用生成模型解开视网膜图像的表征|文献速递-医学影像算法文献分享
Title
题目
Disentangling representations of retinal images with generative models
用生成模型解开视网膜图像的表征
01
文献速递介绍
视网膜眼底图像是一种医学图像,它能捕捉眼睛后部的情况,显示出视网膜、视盘、黄斑和血管。由于这类图像是通过瞳孔拍摄的彩色照片,获取成本低、无侵入性且速度快,因此即使在资源有限的地区也能使用。尽管视网膜眼底图像获取便捷,但借助深度学习技术,它们不仅可用于检测眼部疾病,还能用于发现心血管风险因素或神经系统疾病(Poplin 等人,2018;Kim 等人,2020;Rim 等人,2020;Son 等人,2020;Sabanayagam 等人,2020;Xiao 等人,2021;Rim 等人,2021;Nusinovici 等人,2022;Cheung 等人,2022;Tseng 等人,2023)。 然而,深度学习模型需要大量数据集,而大型医学影像队列往往具有异质性,技术混杂因素普遍存在。对于眼底图像而言,相机类型、瞳孔 dilation、图像质量和光照水平的差异都会影响图像生成。此外,不同医院以及患者研究选择带来的偏差,可能导致这些因素与数据中的生物学变异形成虚假的特征关联。深度学习模型可能会基于这种虚假关联学习到“捷径”(Geirhos 等人,2020),而非特定的与患者相关的图像特征(图 1a)。结果是,这些模型可能仅在与训练数据分布相同的情况下表现良好,且潜在空间分析可能会产生误导(Müller 等人,2022)。例如,某视网膜影像数据集可能来自两家医院,这两家医院使用的相机由不同制造商生产(Fay 等人,2023)。相机 A 拍摄的图像在色调上与相机 B 存在差异。第一家医院接诊的患者以拉丁美洲人为主,而第二家医院接诊的患者以白种人为主。在这种情况下,深度学习模型通过识别色调来推断患者的种族,比理解种族与表型图像特征之间隐藏的因果关系要容易得多(Castro 等人,2020)。 解决数据混杂因素的一种方法是子空间学习,它将表征学习与解耦相结合。在我们的研究中,我们基于因果图构建了潜在子空间,充分利用了关于影响图像生成过程因素的领域知识(Castro 等人,2020)。我们使用了一个简化的因果模型,将眼底图像生成分为三个因果变量:患者属性(B)、相机(C)和风格(D)(图 1a)。在因果表征学习和图像生成的相关文献中,风格特征被认为是与内容特征(在我们的案例中为 B 和 C)无关的信息(Yao 等人,2024b;Havaei 等人,2021)。由于存在未知的混杂因素(A),我们假设 B、C 和 D 之间存在统计关联,尽管它们并非直接存在因果关系。这种关联可能会导致由虚假相关驱动的“捷径”连接,特别是在患者属性(如种族)和技术因素(如相机)等因素之间(图 1a)。为了防止模型学习“捷径”,我们通过将这些变异因素编码到统计独立的潜在子空间中,来对它们进行解耦(Bengio 等人,2013;Higgins 等人,2018)。 获取解耦表征的一种常见策略是使用生成式图像模型,如变分自编码器(VAEs)(Kingma 和 Welling,2014)。生成模型通过从潜在空间重建图像,为表征学习提供了有价值的归纳偏置,并且可以扩展以学习独立的子空间(图 1b)(Higgins 等人,2017;Klys 等人,2018;Tschannen 等人,2018)。以往的方法主要侧重于实现解耦的潜在空间,往往忽略了同时追求高质量图像生成这一目标。然而,当同时处理潜在空间解耦和图像生成问题时,生成式图像模型通过图像空间中可控的特征变化,提供了一种内置的解释方法(图 1d)。 在这项研究中,我们填补了眼底图像领域中生成式解耦表征学习与高质量图像生成相结合方面的空白。我们的贡献有三个方面: 1. 在最先进的生成对抗模型中,利用基于距离相关性的解耦损失函数对潜在子空间进行解耦。 2. 开发一种能够端到端地联合优化解耦和可控高分辨率图像生成的方法。 3. 运用定量和定性方法,对解耦效果、图像质量和可控图像生成进行广泛分析,以评估我们提出的解耦损失函数的有效性。
Abatract
摘要
Retinal fundus images play a crucial role in the early detection of eye diseases. However, the impact of technicalfactors on these images can pose challenges for reliable AI applications in ophthalmology. For example, largefundus cohorts are often confounded by factors such as camera type, bearing the risk of learning shortcutsrather than the causal relationships behind the image generation process. Here, we introduce a populationmodel for retinal fundus images that effectively disentangles patient attributes from camera effects, enablingcontrollable and highly realistic image generation. To achieve this, we propose a disentanglement loss basedon distance correlation. Through qualitative and quantitative analyses, we show that our models encodedesired information in disentangled subspaces and enable controllable image generation based on the learnedsubspaces, demonstrating the effectiveness of our disentanglement loss.
视网膜眼底图像在眼部疾病的早期检测中起着至关重要的作用。然而,技术因素对这些图像的影响可能给眼科领域中可靠的人工智能应用带来挑战。例如,大型眼底图像队列往往会受到相机类型等因素的干扰,这使得模型可能学习到捷径,而非图像生成过程背后的因果关系。 在此,我们提出了一种视网膜眼底图像的群体模型,该模型能有效将患者属性与相机效应分离开来,从而实现可控且高度逼真的图像生成。为实现这一目标,我们提出了一种基于距离相关性的解耦损失函数。通过定性和定量分析,我们表明所提出的模型能将所需信息编码到解耦的子空间中,并基于学习到的子空间实现可控的图像生成,这证明了我们所提解耦损失函数的有效性。
Background
背景
Deep generative models have demonstrated great success in datageneration and density estimation from observational data, but theyface limitations such as lack of explainability, risk of learning spuriouscorrelations and poor performance on out-of distribution data. Toaddress these challenges, causal models offer several valuable benefits, such as distribution shift robustness, fairness, and interpretability (Schölkopf et al., 2021). The interpretability of causal modelscan be viewed in terms of both learning semantically meaningfulrepresentations of a system and controllably generating realistic counterfactual data. Causal models, particularly Structural Causal Models(SCMs), describe the data-generating processes and the complex causalrelationships between variables, making them a natural complementto generative models (Schölkopf et al., 2021). Causal representationlearning (CRL) focuses on identifying meaningful latent variables andtheir causal structures from high-dimensional data, ensuring the correctidentification of the true generative factors (Schölkopf et al., 2021).In our causal diagram the fundus image (X) is influenced by severalfactors: patient attribute (B), camera (C), and style (D). However, thereis also an unknown confounder (A) that affects all of these factorsand creates a statistical association between the causal variables B,C, D, even though they are not causally related (Castro et al., 2020;Schölkopf et al., 2021). We represent the causal relationships betweenthese variables by a directed acyclic graph (DAG) which implies thefactorization of causal conditionals (Schölkopf et al., 2021):𝑃* (𝑋) = 𝑃 (𝐵|𝐴) ⋅ 𝑃 (𝐶|𝐴) ⋅ 𝑃 (𝐷|𝐴).In theory, the confounder could be addressed by causal interventions,which is not feasible in our setting with only observational data.Therefore, in this work, we address the confounder by disentanglingthe causal variables B, C, D in the latent space of a generative model.Our approach is inspired by our DAG structure, which implies a disentangled factorization of causal conditionals due to the causal Markovcondition (Castro et al., 2020). Regarding CRL, our causal variables Band C are identifiable because of the invariance principle introducedin Yao et al. (2024a). For these variables, we use labels togetherwith linear classifiers to enforce content encoding in latent subspaces.Intuitively, with our subspace classifiers we force images with thesame label to have the same content latent subspaces. Identifyingthe style variable (D) is more complicated, but we can use Corollary3.9–3.11 from (Yao et al., 2024b) to identify style, assuming that it isindependent of the content variables B and C.
因果背景 深度生成模型在从观测数据中进行数据生成和密度估计方面已取得显著成功,但它们存在一些局限性,例如缺乏可解释性、存在学习虚假关联的风险以及在分布外数据上表现不佳等。为解决这些挑战,因果模型具有诸多宝贵优势,如对分布偏移的稳健性、公平性和可解释性(Schölkopf 等人,2021)。 因果模型的可解释性体现在两个方面:一是学习系统的语义 meaningful 表征,二是可控地生成逼真的反事实数据。因果模型,特别是结构因果模型(SCMs),能够描述数据生成过程以及变量之间复杂的因果关系,因此成为生成模型的天然补充(Schölkopf 等人,2021)。因果表征学习(CRL)专注于从高维数据中识别有意义的潜在变量及其因果结构,确保正确识别真实的生成因素(Schölkopf 等人,2021)。 在我们的因果图中,眼底图像(X)受到多个因素的影响:患者属性(B)、相机(C)和风格(D)。然而,还存在一个未知的混杂因素(A),它会影响所有这些因素,并在因果变量 B、C、D 之间建立统计关联,尽管它们在因果上并无关联(Castro 等人,2020;Schölkopf 等人,2021)。我们通过有向无环图(DAG)来表示这些变量之间的因果关系,这意味着因果条件的因式分解(Schölkopf 等人,2021): [P(X) = P(B|A) \cdot P(C|A) \cdot P(D|A)] 理论上,混杂因素可以通过因果干预来解决,但在我们仅有观测数据的情况下,这一方法并不可行。因此,在本研究中,我们通过在生成模型的潜在空间中解耦因果变量 B、C、D 来处理混杂因素。 我们的方法受 DAG 结构的启发,由于因果马尔可夫条件,该结构意味着因果条件的解耦因式分解(Castro 等人,2020)。关于因果表征学习,基于 Yao 等人(2024a)提出的不变性原理,我们的因果变量 B 和 C 是可识别的。对于这些变量,我们使用标签结合线性分类器,以在潜在子空间中强化内容编码。直观地说,通过子空间分类器,我们迫使具有相同标签的图像拥有相同的内容潜在子空间。 风格变量(D)的识别更为复杂,但假设其与内容变量 B 和 C 相互独立,我们可以利用(Yao 等人,2024b)中的推论 3.9–3.11 来识别风格。
Method
方法
This section introduces the proposed model extensions and trainingconstraints to disentangle representations, prevent shortcut learning,and still enable controllable high-resolution image generation. First, weintroduce the dataset, an encoder model and our disentanglement lossas preliminary steps towards the complete image generation pipeline.4.1. DataWe trained our models on retinal fundus images provided by EyePACS Inc. Cuadros and Bresnick (2009), Eye (2008), an adaptabletelemedicine system for diabetic retinopathy screening from California.All data was anonymized by the data provider. We filtered for healthyfundus images with no reported eye disease which were labeled as‘‘good’’ or ‘‘excellent’’ quality. This resulted in 75,989 macula-centeredretinal fundus images of 24,336 individual patients. For our experiments, we split the data by patient-identity into 60% training, 20%validation, and 20% test sets.
4. 方法 本节介绍了所提出的模型扩展和训练约束,旨在解耦表征、防止“捷径”学习,同时实现可控的高分辨率图像生成。首先,我们将介绍数据集、编码器模型和我们提出的解耦损失函数,作为构建完整图像生成流程的预备步骤。 4.1. 数据 我们在 Eye PACS Inc. 提供的视网膜眼底图像上训练模型(Cuadros 和 Bresnick,2009;Eye,2008),该数据集来自加利福尼亚州一个适用于糖尿病视网膜病变筛查的远程医疗系统。所有数据均由数据提供方进行了匿名化处理。 我们筛选出无眼部疾病报告且质量被标记为“良好”或“优秀”的健康眼底图像,最终得到 75,989 张以黄斑为中心的视网膜眼底图像,来自 24,336 名独立患者。在实验中,我们按患者身份将数据分为 60% 的训练集、20% 的验证集和 20% 的测试集。
Results
结果
We conducted empirical evaluations to assess the efficacy of ourdisentanglement loss in two distinct scenarios: (1) a predictive taskand (2) a generative task, both performed on retinal fundus images.Our primary objective in both cases was to disentangle camera as atechnical factor from the patient attributes age and ethnicity.To evaluate the success, we defined a quantitative measure ofdisentanglement. While there is no universally accepted definitionof disentanglement, most agree on two main points (Eastwood andWilliams, 2018; Carbonneau et al., 2022): (1) factor independenceand (2) information content. Factor independence means that a factoraffects only a subset of the representation space, and only this factoraffects this subspace. We refer to this property as modularity. Asanother criterion for factor independence some argue that the affectedrepresentation space by a factor should be as small as possible, aprinciple known as compactness. The second agreed-upon criterionis the information content or explicitness. In essence, a disentangledrepresentation should completely describe all factors of interest. Toassess disentanglement, three distinct families of metrics have beenproposed: intervention-based, predictor-based, and information-basedmetrics (Carbonneau et al., 2022).
我们通过实证评估来检验所提出的解耦损失函数在两种不同场景下的有效性:(1)预测任务;(2)生成任务,这两项任务均在视网膜眼底图像上进行。在这两种情况下,我们的主要目标是将作为技术因素的相机(特征)与患者的年龄和种族属性(特征)解耦。 为评估解耦是否成功,我们定义了一种定量的解耦度量方法。尽管目前对于解耦尚无公认的定义,但大多数研究在两个主要方面达成共识(Eastwood 和 Williams,2018;Carbonneau 等人,2022):(1)因素独立性;(2)信息内容。因素独立性是指一个因素仅影响表征空间的一个子集,且只有该因素会影响这个子空间。我们将这一特性称为模块性。作为因素独立性的另一评判标准,有人认为一个因素所影响的表征空间应尽可能小,这一原则被称为紧凑性。第二个公认的标准是信息内容或明确性。本质上,解耦后的表征应能完整描述所有感兴趣的因素。 为评估解耦效果,已提出三类不同的度量方法:基于干预的度量、基于预测器的度量和基于信息的度量(Carbonneau 等人,2022)。
Figure
图
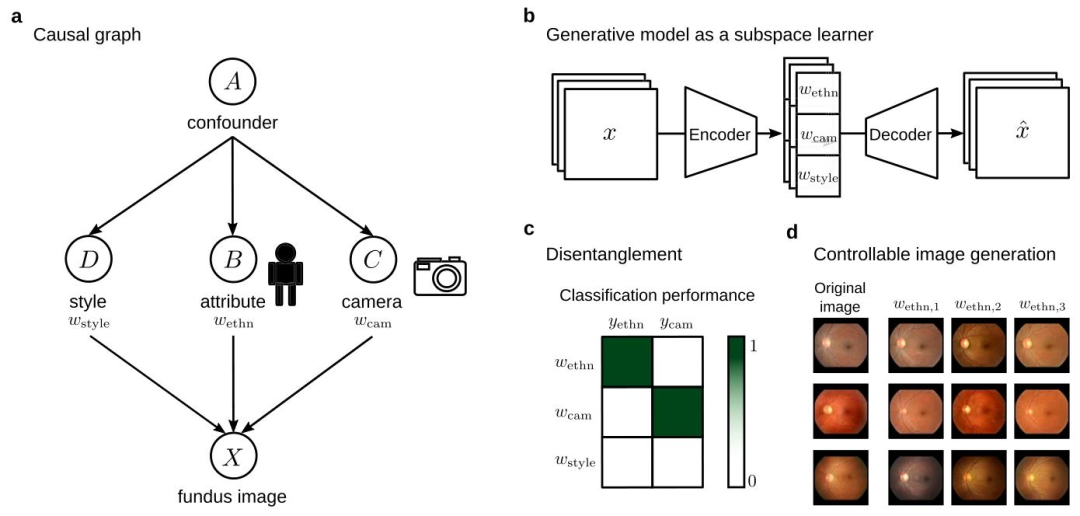
Fig. 1. Disentangling representations of retinal images with generative models. In panel a, we present our conceptual causal graph outlining the image generation process.Within this framework, we break down retinal fundus image generation into the causal variables patient attribute (B), camera (C), and style (D) and highlight an unknownconfounder (A), which can lead to shortcut connections for deep learning models. In panel b, we introduce a strategy to prevent shortcut learning by using a generative modelas an independent subspace learner. Panel c shows our metric for disentanglement: an ideal confusion matrix between the available labels (columns) and the learned subspaces(rows). Panel d shows controllable fundus image generation from swapped ethnicity subspaces.
图1. 利用生成模型解耦视网膜图像的表征 在面板a中,我们展示了描述图像生成过程的概念性因果图。在此框架内,我们将视网膜眼底图像的生成分解为患者属性(B)、相机(C)和风格(D)这三个因果变量,并强调了一个未知的混杂因素(A),该因素可能导致深度学习模型形成“捷径”连接。 面板b介绍了一种通过使用生成模型作为独立子空间学习器来防止“捷径”学习的策略。 面板c展示了我们的解耦度量:可用标签(列)与学习到的子空间(行)之间的理想混淆矩阵。 面板d展示了通过交换种族子空间实现的可控眼底图像生成。
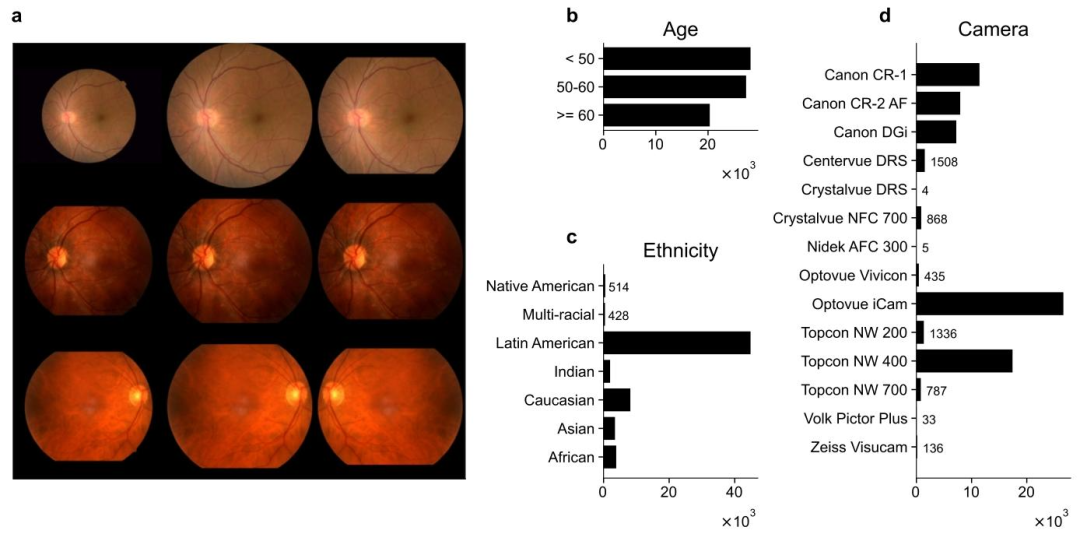
Fig. 2. Image preprocessing and data distribution. In panel a, we outline our two-step preprocessing of fundus images. The first column displays original samples from thetraining set, while the second column shows images tightly cropped around the fundus circle. In the third column, we further cropped and flipped the images for consistency. Thecorresponding label distributions are visualized as histogram plots in panels b–d. Specifically, panel b illustrates the age group distribution across three classes, panel c shows theethnicity distribution, and panel d presents the camera distribution.
图2. 图像预处理与数据分布 在面板a中,我们展示了眼底图像的两步预处理流程。第一列是训练集中的原始样本,第二列是围绕眼底圆形区域进行紧密裁剪后的图像,第三列是经过进一步裁剪和翻转以保证一致性的图像。 面板b–d中以直方图形式展示了相应的标签分布:具体而言,面板b显示了三个年龄段的分布情况,面板c为种族分布,面板d则呈现了相机分布。
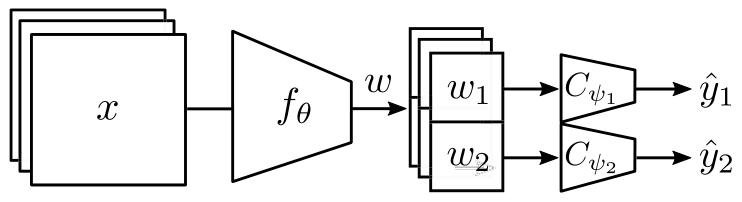
Fig. 3. Encoder architecture. Feature encoder 𝑓𝜃 encodes input images 𝑥 to featurevectors 𝑤. Each feature vector is split into two subspaces 𝑤1 and 𝑤2 by classificationheads 𝐶𝜓1and 𝐶𝜓2
图3. 编码器架构 特征编码器(f{\theta})将输入图像(x)编码为特征向量(w)。每个特征向量通过分类头(C{\psi_1})和(C_{\psi_2})被分割为两个子空间(w_1)和(w_2)。
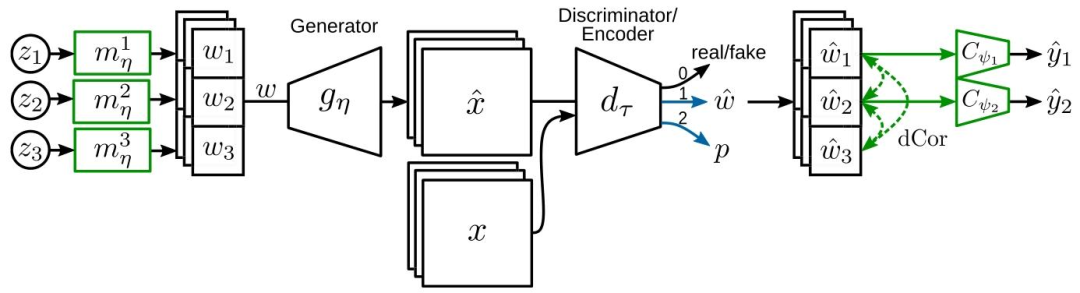
Fig. 4. Generative image model with subspace constraints. For each image, we sample three individual latent codes from a standard normal distribution 𝑧𝑘 ∼ (0, 𝐼𝑑𝑘) andmap them to intermediate latent spaces. The concatenation of all three subspaces 𝑤 = [𝑤1 , 𝑤2 , 𝑤3 ] ∈ R𝑑1+𝑑2+𝑑3 serves as input to the generator 𝑔𝜂 ∶ → . For GAN-inversion, weextend our discriminator with two additional heads: one for latent representation 𝑤̂ and another for a pixel feature vector 𝑝 for image encoding and pixel space reconstruction,respectively. For subspace learning, we introduce individual mapping networks for each subspace and incorporate label information for real images through classification heads.To prevent subspace correlation, we add a penalty to the classification tasks using the average distance correlation (dCor) between the subspaces 𝑤̂ 𝑘
图4. 带 subspace 约束的生成图像模型 对于每张图像,我们从标准正态分布(z{k} \sim \mathcal{N}(0, I{d{k}}))中采样三个独立的潜在编码,并将其映射到中间潜在空间。所有三个子空间的拼接(w = [w{1}, w{2}, w{3}] \in \mathbb{R}^{d{1}+d{2}+d{3}})作为生成器(g{\eta}: \mathcal{Z} \to \mathcal{X})的输入。 在 GAN 反演中,我们为判别器扩展了两个额外的头:一个用于潜在表征(\hat{w}),另一个用于像素特征向量(p),分别用于图像编码和像素空间重建。 在子空间学习方面,我们为每个子空间引入独立的映射网络,并通过分类头整合真实图像的标签信息。为防止子空间相关性,我们利用子空间(\hat{w}_{k})之间的平均距离相关性(dCor),对分类任务添加惩罚项。
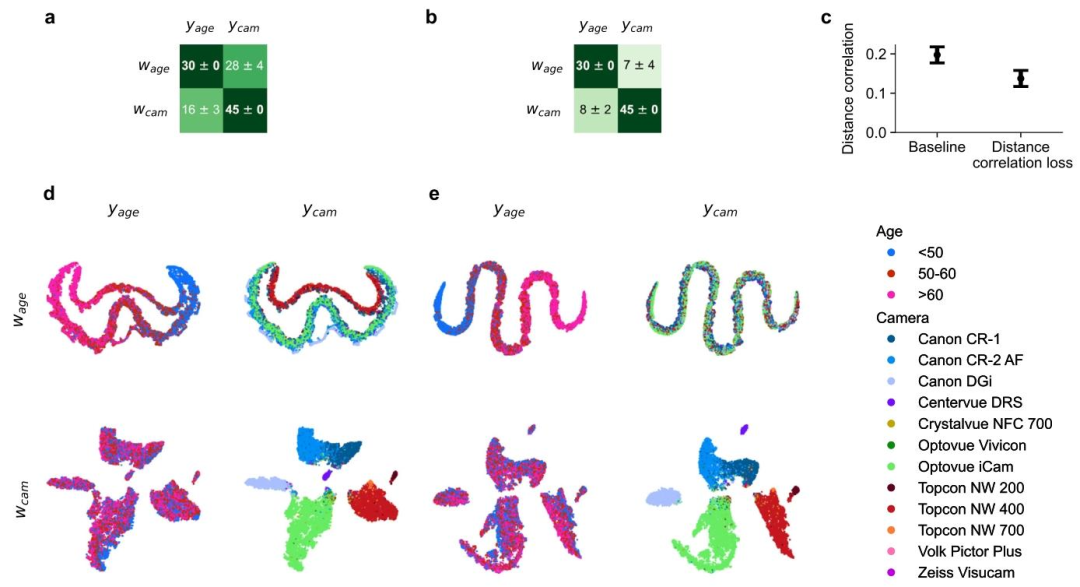
Fig. 5. Encoder disentanglement performance for age-camera setup. We trained encoder models on retinal images, where the first subspace 𝑤age encoded age 𝑦age, and thesecond subspace 𝑤cam encoded camera information 𝑦cam. In panels a and b, we show the accuracy improvement over chance level accuracy. As a baseline model in a, we onlytrained linear classifiers on top of subspaces. In b, we further disentangled the subspaces using our distance correlation loss. Panel c shows the distance correlation measurebetween subspaces for both the baseline method and our proposed method for subspace disentanglement. In panels d and e, we provide t-SNE visualizations comparing a baselinemodel with a model with disentanglement loss, respectively
图5. 年龄-相机设置下的编码器解耦性能 我们在视网膜图像上训练编码器模型,其中第一个子空间(w{\text{age}})对年龄信息(y{\text{age}})进行编码,第二个子空间(w{\text{cam}})对相机信息(y{\text{cam}})进行编码。 面板a和b展示了相较于随机水平准确率的提升情况: - 面板a中的基线模型仅在子空间顶部训练线性分类器; - 面板b中的模型则进一步利用我们提出的距离相关损失函数对两个子空间进行解耦。 面板c显示了基线方法与我们提出的子空间解耦方法中,子空间之间的距离相关性度量结果。 面板d和e分别提供了基线模型与带解耦损失的模型的t-SNE可视化对比。
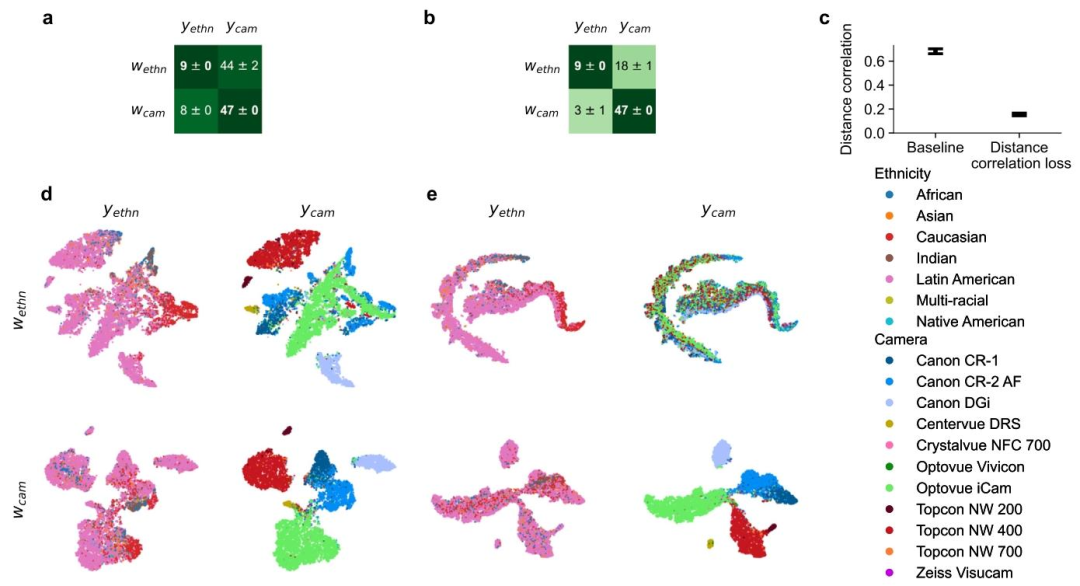
Fig. 6. Encoder disentanglement performance for ethnicity-camera setup. We trained encoder models on retinal images, where the first subspace 𝑤ethn encoded ethnicity𝑦ethn, and the second subspace 𝑤cam encoded camera information 𝑦cam. In panels a and b, we show accuracy improvement over chance level accuracy. As a baseline model in a,we only trained linear classifiers on top of subspaces. In b, we further disentangled the subspaces using our distance correlation loss. Panel c compares the distance correlationmeasure between subspaces of our two model configurations. In panels d and e, we provide t-SNE visualizations comparing a baseline model with a model with disentanglementloss, respectively
图6. 种族-相机设置下的编码器解耦性能 我们在视网膜图像上训练编码器模型,其中第一个子空间(w{\text{ethn}})对种族信息(y{\text{ethn}})进行编码,第二个子空间(w{\text{cam}})对相机信息(y{\text{cam}})进行编码。 面板a和b展示了相较于随机水平准确率的提升情况: - 面板a中的基线模型仅在子空间顶部训练线性分类器; - 面板b中的模型则进一步利用我们提出的距离相关损失函数对两个子空间进行解耦。 面板c对比了两种模型配置(基线模型与带解耦损失的模型)中子空间之间的距离相关性度量结果。 面板d和e分别提供了基线模型与带解耦损失的模型的t-SNE可视化对比。
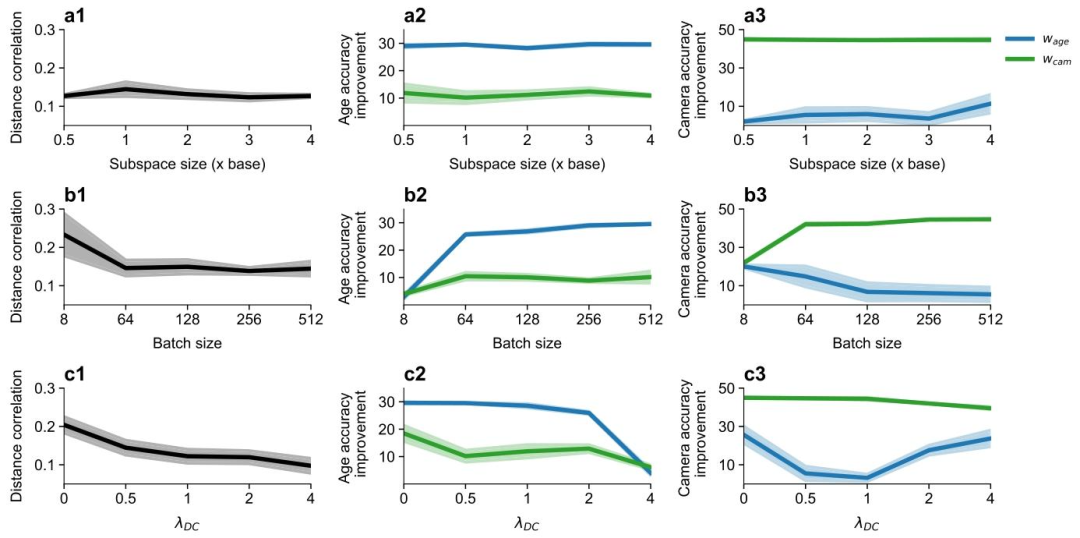
Fig. 7. Impact of hyperparameters on disentanglement performance. In a1–a3, we present performance variations across different subspace sizes. Specifically, a1 illustrates thedistance correlation between subspaces, while a2 and a3 depict the accuracy improvement over chance level for age and camera, respectively. In b1–b3, we examine disentanglementperformance under varying batch sizes. c1–c3 focus on the impact of different distance correlation loss weights on disentanglement performance. We evaluated all metrics on thetest data over four models with different initializations.
图7. 超参数对解耦性能的影响 在a1–a3中,我们展示了不同子空间大小下的性能变化:具体而言,a1说明了子空间之间的距离相关性,a2和a3则分别描述了年龄和相机(任务)相较于随机水平的准确率提升。 在b1–b3中,我们考察了不同批次大小下的解耦性能。 c1–c3重点分析了不同距离相关损失权重对解耦性能的影响。 我们基于测试数据,通过4个具有不同初始化参数的模型对所有指标进行了评估。
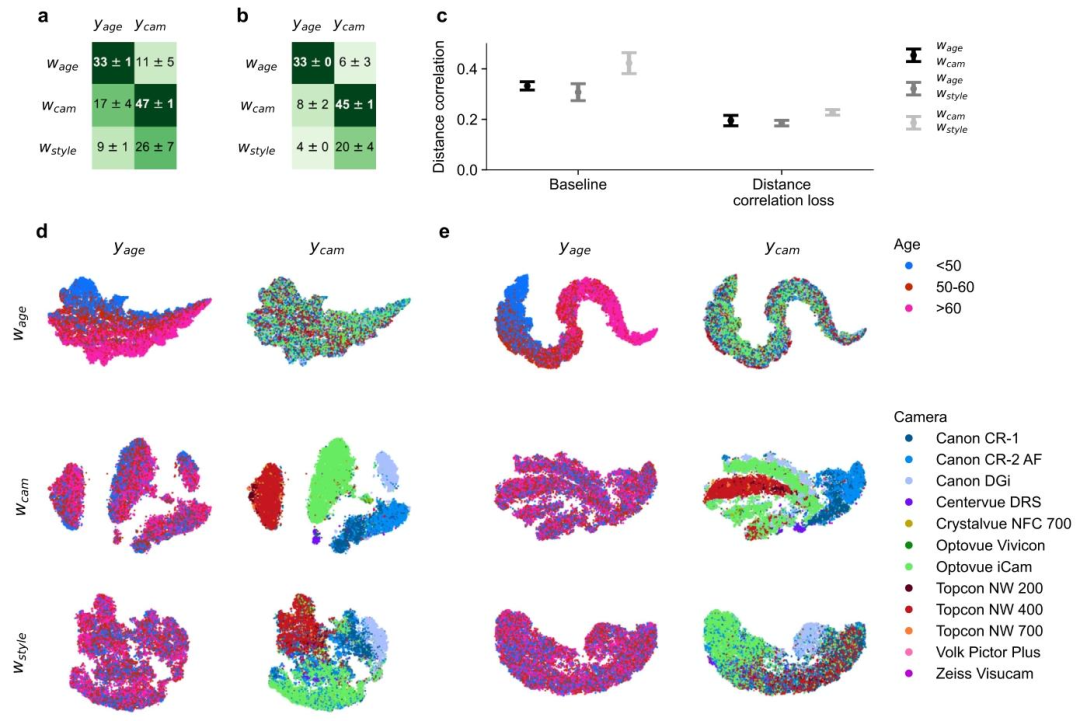
Fig. 8. Disentanglement performance for age-camera setup. We trained generative models on retinal images, featuring three subspaces: 𝑤age encoding the age class 𝑦age, 𝑤camencoding the camera class 𝑦cam, and 𝑤style serving as a style subspace. In a and b, we report kNN classifier accuracy improvement over chance level accuracy. The baseline modelin a involved training linear classifiers on the first two subspaces. In b, we additionally disentangled the subspaces using our distance correlation loss. Panel c compares thedistance correlation measure between subspaces of our two model configurations. Panels d and e present t-SNE visualizations of one baseline model and one trained generativemodel with the disentanglement loss, respectively
图8. 年龄-相机设置下的解耦性能 我们在视网膜图像上训练生成模型,该模型包含三个子空间:对年龄类别(y{\text{age}})进行编码的(w{\text{age}})、对相机类别(y{\text{cam}})进行编码的(w{\text{cam}}),以及作为风格子空间的(w_{\text{style}})。 面板a和b报告了kNN分类器相较于随机水平准确率的提升情况: - 面板a中的基线模型在头两个子空间上训练线性分类器; - 面板b中的模型则额外利用我们提出的距离相关损失函数对这些子空间进行解耦。 面板c对比了两种模型配置(基线模型与带解耦损失的模型)中子空间之间的距离相关性度量结果。 面板d和e分别呈现了一个基线模型和一个带解耦损失的训练生成模型的t-SNE可视化结果。
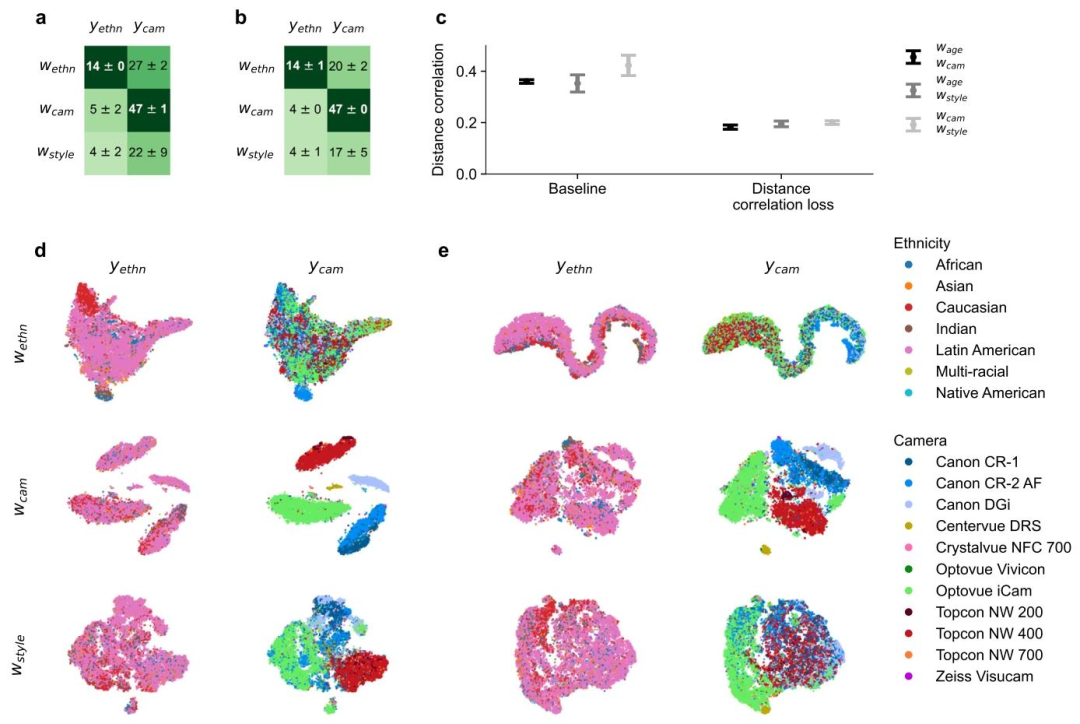
Fig. 9. Disentanglement performance for ethnicity-camera setup. We trained generative models on retinal images, featuring three subspaces: 𝑤ethn encoding the ethnicity class𝑦*ethn, 𝑤cam encoding the camera class 𝑦cam, and 𝑤style serving as the style subspace. In a and b, we report kNN classifier accuracy improvement over chance level accuracy. Thebaseline model in a involved training linear classifiers on the first two subspaces. In b, we additionally disentangled the subspaces using our distance correlation loss. Panel ccompares the distance correlation measure between subspaces of our two model configurations. Panels d and e present t-SNE visualizations of one baseline model and one trainedgenerative model with the disentanglement loss, respectively
图9. 种族-相机设置下的解耦性能 我们在视网膜图像上训练生成模型,该模型包含三个子空间:对种族类别(y{\text{ethn}})进行编码的(w{\text{ethn}})、对相机类别(y{\text{cam}})进行编码的(w{\text{cam}}),以及作为风格子空间的(w_{\text{style}})。 面板a和b报告了kNN分类器相较于随机水平准确率的提升情况: - 面板a中的基线模型在头两个子空间上训练线性分类器; - 面板b中的模型则额外利用我们提出的距离相关损失函数对这些子空间进行解耦。 面板c对比了两种模型配置(基线模型与带解耦损失的模型)中子空间之间的距离相关性度量结果。 面板d和e分别呈现了一个基线模型和一个带解耦损失的训练生成模型的t-SNE可视化结果。
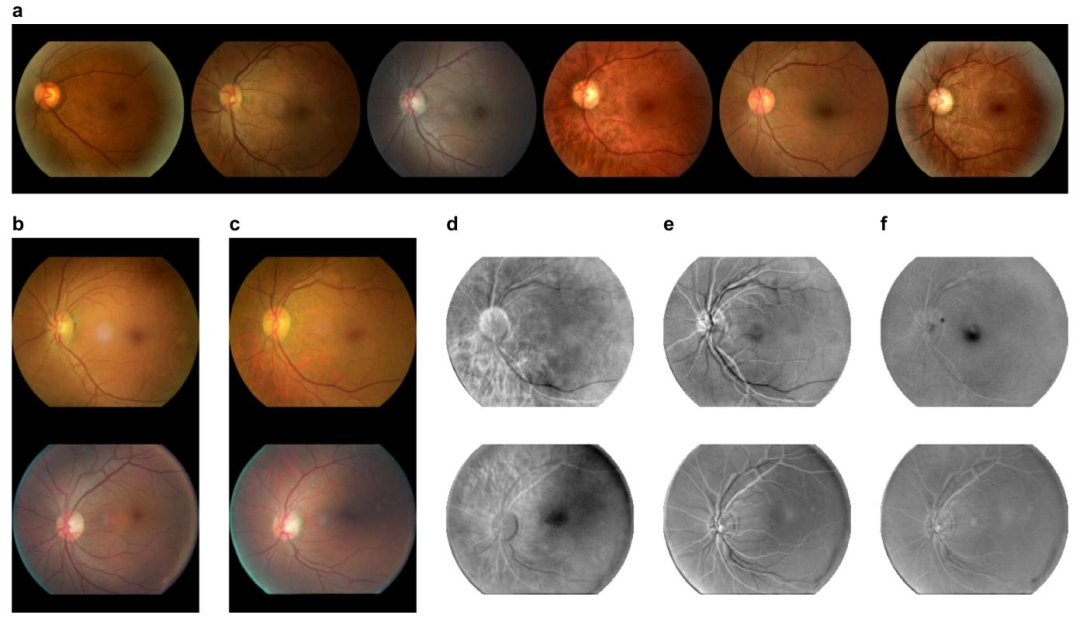
Fig. 10. Qualitative image generation and inversion performance. We present a qualitative assessment of image generation performance for one model of configuration (C)(Table 1). In panel a, we show images generated from randomly sampled latent vectors. Panel b features retinal image samples from the test dataset. In panel c, we display thecorresponding reconstructions produced by the generative model. Additionally, we show the difference maps for each of the RGB channels in d–f.
图10. 定性图像生成与反演性能 我们对配置(C)的一个模型(表1)的图像生成性能进行了定性评估。 - 面板a展示了从随机采样的潜在向量生成的图像。 - 面板b呈现了测试数据集中的视网膜图像样本。 - 面板c显示了生成模型生成的对应重建图像。 - 此外,面板d–f分别展示了每个RGB通道的差异图。
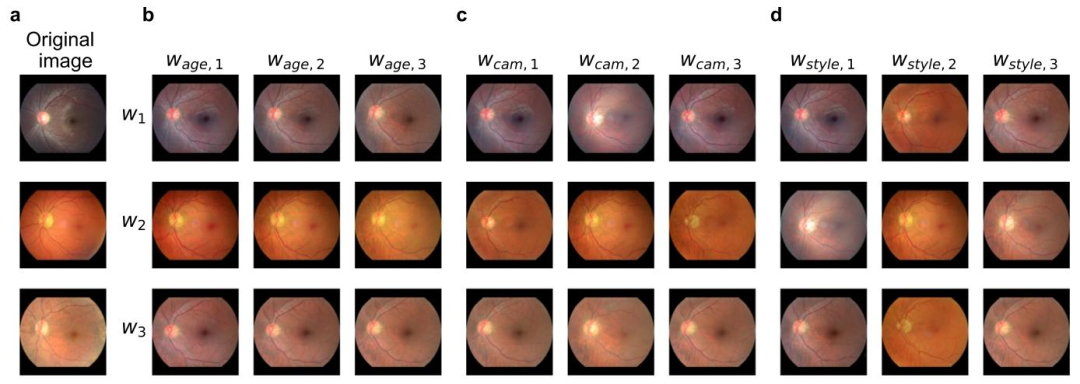
Fig. 11. Reconstructions of swapped latent subspaces for age-camera-style disentanglement.In panel a, original fundus images are presented alongside their respectivereconstructions in panels b–d. Each column in panels b–d corresponds to the exchange of age, camera, or style subspaces between the image encodings of panel a. The maindiagonals in panels b–d show reconstructions of the images in a, while the off-diagonals illustrate reconstructions where one subspace has been replaced with the subspace indicatedin the column header.
图11. 年龄-相机-风格解耦中潜在子空间交换后的重建结果 在面板a中,原始眼底图像与其在面板b–d中的对应重建图像一同呈现。 面板b–d中的每一列对应于将面板a中图像编码的年龄、相机或风格子空间进行交换的结果: - 面板b–d的主对角线展示了面板a中图像的重建结果; - 非对角线部分则显示了其中一个子空间被列标题所示子空间替换后的重建结果。
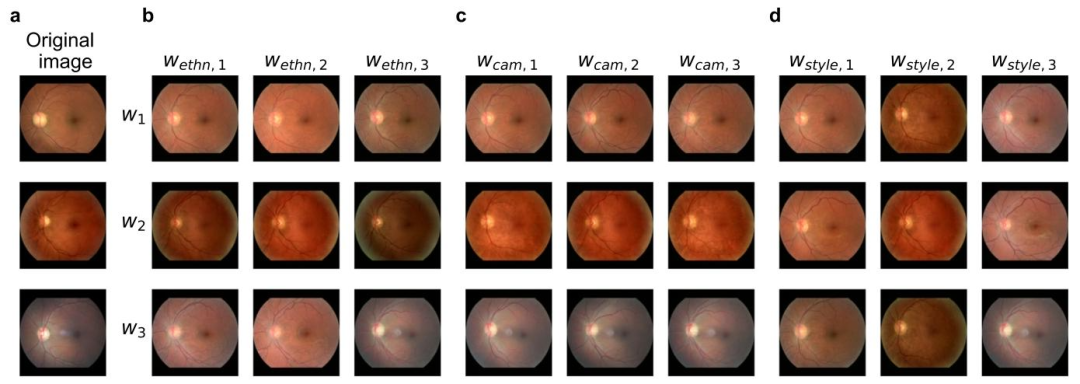
Fig. 12. Reconstructions of swapped latent subspaces for ethnicity-camera-style disentanglement. In panel a, original fundus images are presented alongside their respectivereconstructions in panels b–d. Each column in panels b–d corresponds to the exchange of ethnicity, camera, or style subspaces between the image encodings of panel a. Themain diagonals in panels b–d show reconstructions of the images in a, while the off-diagonals illustrate reconstructions where one subspace has been replaced with the subspaceindicated in the column header
图12. 种族-相机-风格解耦中潜在子空间交换后的重建结果 在面板a中,我们展示了原始眼底图像,面板b–d则为其对应的重建图像。 面板b–d中的每一列对应于将面板a中图像编码的种族、相机或风格子空间进行交换的结果: - 面板b–d的主对角线展示了面板a中图像的重建结果; - 非对角线部分则展示了其中一个子空间被列标题所示子空间替换后的重建结果。
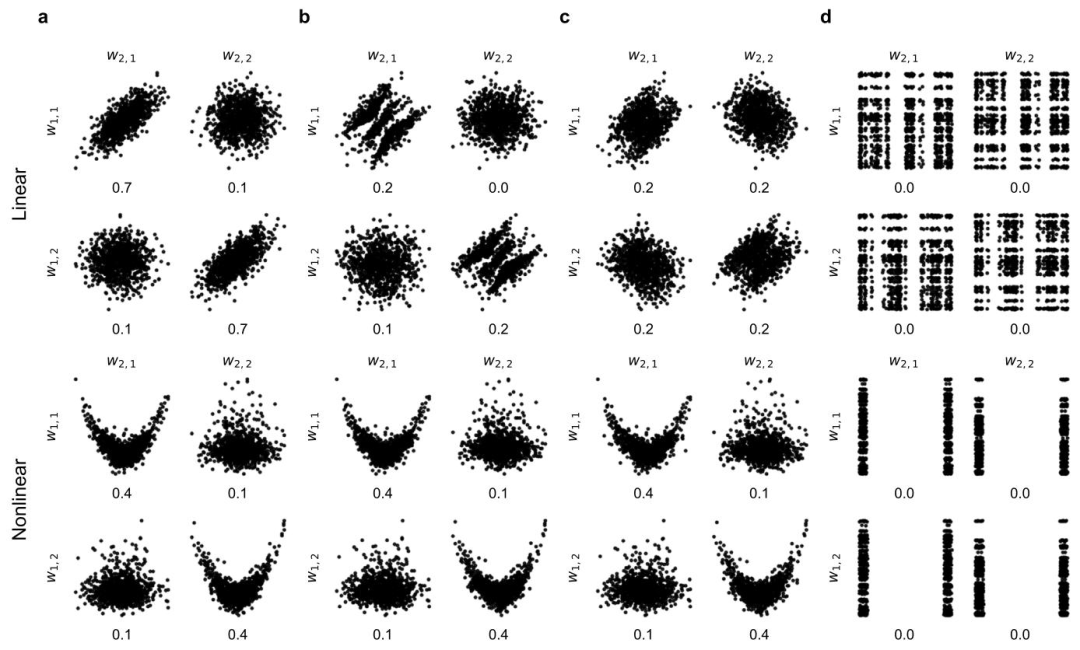
Fig. A.13. Toy example for different dependence measures. We sampled 1,000 points from two 2-dimensional subspaces 𝑤1 = [𝑤1,1 , 𝑤1,2 ] ∈ R2 and 𝑤2 = [𝑤2,1 , 𝑤2,2 ] ∈ R2and created dependencies between the main diagonals in the pair plots of a. We defined an optimization problem where we changed point coordinates to minimize variousdependence measures. Below the points we show distance correlation as a nonlinear dependence measure. In panels b and c we show the displacement of points when minimizingthe linear dependence measures GMI and C-GMI, respectively. In panel d we see that, compared to GMI and C-GMI, distance correlation can also effectively disentangle nonlineardependencies between subspaces
图A.13. 不同依赖度量的玩具示例 我们从两个二维子空间\(w_1 = [w_{1,1}, w_{1,2}] \in \mathbb{R}^2\)和\(w_2 = [w_{2,1}, w_{2,2}] \in \mathbb{R}^2\)中采样了1000个点,并在a的配对图主对角线上构建了它们之间的依赖关系。我们定义了一个优化问题,通过改变点的坐标来最小化各种依赖度量。点的下方显示了作为非线性依赖度量的距离相关性。 - 面板b和c分别展示了在最小化线性依赖度量(高斯互信息GMI和压缩高斯互信息C-GMI)时的点位移情况。 - 面板d显示,与GMI和C-GMI相比,距离相关性还能有效解耦子空间之间的非线性依赖关系。
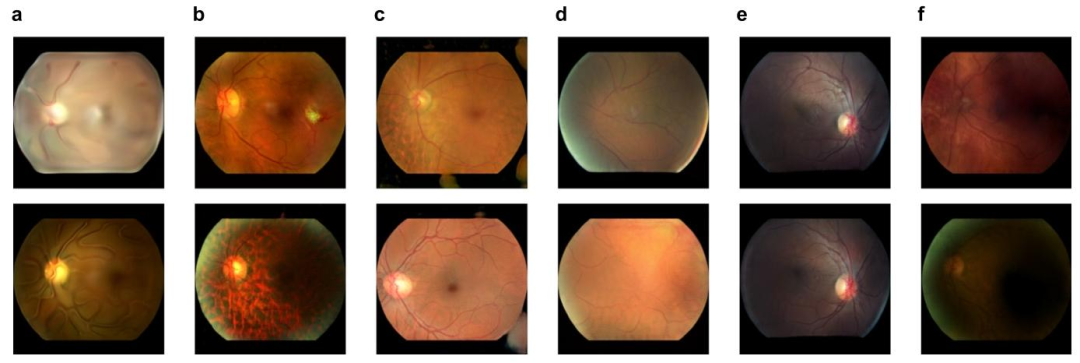
Fig. E.14. Examples of incorrectly generated fundus images. In a, we show cartoon-like images due to a not yet converged generative model. In addition, training instabilitiesresulted in unrealistic features in b, non-black background pixels in d, and missing anatomical features in d. Moreover, due to an imperfectly filtered dataset, the optic disc wason the wrong side in e, and some images were of poor quality as in f.
图E.14. 错误生成的眼底图像示例 - 面板a展示了因生成模型尚未收敛而产生的卡通化图像。 - 此外,训练不稳定性导致:面板b中出现不真实特征,面板c中存在非黑色背景像素,面板d中缺失解剖学特征。 - 另外,由于数据集筛选不够完善,面板e中出现视盘位置错误的图像,面板f中则存在部分质量较差的图像。
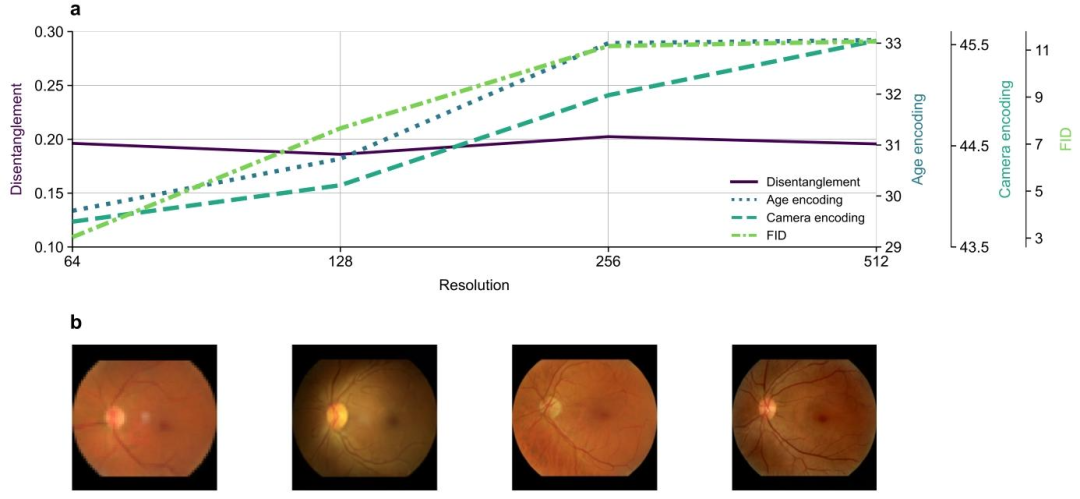
Fig. F.15. Performance comparison of different image resolutions. In a, we show a selection of measures to evaluate the performance of the GAN models with differentresolutions. For panel b, we randomly generated a fundus image with each trained model (resolutions 64, 128, 256, 512; from left to right)
图F.15. 不同图像分辨率的性能对比 - 面板a展示了一组用于评估不同分辨率下GAN模型性能的度量指标。 - 面板b中,我们使用每个训练好的模型(分辨率分别为64、128、256、512,从左至右)随机生成了一张眼底图像。
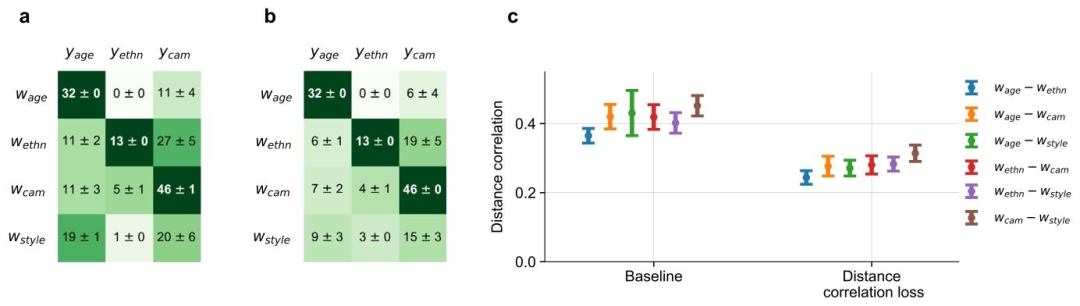
Fig. G.16. Disentanglement performance of a generative model with multiple subspaces. We trained generative models on retinal images, featuring four subspaces: 𝑤ageencoding the age class 𝑦age, 𝑤ethn encoding patient ethnicity 𝑦ethn, 𝑤cam encoding the camera class 𝑦cam, and 𝑤style serving as a patient-style subspace. In a and b, we reportkNN classifier accuracy improvement over chance level accuracy. The baseline model in a involved training linear classifiers on the first three subspaces. In b, we additionallydisentangled the subspaces using our distance correlation loss. Panel c compares the distance correlation measure between subspaces for two model configurations
图G.16. 具有多个子空间的生成模型的解耦性能 我们在视网膜图像上训练生成模型,该模型包含四个子空间:对年龄类别(y{\text{age}})进行编码的(w{\text{age}})、对患者种族(y{\text{ethn}})进行编码的(w{\text{ethn}})、对相机类别(y{\text{cam}})进行编码的(w{\text{cam}}),以及作为患者风格子空间的(w_{\text{style}})。 - 面板a和b报告了kNN分类器相较于随机水平准确率的提升情况: - 面板a中的基线模型在头三个子空间上训练线性分类器; - 面板b中的模型则额外利用我们提出的距离相关损失函数对这些子空间进行解耦。 - 面板c对比了两种模型配置(基线模型与带解耦损失的模型)中子空间之间的距离相关性度量结果。
Table
表
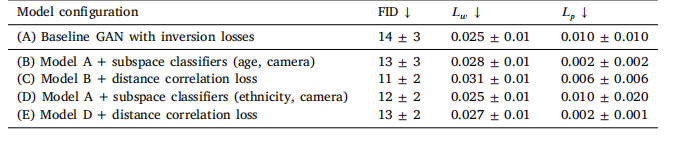
Table 1Image quality and inversion performance. For different model configurations we report the FID scoresbetween the training dataset and the generated images, along with the inversion losses 𝐿**𝑤 and 𝐿**𝑝 . Allmetrics are reported on the test set as the average over four models with different weight initializations.
表1 图像质量与反演性能。对于不同的模型配置,我们报告了训练数据集与生成图像之间的FID分数,以及反演损失(L_w)和(L_p)。所有指标均在测试集上报告,为4个具有不同权重初始化的模型的平均值。
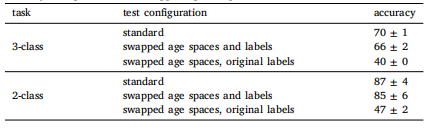
Table 2Quantitative age space performance. In an image classification setting, we demonstratethe influence of the age subspace on image generation by capturing relevant features.We trained image classifiers using reconstructions from our 4 GAN models on the 3-class age problem. Subsequently, we tested the classifiers on the 3-class problem (< 50,50 − 60, ≥ 60) and a simpler 2-class problem (≤ 40, ≥ 65). Here, we present the meanand standard deviation of classification performances, illustrating how age predictionscorrectly changed when we swapped age subspaces.
表2 定量年龄空间性能。在图像分类场景中,我们通过捕捉相关特征,展示了年龄子空间对图像生成的影响。 我们使用4个GAN模型的重建图像,针对3分类年龄问题(<50岁、50-60岁、≥60岁)训练了图像分类器。随后,在3分类问题和更简单的2分类问题(≤40岁、≥65岁)上对分类器进行了测试。 此处呈现了分类性能的均值和标准差,以此说明当我们交换年龄子空间时,年龄预测如何发生正确变化。