银行营销数据预测分析:从数据到精准营销决策
项目背景
本项目基于葡萄牙银行机构的直接营销活动数据,通过电话联系客户推广定期存款产品。目标是分析客户特征与订阅行为的关系,并构建预测模型识别高潜力客户。
数据集摘要
该数据与葡萄牙银行机构的直接营销活动(电话呼叫)相关。分类目标是预测客户是否会订阅定期存款(变量y)。Kaggle数据集
数据集信息
该数据涉及葡萄牙银行机构的直接营销活动。营销活动基于电话呼叫进行。通常,为了确定客户是否会订阅银行定期存款产品(‘是’或’否’),需要与同一客户进行多次联系。
属性信息
银行客户数据
- 年龄(age):数值型
- 职业(job):分类型,包括:‘admin.’(行政人员)、‘blue-collar’(蓝领)、‘entrepreneur’(企业家)、‘housemaid’(家政服务)、‘management’(管理层)、‘retired’(退休人员)、‘self-employed’(自雇者)、‘services’(服务业)、‘student’(学生)、‘technician’(技术人员)、‘unemployed’(失业者)、‘unknown’(未知)
- 婚姻状况(marital):分类型,包括:‘divorced’(离婚/丧偶)、‘married’(已婚)、‘single’(单身)、‘unknown’(未知)
- 教育程度(education):分类型,包括:‘basic.4y’(4年基础教育)、‘basic.6y’(6年基础教育)、‘basic.9y’(9年基础教育)、‘high.school’(高中)、‘illiterate’(文盲)、‘professional.course’(职业课程)、‘university.degree’(大学学位)、‘unknown’(未知)
- 信用违约(default):分类型,包括:‘no’(无违约)、‘yes’(有违约)、‘unknown’(未知)
- 住房贷款(housing):分类型,包括:‘no’(无)、‘yes’(有)、‘unknown’(未知)
- 个人贷款(loan):分类型,包括:‘no’(无)、‘yes’(有)、‘unknown’(未知)
与当前营销活动最后一次联系相关的数据
- 联系方式(contact):分类型,包括:‘cellular’(手机)、‘telephone’(电话)
- 月份(month):分类型,包括一年中的各个月份:‘jan’(一月)至’dec’(十二月)
- 星期几(day_of_week):分类型,包括:‘mon’(周一)、‘tue’(周二)、‘wed’(周三)、‘thu’(周四)、‘fri’(周五)
- 通话时长(duration):数值型,以秒为单位。重要说明:此属性高度影响输出目标(例如,如果duration=0,则y=‘no’)。然而,通话时长在拨打前是未知的,且通话结束后y值显然已确定。因此,该输入仅用于基准测试,若要构建实际预测模型应排除此特征。
其他属性
- 本次活动联系次数(campaign):数值型,包括本次活动中对该客户的联系次数(含最后一次)
- 上次联系间隔天数(pdays):数值型,上次活动联系客户后至本次活动的天数(999表示之前未联系过)
- 之前联系次数(previous):数值型,本次活动前对该客户的联系次数
- 之前活动结果(poutcome):分类型,包括:‘failure’(失败)、‘nonexistent’(无记录)、‘success’(成功)
社会经济环境属性
- 就业变化率(emp.var.rate):数值型,季度指标
- 消费者价格指数(cons.price.idx):数值型,月度指标
- 消费者信心指数(cons.conf.idx):数值型,月度指标
- 欧元银行同业拆借利率3个月(euribor3m):数值型,每日指标
- 就业人数(nr.employed):数值型,季度指标
输出变量(目标变量)
- y:客户是否订阅定期存款(二元:‘yes’(是)、‘no’(否))
数据概览
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
首先导入数据分析所需的基础库,包括数据处理库pandas、数值计算库numpy、可视化库matplotlib和seaborn,以及机器学习相关模块。这些库提供了从数据加载、处理、可视化到模型构建和评估的完整工具链。
# 设置中文显示
plt.rcParams['font.family'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
接下来设置中文显示参数,通过plt.rcParams配置字体,确保图表中的中文能正常显示。同时设置axes.unicode_minus为False,解决负号显示为方块的问题。
# 加载数据(注意分隔符为分号)
df = pd.read_csv('bank-additional-full.csv', sep=';')
然后加载数据,由于该数据集使用分号分隔而非默认的逗号,所以在pd.read_csv中指定sep=';'参数以正确解析数据。
# 查看数据基本信息
print('数据集形状:', df.shape)
print('\n数据前5行:\n', df.head())
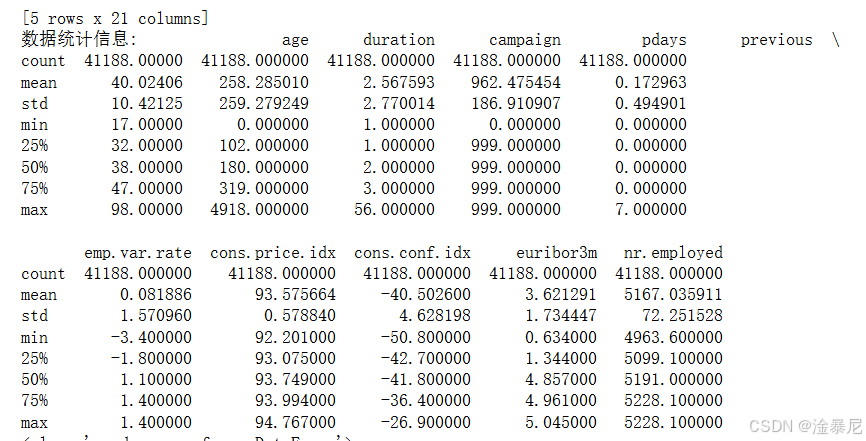
print('\n数据统计信息:\n', df.describe())
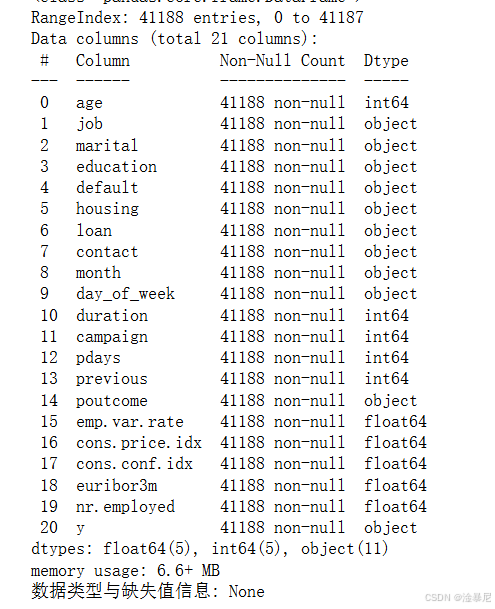
print('\n数据类型与缺失值信息:\n', df.info())
最后通过多种方法查看数据集基本信息:shape属性查看数据规模,head()方法显示前5行样本,describe()提供数值特征的统计摘要,info()则展示各列的数据类型和缺失值情况,为后续分析奠定基础。
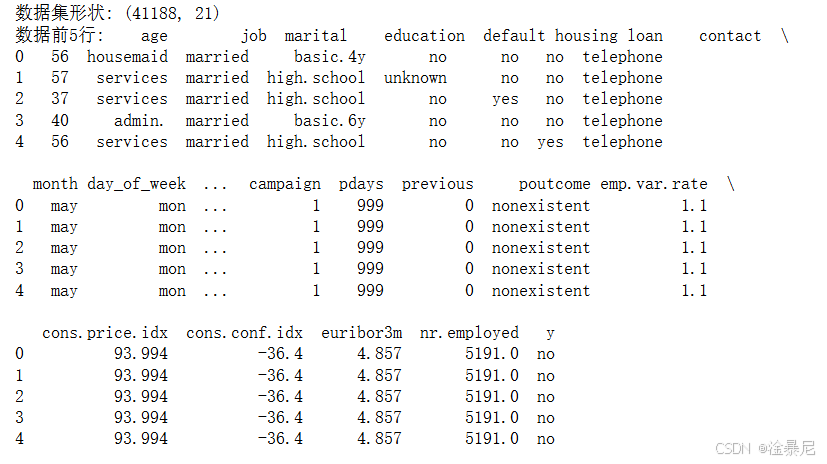
数据集包含41,188条记录(行)和21个特征(列)
通过shape确认了数据维度为(41188, 21)
数据预处理与探索性分析
# 检查目标变量分布
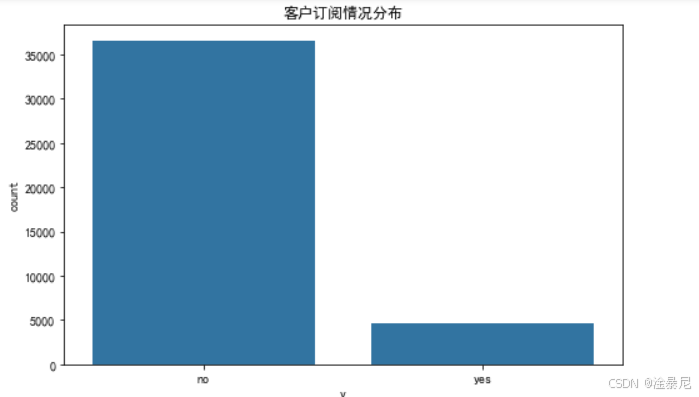
plt.figure(figsize=(8, 5))
sns.countplot(x='y', data=df)
plt.title('客户订阅情况分布')
plt.show()
首先分析目标变量分布,通过countplot绘制客户订阅情况的柱状图,直观了解订阅与未订阅客户的比例,判断数据是否存在不平衡问题。
-
未订阅(“no”):约35,000人(具体精确值需查看实际数据)
-
订阅(“yes”):约5,000人(柱形高度约为"no"的1/7)
# 分析数值型特征与目标变量的关系
numeric_features = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
plt.figure(figsize=(15, 10))
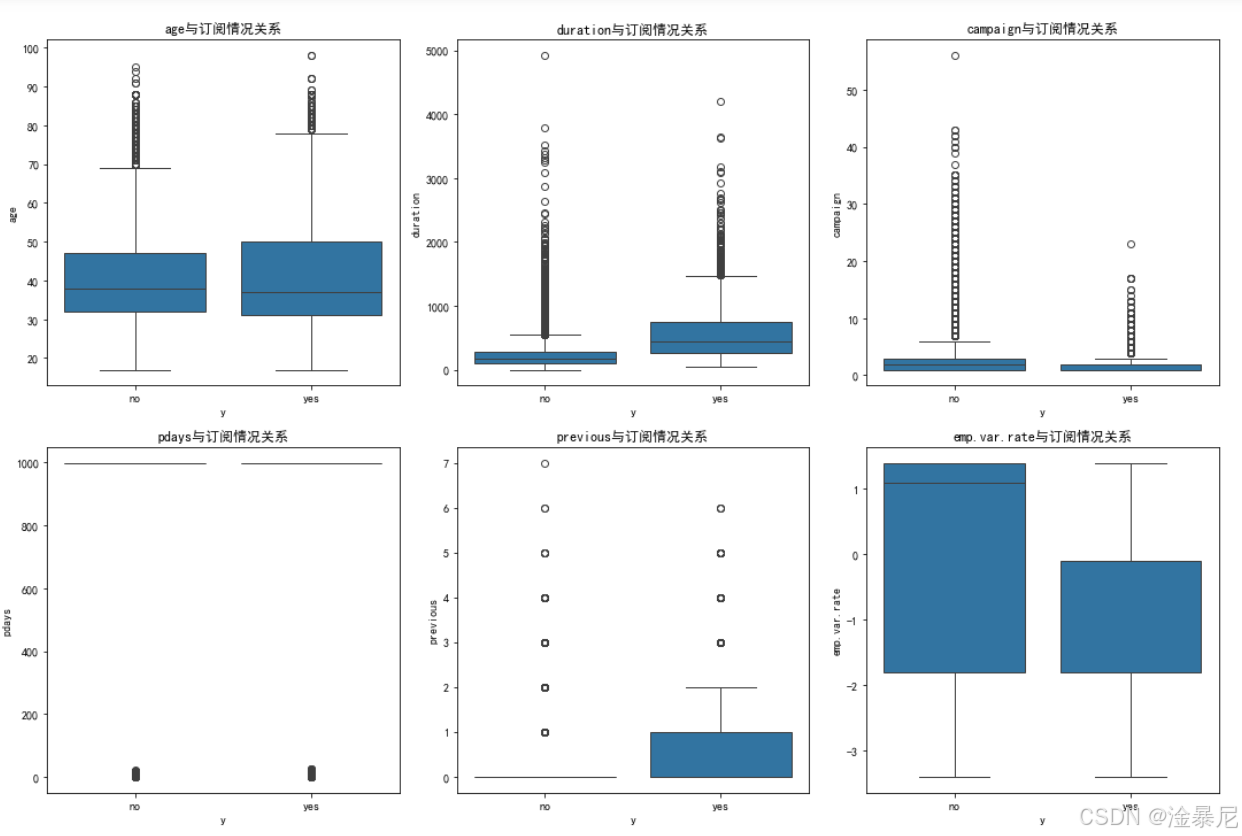
for i, feature in enumerate(numeric_features[:6]):plt.subplot(2, 3, i+1)sns.boxplot(x='y', y=feature, data=df)plt.title(f'{feature}与订阅情况关系')
plt.tight_layout()
plt.show()
接下来分析数值型特征,通过select_dtypes筛选出所有数值型列,然后使用循环创建2×3的子图布局,通过箱线图比较不同订阅情况下各特征的分布差异,判断数值特征对订阅行为的影响。
# 分析分类型特征与目标变量的关系
categorical_features = df.select_dtypes(include=['object']).columns.tolist()
categorical_features.remove('y') # 排除目标变量
plt.figure(figsize=(15, 20))
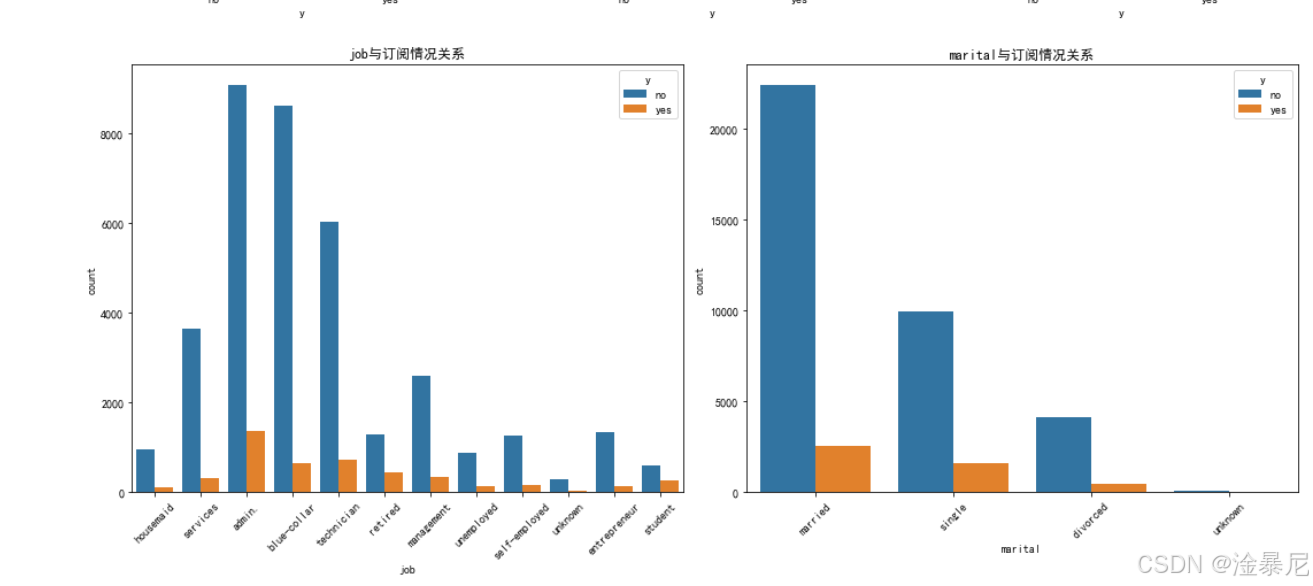
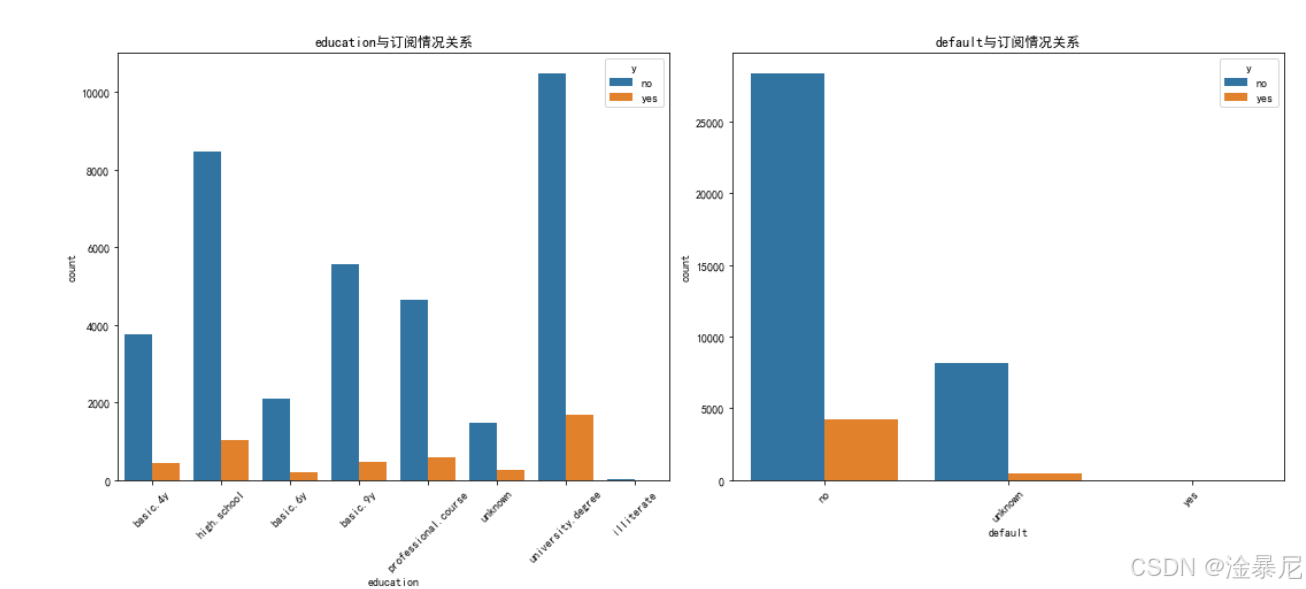
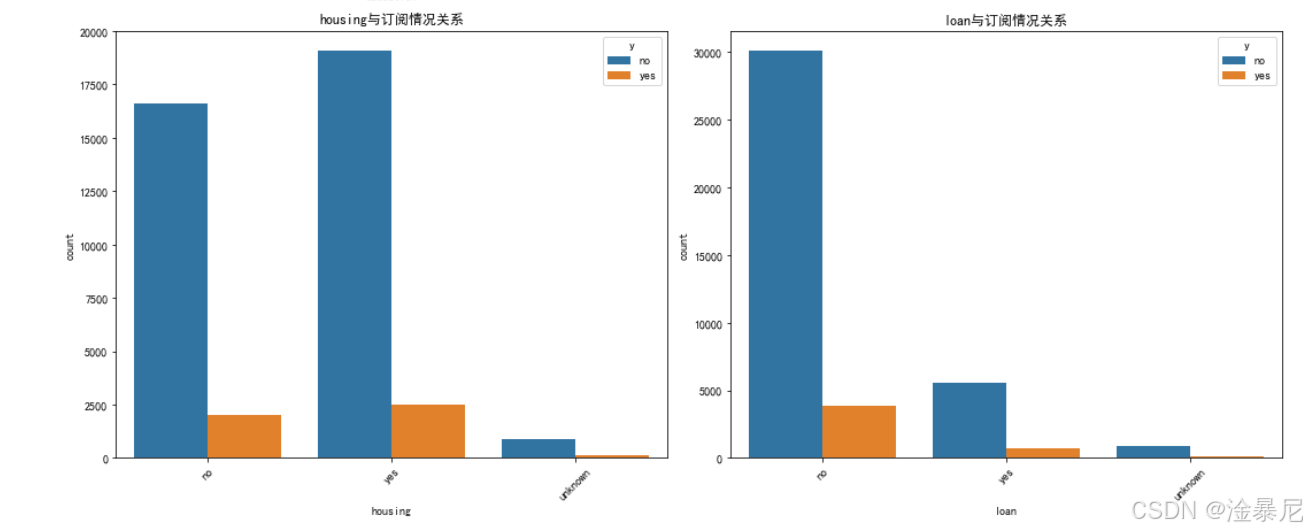
for i, feature in enumerate(categorical_features[:6]):plt.subplot(3, 2, i+1)sns.countplot(x=feature, hue='y', data=df)plt.title(f'{feature}与订阅情况关系')plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
最后分析分类型特征,同样通过select_dtypes筛选出分类型列并排除目标变量,然后使用3×2的子图布局,通过计数图展示不同类别与订阅情况的关系,特别对x轴标签进行45度旋转以避免重叠。
特征工程与模型构建
# 准备特征与目标变量
X = df.drop('y', axis=1)
y = (df['y'] == 'yes').astype(int) # 将'yes'/'no'转换为1/0
首先准备建模数据,将特征(X)和目标变量(y)分离,其中目标变量通过布尔索引转换为1/0的数值形式,便于模型处理。
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
然后划分训练集和测试集,设置test_size=0.2保留20%数据用于测试,random_state=42确保结果可复现,stratify=y使两个集合保持与原数据一致的目标变量分布。
# 定义预处理管道
numeric_transformer = Pipeline(steps=[('scaler', StandardScaler())
])categorical_transformer = Pipeline(steps=[('onehot', OneHotEncoder(handle_unknown='ignore'))
])
接下来定义特征预处理管道:数值型特征使用StandardScaler进行标准化,消除量纲影响;分类型特征使用OneHotEncoder进行独热编码,将类别转换为模型可理解的数值形式,并设置handle_unknown='ignore’处理未知类别。
# 划分数值型和分类型特征
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns# 组合预处理步骤
preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),('cat', categorical_transformer, categorical_features)])
通过select_dtypes自动识别并划分数值型和分类型特征,然后使用ColumnTransformer组合两种预处理管道,实现对不同类型特征的并行处理。
# 构建完整管道(预处理+模型)
model = Pipeline(steps=[('preprocessor', preprocessor),('classifier', RandomForestClassifier(n_estimators=100, random_state=42))
])# 训练模型
model.fit(X_train, y_train)
将预处理管道与RandomForestClassifier模型组合成一个完整的机器学习管道,这样可以确保预处理步骤仅在训练数据上拟合,避免对测试数据造成数据泄露。设置n_estimators=100构建包含100棵树的随机森林模型。
# 预测与评估
y_pred = model.predict(X_test)print('模型准确率:', accuracy_score(y_test, y_pred))
print('\n分类报告:\n', classification_report(y_test, y_pred))
使用训练好的模型对测试集进行预测,然后通过准确率和分类报告评估模型性能,后者提供了精确率、召回率和F1分数等更全面的指标。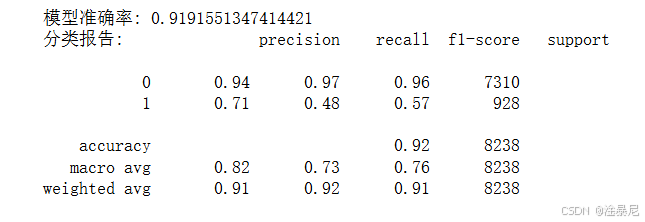
# 混淆矩阵可视化
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('混淆矩阵')
plt.xlabel('预测结果')
plt.ylabel('实际结果')
plt.show()
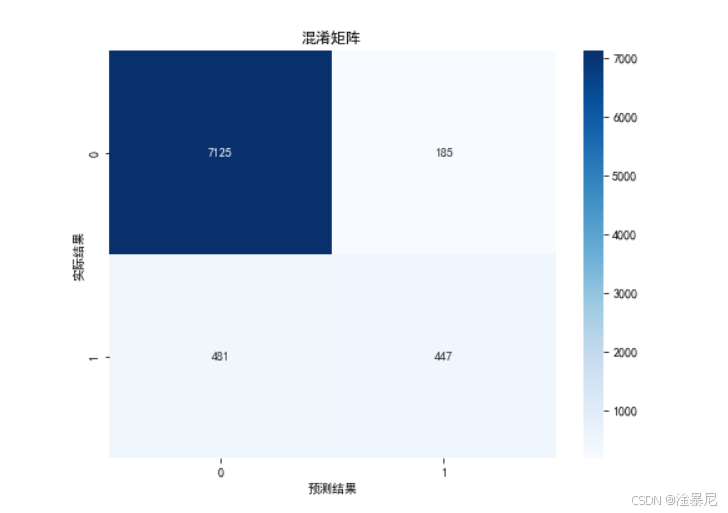
通过混淆矩阵可视化展示模型预测结果的详细分布,包括真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)的数量,帮助理解模型在不同类别上的表现。
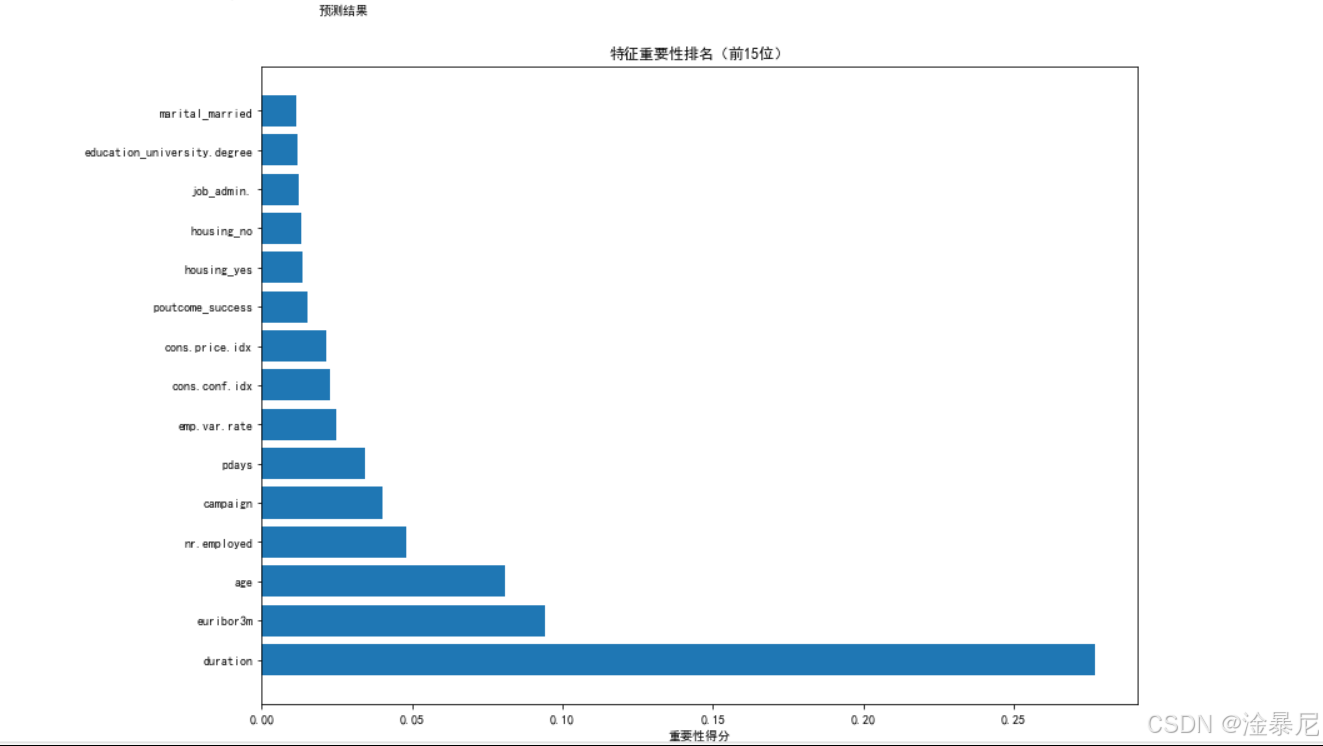
# 特征重要性分析
if hasattr(model[-1], 'feature_importances_'):# 获取特征名称categorical_ohe_feature_names = model.named_steps['preprocessor'].named_transformers_['cat'].named_steps['onehot'].get_feature_names_out(categorical_features)all_feature_names = list(numeric_features) + list(categorical_ohe_feature_names)# 获取特征重要性importances = model.named_steps['classifier'].feature_importances_indices = np.argsort(importances)[::-1]# 可视化特征重要性plt.figure(figsize=(12, 8))plt.barh(range(len(indices[:15])), importances[indices[:15]])plt.yticks(range(len(indices[:15])), [all_feature_names[i] for i in indices[:15]])plt.title('特征重要性排名(前15位)')plt.xlabel('重要性得分')plt.tight_layout()plt.show()
最后进行特征重要性分析,通过随机森林模型的feature_importances_属性获取各特征对预测的贡献度,然后可视化展示前15位最重要的特征,为后续营销决策提供依据。
结论与营销建议
# 根据分析结果提出营销建议
print('''营销建议:
1. 关注与高订阅率相关的客户特征,如:- 接触时长较长的客户- 之前营销活动成功的客户- 处于特定就业状态的客户2. 优化营销策略:- 针对高潜力客户群体增加营销投入- 改进电话营销的时间安排- 基于客户特征定制营销话术3. 模型可用于客户分群,实现精准营销,提高转化率''')
通过前面的数据分析和模型构建,我们得出以下营销建议:首先应关注接触时长较长、之前营销活动成功以及处于特定就业状态的客户,这些特征与高订阅率高度相关。通过针对高潜力客户群体增加营销投入、改进电话营销的时间安排、基于客户特征定制营销话术等方式优化营销策略。最终,通过该模型可以实现客户分群和精准营销,有效提高转化率和营销效率。