【大模型关键技术】Transformer 前沿发展
文章目录
- 前言
- 1. 人工智能发展 - 四阶段技术成果对比
- 2. Transformer 背景
- 3. 注意力模型
- 3.1 注意力模型对 Encoder-Decoder 网络的改进
- 3.2 Encoder-Decoder 架构 (本质还是 RNN)
- 3.3 上下文向量与注意力权重
- 3.4 算法抽象 - 核心公式
- 4. Transformer 核心
- 4.1 模型概述
- 4.2 自注意力机制(Self-Attention)
- 4.3 位置编码
- 4.4 Add(残差连接)& Norm(层归一化)
- 5. 传统模型 v.s. 大模型
- 6. 前沿技术点
前言
本文作为大模型学习笔记,阅读前需要具备深度学习基础知识,知识大纲可参考:
【神经网络概述】从感知机到深度神经网络(CNN & RNN)
1. 人工智能发展 - 四阶段技术成果对比
| 阶段 | 时间 | 代表性技术成果 | 数据规模 | 技术栈 |
|---|---|---|---|---|
| 弱人工智能 | 1950-1990 | 基于人工设计的规则系统 | 数百规则集 | 基于专家知识和规则的系统 |
| 统计机器学习 | 1990-2012 | HMM, CTF, SVM 反向传播,卷积网络 | 百万级标注数据 | 统计机器学习算法+算法包 (scikit-learn, XGBoost) |
| 深度学习 | 2013-2018 | AlexNet, GoogLeNet, ResNet, Transformer | 十亿级标注数据 | 深度神经网络+开发框架 (TensorFlow, PyTorch) |
| 大语言模型 | 2018-至今 | GPT-4, LLaMA, Claude DeepSeek, Qwen | 全网万亿数据 干亿用户反馈 | 预训练 +微调 +混合专家模型 (MoE) +强化学习 (RL) (HuggingFace, DeepSpeed) |
2. Transformer 背景
- 开山之作:Neural Network Language Model (NNLM)- 2003,语言模型从统计学->深度学习
- 架构基础:Sequence to Sequence Learning with Neural Networks - 2014,提出经典 seq2seq 架构
- 首次应用:Neural Machine Translation by Jointly Learning to Align and Translate - 2014,机器翻译中应用注意力机制
- 问世:Attention is All You Need - 2017,提出 Transformer 架构
3. 注意力模型
3.1 注意力模型对 Encoder-Decoder 网络的改进
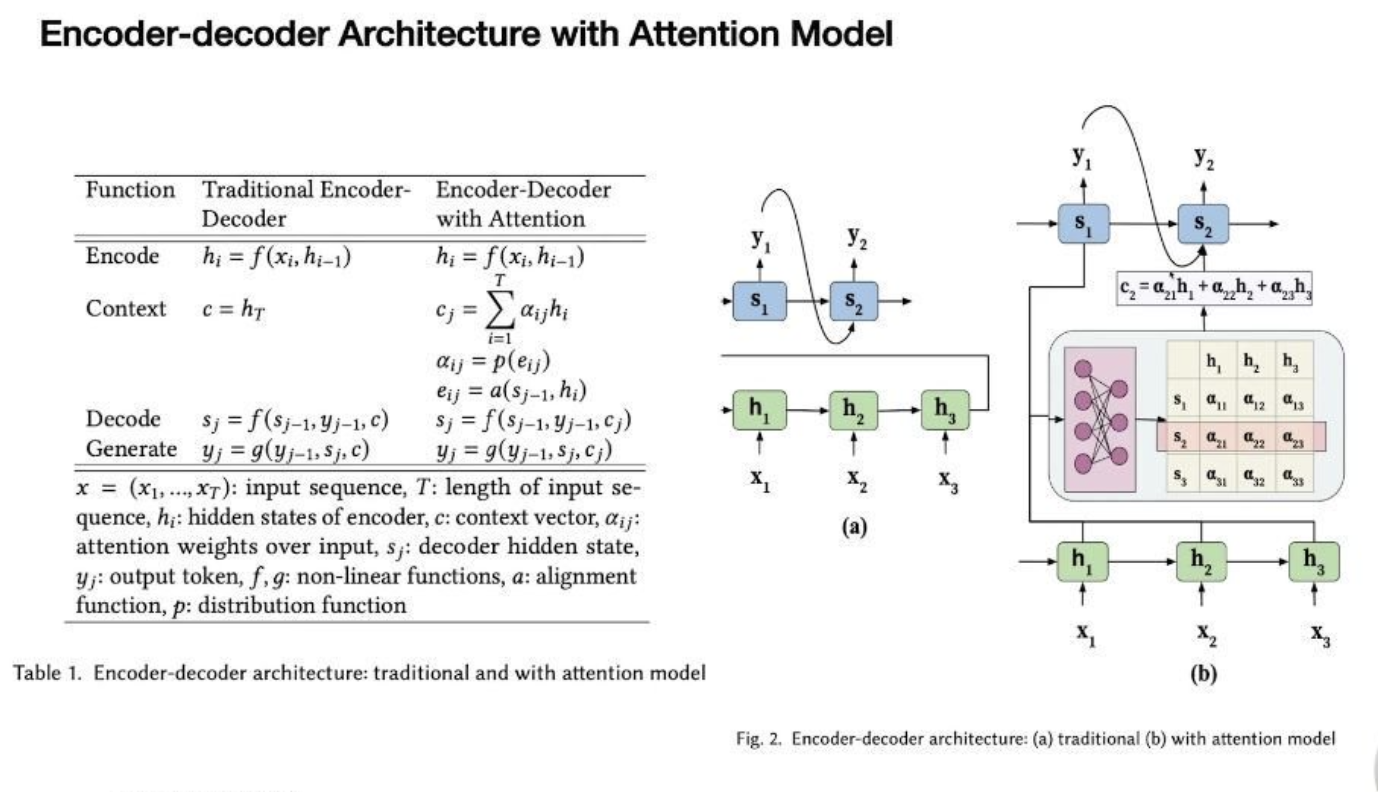
- 结构变化:
- 传统结构:解码器仅接收前序状态 sj−1s_{j-1}sj−1 和输出 yj−1y_{j-1}yj−1
- 注意力结构:新增上下文向量 cj=∑αijhic_j=\sum\alpha_{ij}h_icj=∑αijhi 作为输入
- 功能实现:通过注意力权重 αij\alpha_{ij}αij 动态决定各编码器状态 hih_ihi 的重要性
- 局限性:传统注意力模型是单向翻译模型(如法→英),无法逆向工作(英→法)。本质原因是注意力权重随输入输出位置变化,query 和 key 互换后模型失效
3.2 Encoder-Decoder 架构 (本质还是 RNN)
- 数学表达
- 编码器:hi=f(xi,hi−1)h_i = f(x_i, h_{i-1})hi=f(xi,hi−1)
- 解码器:sj=f(sj−1,yj−1,cj)s_j = f(s_{j-1}, y_{j-1}, c_j)sj=f(sj−1,yj−1,cj)
- 输出:yj=g(yj−1,sj,cj)y_j = g(y_{j-1}, s_j, c_j)yj=g(yj−1,sj,cj)
- 参数说明:
- x=(x1,...,xT)x=(x_1,...,x_T)x=(x1,...,xT):输入序列
- hih_ihi:编码器隐藏状态
- cjc_jcj:上下文向量
- αij\alpha_{ij}αij:注意力权重
3.3 上下文向量与注意力权重
- 算法思想:建立输入输出间的动态关联(如"I’m a student")翻译时重点关联最后一个,训练目标是使相关词对获得更大注意力权重(如 α23\alpha_{23}α23 接近1,其他接近0)
- 计算过程:
- 对齐分数:eij=a(sj−1,hi)e_{ij} = a(s_{j-1}, h_i)eij=a(sj−1,hi)
- 权重归一化:αij=softmax(eij)\alpha_{ij} = \text{softmax}(e_{ij})αij=softmax(eij)
- 上下文生成:cj=∑αijhic_j = \sum\alpha_{ij}h_icj=∑αijhi
- 物理意义:αij\alpha_{ij}αij 表示解码器第j步对编码器第i步的“关注程度”
- 对齐函数与分布函数
- 对齐函数:
- 作用:建立 query(解码器状态)与 key(编码器状态)的关联
- 实现:a(k,q) 计算相似度,常用点积、加性等方法
- 分布函数:
- 必要性:将注意力分数 eije_{ij}eij 归一化为概率分布
- 典型选择:softmax 函数确保 ∑αij=1\sum\alpha_{ij}=1∑αij=1
- 对齐函数:
3.4 算法抽象 - 核心公式
A(q,K,V)=∑ip(a(ki,q))∗viA(q,K,V) = \sum_i p(a(k_i,q)) * v_iA(q,K,V)=∑ip(a(ki,q))∗vi
- 参数解释:
- q:查询向量(当前解码需求)
- K:键矩阵(编码器状态集合)
- V:值矩阵(实际输入特征)
- 计算流程:
- 计算 query 与各 key 的相似度 a(ki,q)a(k_i,q)a(ki,q)
- 通过 softmax 获得注意力分布 p(a(ki,q))p(a(k_i,q))p(a(ki,q))
- 加权求和得到上下文表示
4. Transformer 核心
4.1 模型概述
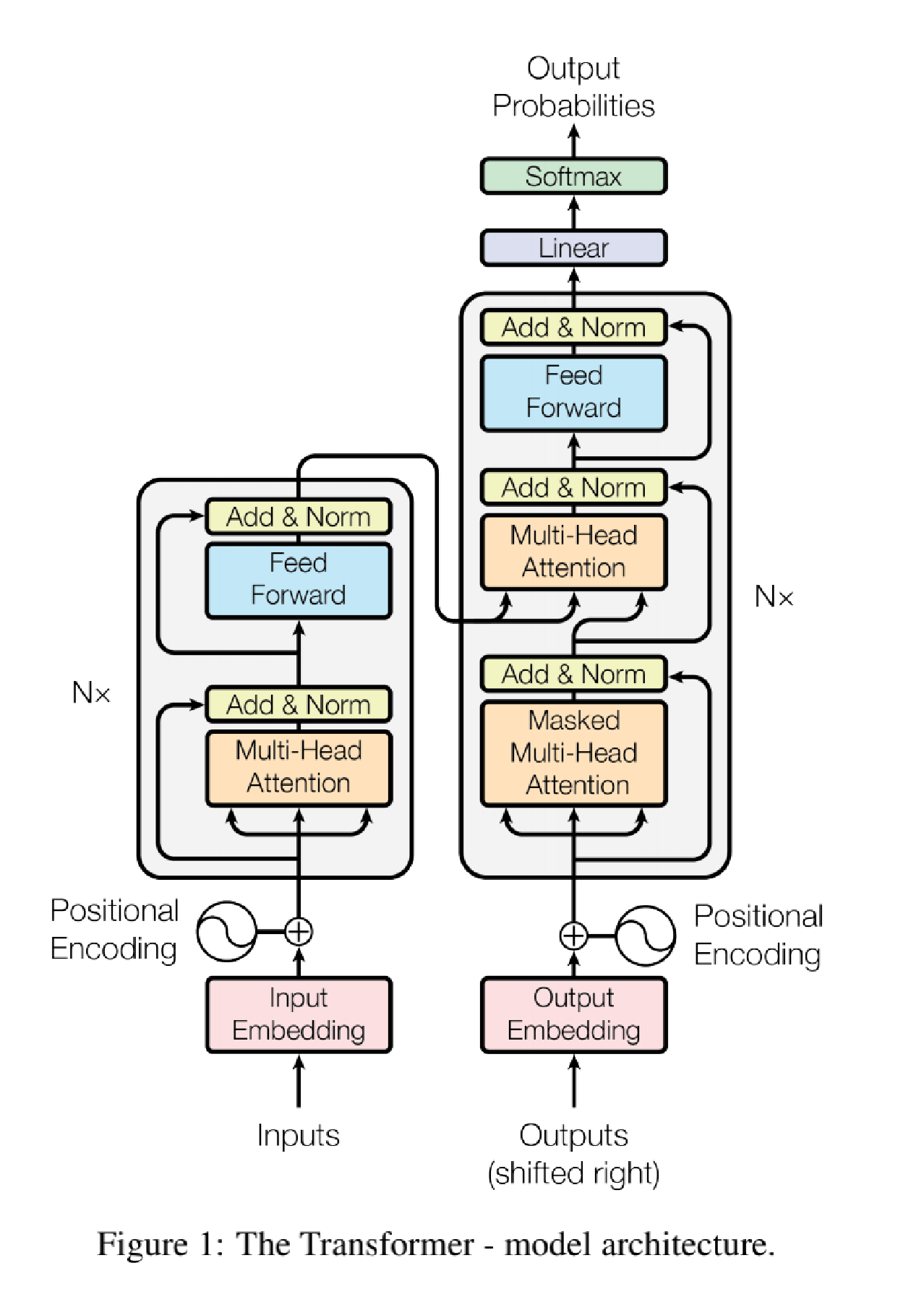
训练目标
让模型通过端到端学习,学会从源序列生成语义一致的目标序列。
训练步骤
- 数据预处理
构建 “源 - 目标” 序列对,转换为 token 索引并对齐长度(填充 / 截断)。
生成词嵌入 + 位置编码,作为编码器和解码器的输入。 - 前向传播
- 编码器:对源序列进行多层编码(多头自注意力 + 前馈网络 + 残差归一化),输出含全局上下文的特征矩阵。
- 解码器:对目标序列进行多层解码(Masked 自注意力避免未来信息泄露 + Encoder-Decoder 注意力关联源特征 + 前馈网络 + 残差归一化),输出生成特征。
- 经线性层映射到词表维度,得到每个 token 的预测概率。
- 损失计算与优化
以 “右移一位的目标序列” 为标签,计算交叉熵损失(忽略填充 token)。
反向传播计算梯度,经裁剪后用优化器(如 Adam)更新参数。 - 训练调控
迭代训练,通过验证集监控性能(如 BLEU),结合早停和学习率调度(预热 + 衰减)避免过拟合,加速收敛。
4.2 自注意力机制(Self-Attention)
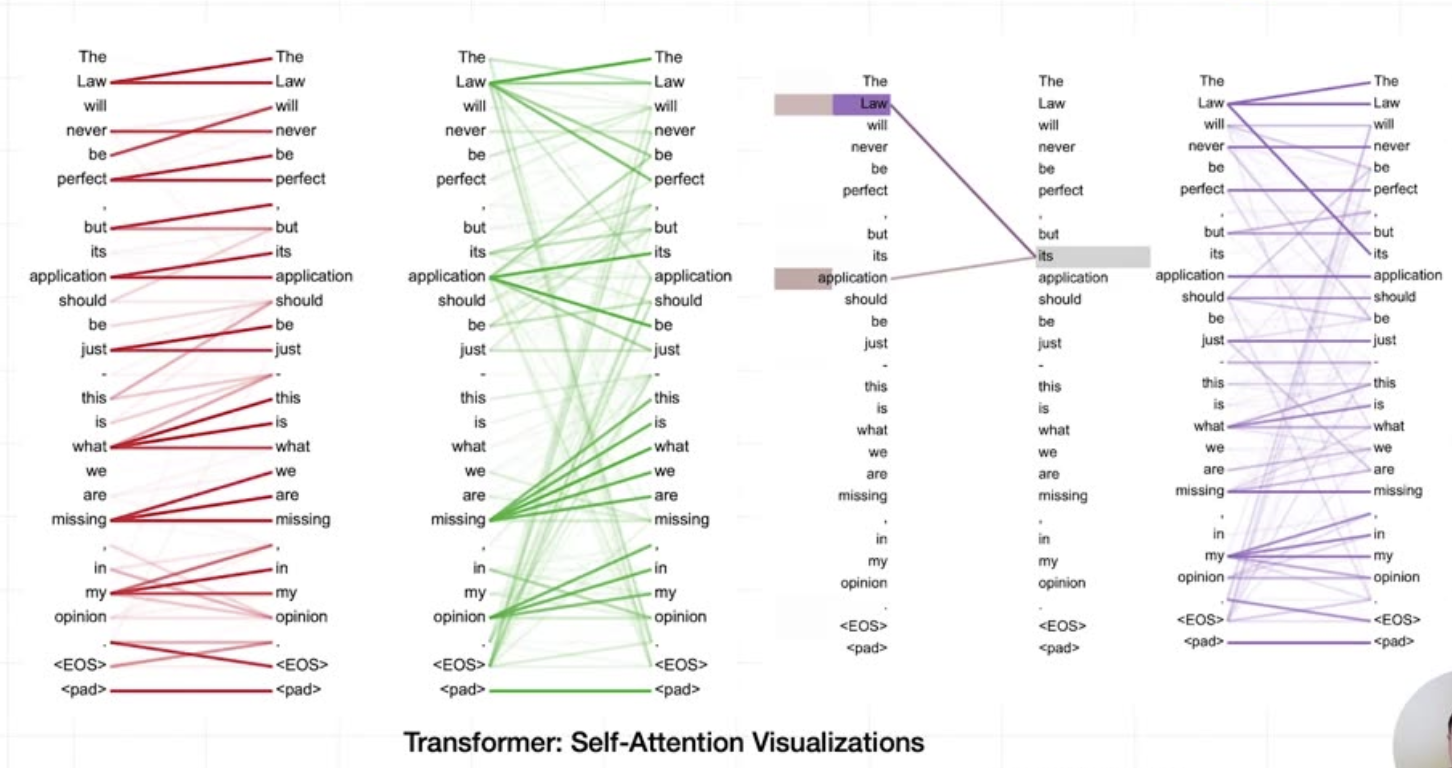
- 核心思想:让序列中的每个元素 “关注” 自身与其他元素的关联程度(如句子中 “its” 与 “Law” 的指代关系),并基于这种关联生成融合上下文的特征表示。其本质是通过 Q-K-V 机制计算注意力权重,实现全局信息的动态聚合。
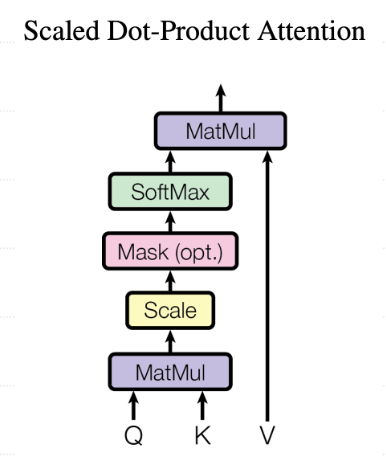
与传统注意力机制的区别:不再处理多语言转换,而是单语言内部语义理解。 - 计算公式:Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dkQKT)V
- 多头注意力:并行计算不同子空间的特征
计算公式:
MultiHead(Q,K,V)=Concat(head1,…,headh)WOMultiHead(Q,K,V)=Concat(head_1,…,head_h)W^OMultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中 headi=Attention(QWiQ,KWiK,VWiV)head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)
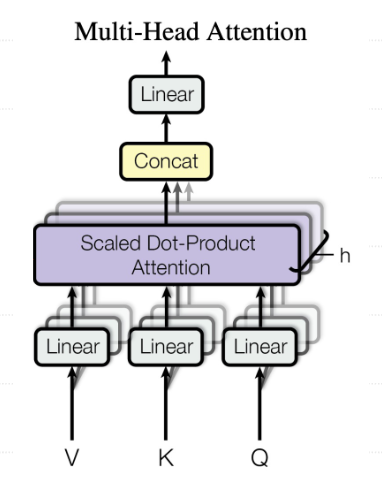
优势:每个注意力头可以学习到不同的 “关注模式”(例如,某头关注语法结构,某头关注语义关联),通过并行计算和融合,模型能捕捉输入序列中多维度的依赖关系,提升对复杂序列的建模能力。
4.3 位置编码
对于输入的文本序列,该模型先使用位置编码方式表示序列的顺序。直观理解就是将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
| 特性 | 固定位置编码 (Absolute PE) | 相对位置编码 (Relative PE) | 旋转位置编码 (RoPE) |
|---|---|---|---|
| 代表方法 | Transformer 的 sin/cos 编码 | T5 的注意力偏置、 ALiBi (如MPT, BLOOM) | DeepSeek-V2/V3, Qwen, LLaMA |
| 核心思想 | 为每个绝对位置生成固定编码,直接加到词嵌入上 | 通过注意力分数中的偏置项(bias)建模相对位置关系 | 通过旋转矩阵变换 Query/Key,隐式编码相对位置 |
| 位置信息类型 | 绝对位置 | 相对位置 | 相对位置 |
| 外推性 | 弱(超出训练长度需微调) | 中等(ALiBi外推较好) | 强(支持超长上下文,如128K) |
| 计算复杂度 | 低(预计算固定编码) | 中等(需计算/存储偏置矩阵) | 低(融合到Q/K计算中) |
| 显存占用 | 低(固定编码表) | 中等(偏置矩阵随序列长度增长) | 低(无额外参数) |
| 优点 | 简单易实现,适合短文本 | 显式建模相对位置,适合任务如机器翻译 | 长文本友好,泛化性强,兼容高效注意力优化(如 FlashAttention) |
| 缺点 | 难以泛化到更长序列 | 偏置项设计需人工干预(如 ALiBi 的线性衰减) | 旋转计算可能增加少量开销(但可优化) |
4.4 Add(残差连接)& Norm(层归一化)
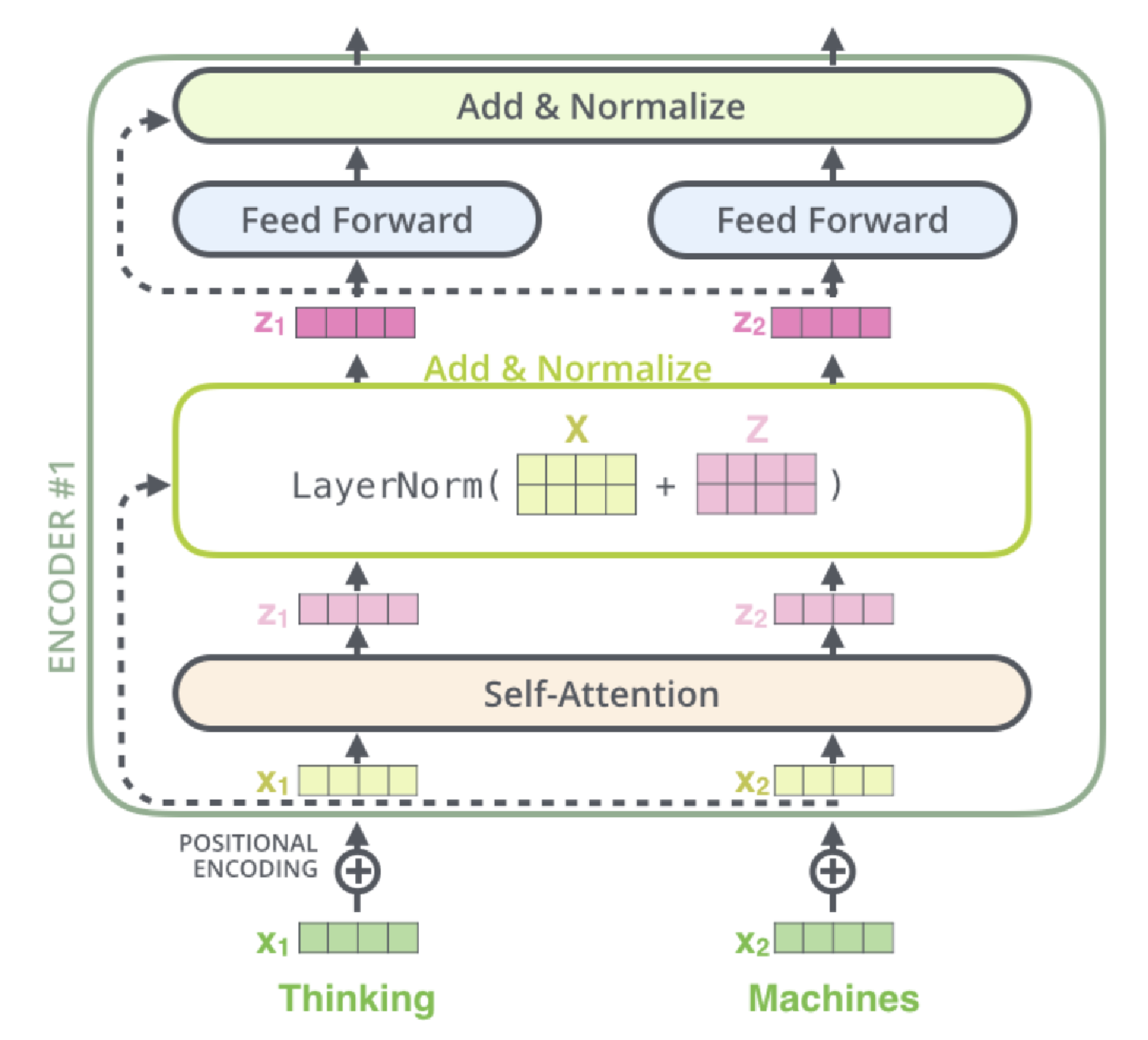
Add & Norm 是保障 Transformer 能训练深层网络的关键设计:
- Add(残差连接):缓解深层网络的梯度消失问题,让模型更容易学习 “输入与输出的差异”。将当前层的输入与该层的处理结果(如自注意力输出)逐元素相加:AddOutput=Input+SelfAttentionOutputAdd_{Output} = Input + SelfAttention_{Output}AddOutput=Input+SelfAttentionOutput
- Norm(层归一化):稳定每一层的输入分布,加速训练收敛,避免某一维度的特征值过大主导学习。
对残差连接的输出进行层归一化:
○ 计算该层所有样本在特征维度上的均值 μ\muμ 和方差 σ2\sigma^2σ2:
μ=1dmodel∑i=1dmodelxi,σ2=1dmodel∑i=1dmodel(xi−μ)2\mu=\frac1{d_{model}}\sum_{i=1}^{d_{model}}x_i, \sigma^2=\frac1{d_{model}}\sum_{i=1}^{d_{model}}(x_i-\mu)^2μ=dmodel1∑i=1dmodelxi,σ2=dmodel1∑i=1dmodel(xi−μ)2
○ 对每个特征进行归一化(加入微小 ε\varepsilonε 避免分母为 0):
xi^=xi−μσ2+ε\hat{x_i}=\frac{x_i-\mu}{\sqrt{\sigma^2+\varepsilon}}xi^=σ2+εxi−μ
○ 通过可学习的缩放参数 γ\gammaγ 和偏移参数 β\betaβ 调整分布:
NormOutput=γ⋅x^i+βNorm_{Output} = \gamma \cdot \hat{x}_i + \betaNormOutput=γ⋅x^i+β
5. 传统模型 v.s. 大模型
| 维度 | 传统模型 | 大模型 |
|---|---|---|
| 规模量级 | 几千-几百万参数 | 几十亿-万亿级 |
| 训练范式 | 任务驱动 | 三阶段(预训练、微调、后训练) |
| 训练成本(时间、算力) | 成本可控 | 成本高昂 |
| 能力与表现 | 专注特定领域,难以泛化 性能有上限 | 涌现能力 性能符合 Scaling Laws |
| 开发哲学 | ⼿⼯作坊模式 | 工业化平台模式 |
- 人工智能三大核心:数据、算力、算法
- 大模型发展两阶段
- 上半场:知识驱动(如GPT)
- 下半场:推理驱动(如DeepSeek R1)
6. 前沿技术点
- 稀疏注意力机制
- 在处理⻓序列时,降低计算复杂度,尽可能保留模型捕捉⻓距离依赖的能⼒。
- 不再让每个词都关注序列中的所有其他词,⽽是只关注序列中经过精⼼选择的⼀⼩部分词。
- 混合专家模型(MoE):动态路由机制
- 模型压缩与量化
- 模型剪枝 (Pruning): 移除模型中不重要的参数(权重、连接、甚至神经元)。
- 模型量化 (Quantization): 降低模型参数和计算的数值精度。
- 知识蒸馏 (Knowledge Distillation): 用大模型的输出/行为指导训练一个小模型。
- 网络结构搜索 (NAS) / 低秩分解 (Low-Rank Factorization) 等。