有关Kubernetes技术的学习
背景
Kubernetes是谷歌开源的容器集群管理系统,它的发展非常迅速,已经成为最流行和最活跃的容器编排系统。它提供了完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。
组成
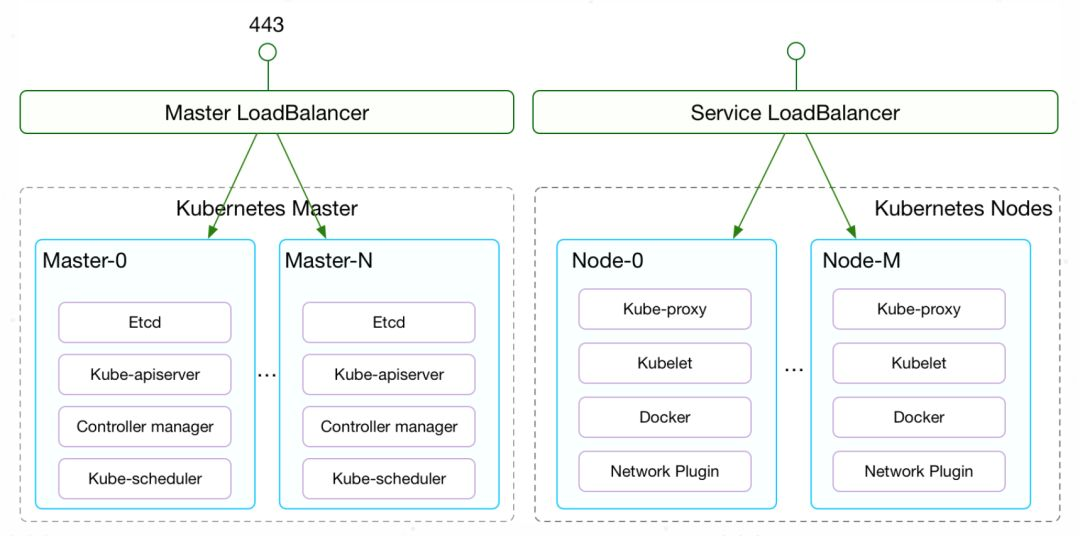
从架构上来说,Kubernetes的组件可以分为Master和Node两部分,其中Master是整个集群的大脑,所有的编排、调度、API访问等都由Master来负责。
Master包括以下几个组件:
- etcd保存整个集群状态;
- kube-apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制。
- kube-controller-manager 负责维护集群的状态,包括很多资源的控制器,这些控制器是保证Kubernetes声明API工作的大脑,比如故障检测、自动扩展、滚动更新等;
- kube-scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的Node上。
Node是负责运行具体的容器,并为容器提供存储、网络等必要功能:
- kubelet 负责维持容器的生命周期,同时也负责Volume(CSI) 和网络(CNI)的管理;
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI),默认的容器运行时为Docker;
- kube-proxy负责为Service提供Cluster内部的Service Discovery和负载均衡;
- Network plugin负责为容器配置网络。
Kubelet(节点代理)的组件包括:
- Kubelet Server 对外提供API ,供kube-apiserver、metrics-server等服务调用。比如kubectl exec时需要通过Kubelet API/exec/{token} 与容器进行交互;
- Container Manager管理容器的各种资源,比如CGroups、QoS、cpuset、device等;
- Volume Manager 管理容器的存储卷,比如格式化资盘、挂载到Node本地、最后再将挂载路径传给容器;
- Eviction负责容器的驱逐,比如在资源不足时驱逐优先级低的容器,保证高优先级容器的运行;
- cAdviser负责为容器提供Metrics;
- Metrics和stats提供容器和节点的度量数据;
- Generic Runtime Manager是容器运行时的管理者,负责于CRI(容器运行时接口,)交互,完成容器和镜像的管理;
- 在CRI之下,包括两种容器运行时的实现:
一种是内置的dockershim,实现了Docker容器引擎的支持以及CNI网络插件(包括kubenet)的支持;
另一种是外部的容器运行时, 用来支持runc、contained,gVisor等外部容器运行时。
Kubelet通过CRI接口跟外部容器运行时交互,组件包括:
- CRI Server:CRI gRPC server,监听在Unix socket上;
- Streaming Server:提供streaming API,包括Exec、Attach、Port Forward;
- 容器和镜像的管理:比如拉取镜像、创建和启动容器等;
- CNI网络插件的支持,用于给容器配置网络;
- 容器引擎管理,比如支持runc、contained或者支持多个容器引擎。
Kubernetes中的容器运行时按照不同的功能可以分为三个部分:
- 第一部分:kubelet中容器运行时的管理,它通过CRI管理容器和镜像;
- 第二部分:容器运行时接口,它是kubelet与外部容器运行时的通信接口;
- 第三部分:具体的容器运行时实现,包括Kubelet 内置的dockershim以及外部的容器运行时(如cri-o、cri-contained、frakti等)。
容器运行时的演进过程
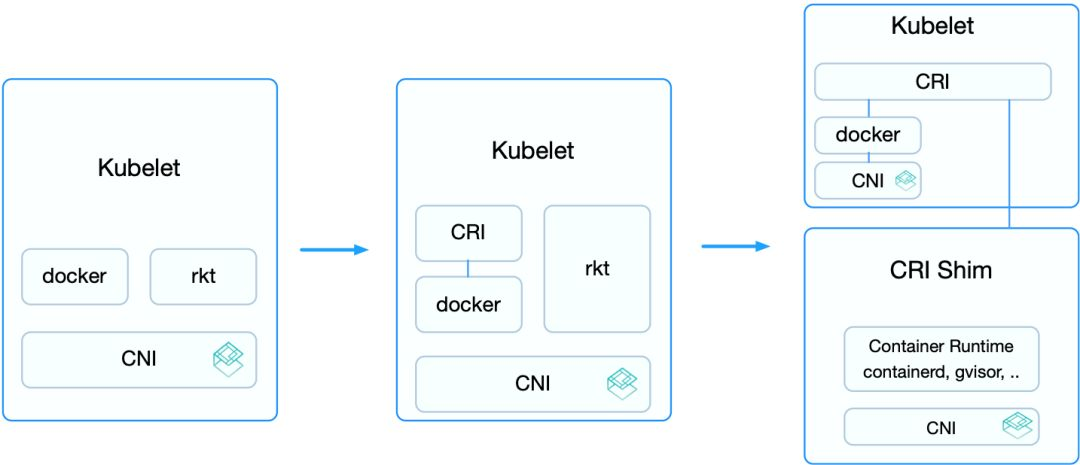
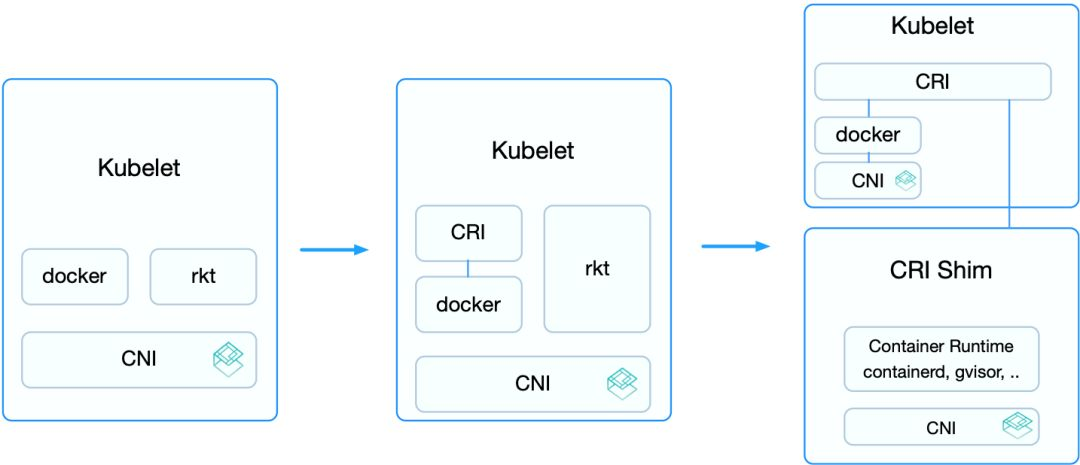
容器运行时的演进可以分为三个阶段:
第一阶段,在Kubernetes v1.5之前,kubelet内置了Docker和rkt的支持,并且通过CNI网络插件给它们配置容器网络。维护和升级非常麻烦。
第二阶段,不同用户实现的容器运行时各有所长,许多用户都希望Kubernetes支持更多的运行时。于是,v1.5开始增加了CRI接口,通过容器运行时的抽象层消除了这些障碍,使得无需修改kubelet就可以支持运行多种容器。
CRI接口包括了一组Protocol Buffer、gRPC API、用于streaming接口的库以及用于调试和验证的一系列工具等。在此阶段,内置的Docker实现也逐步迁移到了CRI的接口下。但此时rkt还未完全迁移,这是因为rkt迁移CRI的过程将在独立的repository完成,方便其维护和管理。
第三阶段,从v1.11开始,Kubelet内置的rkt代码删除,CNI的实现迁移到dockershim之内。这样,除了Docker之外,其他的容器运行时都通过CRI接入。外部的容器运行时一般称为CRI Shim,它除了实现CRI接口外,也要负责为容器配置网络。
CRI(容器运行时接口)是一个用来扩展容器运行时的接口,它基于gPRC,用户不需要关心内部通信逻辑,只需要实现定义的接口(包括RuntimeService 和 ImageService)方可。
RuntimeService负责管理Pod和容器的生命周期;
ImageService负责管理镜像的生命周期;
除了gRPC API,CRI 还包括用于实现 Streaming Server 的库(用于 Exec、Attach、PortForward 等接口)和 CRI Tools。
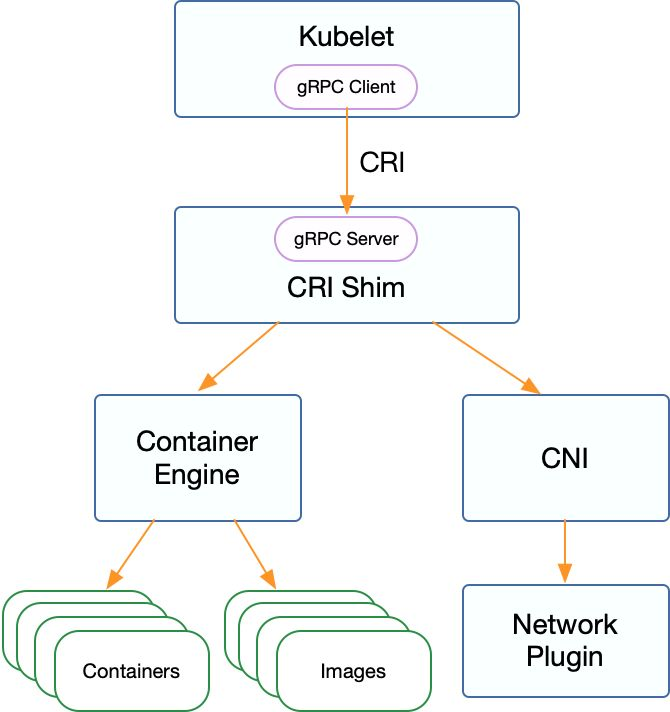
基于 CRI 接口的容器运行时通常称为 CRI shim, 这是一个 gRPC Server,监听在本地的 unix socket 上;而 kubelet 作为 gRPC 的客户端来调用 CRI 接口。另外,外部容器运行时需要自己负责管理容器的网络,推荐使用 CNI,使它与 Kubernetes 的网络模型保持一致。
不同场景下一些列的容器运行时:
-
cri-containerd ——基于 containerd 的容器运行时;
-
cri-o ——基于 OCI 的容器运行时;
-
frakti ——基于虚拟化的容器运行时;
而基于这些容器运行时,还可以轻易联结新型的容器引擎,比如可以通过 clear container、gVisor 等新的容器引擎配合 cri-o 或 cri-containerd 等轻易接入 Kubernetes,将 Kubernetes 的应用场景扩展到了传统 IaaS 才能实现的强隔离和多租户场景。
当使用 CRI 运行时,需要配置 kubelet 的 --container-runtime 参数为 remote,并设置 --container-runtime-endpoint 为监听的 unix socket 位置(Windows 上面为 tcp 端口)。
CRI 接口
CRI 接口包括 RuntimeService 和 ImageService 两个服务,这两个服务可以在一个 gRPC server 中实现,也可以分开成两个独立服务。目前社区的很多运行时都是将其在一个 gRPC server 里面实现。
管理镜像的 ImageService 提供了 5 个接口:
-
查询镜像列表;
-
拉取镜像到本地;
-
查询镜像状态;
-
删除本地镜像;
-
查询镜像占用空间等。
这些都很容易映射到 Docker API 或者 CLI 上面。
RuntimeService则提供了更多的接口,按照功能可以划分为四组。
-
PodSandbox 的管理接口:PodSandbox 是对 Kubernete Pod 的抽象,用来给容器提供一个隔离的环境(比如挂载到相同的 CGroup 下面),并提供网络等共享的命名空间。PodSandbox 通常对应到一个 Pause 容器或者一台虚拟机;
-
Container 的管理接口:在指定的 PodSandbox 中创建、启动、停止和删除容器;
-
Streaming API 接口:包括 Exec、Attach 和 PortForward 等三个和容器进行数据交互的接口,这三个接口返回的是运行时 Streaming Server 的 URL,而不是直接跟容器交互;
-
状态接口:包括查询 API 版本和查询运行时状态
Streaming API
Streaming API 用于客户端与容器进行交互,包括 Exec、PortForward 和 Attach 等三个接口。kubelet 内置的 Docker 通过 nsenter、socat 等方法来支持这些特性,但它们不一定适用于其他的运行时,也不支持 Linux 之外的其他平台。因而,CRI 也显式定义了这些 API,并且要求容器运行时返回一个 Streaming Server 的 URL 以便 kubelet 重定向 API Server 发送过来的流式请求。
因为所有容器的流式请求都会经过 kubelet,这可能会给节点的网络流量带来瓶颈,因而 CRI 要求容器运行时启动一个对应请求的单独的流服务器,将地址返回给 kubelet。kubelet 将这个信息再返回给 Kubernetes API Server, 它会直接打开与运行时提供的服务器相连的流连接,并通过它跟客户端连通。
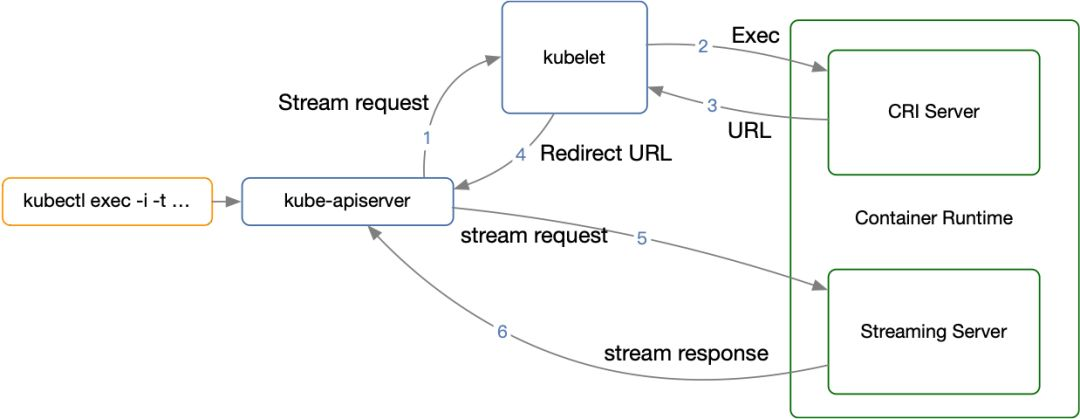
这样一个完整的 Exec 流程就如上图所示,分为多个阶段:
-
客户端 kubectl exec -i -t ... ;
-
kube-apiserver 向 kubelet 发送流式请求 /exec/ ;
-
kubelet 通过 CRI 接口向 CRI Shim 请求 Exec 的 URL;
-
CRI Shim 向 kubelet 返回 Exec URL;
-
kubelet 向 kube-apiserver 返回重定向的响应;
-
kube-apiserver 重定向流式请求到 Exec URL,然后将 CRI Shim 内部的 Streaming Server 跟 kube-apiserver 进行数据交互,完成 Exec 的请求和响应。
容器运行时实例
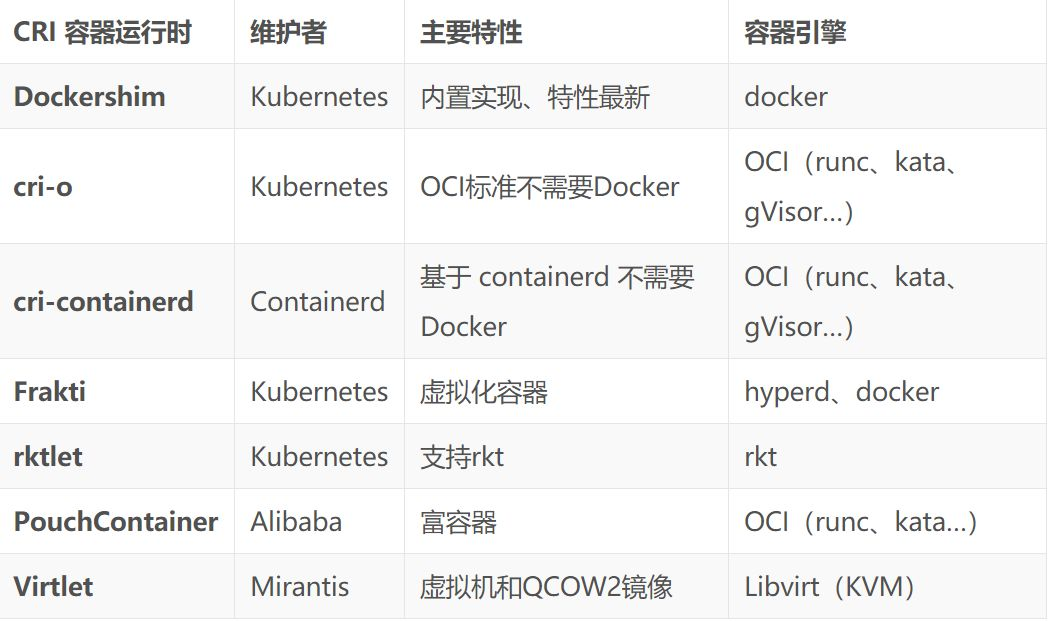
多租户场景
有了 CRI 之后,就可以接入 Kata Container、Clear Container 等基于虚拟化的容器引擎。这样通过虚拟化实现了容器的强隔离,不同租户的容器也可以运行在相同的 Node 上,大大提高了资源的利用率。
多租户不仅需要容器自身的强隔离,还需要众多其他的功能一起配合,比如:
-
网络隔离,比如可以使用 CNI 构建新的网络插件,把不同租户的 Pod 接入到相互隔离的虚拟网络中;
-
资源管理,比如基于 CRD 构建租户 API 和租户控制器,管理租户和租户的资源;
-
认证、授权、配额管理等也都可以在 Kubernetes API 之上构建。
CRI Tools
CRI Tools 是社区 Node 组针对 CRI 接口开发的辅助工具,它包括两个工具:crictl 和 critest。
crictl 是一个容器运行时命令行接口,它对系统和应用的排错来说是个很有用的工具。当使用 Docker 运行时,调试系统信息的时候我们可能使用 docker ps 和 docker inspect 等命令检查应用的进程情况。
但是对于其他基于 CRI 的容器运行时来说,它们可能没有自己的命令行工具;即便有,它们的操作界面也不一定与 Kubernetes 中的概念一致。有很多的命令对 Kubernetes 没什么用,甚至会损害系统(比如 docker rename)。因而,我们推荐使用 crictl 作为 Docker CLI 的继任者,用于 Kubernetes 节点上 Pod、容器以及镜像的除错工具。
crictl 提供了类似 Docker CLI 的使用体验, 并且支持所有 CRI 兼容的容器运行时。并且,crictl 提供了一个对 Kubernetes 来说更加友好的容器视角:它就是为 Kubernetes 而设计的,有不同的命令分别与 Pod 和容器进行交互。例如 crictl pods 会列出 Pod 信息,而 crictl ps 只会列出应用容器的信息。
而 critest 则是一个容器运行时的验证测试工具,用于验证容器运行时是否符合 Kubelet CRI 的要求。除了验证测试,critest 还提供了 CRI 接口的性能测试,比如 critest -benchmark。
多容器运行时RuntimeClass
多容器运行时是指在一个系统或平台上同时支持和使用多种容器运行时的架构模式。这种设计允许不同的工作负载根据其特定需求选择合适的运行时环境。
核心概念
-
基本定义:
-
允许在同一集群或主机上并行使用多种容器运行时技术
-
每个Pod或容器可以选择最适合其需求的运行时
-
通过统一的接口(如CRI)进行管理
-
-
与传统单运行时的区别:
-
传统方式:整个集群使用单一运行时(如containerd)
-
多运行时:同时支持containerd、Kata、gVisor等不同运行时
-
典型的多运行时组合
-
标准容器运行时:
-
containerd
-
CRI-O
-
适用于大多数常规工作负载
-
-
安全增强型运行时:
-
Kata Containers
-
gVisor
-
用于高安全性要求的负载
-
-
特殊用途运行时:
-
NVIDIA Container Runtime(用于GPU加速)
-
WasmEdge(用于WebAssembly工作负载)
-
用于不同目的,比如使用虚拟化容器引擎式运行不可信应用和多租户应用,而使用Docker运行系统组件或者无法虚拟化的容器(比如需要HostNetwork的容器)。
技术实现
Kubernetes 在 v1.12 中将开始增加 RuntimeClass 这个新的 API 对象,用来支持多容器运行时。
RuntimeClass 表示一个运行时,在使用前需要开启特性开关 RuntimeClass ,并创建 RuntimeClass CRD:
kubectl apply -f
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/runtimeclass/runtimeclass_crd.yaml
定义RuntimeClass对象:
apiVersion: node.k8s.io/v1alpha1 # RuntimeClass is defined in the node.k8s.io API group
kind: RuntimeClass
metadata:name: myclass # The name the RuntimeClass will be referenced by# RuntimeClass is a non-namespaced resource
spec:runtimeHandler: myconfiguration # The name of the corresponding CRI configuration
可以在Pod中定义使用哪个RuntimeClass
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:runtimeClassName: myclass# ...
无服务容器服务
无服务器(Serverless)现在是一个很热门的方向,各个云平台也提供很多种类的无服务器计算服务,比如 Azure Container Instance、AWS Farget 等。它们的好处是用户不需要去管理容器底层的基础设施,而只需要管理容器本身的部署和运行,并且容器通常按实际的运行时间收费。这样,对用户来说,不仅省去了管理基础设施的繁琐步骤,还更节省成本。
借助 Virtual Kubelet 项目,使用 Kubernetes 为这些平台的容器提供编排功能。Virtual Kubelet 是针对 Serverless 容器平台设计的虚拟 Kubernetes 节点,它模拟了 kubelet 的功能,并将 Serverless 容器平台抽象为一个虚拟的无限资源的 Node。这样就可以通过 Kubernetes API 来管理其上的容器。
-
无需基础设施管理
-
用户不需要关心:
✓ 服务器配置(CPU/内存/存储)
✓ 节点扩缩容
✓ 操作系统/运行时补丁更新
✓ 集群编排(如Kubernetes运维) -
服务商自动处理底层资源调度和运维。
-
-
按实际使用计费
-
通常按容器运行时间和资源消耗量计费(如每秒使用的vCPU和内存GB)。
-
典型代表:AWS Fargate、Azure Container Instances、Google Cloud Run。
-
-
事件驱动/自动伸缩
-
根据请求量自动从0扩展到N个容器实例(如HTTP请求触发)。
-
空闲时自动缩容到0(避免资源浪费)。
-
与传统容器服务的区别
| 维度 | 无服务器容器服务 | 传统容器服务(如自建K8s) |
|---|---|---|
| 基础设施管理 | 完全托管,用户不可见 | 需自行管理节点、集群、网络 |
| 伸缩粒度 | 按单个容器自动伸缩 | 通常按节点/Pod组伸缩 |
| 计费模式 | 按实际资源使用量 | 按预留资源付费(无论是否用完) |
| 启动延迟 | 冷启动可能延迟(几百ms~几秒) | 常驻实例(毫秒级响应) |
| 适用场景 | 突发流量、间歇性任务 | 长期运行的服务 |
典型工作流程(以AWS Fargate为例)
-
用户提交容器镜像
bash
docker push my-registry/my-app:latest
-
定义任务配置(CPU/内存/环境变量)
json
// task-definition.json {"cpu": "1 vCPU","memory": "2 GB","image": "my-registry/my-app:latest" } -
服务商自动处理:
✓ 选择最优的底层节点
✓ 拉取镜像并启动容器
✓ 监控健康状态
✓ 根据负载扩缩容
注意事项
-
冷启动延迟
-
从0扩容时需初始化环境(可通过预留实例缓解)。
-
-
本地调试限制
-
难以完全模拟生产环境(需依赖日志和远程调试工具)。
-
-
厂商锁定风险
-
各云平台的无服务器实现存在差异(如AWS Fargate vs Azure Container Apps)。
-
无服务器容器服务通过完全托管的基础设施和精细化的资源调度,实现了"仅关注业务代码,无需运维底层"的体验,是容器技术向更高抽象层级发展的典型代表。
文章参考:
微软资深工程师详解 K8S 容器运行时Kubernetes 已成为容器编排调度领域的事实标准,其优良的架构不仅保证了丰富 - 掘金