数仓规范体系的构建
一、前言
数仓存储着公司的数据资产,里面的数据不仅海量,包含的业务也是多如牛毛,作为数仓如何能够更加有效,快速,有价值的协助公司发挥其优势,但是伴随着数据量和业务的增长,数据标准化也成为大家经常提及的话题。
但是从数据开发的标准、数据资产管理、数据质量的治理来说,都绕不开一个名词—数仓建模
二、数仓建模的目标
在使用数据时,往往面临很多问题比如:
- 1、数据源不统一 :数据在使用时,不晓得数据源有没有,不晓得数据在哪里。
- 2、不能见名之意 :数据的使方是多样的,同一个命名业务与技术的定义各有歧义。
- 3、指标口径不统一:数据服务过程中,使用方不一样,对同个指标的定义各有不同。
数仓目的是准确、快速、高质量、有价值的提供数据支持以便公司进行决策。因此在数仓建设过程中:
1、要对数据含义要明确
2、对数据源要找得到
3、对表字段定义要清晰
4、对数据指标口径要统一
从而避免烟囱式开发,冗余大量代码,通过数据的复用性提高开发效率,降低数据返工率,达到敏捷开发。
三、数仓建设内容
明确数仓的建设目标后可以从以下方向建设数仓:
1、数仓的分层架构:合理的数仓架构能够清晰且快速让数据有序的进行流转。
2、词根设计:通过数据字典可以规范表名、字段名、含义、字段类型等等。
3、指标体系:保证统一对外输出的数据口径,避免同一指标不同口径的情况发生。
4、主题域划分:保证同一业务域数据的一致性,简化模型设计,提高数据复用性。
3.1 数仓分层及开发规范
一个优秀的数仓应该怎么分层?分几层?市面上有很多优秀的建模方法和案例,但是没有最好的 只有最合适的,分层目的是因快速增长的数据,给未来数据的使用提供稳定的框架,为业务发展提供稳定、准确的数据,并能按照数仓模型进行数据驱动。
一个好的分层架构,有以下好处:
-
清晰数据结构;
-
数据血缘追踪;
-
减少重复开发;
-
数据关系条理化;
-
屏蔽原始数据的影响。
最终数仓分层还是要结合公司业务进行的,下图是某公司某业务的数据仓分层图:
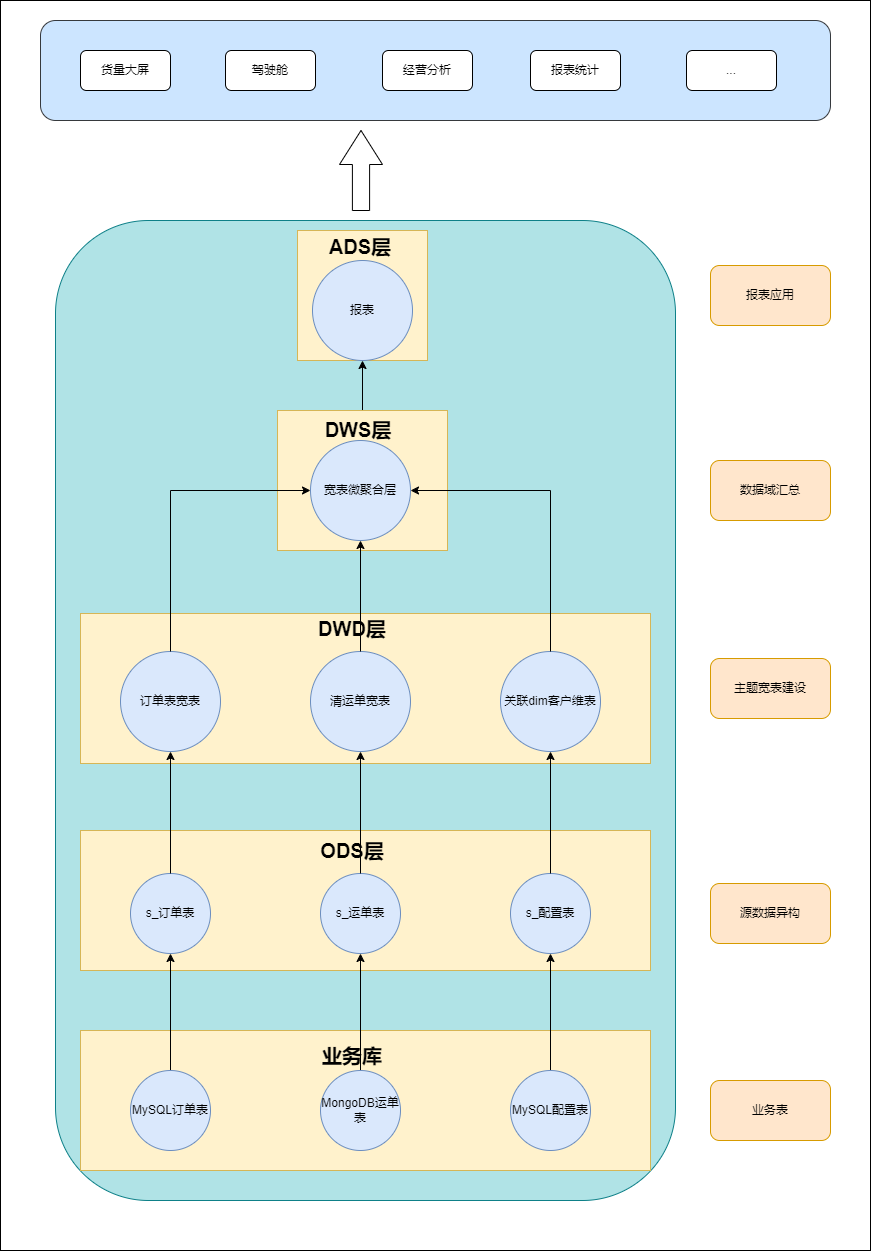
分层解释及各层规范:
1.ODS(数据临时存储层)
1. 异构数据源,将各系统基础数据同步至数仓,结构上与源系统基本保持一致。
2. 增全量同步逻辑要清晰。
2.DW 层(包含三层)
2.1 DWD(明细数据层 Data Warehouse Detail)
1. 对ODS数据层做一些数据清洗和规范化的操作,比如 null 转换,货量是 KG or T 注释要清晰等,
2. 区分ODS中各个数据到底是属于事实表,还是属于维度表。对分区的表管理生命周期,是否设置 TTl 等
3. 对是否记录数据生命过程的表,做拉链表等等
4. 多张表数据关联在一起,降维操作,形成一张大宽表。
2.2DWS(服务数据层 Data Warehouse Service)
基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据(最小维度微聚合)。
3.DIM(数据维表层 Data Dimension )
如果维度表过多的话可以单独设这一层 比如日期表,省区表,客户表等配置信息表。
4.ADS(报表应用层 ADS)
存储分析的结果表, 对DWS 层统计, 根据需求要求, 从 DWS 表中获取想要的数据, 将这些数据灌入到ADS层
5.各层表及命名
1、 全量表:在表后面用 _full 标识 也可以省略不写(建议不写)
2、 增量表:在表后面用 _inc / _i 标识
3、 拉链表:_l
4、 临时表:tmp.tmp_xxx(专门增加一个临时库 区分正式表和临时表)
drop table if exists tmp.ads_load_car_efficiency ;
create table tmp.ads_load_car_efficiency as
select * from table_s;
5、 维度表:dim_xxx
6、 周期回刷表:后缀用 _d/(day 天更新可省略) _h/(hour小时更新) _m/(month月更新)等等标识
7、 另外对于分区表也做 ttl 优化


8、 表命名尽量做到见名知意,DWD层命名格式:DW.DWD_主题域_表名 或者 DW.DWS_主题域_表名,ADS层命名格式:ADS.ADS_表名
结合以上 举例:dw.dwd_yy_order_detail_hour_inc dw.dwd + 运营系统+订单主题+小时更新频率+增量表
业务域、主题域我们都可以用词根的方式枚举清楚,不断完善。
3.2 主题域划分
总是听到数据域,那么数据域和主题域是有什么关系呢,参考《阿里巴巴大数据之路》书籍和网上有人总结过这么一段,如下:
主题域:面向业务过程,将业务活动事件进行抽象的集合,如下单、支付、退款都是业务过程,针对公共明细层(DWD 在我的划分中是 DWB)进行主题划分。
数据域:面向业务分析,将业务过程或者维度进行抽象的集合,针对公共汇总层(DWS)进行数据域划分。
业务过程:指企业的业务活动事件,如下单、支付、退款都是业务过程,业务过程就是一个不可拆分的行为事件。
个人案例实践分享
划分主题域
我负责的是某物流业务的数仓,我是按照我们业务系统划分的,因为业务系统隔离在建设过程中减少扯皮。
主题的划分
主题域划分之后就要分析我的主题对象在我的这一过程我主要是对货量的分析,我的分析对象有运单,订单,操作 等等 那么数仓主题就可以划分为 运单主题,订单主题等。
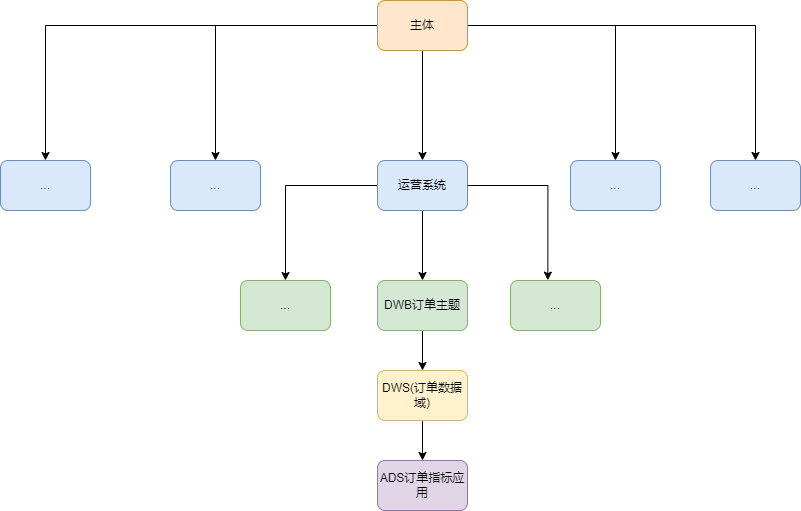
为保障整个体系的健壮性,主题域需要长期维护和更新且不轻易变动。在划分主题域时,既能涵盖当前所有的业务需求,又能兼容新业务以及扩展新的 数据域域。
四、数仓命名规范
词根:可以用来统一表名、字段名、主题域名等等
对于词根的管理我们在经历了一段时间的混乱期后决定用数据字典(Data Dictionary)来代替词根,为此我们根据搜集的元数据信息做匹配,使用标准化字典库和智能推荐机制,解决字段命名不规范问题,提升开发效率与数据治理水平。
站在数据字典的角度设计字段命名规则,需要将命名规范与元数据结合起来,确保每个字段名在技术上是标准规范的,在业务上也是通俗易懂的。
4.1 元数据驱动校验
DDL自动化扫描,自动检测建表语句:
工具用的是(Apache Calcite)
-- 违规示例:
CREATE TABLE dwd_order (orderid BIGINT, -- 违反规则:应命名order_idcnt INT, -- 违反规则:应命名order_cntdate STRING -- 违反规则:应命名order_date
);
→ 自动拦截并提示:举例 date

建表时 字段是否存在 指标字段是否和指标字典有冲突都会有字典校验

冲突如都提供一定处理建议:

建议:
- 字段命名不要出现同义不同名、同名不同义
- 所有单词小写
- 用下划线做分隔符: order_cnt
- 数量字段后缀 _cnt 等标识…
- 金额,货量,体积等字段类型 统一 decimal(24,4) 数量,件数统一 int 类型 不要存在 string 类
- 日期格式: 统一为 YYYY-MM-DD 或其它约定格式
- 分区字段: 统一为YYYYMMDD类型 string
- 缩写规范: 明确缩写的含义, 避免歧义 (如 qty 表示数量 quantity)
- …
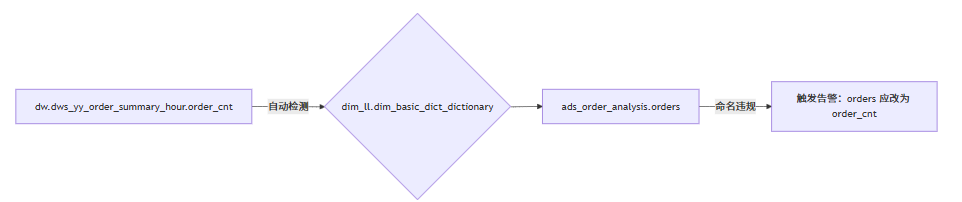
4.2 字段级血缘
当核心指标字段(如 order_cnt)被下游引用时,自动同步命名规范:
4.3 智能命名推荐
在IDE(如DBeaver/Datagrip)集成插件,输入业务含义自动推荐合规字段名:
输入: “统计日期”
推荐: count_date
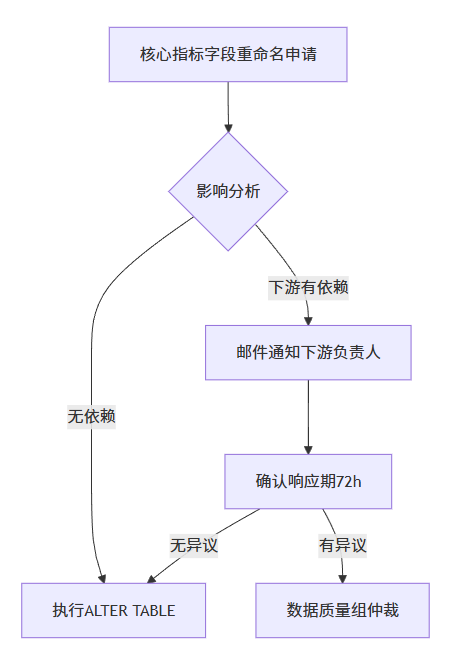
4.4 流程制度
4.5 历史治理策略
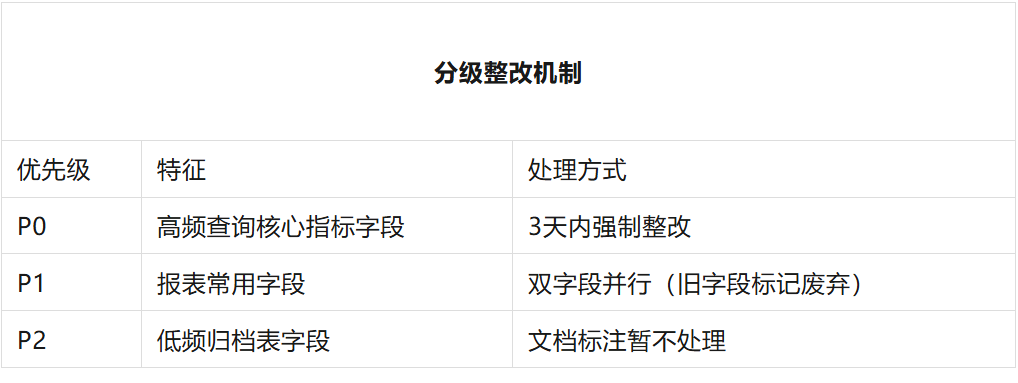
alter table ads.ads_order_analysis change prod_cat_code disable_prod_cat_code string comment '产品类目编码';alter table ads.ads_order_analysis add column product_category_code string comment '产品类目编码_新规范';
4.6 治理闭环设计
