Linux打开、读写一个文件内核做了啥?
目录
一、PCB中关于文件部分的结构体是什么?
二、files_struct的两个核心成员
三、fork函数原理
四、读写文件时的三层缓冲区
我们在使用C语言打开一个文件,只需要简简单单的调用open函数,就会给我们返还一个FILE*的指针或者使用系统调用返还给我们fd,通过这个指针即可对文件进行读写,但是他的底层做了什么呢?内核又有什么数据字段来管理呢?
一、PCB中关于文件部分的结构体是什么?
这是一段直接使用系统调用打开文件,并读写的示例:
#include <stdio.h> // 标准输入输出
#include <fcntl.h> // open函数需要
#include <unistd.h> // read/write/close函数需要
#include <string.h> // strlen函数需要int main() {// 1. 打开文件(如果不存在则创建)int fd = open("test.txt", O_RDWR | O_CREAT, 0644);if (fd == -1) {perror("打开文件失败"); // 打印错误原因return 1;}printf("文件打开成功,fd = %d\n", fd); // 输出文件描述符// 2. 向文件写入数据const char *msg = "Hello, File!";ssize_t write_len = write(fd, msg, strlen(msg));if (write_len == -1) {perror("写入失败");close(fd);return 1;}printf("写入了 %zd 个字节\n", write_len);// 3. 移动文件指针到开头(否则读不到刚写入的内容)lseek(fd, 0, SEEK_SET);// 4. 从文件读取数据char buf[1024];ssize_t read_len = read(fd, buf, sizeof(buf)-1); // 留1个字节存结束符if (read_len == -1) {perror("读取失败");close(fd);return 1;}buf[read_len] = '\0'; // 手动添加字符串结束符printf("读到的内容:%s\n", buf);// 5. 关闭文件close(fd);return 0;
}fd一个非负整数(如上面的3),它是进程用来标识 “当前打开的文件” 的编号。
fd由于也是进程的一个属性,所以他必然在PCB中。
struct task_struct
{ // 进程的“档案袋”...struct files_struct *files; // 管理所有打开的文件...
};struct files_struct
{atomic_t count;struct fdtable __rcu *fdt;struct fdtable fdtab;spinlock_t file_lock ____cacheline_aligned_in_smp;int next_fd;unsigned long close_on_exec_init[1];unsigned long open_fds_init[1];unsigned long full_fds_bits_init[1];struct file __rcu ** fd_array;
};struct fdtable
{ // “文件索引表”(核心!)struct file *fd[1024]; // 数组:索引=fd值,内容=文件的详细信息// 例如:fd[0] → 标准输入;fd[1] → 标准输出;fd[3] → 我们打开的test.txt
};
在这幅图中,我们首先要明白PCB和files_struct的从属关系,还是和之前一样,进程的所有信息都被存放在PCB中。当你调用open创建或者打开一个文件的时候,内核本质上是在你进程的PCB中创建了一个files对象,替换原本的NULL指针。
然后对于files_struct我们看看其中关键的几个成员(如图所示):
(1)
atomic_t count:
这是一个原子计数器,用于记录当前有多少个引用指向这个files_struct结构体。在 Linux 内核中,当发生进程复制(如fork操作)时,不会立马给子进程创建files_struct结构体。(因为如果子进程创建后直接exec了,那么给子进程创建结构体就是一个资源浪费了)而是子进程会共享父进程的files_struct结构体,此时计数器的值会增加。只有当子进程或父进程打开或者关闭某个文件描述符的“写”操作,才会给子进程创建一个新的,复制瞬间两者完全一样。当一个进程关闭所有文件并销毁其files_struct结构体时,计数器的值会减少,当计数器变为 0 时,内核就可以释放该files_struct结构体所占用的资源。(2)
struct fdtable __rcu *fdt:
这是一个指向fdtable结构体的指针,并且使用了__rcu(Read - Copy - Update)机制。fdtable结构体用于管理文件描述符表,fdt指针指向当前正在使用的文件描述符表。__rcu机制允许在不阻塞读操作的情况下对fdt进行更新,提高了并发访问时的性能。(3)
struct fdtable fdtab:
这是一个fdtable结构体实例,作为备用的文件描述符表。在一些情况下,例如当需要动态扩展文件描述符表时,内核会先操作这个备用表,然后再切换到新的表,以保证操作的原子性和正确性。(4)
spinlock_t file_lock ____cacheline_aligned_in_smp:这是一个自旋锁,用于保护对
files_struct结构体中共享资源的访问。在多处理器系统(SMP)中,当多个内核线程可能同时访问和修改files_struct中的数据(比如添加或删除文件描述符 )时,通过自旋锁可以避免竞态条件,保证数据的一致性和正确性。____cacheline_aligned_in_smp用于确保自旋锁在 SMP 系统中以缓存行对齐的方式存储,减少缓存冲突,提高性能。(5)
int next_fd:
记录下一个可用的文件描述符的值。当进程打开一个新文件时,内核会从next_fd开始查找空闲的文件描述符,并将其分配给新打开的文件,然后更新next_fd的值。(6)
unsigned long close_on_exec_init[1]:
这是一个数组,用于记录在执行exec系列系统调用(如execve)时,哪些文件描述符应该被关闭。每个比特位对应一个文件描述符,比特位为 1 表示该文件描述符在exec时应该被关闭。初始状态下,这个数组的值会被初始化,用户可以通过fcntl系统调用的FD_CLOEXEC标志来修改特定文件描述符对应的比特位。初始情况下可以看到他只给了1个long类型的位图,即64个文件描述符,一般情况下是够用的,如果超过了内核会有一个close_on_exec的新位图来接替他的工作。(7)
unsigned long open_fds_init[1]:
也是一个数组,用于记录当前已经打开的文件描述符。每个比特位对应一个文件描述符,比特位为 1 表示该文件描述符已经被打开。(8)
unsigned long full_fds_bits_init[1]:
这个数组用于表示文件描述符表的哪些位置被占用了。当文件描述符表中的位置被占用时,对应的比特位会被设置。即方便了next_fd的查询。(9)
struct file __rcu ** fd_array:
这是一个指向struct file指针数组的指针。fd_array数组用于存储文件描述符和对应的struct file结构体之间的映射关系,数组的索引就是文件描述符的值,数组元素是指向对应文件的struct file结构体的指针。而file这个结构体负责描述打开文件的状态,如文件偏移量、文件操作方法、文件读写权限、和引用计数。
二、files_struct的两个核心成员
他们分别是文件描述符表,和file结构体的fd_array二级指针。
而文件描述符表的核心部分是一个file结构体的指针数组,通过下标可以找到文件描述符对应的file结构体,从而获取file的更多信息。

我们以read为例:
- 用户态调用
read(fd, buf, n),传入文件描述符fd- 内核通过当前进程的
task_struct找到files_struct- 从
files_struct->fdt拿到当前活跃的文件描述符表,通过fd作为索引访问fd_array[fd],得到指向struct file的指针- 查看
struct file中的关键信息:
f_pos:确定当前读写位置(比如上次读到了文件的第 100 字节,这次从 100 开始读)f_op:获取文件操作方法集(比如f_op->read指向具体的读函数,不同文件系统 / 设备的读逻辑不同,都通过这里抽象)f_path:找到文件在文件系统中的位置(比如对应哪个 inode,数据存在磁盘的哪个块)- 执行实际的读操作(从磁盘 / 缓存读取数据),并更新
f_pos(比如读了 50 字节,f_pos变为 150)- 将数据返回给用户态的
buf
当然,如果一个进程多次打开同一个文件,会有多个fd被记录。
三、fork函数原理
当使用fork创建一个进程的时候,首先会给子进程分配一个PCB。这是进程在内核中的核心描述符,记录了进程的所有关键信息,如进程状态、调度信息、内存管理信息等。
task_struct 中的很多字段会直接从父进程复制过来(写时拷贝计数),不过也有一些字段需要进行特殊处理,例如子进程的 PID 是唯一的,需要内核进行分配。
Linux 采用写时复制(Copy - On - Write,COW)技术来处理父子进程的内存。写时复制的核心思想是,在 fork 发生时,子进程并不立即复制父进程的所有内存页面,而是与父进程共享这些页面。父子进程的页表会指向相同的物理内存页,并将这些页标记为只读。只有当父子进程中的某一个试图修改共享的内存页面时,内核才会为修改的页面分配新的物理内存,并更新相应的页表,使得父子进程各自拥有独立的内存副本。
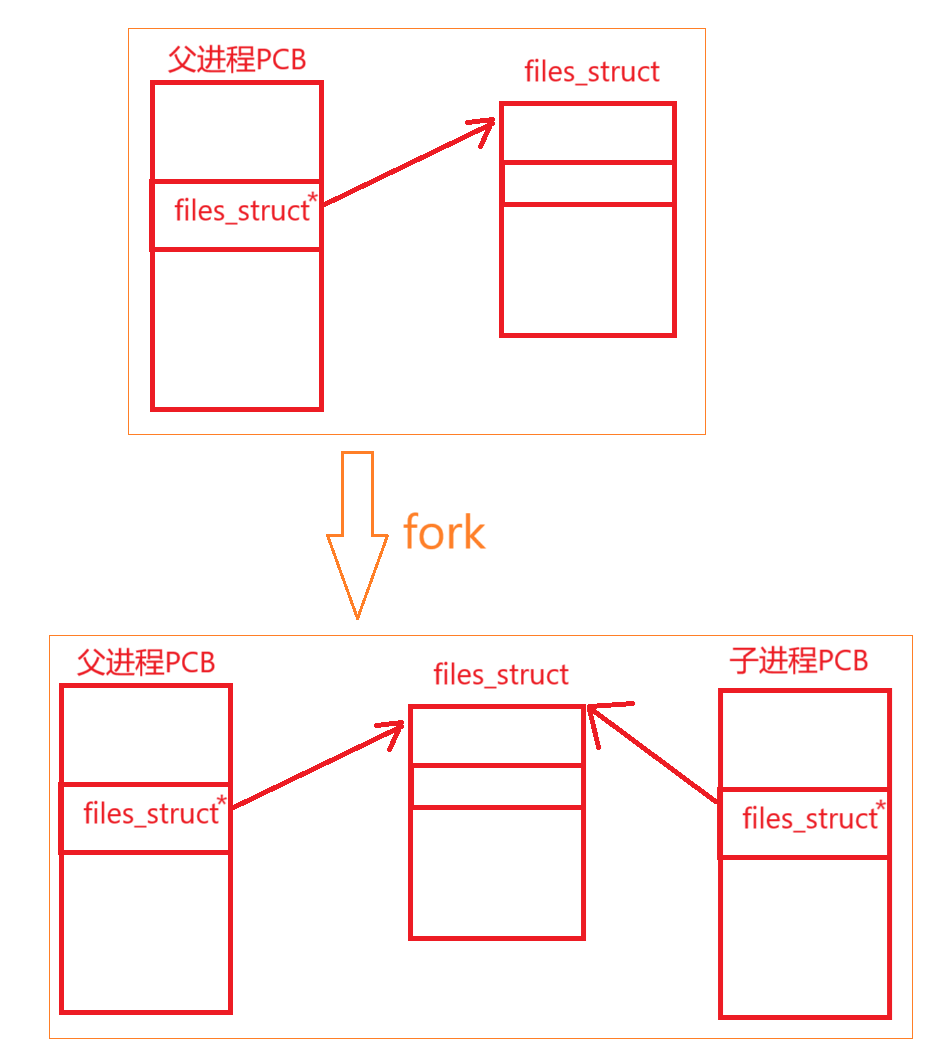
- 共享模式:在默认情况下,子进程会共享父进程的
files_struct结构体。这意味着父子进程共享相同的文件描述符表,也就是它们共享相同的fd_array。例如,若父进程打开了一个文件,文件描述符为fd,那么子进程也可以通过这个fd访问同一个文件。此时,files_struct中的atomic_t count原子计数器的值会增加,以记录有多少个进程(这里是父子两个进程)共享这个files_struct结构体。- 分离情况:当父子进程中的某一个对文件描述符进行修改操作(如
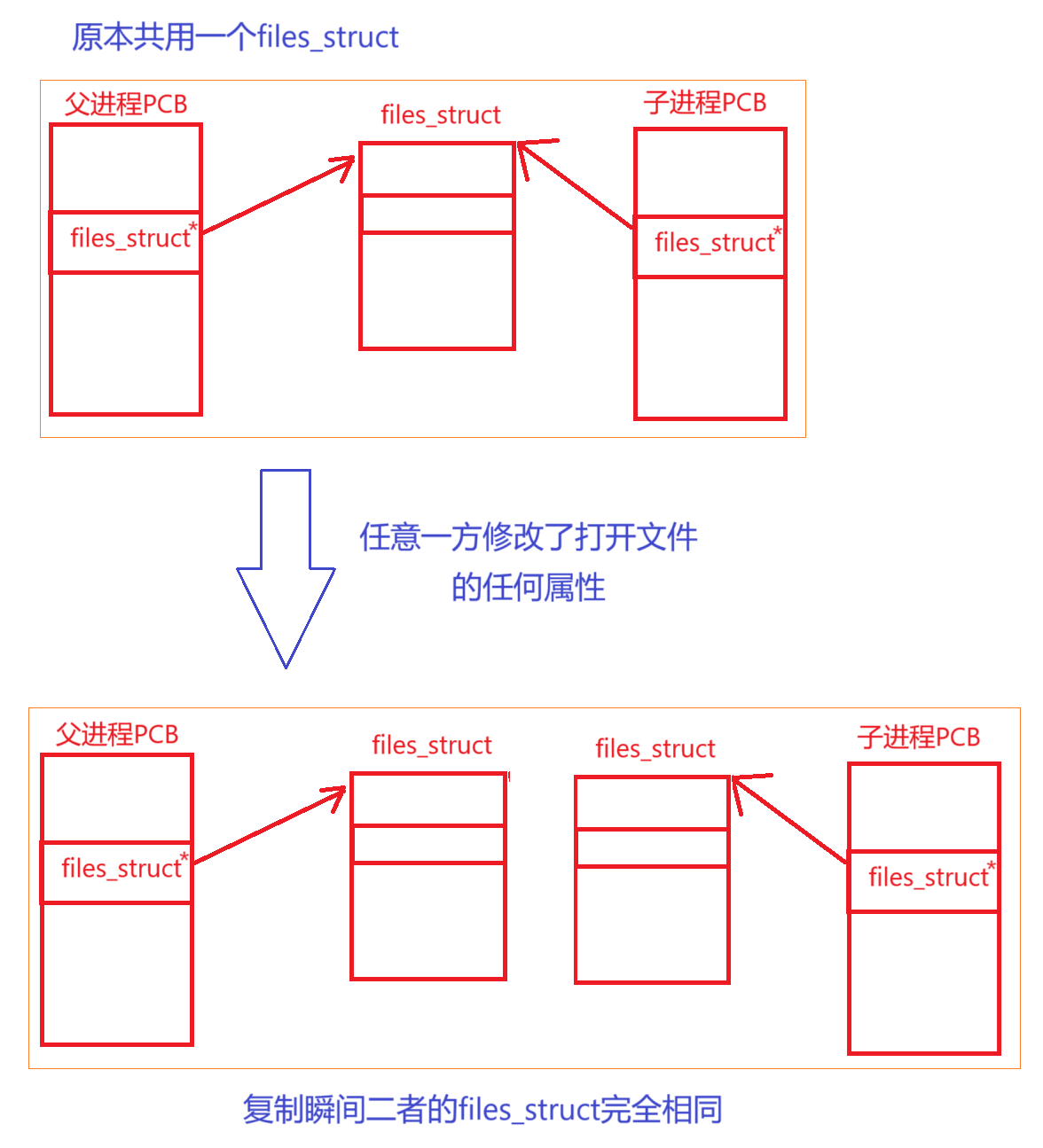
close一个文件描述符,或者通过fcntl更改文件描述符的属性)时,内核会为子进程创建一个新的files_struct结构体副本。这个副本会复制父进程files_struct中的大部分信息,包括文件描述符表(fdtable)的状态,但它们从此各自独立。这是因为写时复制技术不仅应用于内存,也适用于像files_struct这样的资源管理结构,目的是减少不必要的资源复制开销,提高系统性能。
当父子进程任意一个对自己打开的文件进行了修改,如修改文件权限、打开、关闭文件。内核会剥离二者的files_struct,各自独享一份,在复制瞬间二者是完全一样的。
四、读写文件时的三层缓冲区
我们先来看看C语言中FILE结构体是如何对fd进行封装的:
// 简化自glibc的stdio.h实现
typedef struct _IO_FILE FILE;struct _IO_FILE {int _flags; // 文件状态标志(如读写模式、缓冲模式等)
#define _IO_FILE_FLAGS 0x00000fff// 缓冲区相关char* _IO_buf_base; // 缓冲区起始地址char* _IO_buf_end; // 缓冲区结束地址(缓冲区大小 = _IO_buf_end - _IO_buf_base)char* _IO_ptr_base; // 当前缓冲区中数据的起始位置char* _IO_ptr_end; // 当前缓冲区中数据的结束位置(下一个写入位置)// 文件描述符int _fileno; // 封装的文件描述符(fd),关联内核的文件操作// 错误和EOF标志int _IO_errno; // 错误码(类似errno)int _IO_eof; // EOF标志(1表示已到达文件末尾)// 缓冲模式控制enum {_IO_UNBUFFERED, // 无缓冲(如stderr)_IO_LINE_BUF, // 行缓冲(如stdout,遇到换行符刷新)_IO_FULL_BUF // 全缓冲(默认模式,缓冲区满时刷新)} _IO_buf_mode;// 其他辅助成员(简化省略)struct _IO_FILE* _chain; // 用于链接多个FILE结构(如stdio列表)off_t _offset; // 当前文件位置(部分情况下使用)
};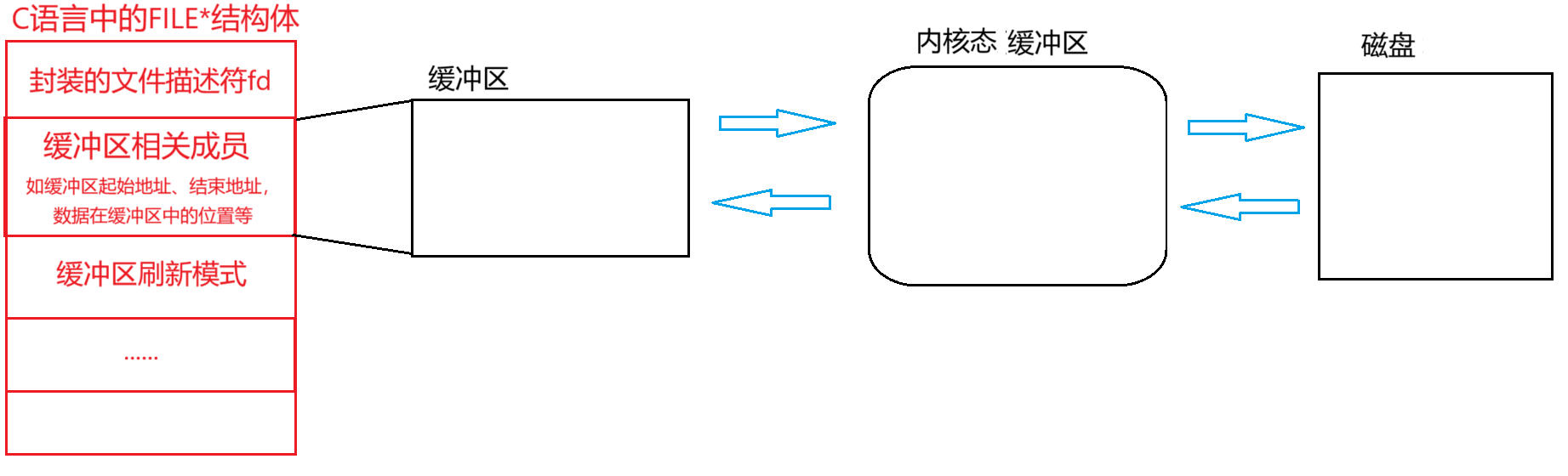
从这张图我们可以知道:
(1)每一个FILE结构体内部都有一个缓冲区,所以各个文件数据不会互相干扰。
(2)当想通过C语言向磁盘文件中写入数据的时候,会首先进入C语言层面的缓冲区、然后进入内核缓冲区,最后才能修改磁盘文件的内容。即经过了2次缓存。
(3)我们在使用C语言的时候,一般还会自己定义一个用于存放数据的缓冲区,比如数组、字符串然后才是将这些内容写入到FILE中的缓冲区,所以大多数实际使用经过了3次缓存。