数据采集分析:从信息洪流中掘金的科学与艺术
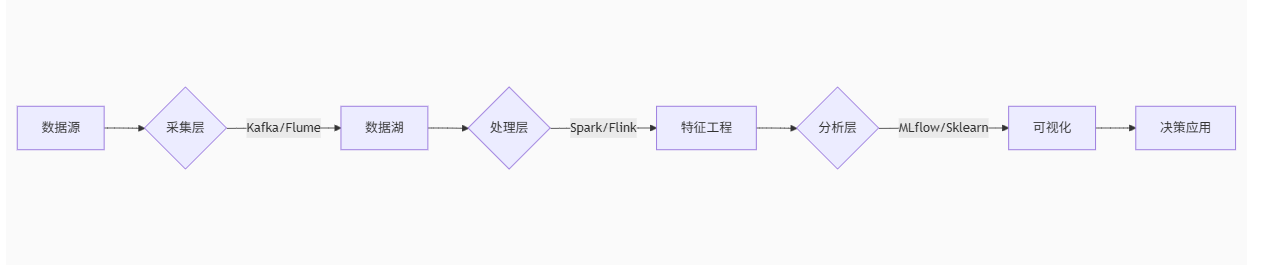
——如何将原始数据转化为商业决策的黄金?
🌐 引言:我们正淹没在数据的海洋,却渴求着知识的甘泉
每天全球产生 2.5万亿字节 数据(相当于每秒下载4.5万部高清电影),但未经分析的数据如同未提炼的原油——看似庞大却无法驱动业务引擎。数据采集分析正是将原始信息转化为决策智慧的核心能力,它决定了企业能否在数字化浪潮中抢占先机。
🔍 一、数据采集:精准捕获目标信息的“雷达系统”
核心原则:高质量输入 = 高质量输出
▶ 主流采集技术对比
| 方法 | 适用场景 | 工具示例 | 关键挑战 |
|---|---|---|---|
| 网络爬虫 | 竞品价格监控、舆情分析 | Scrapy, Selenium | 反爬虫机制、动态渲染 |
| API对接 | 第三方平台数据(天气/支付) | Python requests, Postman | 权限限制、速率控制 |
| 日志埋点 | 用户行为追踪(APP/网页) | Google Analytics, Matomo | 数据丢失、隐私合规 |
| IoT传感器 | 工业设备监测、环境数据 | Raspberry Pi, LoRaWAN | 传输稳定性、海量存储 |
python
# 动态网页爬虫示例(Selenium对抗反爬)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options options = Options()
options.add_argument("--headless") # 无界面模式
driver = webdriver.Chrome(options=options)
driver.get("https://example.com/dynamic-content")
data = driver.find_element_by_id("price").text # 获取动态加载价格 ⚠️ 采集避坑指南
法律红线:GDPR/《个保法》要求用户授权(如Cookies提示)
反爬策略:动态IP代理池(参考Scrapy-Redis架构)
数据校验:实时检测字段缺失率(如Alibaba DataX)
🧪 二、数据分析:从混沌到秩序的“炼金术”
核心公式:数据 → 清洗 → 建模 → 洞见
▶ 四层分析框架
描述性分析(What happened?)
方法:数据可视化(Tableau/Power BI)、统计摘要
输出:日报/周报(如DAU暴跌15%预警)
诊断性分析(Why did it happen?)
方法:关联分析(Apriori算法)、漏斗归因
案例:电商转化率下降 → 定位到支付页加载延迟
预测性分析(What will happen?)
方法:时序预测(LSTM/Prophet)、分类模型(XGBoost)
python
# 用Prophet预测销售额 from prophet import Prophet model = Prophet(seasonality_mode='multiplicative') model.fit(df) # df含ds(日期), y(销售额) future = model.make_future_dataframe(periods=30) forecast = model.predict(future)
处方性分析(How to improve?)
方法:A/B测试、优化算法(遗传算法)
输出:策略建议(如推荐系统提升CTR 23%)
🚀 三、实战场景:数据驱动增长的经典案例
案例1:电商用户留存提升
问题:新用户7日留存率仅18%
分析路径:
埋点采集:追踪用户注册→首单路径
漏斗诊断:发现优惠券领取页流失率62%
A/B测试:简化领取流程(点击减至1步)
结果:留存率提升至29%,年增收$500万
案例2:制造业预测性维护
问题:设备突发故障导致停产损失
方案:
采集:5000+传感器实时温度/振动数据
分析:LSTM模型预警故障(准确率92%)
价值:维修成本降低40%,产能利用率提升17%
⚡ 四、技术栈升级:现代数据分析架构
图表
代码
实时分析:Apache Doris(毫秒级响应)
自动化:Airflow调度ETL管道
云原生:Snowflake + AWS Lambda 无服务器架构
🛡️ 五、风险与应对:避开数据分析的致命陷阱
垃圾进垃圾出(GIGO)
对策:数据血缘追踪(Apache Atlas)
隐私泄露
对策:差分隐私(Apple方案)、联邦学习
模型漂移
对策:持续监控指标(PSI特征稳定性分析)
🔮 结语:未来属于“数据炼金师”
当传统企业还在依赖直觉决策时,掌握数据采集分析能力的团队已实现:
“预测需求波动、精准狙击用户痛点、用算法重构业务流程”
行动指南:
从核心业务场景切入(如转化率/库存周转)
建立“采集-分析-反馈”闭环(参考字节跳动Data平台)
培养数据思维:每个决策必须附带数据证据链
“数据是新时代的石油,而分析能力是炼油厂。” ——《经济学人》