大数据之路:阿里巴巴大数据实践——实时技术与数据服务
实时技术
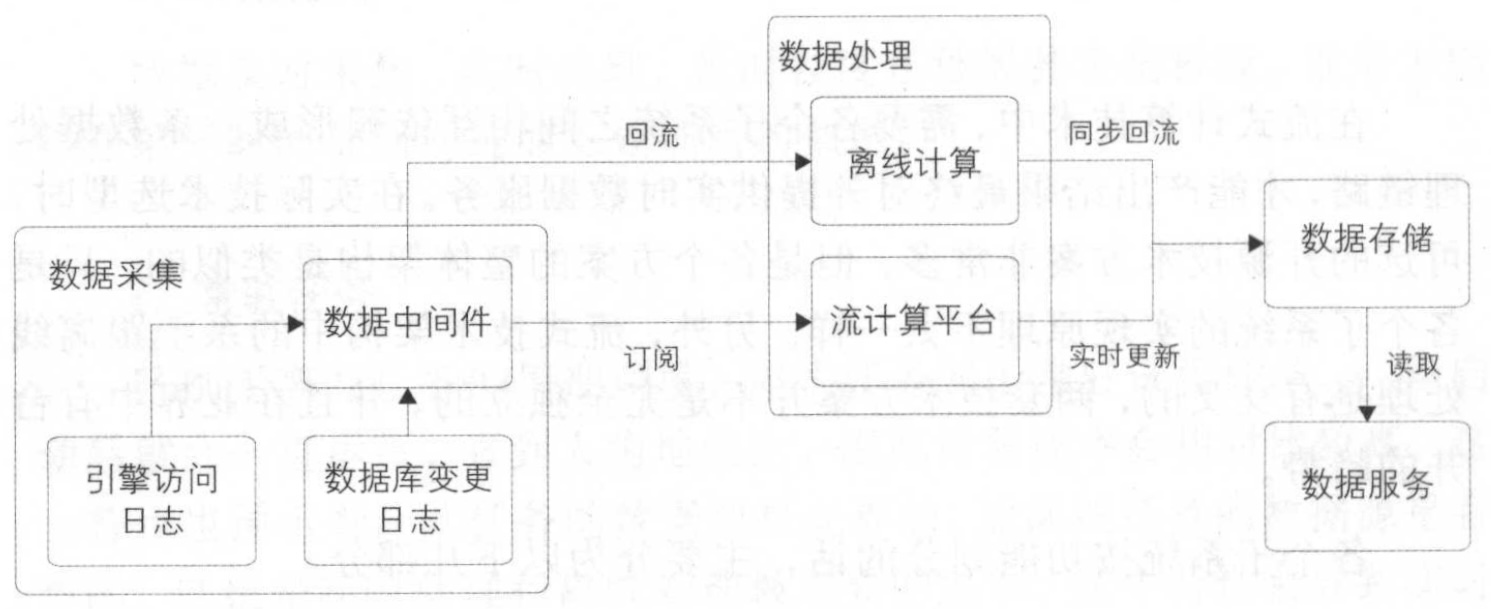
流式技术架构
-
数据采集:数据的源头,一般来自于各个业务的日志服务器,这些数据被实采集到数据中间件(Kafka)中, 供下游实时订阅使用。
- DB变更日志:比如 MySQL 的 binlog 日志、 HBase 的 hlog 日志、 OceanBase 的变更日志、 Oracle 的变更日志等。
- 引擎访问日志:用户访问网站产生的 Apache 擎日志、搜索引擎的接口查询日志等。
-
数据处理:下游实时订阅数据并拉取到流式计算系统的任务中进行加工处理,需要提供流计算引擎(Flink)以支持流式任务的执行。
-
StreamCompute:全链路流计算开发平台,涵盖了从数据采集到数据生产各个环节,力保流计算开发严谨、可靠。
-
StreamSQL:流式数据分析结构化查询语言,开发人员只需要写SQL,不需要关注其中的计算状态细节。
-
指标去重:包括精确去重和模糊去重,其中精确去重需要将明细数据全部保存下来。
布隆过滤器:该算法是位数组算法的应用,不保存真实的明细数据,只保存明细数据对应哈希值的标记位。
基数估计(BitMap):利用哈希的原理,按照数据的分散程度来估算现有数集的边界,从而得出大概的去重值总和。
-
数据倾斜:分区数据量非常大的时候,单个节点的处理能力是有限的,单任务产出延迟会导致整体性能下降。
去重指标分桶:通过对去重值进行分桶 Hash ,把每个桶的值进行聚合就得到总值,这里利用了每个桶的 CPU 和内存。
非去重指标分桶:数据随机分发到每个桶中,最后再把每个桶的值汇总,主要利用的是各个桶的 CPU 能力。
-
事物处理:由于实时计算是分布式处理的,系统的不稳定性必然会导致数据的处理有可能出现失败的情况。
-
-
数据存储:数据被实时加工处理(比如聚合、清洗等)后,会写到某个在线服务的存储系统(Hive)中,供下游调用方使用。
- 中间计算结果:在实时应用处理过程中,会有一些状态的保存 ,用于在发生故障时使用数据库中的数据恢复内存现场。
- 最终结果数据:指的是通过 ETL 处理后的实时结果数据,这些数据是实时更新的,写的频率非常高,可以被下游直接使用。
- 维表数据:在离线计算系统中,通过同步工具导入到在线存储系统中,供实时任务来关联实时流数据。
- 表名设计:汇总层标识 + 数据域 + 主维度 + 时间维度。
- rowkey设计:MD5 + 主维度 + 维度标识 + 子维度1 + 时间维度 + 子维度2。
-
数据服务:在存储系统上会架设一层统一的数据服务层(比如提供 RPC 接口、 HTTP 服务等),用于获取实时计算结果。
流式数据模型
- 数据分层
- ODS层(操作数据层):ODS 层属于操作数据层,是直接从业务系统采集过来的最原始数据,包含了所有业务的变更过程。
- DWD层(明细数据层):在 ODS 层的基础上,根据业务过程建模出来的实时事实明细层。
- DWS层(汇总数据层):订阅明细层的数据后,会在实时任务中计算各个维度的汇总指标。
- ADS层(应用数据层):应用于一般垂直业务的个性化维度汇总层。
- DIM层(实时维表层):实时维表层的数据基本上都是从离线维表层导出来的,抽取到在线系统中供实时应用调用。
- 多流关联:在流式计算中常常需要把两个实时流进行主键关联,以得到对应的实时明细表,涉及中间状态的保存和恢复机制等。
数据服务
服务架构演进
- DWSOA:将业务方对数据的需求通过 SOA 服务的方式暴露出去,一个需求开发一个或者几个接口,开放给业务方调用。
- OpenAPI:将数据按照其统计粒度进行聚合,同样维度的数据,形成一张逻辑表,采用同样的接口描述。
- SmartDQ:开放给业务方通过写 SQL 的方式对外提供服务 ,由服务提供者自己来维护 SQL,支持异构数据源和分布式查询。
- OneService:提供数据服务的核 心引擎、开发配置平台以及门户网站。数据生产者将数据人库之后,服务提供者可以根据标准规范快速创建服务、发布服务、监控服务、下线服务, 服务调用者可以在门户网站中快速检索服务,申请权限和调用服务。
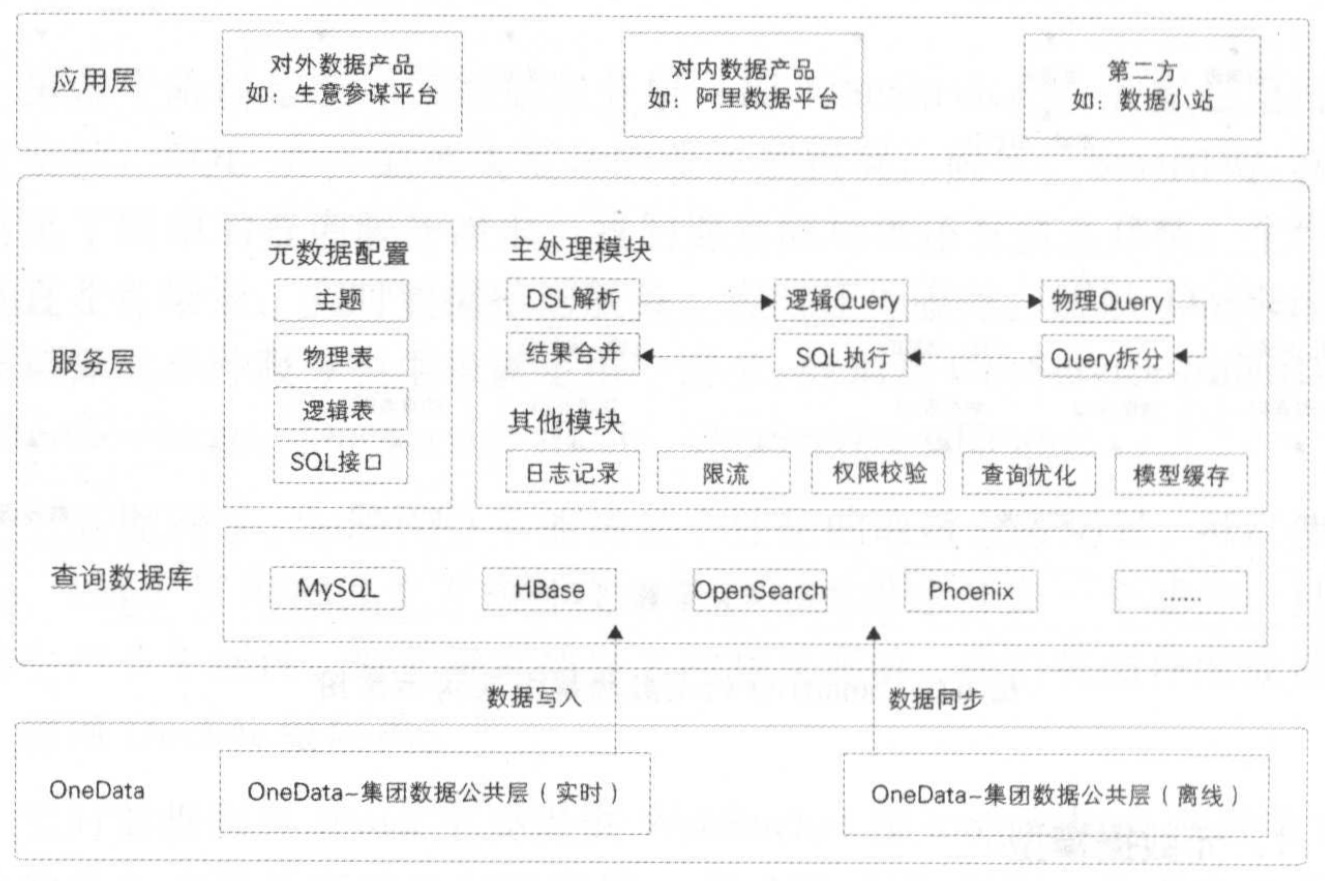
技术架构
-
SmartDQ(数据查询服务)
-
元数据模型:逻辑表到物理表的映射,自底向上分别是数据源、物理表、逻辑表、主题。
-
主处理模块
DSL 解析:对用户的查询 DSL 进行语法解析,构建完整的查询树。
逻辑 Query 构建:遍历查询树,通过查找元数据模型,转变为逻辑 Query。
物理 Query 构建:通过查找元数据模型中的逻辑表与物理表的映射关系,将逻辑 Query 转变为物理 Query。
Query 拆分:如果该次查询涉及多张物理表,并且在该查询场 景下允许拆分,则将 Query 拆分为多个 SubQuery。
SQL 执行:将拆分后的 SubQuery 组装成 SQL 语句,交给对应 DB 执行。
结果合并:将 DB 执行的返回结果进行合井,返回给调用者。
-
架构图
-
-
Lego(垂直业务服务)
- 介绍:面向中度和高度定制化数据查询需求、支持插 件机制的服务容器。
- 应用:提供日志 、服务注册、 配置监听、 鉴权、数据源管理等一系列基础设施,具体的数据服务则由服务插件提供。
- 实现:采用轻量级的 Node.JS 技术核实现,适合处理高并发、低延迟的 IO 集型场景。
-
iPush(数据推送服务)
- 通信:基于高性能异步事件驱动模型的网络通信框架 Netty 4 实现。
- 缓存:使用 Guava 缓存实现本地注册信息的存储。
- 消息队列:基于 Disruptor 高性能的异步处理框架(可以认为是最快的消息框架)的消息队列。
- 服务发现:使用 Zookeeper 在服务中实时监控服务器状态。
-
uTiming(定时任务服务)
- 介绍:基于在云端的任务调度应用,提供批量数据处理服务。
- 应用:支撑用户识别、用户画像、人群圈选三类服务的离线计算,以及用户识别、用户画像、人群入库。
- 实现:uTiming-scheduler 负责调度执行 SQL 或特定配置的离线任务,用户使用数据集市工具或 Lego API 建立任务。
数据服务
- 发布系统
- 元数据隔离:开发环境元数据、预发环境元数据和线上环境元数据相隔离。
- 隔离发布:使用资源划分、资源独占、增量更新对不同用户的发布操作进行隔离。
- 隔离
- 机房隔离:每个机房独立部署一个集群,且机器数量尽量保持均衡,以实现双机房多活容灾。
- 分组隔离:根据某些条件将调用者进行分层 ,然后将服务端的机器划分为干个分组,每个分组都有明确的服务对象和保障等级。
- 安全限制:对调用者的最大返回记录数、必传字段、超时时间进行配置,防止查询消耗大量资源。
- 监控
- 调用日志监控:对调用信息进行监控,采集基础信息、调用者信息、调用信息、性能指标和错误信息。
- 调用监控:用于监控传统的健康状态,包括性能趋势、零调用统计、慢SQL查询、错误排查。
- 限流&降级
- 限流:针对调用者以及数据源等关键角色以API实例粒度做 QPS 阔值控制,实现方案包括令牌桶、漏桶算法。
- 降级:如果某个数据源突然出现问题,可以通过限流措施(QPS降为0)、元数据置失效进行降级保障整体高可用。
性能调优
- 资源分配
- 剥离计算资源:剥离复杂的计算统计逻辑,将其全部交由底层的数据公共层进行处理,只保留核心的业务处理逻辑。
- 查询资源分配:分别建立KV查询线程池和List查询线程池,解耦快查询/慢查询。
- 执行计划优化:采用DAG依赖对查询任务进行并行合并提高性能。
- 缓存优化
- 元数据缓存:在服务启动时就已经将全量数据加载到本地缓存中,以最大程度地减少元数据调用的性能损耗。
- 模型缓存:将解析后的模型(包括逻辑模型、物理模型)缓存在本地,遇到相似的 SQL 时,直接从缓存中得到解析结果。
- 结果缓存:对重复请求查询结果进行缓存,以提高查询性能。