大模型-batch之static batch
一、Static Batch
1.1 背景描述
目前的推理服务系统,基本都是专注于最大化整体 LLM serving 系统的整体吞吐量(throughput),也就是每秒服务的请求数量(或 rps)。目前主流的 LLM serving 引擎都把整体的吞吐量作为对比性能的主要指标。
为了提高吞吐率,大家会采用批处理技术。所谓的批处理是一种将多个数据样本一起传递给模型进行处理的技术, 使用批处理后,推理引擎会将来自多个请求的输入张量合并成一个大的输入张量,然后将其送入模型进行推理。由于目前的GPU具备很强的计算能力,所以更加倾向于输入大型输入张量而不是小型张量,因此相比于逐个处理单个样本,批处理可以在一次计算中同时处理多个样本。这样可以更有效地利用计算资源,提高计算速度。在LLM推理中,批处理比一个个请求处理的优势主要体现在以下几个方面:
减少模型参数加载次数: 在不使用批处理的情况下,每次处理一个输入序列都需要加载一次模型参数,而加载模型参数通常会消耗大量的内存带宽。使用批处理可以在一次加载模型后, 可以复用模型参数,多次使用这些参数来处理多个输入序列,从而减少了加载的次数,减少io,提升效率。
提高内存带宽和计算资源的利用率: GPU的内存带宽是有限的资源,通过批处理,可以更有效地让这些内存带宽在计算过程中得到更充分的利用,从而可以更有效地利用计算资源,提高计算速度。
1.2 Static Batching
传统的批处理方法被称为静态批处理,是因为在这种方法中,批处理的大小在批次中所有请求推理完成之前保持不变。在静态批处理中,当新请求在当前批次执行过程中到达时,引擎会保持这些新请求在请求队列中,直到当前批次中所有请求都完成,也就是推理服务并不会立马执行新的请求序列。
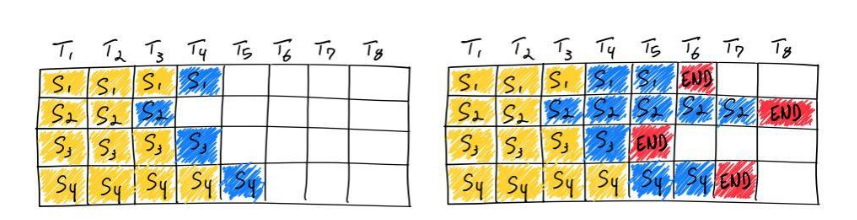
如下图自始至终这里所处理的batch数都是4,这也就是static的由来。然而,因为不同输入的输出长度差别可以很大,比如下图中的第二个输入,生成了5个token才终止,而第3个输入生成了1个token就终止了。除非所有的输入长度都一致、且输出长度也一致(比如分类问题),那么下图右侧空白格的这些时刻的系统资源都是处于空闲的状态,导致系统的整体的吞吐量下降。
看一个推理服务系统的使用static batching的实际运行状态:
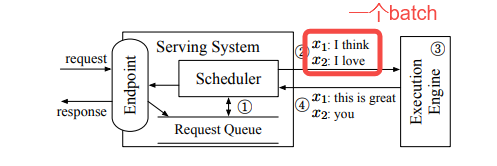
如果当前执行引擎空闲,Scheduler(调度器)从队列中获取一批请求构建成一个batch(图中的x1 :"I Think"和 x2 :"I love"),对于下图中标号1。
Scheduler将batch交给Execution Engine(执行引擎)去做推理,对于下图中标号2。
Execution Engine通过运行模型的多次迭代来处理接收到的batch,对于下图中标号3。
当Execution Engine把这个batch的请求都处理完之后(Execution Engine分别生成“this is great”和“you”作为请求x1和x2的响应。),会统一返回给Scheduler,对于下图中标号4。
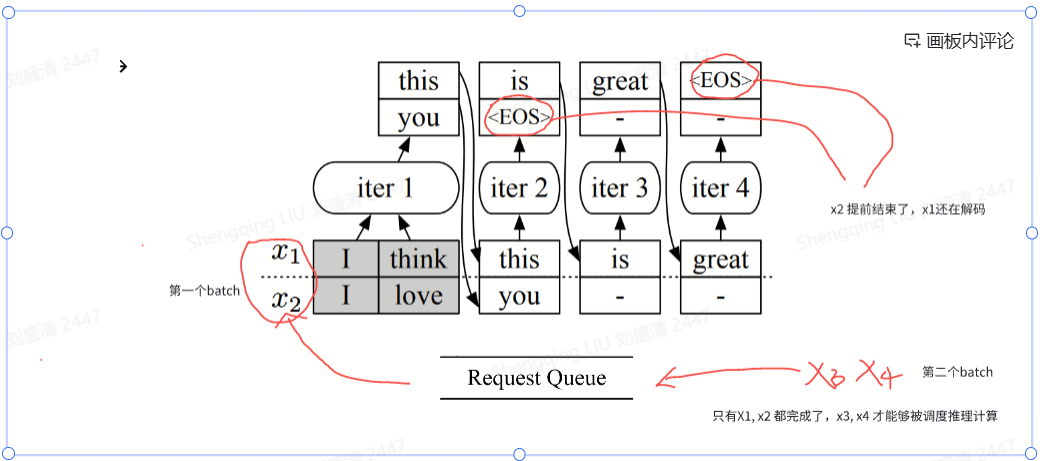
Scheduler会从请求队列中再次获取一批请求构建一个新batch。我们很容易发现静态批处理策略的劣势:它难以有效地处理不同生成长度的序列。静态批处理可能导致GPU在批处理中的不同序列的生成长度不同时被低效利用。因为不同的序列可能会在批处理中的不同迭代步骤中完成生成,而静态批处理会等待所有序列完成生成后才开始处理新的序列。这导致了在等待最后一个序列完成生成之前,GPU可能会被低效利用的情况。因为通过自回归方式处理单个请求时可能需要运行多次模型,而不同请求所生成的文本长度不一致,需要的迭代次数很可能不同,这就使得一些请求提前完成而其他请求仍在进行中。一旦有一个生成时间较长的序列存在,其他生成时间较短的序列将被迫等待、不能立即返回给客户端,即增加了给客户带来得延迟,也导致GPU的计算资源无法充分利用,浪费GPU的计算能力。如上图所示,x2提前完成,但是x1 尚未完成迭代,所以x2无法立即返回。而在上次分派之后到达的新请求(x3,x4)也必须等待当前batch中的x1处理完毕才能继续分发,这显著增加了排队时间。
问题本质在于“基于Transformer的生成模型的多迭代特性”和“以请求为粒度的调度策略”之间的冲突。多迭代特性意味着不同请求可能需要不同次数的迭代,某些请求的迭代次数可能会很少,可以提前处理完毕并返回给用户。而与静态批处理的这种特点对应,传统推理架构的调度策略是以请求为粒度的调度(Request-Level Schedule)。以请求为粒度的调度策略缺少灵活性,无法更改当前正在处理的请求batch,比批次中其他请求更早完成的请求无法返回客户端,而新到达的请求则必须等到当前批次完全处理完毕。这就导致当前的请求级调度机制无法有效处理具有多次迭代特性的工作负载。
因此,我们目前需要解决的问题如下:
问题1:如何处理提前完成的请求(early-finished requests)。不同请求所生成的文本长度不一致,短文本请求只能等待长文本请求处理完毕。而因为不易预测生成文本长度,故此难以把相同长度的文本组成一个batch一并处理。因此需要一个将已生成结束的请求从Batch中移除并提前返回结果的机制。
问题2:如何释放资源、处理延迟加入的请求(late-joining requests)。static batching 的队列中的新请求只能等到当前batch结束之后才能被scheduler进行分发,等待时间过长。因此需要一个将新请求插入到当前处理Batch中的机制。
1.3 缺陷解决与思考
面对上述两个问题,自然而然的会有如下思考:
针对问题1:如何处理提前完成的请求
因为当前整个batch都没有完成,用户只能等待。因此有研究人员想到:是否可以让batch中已经做完推理的请求释放资源,让新来的请求执行prefill操作。原有的请求继续执行目前的操作(prefill或者decode)。
针对问题2:如何处理延迟加入的请求。
由于预填充和解码阶段具有不同的特征,具体来说,预填充阶段主要关注请求到达和生成第一个标记之间的延迟,即时间到第一个标记(TTFT)。另一方面,解码阶段关注同一请求连续标记生成之间的延迟,称为标记之间的时间(TBT)。如何满足以上指标?有不同的思路。
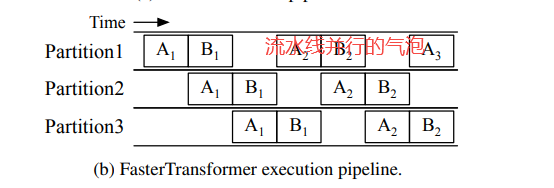
A, B 两个序列在切分成三个模型的计算设备上计算,当使用流水线并行时,有研究人员想到是否可以在气泡处插入新请求做prefill或者decode操作?这样可以在不影响当前请求的情况下填满气泡。
当不使用流水线并行时,接下来是处理等待prefill的请求?还是处理等待decode的请求?其实取决于在TTFT和TPOT两个指标中牺牲哪个,保全哪个。假设请求池有若干的prefill请求,如果优先处理等待prefill的请求,就可以快速给用户返回第一个token。但是需要连续处理好几个处理等待prefill的请求,无法做decode。这是在牺牲TPOT保全TTFT;如果为了让用户快速获取后续的token,让系统连续处理几个等待decode的请求,prefill请求就要等待,这样是在牺牲TTFT好全TPOT。似乎无论调度策略怎么调整,TTFT和TPOT这两个指标都存在强耦合关系。是prefill和decode这两个阶段在本质上就无法共存。
Prefill 和 Decode 请求有着不同的计算特性:
这种干扰是经典的系统问题。
优先安排一个阶段可能会导致无法满足另一个阶段的延迟要求。比如,较高的到达率(req/s)会生成更多的预填充作业,如果优先考虑预填充作业,则需要更多的GPU时间来满足TTFT要求,这反过来会对TPOT产生不利影响。
针对上面的疑问,处理Prefill和Decode有融合派和分离派两个思路:
分离思路:
Splitwise: Efficient generative LLM inference using phase splitting和 DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving就是其中的代表之作。
Prefill。主要满足 TTFT 指标。这是一种Compute Bound 的运算,对计算资源的需求量极大。其计算量随输入提示长度的平方增加。耗时超线性增加(吞吐量下降,如果耗时线性增加,那么平均吞吐量不变),哪怕是小批次的预填充任务,甚至单个较长的预填充任务,都可能使 GPU 的计算能力达到饱和,打满计算资源。一旦加速器达到饱和状态,预填充阶段的吞吐量就会保持不变(我们将其命名为加速器饱和阈值)。
Decode:主要满足 TPOT(token per of time) 指标。这是一种 Memory Bound 的运算,更容易受到 GPU 内存带宽限制的影响。对延迟敏感的任务,其资源使用量随生成的token长度呈次线性增长。Decode 计算需要大 batch 请求提高计算强度,充分利用计算资源。随着bs的增大,耗时略有增加(主要是因为数据增多导致传输耗时增多,计算耗时基本认为不变),吞吐量大概是线性增加。随着批量大小增加,解码阶段的吞吐量继续增加,但一旦内存带宽达到饱和状态,吞吐量就会达到峰值。
互相影响
Prefill 和 Decode 放在相同的 GPUs 上运行会导致它们之间相互干扰。我们看看当 GPU 在同时处理 Prefill 请求和 Decode 请求时,Prefill 和 Decode 如何互相影响性能。
对于 Prefill 请求,由于同一个 batch 有其它 Decode 请求,所以在 GPU 中计算耗时对比没有 Decode 请求时会略微增加,从而增加 Prefill 请求的 TTFT。
对于 Decode 请求,由于同一个batch 有 Prefill 请求,并且 Prefill 请求计算耗时通常会比 Decode 请求耗时大很多(一般是好几倍甚至几十倍的关系)。批处理中的解码任务必须等待更长的预填充作业完成,会造成 Decode 请求被 Prefill 请求拖慢,必须等待 Prefill 请求完成计算,Decode 请求才会开始下一个 token 的计算,从而大大增加了 Decode 请求的 TPOT。
混合运行预填充请求会导致严重的减速,因为我们在已经饱和的硬件上继续添加计算密集型作业。
混合运行预填充和解码请求会对两者都产生负面影响,因为我们同时运行批处理和延迟关键的作业。
混合解码请求会导致吞吐量下降,因为我们不了解内存带宽和容量使用情况,从而导致争用和排队阻塞。
融合的思路是将prefill放到Decode的间隙进行处理,或者把prefill和某个decode一起进行推理。开山之作是发布在2022年OSDI的Orca[1],其将Prefill和Decode融合,作为一个批次迭代(batching step)做前向传播。在这之后,以Sarathi[2] 和DeepSpeed-FastGen [3]为代表,将prefill序列拆成chunk,可以把每个chunk的prefill的处理插入到decode阶段之中,甚至和decode阶段进行融合。
考虑Prefill/Decode性质差异,人们开始尝试把Prefill和Decode放到不同的设备来分别处理。比如,
分离预填充和解码自然地解决了两个阶段之间的干扰,并使每个阶段都能专注于其优化目标 - TTFT或TPOT。每种类型的实例可以使用不同的资源和并行性策略来满足各种延迟要求。通过调整为两种类型的实例提供的GPU数量和并行性,我们可以最大化整个系统的每个设备的吞吐量,避免过度配置资源,最终实现符合服务质量的每个查询成本的降低。
分离派可以给Prefill和Decode设置不同的并行度,二者有更大的灵活性,使得整个系统朝着更好利用算力和更好利用带宽这两个不同方向对立发展,可以更好的对硬件进行优化。比如对于prefill和decode采用不同类型的GPU卡,或者可以针对长序列来分配多一些GPU进行处理,进而降低长序列的TTFT。
分离派遇到的最大挑战是如何在不同设备之间传输KVCache,这导致网络成本很大,从而需要比较高规格的网络硬件来在集群中进行互联。而如何处理长序列的并行,也是一个棘手问题。
融合派的优点是,prefill chunk和decode融合之后的处理时间和只做decode处理时间可能类似,这相当于prefill把decode没有用满的算力再利用起来。而且因为decode和prefill阶段都需要读一些固定的数据(比如模型权重),所以decode也可以搭上prefill的便车,把多次的数据读取合并起来,一次读取,多次使用。
融合派的缺点是,Prefill和Decode在相同设备上,二者并行度被绑定。如果prompt长度有限,则在请求的处理时间中,prefill阶段占比较小,尚可利用好算力。对于长序列,则prefill的占比提高,prefill并行度不够灵活的缺陷就暴露出来。
下一篇梳理下continuous batching
二、引用文献
[1] Orca: A distributed serving system for transformer-based generative models https://www.usenix.org/system/files/osdi22-yu.pdf
[2] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills https://arxiv.org/pdf/2308.16369
[3] DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference https://arxiv.org/pdf/2401.08671
[4] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
https://arxiv.org/pdf/2403.02310
[5] Splitwise: Efficient generative LLM inference using phase splitting
https://arxiv.org/abs/2311.18677
[6] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
https://arxiv.org/abs/2401.09670
[7] https://zhuanlan.zhihu.com/p/1928005367754884226