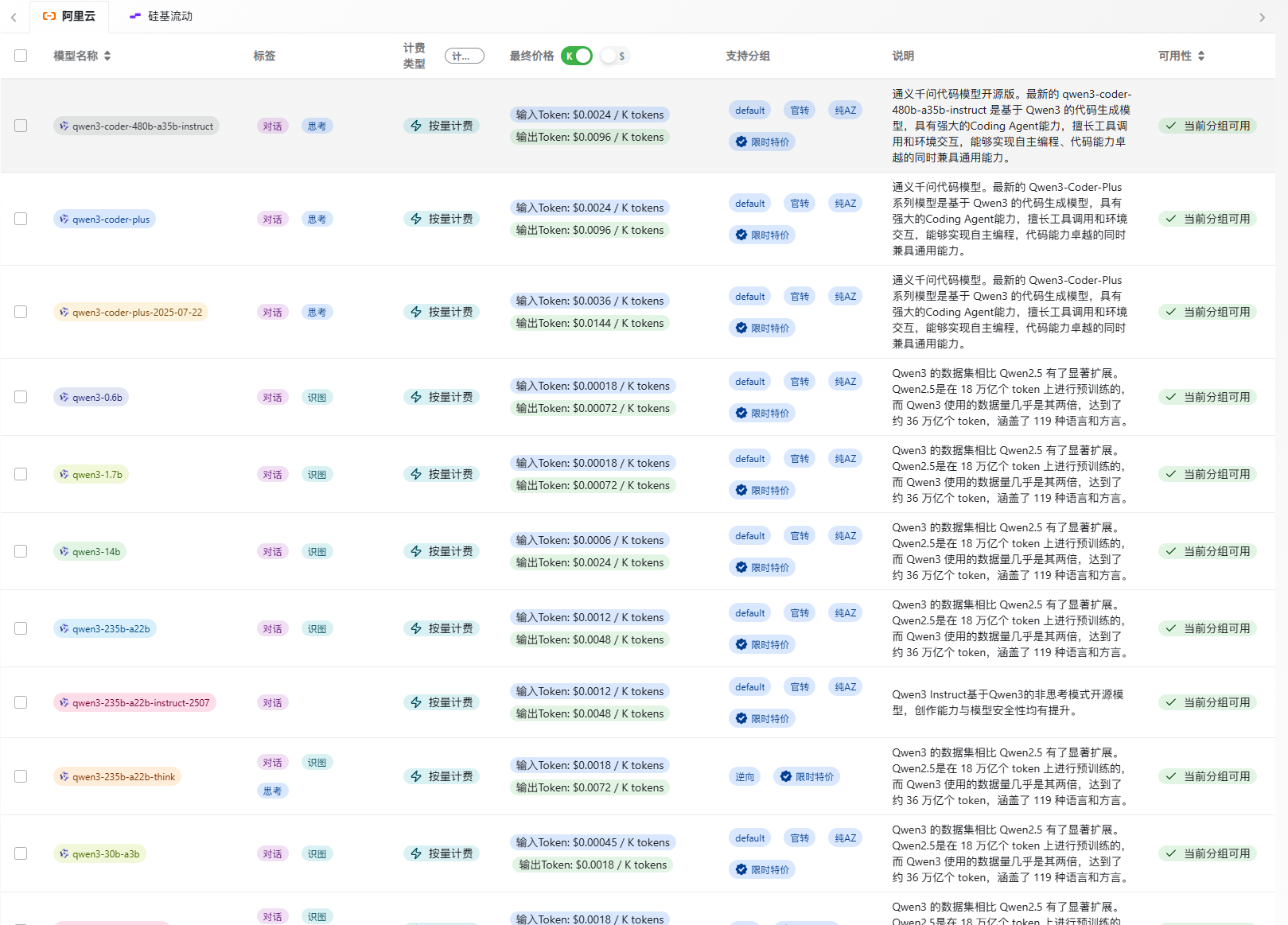
使用中转的优点是无需部署,可直接调用,且对于自用测试或企业调用,兼容性和稳定性更高,特价分组官方价格低至 1 折起。