多模态融合模型迎来新突破!
目前,多模态融合的研究主要集中在提升模型性能上,而对可解释性的关注相对较少。然而,可解释性对于增强用户信任和优化模型决策至关重要,具有重要的研究价值,同时也响应了学术界对透明AI的迫切需求。
因此,可解释的多模态融合是一个极具潜力的研究方向,有望在多模态领域实现突破性进展。例如,中山六院团队开发的可解释多模态融合模型Brim,以及发表在Nature子刊上的可解释纵向多模态融合模型,都是近期值得深入研究的典型案例。
此外,我还整理了12篇可解释多模态融合的最新研究成果(附代码),为寻找研究灵感的同学提供参考。如果暂时缺乏明确方向,可以从细分领域(如医疗)的实际需求出发,从模型架构(如动态注意力机制)、评估指标(如跨模态解释一致性)或应用验证(如伦理审查)等角度切入研究。
我给大家准备了10种创新思路和源码,一起来看有需要的搜索人人人人人人人工重号(AI科技探寻)免费领取
论文1
标题:
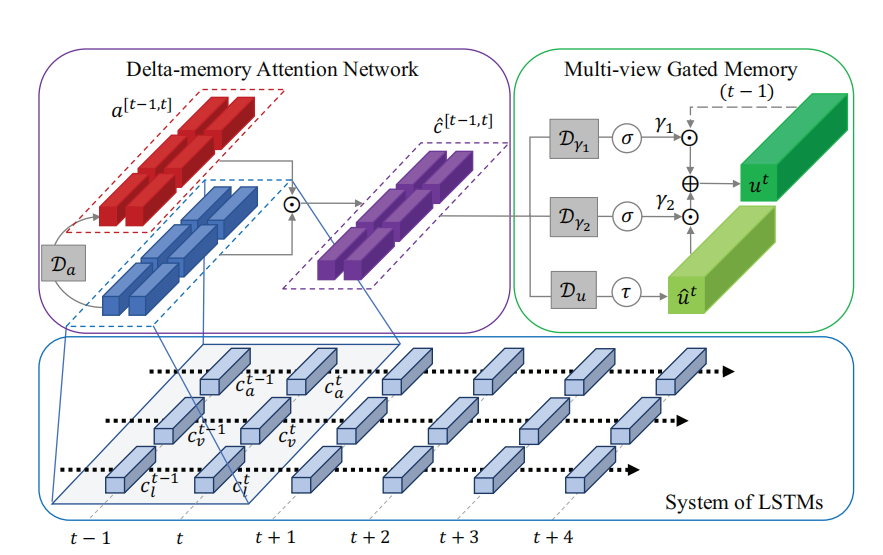
Memory Fusion Network for Multi-View Sequential Learning
多视图序列学习的记忆融合网络
方法:
系统LSTM(System of LSTMs):为每个视图分配一个LSTM网络,独立编码每个视图的特定动态和交互。
Delta-memory注意力网络(Delta-memory Attention Network, DMAN):通过比较不同时刻的LSTM记忆,识别跨视图交互,并为每个LSTM记忆维度分配相关性分数。
多视图门控记忆(Multi-view Gated Memory):存储跨时间的跨视图交互信息,通过保留和更新门控制记忆的更新。
时间对齐:使用P2FA工具对齐语言、视觉和听觉模态的时间戳,确保多模态数据的时间一致性。
创新点:
跨视图交互建模:通过DMAN显式建模跨视图交互,提升了多视图序列学习的性能。
动态记忆机制:引入多视图门控记忆,能够动态更新跨视图交互信息,增强了模型对时间序列数据的处理能力。
性能提升:在多个公开的多视图数据集上,MFN显著优于所有现有的多视图方法,平均性能提升超过2.8%(如CMU-MOSI数据集上的准确率从74.6%提升到77.4%)。
计算效率:MFN在保持高性能的同时,计算效率更高,运行速度比其他复杂模型快10倍以上。
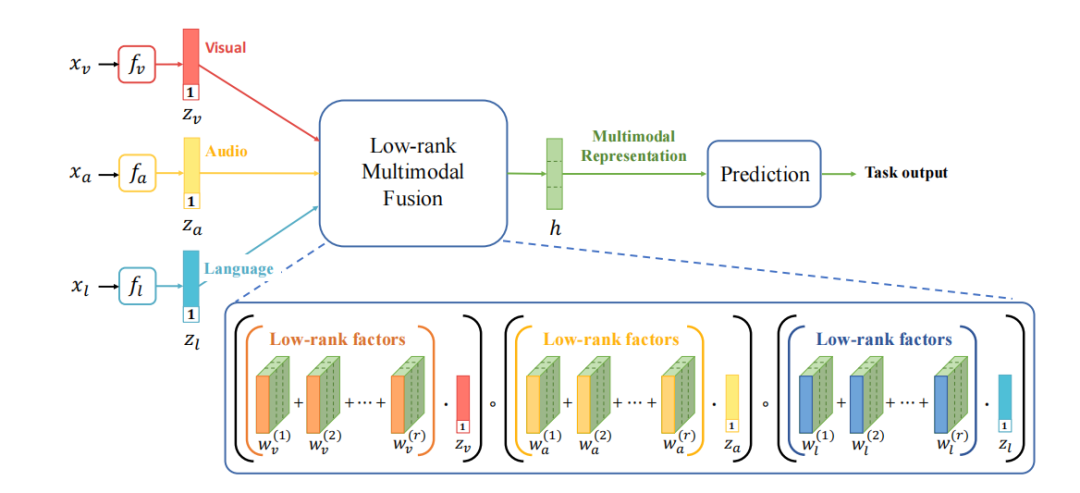
论文2
标题:
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
具有模态特定因子的高效低秩多模态融合
方法:
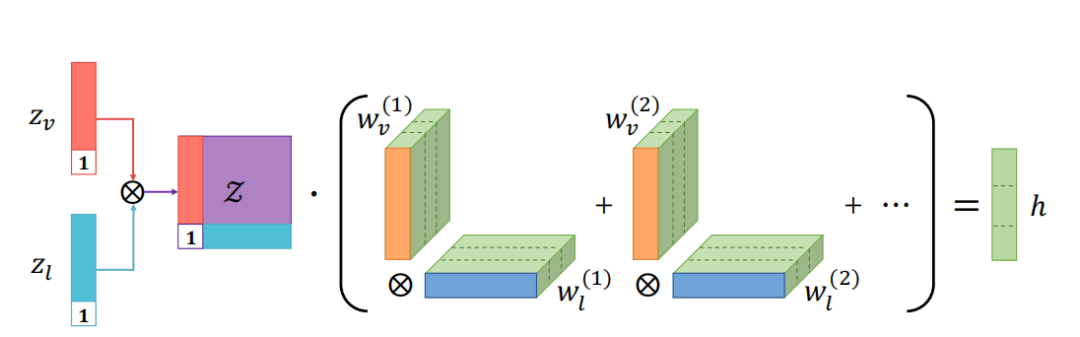
低秩张量分解:将权重张量分解为模态特定的低秩因子,减少模型参数数量。
并行分解计算:利用输入张量和权重张量的并行分解,高效计算多模态融合结果。
多模态表示:通过低秩张量融合生成紧凑的多模态表示,用于下游任务。
特征提取网络:为每个模态设计独立的特征提取网络,提取语言、视觉和听觉模态的特征。
创新点:
低秩融合:通过低秩张量分解,显著减少了多模态融合中的参数数量,降低了计算复杂度。
线性扩展:模型复杂度从指数级降低到线性级,能够高效处理多模态数据。
性能提升:在多个多模态任务上,LMF模型达到了与现有最佳模型相当的性能,同时训练和测试速度分别提高了3倍以上。
鲁棒性:在不同低秩设置下,LMF模型表现出良好的鲁棒性,适用于广泛的多模态应用。
论文3
标题:
Feature Projection for Improved Text Classification
用于改进文本分类的特征投影
方法:
梯度反转层(GRL):在C-Net中使用GRL提取对分类无区分力的公共特征。
正交投影层(OPL):将传统特征向量投影到公共特征的正交方向,生成更纯净的特征向量。
特征提取器:使用CNN、RNN、Transformer和Bert等作为特征提取器,验证方法的通用性。
创新点:
特征投影:首次提出通过特征投影来改进文本分类的特征表示,使特征更具有区分力。
性能提升:在多个文本分类数据集上,FP-Net显著提高了分类准确率,例如在MR数据集上,使用CNN作为特征提取器时,准确率从76.18%提升到78.74%。
通用性:该方法适用于多种深度学习模型,包括LSTM、CNN、Transformer和Bert,并且在所有模型上都取得了性能提升。
非监督学习:不依赖外部数据或知识,仅通过特征投影改进现有模型的特征表示
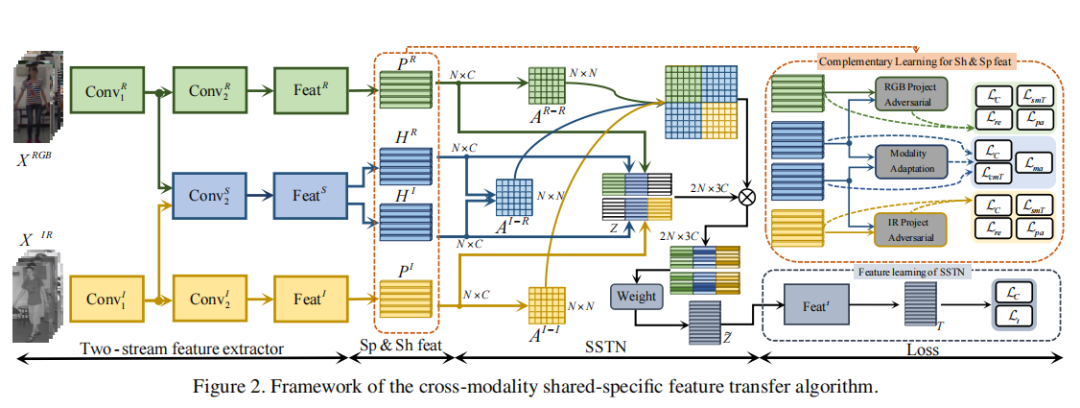
论文4
标题:
Cross-modality Person Re-identification with Shared-Specific Feature Transfer
跨模态行人再识别中的共享 - 特定特征传递
方法:
- 双流特征提取器:分别提取模态共享特征和模态特定特征,增强特征的区分能力。
共享 - 特定转移网络(SSTN):基于共享特征建模样本间的亲和性,并在模态间传递共享和特定特征。
互补特征学习:通过模态适应、投影对抗学习和重建增强,学习自区分和互补的共享及特定特征。
端到端训练:整个算法以端到端的方式进行训练,优化特征提取和转移过程
创新点
共享 - 特定特征融合:首次提出在跨模态行人再识别中同时利用共享和特定特征,显著提升了识别性能。
性能提升:在SYSU-MM01和RegDB两个主流数据集上,mAP分别提升了22.5%和19.3%,Rank-1准确率分别提升了19.2%和14.4%。
特征传递策略:通过建模样本间的亲和性传递特征,有效补偿了特定信息的缺失,增强了共享特征的鲁棒性。
互补学习:提出的互补学习策略进一步提高了特征的区分能力,使共享和特定特征更加互补。