分表分库与分区表
水平切分
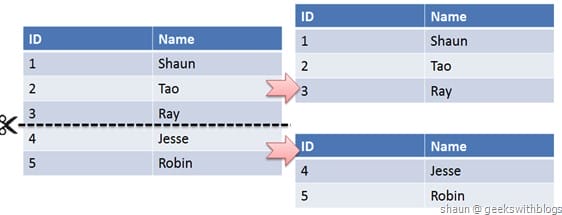
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
垂直切分
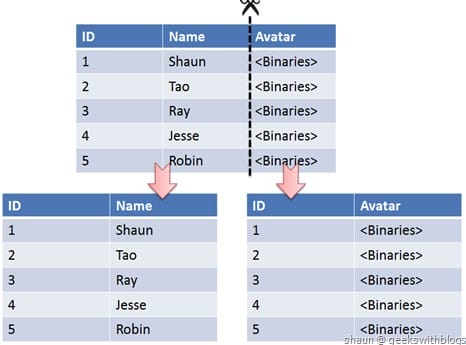
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
Sharding 策略
- 哈希取模: hash(key) % NUM_DB
- 范围: 可以是 ID 范围也可以是时间范围
- 映射表: 使用单独的一个数据库来存储映射关系
Sharding 存在的问题及解决方案
1. 事务问题
使用分布式事务来解决,比如 XA 接口。
2. 链接
可以将原来的 JOIN 分解成多个单表查询,然后在用户程序中进行 JOIN。
3. ID 唯一性
- 使用全局唯一 ID: GUID
- 为每个分片指定一个 ID 范围
- 分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
Sharding 的三种核心策略
1. 哈希取模(Hash Mod)
公式:hash(key) % NUM_DB
适用场景:数据分布均匀,无需范围查询。
优点:
- 数据均匀分布,避免热点问题。
- 实现简单,适合随机读写场景(如用户表)。
缺点:
- 扩容困难:增加分片数量(如从 2 库扩展到 3 库)时,需重新哈希并迁移数据。
- 无法支持范围查询:如
WHERE id BETWEEN 1000 AND 2000需跨多个分片查询。
优化方案:
- 一致性哈希:减少扩容时的数据迁移量(如 DynamoDB 的虚拟节点设计)。
2. 范围分片(Range-Based)
规则:按 ID 范围或时间范围分片(如 1~1000 在分片1,1001~2000 在分片2)。
适用场景:需要范围查询或按时间冷热分离(如订单表、日志表)。
优点:
- 天然支持范围查询(如
WHERE create_time > '2023-01-01')。 - 扩容时只需追加新分片(如按月份分片)。
缺点:
- 数据倾斜:热点数据可能集中在某个分片(如最新月份的数据)。
- 需预判数据增长:范围划分不合理会导致分片负载不均。
优化方案:
- 动态范围调整:根据数据增长动态调整分片边界(如 Elasticsearch 的索引滚动策略)。
3. 映射表(Lookup Table)
规则:使用独立数据库存储分片映射关系(如 user_id → shard_id)。
适用场景:分片规则复杂或需要灵活调整(如多租户系统)。
优点:
- 分片策略可动态变更(无需迁移数据)。
- 支持任意分片键(如非数值字段)。
缺点:
- 性能瓶颈:映射表可能成为单点,需缓存或分片。
- 额外维护成本:需保证映射表的高可用。
优化方案:
- 缓存映射关系:如 Redis 缓存
user_id → shard_id。 - 分片映射表本身:如对映射表按
tenant_id分片。
分片策略选型对比
策略 | 哈希取模 | 范围分片 | 映射表 |
均匀分布 | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️(易倾斜) | ⭐️⭐️⭐️⭐️(可控) |
扩容难度 | ❌ 需数据迁移 | ✅ 可动态追加 | ✅ 无需迁移 |
范围查询 | ❌ 不支持 | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️(需查表) |
适用场景 | 用户表、随机读写 | 订单表、日志表 | 多租户、灵活分片 |
Sharding 的三大核心问题及解决方案
1. 事务问题
问题描述
跨分片操作(如转账涉及分片 A 和 B)无法保证 ACID。
解决方案
- XA 事务(两阶段提交,2PC):
- 阶段一:协调者询问所有分片是否可提交。
- 阶段二:协调者通知所有分片提交或回滚。
- 缺点:性能差(同步阻塞)、协调者单点故障。
- TCC(Try-Confirm-Cancel):
- Try:预留资源(如冻结余额)。
- Confirm/Cancel:确认或取消操作。
- 优点:最终一致,无阻塞;缺点:需业务层实现补偿逻辑。
- Saga 模式:
- 将事务拆分为多个本地事务,失败时触发补偿事务。
- 适用场景:长事务(如电商订单流程)。
- 本地消息表:
- 事务提交后,通过消息队列异步通知其他分片。
2. 跨分片连接(JOIN)问题
问题描述
JOIN 涉及多个分片时性能极差(需网络传输合并数据)。
解决方案
- 应用层 JOIN:
- 查询分片 A 获取
user_ids。 - 用
IN查询分片 B:SELECT * FROM orders WHERE user_id IN (1, 2, 3)。
- 查询分片 A 获取
- 优化技巧:
- 使用临时表存储中间结果。
- 分页查询避免
IN列表过长。
- 冗余字段:
- 在分片 B 中冗余分片 A 的字段(如
orders表冗余user_name)。
- 在分片 B 中冗余分片 A 的字段(如
- 全局表:
- 将小表(如省份编码表)复制到所有分片。
3. 全局唯一 ID 问题
问题描述
分片环境下,自增 ID 会导致冲突。
解决方案
- UUID/GUID:
- 优点:全局唯一;缺点:无序,影响索引效率。
- 分片范围划分:
- 分片1:ID 范围
1~1000,分片2:1001~2000。 - 缺点:需预留空间,扩容不便。
- 分片1:ID 范围
- Snowflake 算法:
- 64 位 ID = 时间戳 + 机器 ID + 序列号。
- 优点:趋势递增,高性能;缺点:依赖时钟回拨处理。
- 数据库号段:
- 从数据库批量获取 ID 段(如每次分配 1000 个 ID)。
- 适用场景:中小规模系统(如美团 Leaf)。
实践建议
- 优先考虑哈希取模:若无需范围查询且数据量均匀。
- 慎用范围分片:需监控热点问题,配合冷热分离。
- 分布式 ID 选型:
- 高性能场景 → Snowflake。
- 简单可控 → 数据库号段。
- 事务妥协:
- 强一致 → XA(牺牲性能)。
- 最终一致 → TCC/Saga(牺牲复杂度)。
总结:分片是“空间换时间”的权衡,需根据业务特点选择策略,并接受分布式带来的复杂度。
分区表(Partitioning)与分库分表(Sharding)的区别
分区表和分库分表都是数据分片的技术,但它们的实现层级、适用场景和解决的问题有本质差异。以下是详细对比:
1. 分区表(Partitioning)
定义
- 数据库内置功能:在同一个数据库实例内,将一张表的数据按规则(如范围、哈希、列表)分配到不同的物理文件(分区)中,但对应用透明,仍像操作单表一样查询。
- 代表实现:MySQL 的
PARTITION BY、PostgreSQL 的TABLE PARTITION。
核心特点
维度 | 说明 |
存储位置 | 同一数据库实例的不同文件(如 |
跨节点能力 | 不支持,所有分区在同一台服务器。 |
SQL 兼容性 | 应用无感知,仍用单表 SQL 操作(如 |
性能优化 | 减少全表扫描(查询只扫描特定分区),提高删除旧数据的效率(直接删除分区)。 |
适用场景
- 单机大数据表:如日志表按时间分区,快速删除过期数据。
- 减少索引体积:分区后每个分区的索引更小,查询更快。
- 本地化查询:如按地区分区,查询时只扫描特定区域数据。
示例(MySQL 分区)
-- 按时间范围分区
CREATE TABLE logs (id INT,log_time DATETIME,content TEXT
) PARTITION BY RANGE (YEAR(log_time)) (PARTITION p2022 VALUES LESS THAN (2023),PARTITION p2023 VALUES LESS THAN (2024)
);-- 查询时自动定位到 p2023 分区
SELECT * FROM logs WHERE log_time > '2023-01-01';2. 分库分表(Sharding)
定义
- 跨数据库/实例:将数据分散到多个物理数据库或服务器,通常需应用层或中间件(如 MyCat、ShardingSphere)支持路由。
- 核心目标:解决单机存储和性能瓶颈(如高并发、海量数据)。
核心特点
维度 | 说明 |
存储位置 | 不同数据库实例或物理服务器(如 |
跨节点能力 | 支持,数据分布在多台机器。 |
SQL 兼容性 | 需改写 SQL 或通过中间件路由(如 |
性能优化 | 分布式存储和计算,提高吞吐量(如分库抗并发,分表减单表数据量)。 |
适用场景
- 高并发读写:如用户表按
user_id分库,分散压力。 - 海量数据存储:如订单表按月分表,避免单表过大。
- 水平扩展:通过增加服务器提升整体容量和性能。
示例(分库分表)
-- 分库分表规则(通过中间件配置)
-- user_id % 2 = 0 → db0.users_0
-- user_id % 2 = 1 → db1.users_1-- 应用查询(中间件自动路由)
SELECT * FROM users WHERE user_id = 123; -- 可能被路由到 db1.users_13. 核心区别总结
对比项 | 分区表(Partitioning) | 分库分表(Sharding) |
数据位置 | 同一实例的不同文件 | 不同数据库实例或服务器 |
扩展性 | 单机垂直扩展(硬件上限) | 水平扩展(无限加机器) |
应用改动 | 无需改动 SQL | 需适配中间件或改写 SQL |
事务支持 | 支持单机事务(ACID) | 跨库事务需分布式方案(如 TCC、XA) |
典型场景 | 日志清理、单机大表优化 | 高并发、海量数据、微服务分库 |
代表技术 | MySQL Partition、PG Partition | MyCat、ShardingSphere、Vitess |
4. 常见误区澄清
误区 1:分区表是分库分表的替代方案?
- 错误:分区表无法替代分库分表,它仅优化单机性能,无法解决分布式问题(如高并发、容灾)。
- 正确关系:
- 单机大数据 → 先尝试分区表。
- 单机性能不足 → 必须分库分表。
误区 2:分区表能提高并发?
- 部分正确:分区表可减少锁竞争(如不同分区可并行写入),但所有分区仍共享同一数据库连接池和 CPU/IO 资源,无法像分库那样通过加机器提升并发。
误区 3:分库分表一定比分区表好?
- 错误:分库分表引入分布式复杂度(如跨库 JOIN、事务),单机够用时优先分区表。
5. 如何选择?
选分区表如果:
- 数据量大但单机资源(CPU/内存/磁盘)足够。
- 需快速删除旧数据(如按时间分区直接
DROP PARTITION)。 - 应用不想改动代码。
选分库分表如果:
- 单机存储或并发达到瓶颈。
- 需要容灾和高可用(多副本分布)。
- 业务已微服务化,需按服务切分数据库。
6. 组合使用案例
日志系统优化:
- 分库分表:按日志类型分库(如
app_logs、security_logs)。 - 分区表:每个库内按时间分区(如按月分区,定期清理)。
效果:
- 分库解决并发和存储问题。
- 分区表加速单库内的查询和清理。
总结
- 分区表是单机数据库的“内部分片”,对应用透明,适合单机优化。
- 分库分表是跨数据库的“分布式分片”,需应用适配,解决扩展性问题。
- 二者可互补:先分区表优化单机,不够时再分库分表。