大模型后训练——SFT实践
大型语言模型在能够执行指令和回答问题之前,需要经历预训练(Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助手、调整模型的语言风格,还是提升特定任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练方法——监督微调(SFT)、直接偏好优化(DPO)和在线强化学习(Online RL)——以及如何有效使用它们。
学习地址:SFT实践。
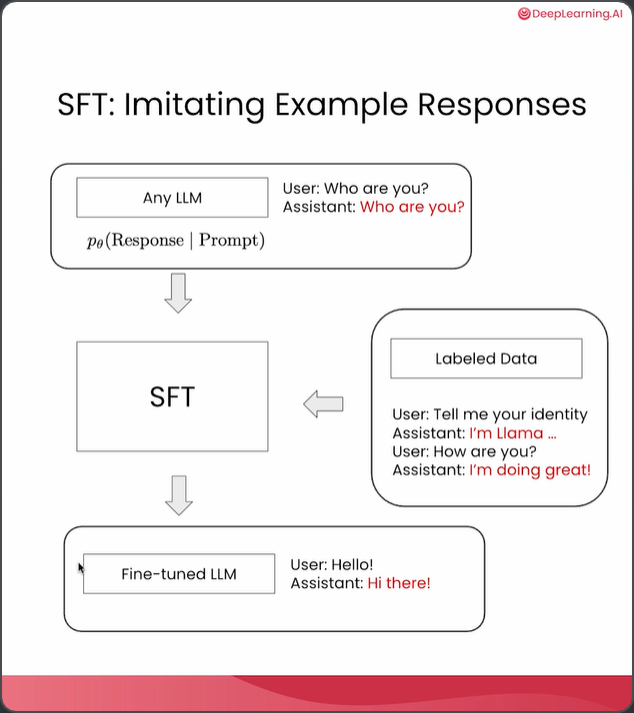
在本课程中,你将在一个小规模训练数据集上构建监督微调(SFT)流水线。如你所知,SFT即监督微调,用于模仿示例回复。我们通常从任意语言模型入手,这可以是一个基础模型,在该模型中,助手试图仅根据用户查询预测下一个最可能的token。然后,我们可以整理一些聊天数据或指令跟随数据,让助手以更自然的方式回复用户查询。 当用户问“你好吗?”时,理想的回答会是“我很好”。我们使用这些带标记的数据在基础模型之上进行这种监督微调,以获得一个经过微调的语言模型,它能更流畅地与你聊天。在实验中,我们将从一个基础语言模型开始,准备用于聊天和指令跟随的标记数据。并且准备用于聊天和指令跟随的标记数据。然后进行监督微调(SFT),以获得一个能够与用户聊天的微调模型。
import torch
import pandas as pd
from datasets import load_dataset, Dataset
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfig首先导入 PyTorch,这是一个主流的深度学习框架,用于张量计算和神经网络训练。后续模型的训练、推理都依赖它。然后导入 pandas 并简写为 pd。pandas 是数据分析和处理的常用库,主要用于表格数据的读取、处理和展示。这里用于展示和分析数据集。从 Hugging Face 的 datasets 库中导入 load_dataset 和 Dataset。load_dataset 用于加载公开数据集或本地数据集。Dataset 是数据集的基本结构,可以自定义或处理数据。
从 transformers 库导入:TrainingArguments:训练参数配置类,定义训练过程中的各种超参数(如 batch size、学习率等)。AutoTokenizer:自动加载与模型配套的分词器(tokenizer),用于文本与模型输入之间的转换。AutoModelForCausalLM:自动加载用于因果语言建模(Causal Language Modeling)的模型(如 GPT、Qwen 等)。
从 trl(Transformer Reinforcement Learning)库导入:SFTTrainer:用于有监督微调(Supervised Fine-Tuning, SFT)的训练器,简化流程。DataCollatorForCompletionOnlyLM:数据整理器,用于将数据批量整理成模型可用的格式,适用于只做补全任务的语言模型。SFTConfig:SFTTrainer 的配置类,用于设置训练相关参数。
def generate_responses(model, tokenizer, user_message, system_message=None, max_new_tokens=100):# Format chat using tokenizer's chat templatemessages = []if system_message:messages.append({"role": "system", "content": system_message})# We assume the data are all single-turn conversationmessages.append({"role": "user", "content": user_message})prompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False,)inputs = tokenizer(prompt, return_tensors="pt").to(model.device)# Recommended to use vllm, sglang or TensorRTwith torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=False,pad_token_id=tokenizer.eos_token_id,eos_token_id=tokenizer.eos_token_id,)input_len = inputs["input_ids"].shape[1]generated_ids = outputs[0][input_len:]response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()return response定义了一个名为generate_responses的函数,功能是基于给定的模型和分词器生成对话回复。
1. 函数定义与参数:
def generate_responses(model, tokenizer, user_message, system_message=None, max_new_tokens=100):定义generate_responses函数,接收model(模型)、tokenizer(分词器)、user_message(用户消息)作为必选参数,system_message(系统消息,默认为None)和max_new_tokens(生成新token的最大数量,默认为100)作为可选参数。
2. 消息格式化:
messages = []:初始化一个空列表messages,用于存储对话消息。if system_message:如果system_message不为空,执行messages.append({"role": "system", "content": system_message}),将系统消息添加到messages列表中,格式为字典,包含role(角色)为system和content(内容)为system_message。messages.append({"role": "user", "content": user_message}):将用户消息添加到messages列表中,格式同样为字典,role为user,content为user_message。
3. 生成提示:
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True, enable_thinking=False, ):使用分词器的apply_chat_template方法,基于messages列表生成提示prompt,tokenize=False表示不进行分词,add_generation_prompt=True表示添加生成提示,enable_thinking=False表示不启用思考模式。
4. 模型输入处理:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device):对生成的提示prompt使用分词器进行处理,并转换为PyTorch张量,然后将其移动到模型所在的设备上。
5. 模型生成回复:
with torch.no_grad():在不计算梯度的情况下执行以下代码块,以减少内存消耗。outputs = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, ):使用模型基于输入inputs生成回复,max_new_tokens指定生成新token的最大数量,do_sample=False表示不使用采样方法,pad_token_id和eos_token_id都设置为分词器的结束标记ID。
6. 提取回复:
input_len = inputs["input_ids"].shape[1]:获取输入ID的长度。generated_ids = outputs[0][input_len:]:从生成的输出中提取新生成的部分ID。response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip():使用分词器将生成的ID解码为文本,并去除特殊标记和两端的空白字符。
7. 返回回复:
return response:返回生成的回复文本。
def test_model_with_questions(model, tokenizer, questions, system_message=None, title="Model Output"):print(f"\n=== {title} ===")for i, question in enumerate(questions, 1):response = generate_responses(model, tokenizer, question, system_message)print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")定义的函数test_model_with_questions,其功能是使用给定的模型和分词器,针对一系列问题进行测试,并打印出模型的输入和输出。具体解释如下:
1. 函数定义与参数:
def test_model_with_questions(model, tokenizer, questions, system_message=None, title="Model Output"):`定义了一个名为test_model_with_questions的函数,它接受五个参数。
model:是一个预训练的模型,用于生成回答。
tokenizer:用于对输入文本进行分词处理,将文本转换为模型可以理解的格式。
questions:这是一个包含多个问题的列表,函数会依次对这些问题进行处理。
system_message:是一个可选参数,默认为None。
title:也是一个可选参数,默认值为“Model Output”,用于在打印输出时作为标题。
2. 函数主体:
print(f"\n=== {title} ==="):打印标题,格式为“===标题内容=== ”,用于区分不同的测试结果。
for i, question in enumerate(questions, 1):使用enumerate函数同时获取问题及其索引i,索引从1开始。
response = generate_responses(model, tokenizer, question, system_message):调用generate_responses函数(该函数未在给定代码中定义),使用model、tokenizer,针对当前问题question和system_message生成回答response。
print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")`:打印当前问题作为模型输入,以及模型生成的回答作为输出,格式为“Model Input 序号:\n问题内容\nModel Output 序号:\n回答内容\n” 。这样可以清晰地看到每个问题及其对应的模型回答。
def load_model_and_tokenizer(model_name, use_gpu = False):# Load base model and tokenizertokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name)if use_gpu:model.to("cuda")if not tokenizer.chat_template:tokenizer.chat_template = """{% for message in messages %}{% if message['role'] == 'system' %}System: {{ message['content'] }}\n{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>{% endif %}{% endfor %}"""# Tokenizer configif not tokenizer.pad_token:tokenizer.pad_token = tokenizer.eos_tokenreturn model, tokenizer定义了一个名为load_model_and_tokenizer的函数,用于加载模型和分词器。以下是对代码的详细解释:
1. 函数定义:def load_model_and_tokenizer(model_name, use_gpu = False):定义了一个名为load_model_and_tokenizer的函数,该函数接受两个参数:model_name(模型名称)和use_gpu(是否使用GPU,默认值False,如果有GPU可以改为True)。
2. 加载基础模型和分词器:tokenizer = AutoTokenizer.from_pretrained(model_name):使用AutoTokenizer从预训练模型库中加载指定名称的分词器。model = AutoModelForCausalLM.from_pretrained(model_name):使用AutoModelForCausalLM从预训练模型库中加载指定名称的因果语言模型。
3. 模型移动到GPU:if use_gpu:如果use_gpu参数为True,则执行以下代码model.to("cuda")`:将模型移动到CUDA设备(即GPU)上,以加速计算。
4. 设置聊天模板:if not tokenizer.chat_template:如果分词器没有聊天模板,则执行以下代码块。
tokenizer.chat_template = ...:定义一个聊天模板,该模板使用了jinja2模板语法,用于格式化聊天消息。在这个模板中,{% for message in messages %}循环遍历聊天消息列表,根据消息的role(角色)分别格式化输出System(系统消息)、User(用户消息)和Assistant(助手消息),并在助手消息后添加<|endoftext|>标记。
5. 分词器配置: if not tokenizer.pad_token:如果分词器没有填充标记(pad_token),则执行以下代码块。tokenizer.pad_token = tokenizer.eos_token:将填充标记设置为结束标记(eos_token)。
6. 返回结果:return model, tokenizer:返回加载的模型和分词器。
def display_dataset(dataset):# Visualize the dataset rows = []for i in range(3):example = dataset[i]user_msg = next(m['content'] for m in example['messages']if m['role'] == 'user')assistant_msg = next(m['content'] for m in example['messages']if m['role'] == 'assistant')rows.append({'User Prompt': user_msg,'Assistant Response': assistant_msg})# Display as tabledf = pd.DataFrame(rows)pd.set_option('display.max_colwidth', None) # Avoid truncating long stringsdisplay(df)定义了一个名为display_dataset的函数,功能是可视化数据集。具体解释如下:
1. 函数定义:def display_dataset(dataset),定义了一个名为display_dataset的函数,该函数接受一个参数dataset,这个参数应该是一个数据集。
2. 初始化列表:rows = [],创建一个空列表rows,用于存储后续提取的用户提示和助手回复信息。
3. 循环提取数据:for i in range(3),循环3次,即只处理数据集中的前3个示例。example = dataset[i],获取数据集中第i个示例。user_msg = next(m['content'] for m in example['messages'] if m['role'] == 'user'),从示例的messages列表中找到role为user的消息,并提取其content内容,赋值给user_msg。assistant_msg = next(m['content'] for m in example['messages'] if m['role'] == 'assistant'),类似地,找到role为assistant的消息,并提取其content内容,赋值给assistant_msg。
rows.append({'User Prompt': user_msg, 'Assistant Response': assistant_msg}),将提取到的用户提示和助手回复信息以字典形式添加到rows列表中。
4. 数据展示:df = pd.DataFrame(rows),使用pandas库将rows列表转换为数据框df。
pd.set_option('display.max_colwidth', None),设置pandas显示选项,避免截断长字符串。display(df),显示数据框df,从而可视化数据集的前3个示例中的用户提示和助手回复信息。
USE_GPU = Falsequestions = ["Give me an 1-sentence introduction of LLM.","Calculate 1+1-1","What's the difference between thread and process?"
]“USE_GPU = False”表示设置一个名为“USE_GPU”的变量,并将其赋值为布尔值“False”,意味着不使用图形处理器(GPU),通常在程序运行时,如果涉及到计算资源选择,这会让程序优先使用CPU而非GPU。“questions”是定义一个名为“questions”的列表。列表中包含三个元素:
“Give me an 1 - sentence introduction of LLM.”是一个字符串,内容为“给我一个关于大语言模型(LLM)的一句话介绍”,这可能是希望程序针对大语言模型给出简短描述。
“Calculate 1+1 - 1”同样是字符串,意思是“计算1 + 1 - 1”,推测程序可能具备运算能力,会对这个式子进行计算。
“What's the difference between thread and process?”也是字符串,意为“线程和进程之间的区别是什么?”,这可能是期望程序能阐述线程和进程二者差异。
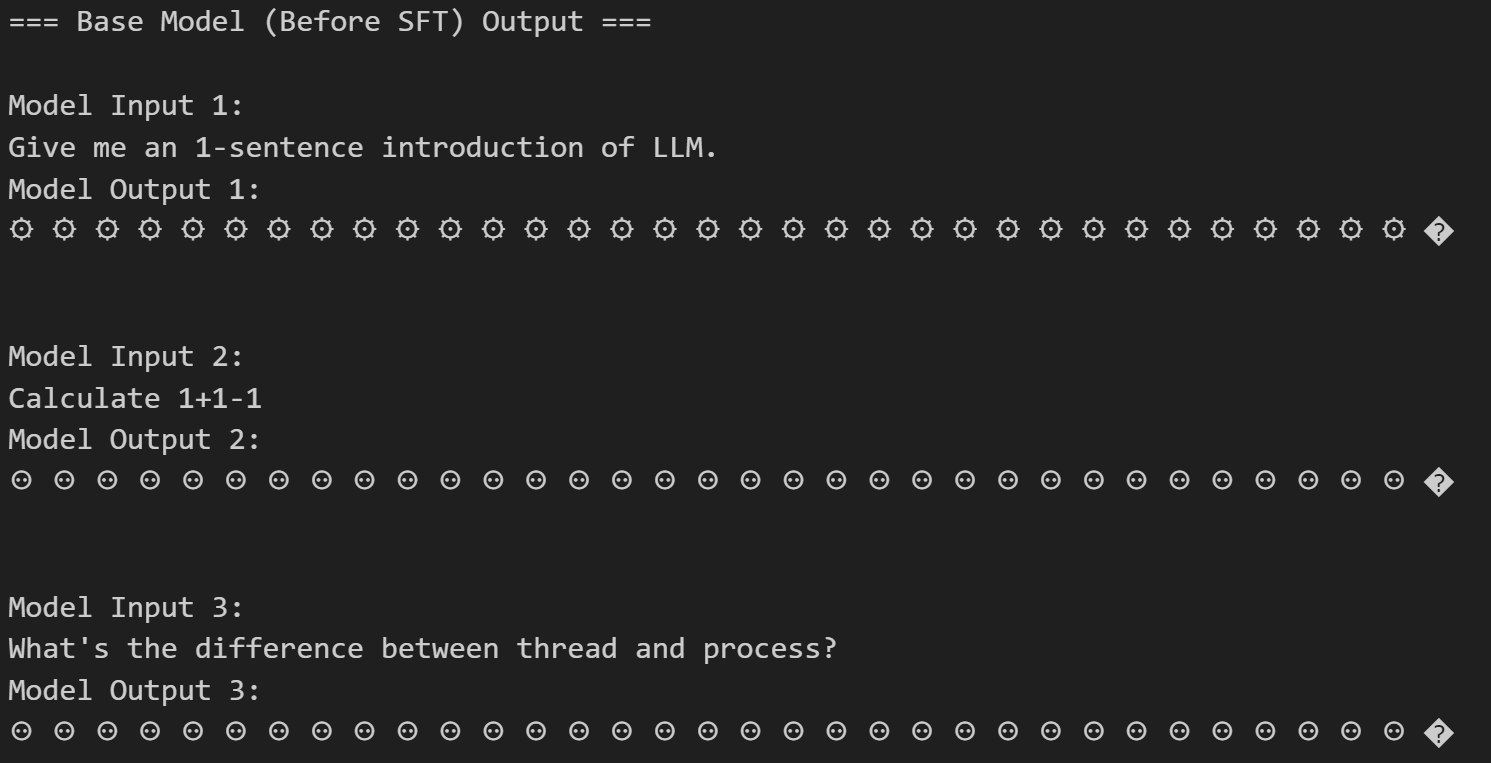
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen3-0.6B-Base", USE_GPU)test_model_with_questions(model, tokenizer, questions, title="Base Model (Before SFT) Output")del model, tokenizer1. model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen3-0.6B-Base", USE_GPU):调用load_model_and_tokenizer函数,传入模型路径"./models/Qwen/Qwen3-0.6B-Base"和是否使用GPU的标志USE_GPU,该函数返回模型model和分词器tokenizer。
2. test_model_with_questions(model, tokenizer, questions, title="Base Model (Before SFT) Output"):调用test_model_with_questions函数,传入模型model、分词器tokenizer、问题列表questions以及标题"Base Model (Before SFT) Output",这个函数可能是用于使用给定的问题测试模型,并以指定标题展示相关输出。
3. del model, tokenizer:删除之前加载的模型model和分词器tokenizer,释放相关资源。
输出结果如下:
model_name = "./Qwen3-0.6B-Base"
model, tokenizer = load_model_and_tokenizer(model_name, USE_GPU)train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]
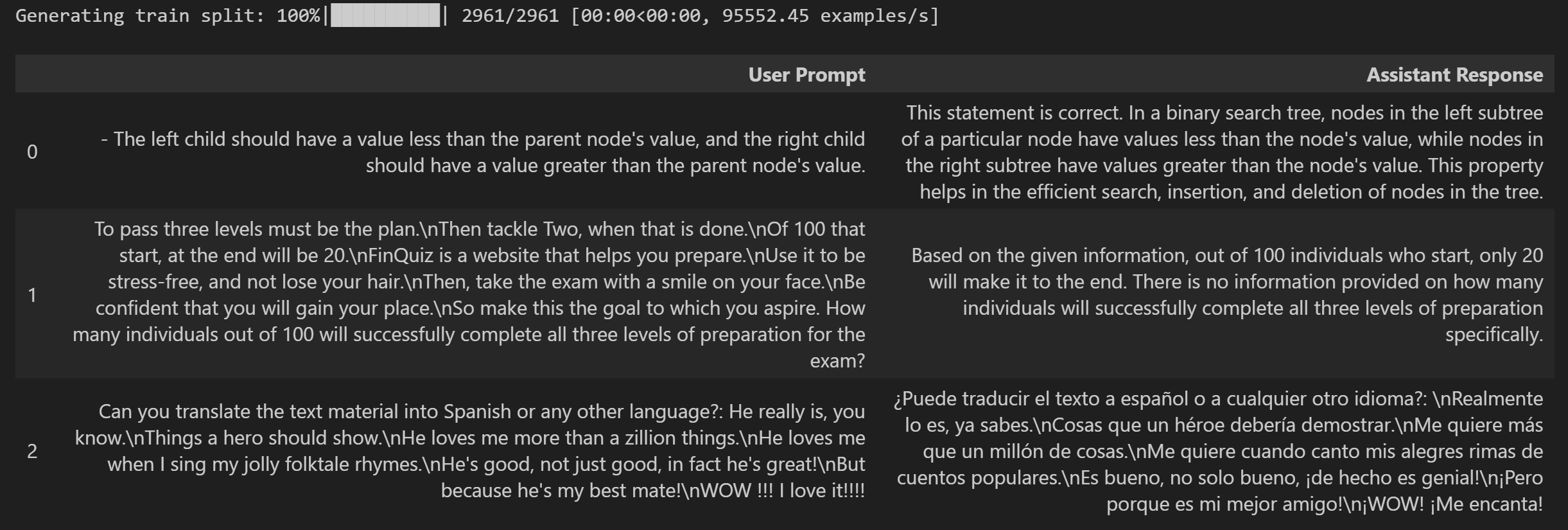
if not USE_GPU:train_dataset=train_dataset.select(range(100))display_dataset(train_dataset)train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]`:从名为“banghua/DL-SFT-Dataset”的数据集加载数据,并选取其中的“train”(训练集)部分,将其赋值给train_dataset。
if not USE_GPU:如果USE_GPU这个变量的值为False,即不使用GPU时。train_dataset=train_dataset.select(range(100)):从train_dataset中选取前100个样本,对train_dataset进行了重新赋值。display_dataset(train_dataset):调用display_dataset函数,并将train_dataset作为参数传入,用于展示或呈现这个训练数据集。
输出结果如下:
# SFTTrainer config
sft_config = SFTConfig(learning_rate=8e-5, # Learning rate for training. num_train_epochs=1, # Set the number of epochs to train the model.per_device_train_batch_size=1, # Batch size for each device (e.g., GPU) during training. gradient_accumulation_steps=8, # Number of steps before performing a backward/update pass to accumulate gradients.gradient_checkpointing=False, # Enable gradient checkpointing to reduce memory usage during training at the cost of slower training speed.logging_steps=2, # Frequency of logging training progress (log every 2 steps).)1. learning_rate=8e-5:设置训练时的学习率为8乘以10的负5次方,学习率决定了模型在训练过程中参数更新的步长,合适的学习率对模型的收敛和性能很关键。
2. num_train_epochs=1:设定训练模型的轮数为1,即模型将完整遍历训练数据集1次。
3. per_device_train_batch_size=1:指定训练期间每个设备(如GPU)上的训练批次大小为1,意味着每次向设备输入1个样本进行训练。
4. gradient_accumulation_steps=8:表示在执行反向传播/更新步骤之前,要累积梯度的步数为8,这样可以在不增加实际批次大小的情况下,模拟更大批次的训练效果。
5. gradient_checkpointing=False:是否启用梯度检查点,这里设置为不启用,启用梯度检查点可以减少训练时的内存使用,但会降低训练速度。
6. logging_steps=2:设置记录训练进度的频率,每2步记录一次训练过程中的相关信息。
sft_trainer = SFTTrainer(model=model,args=sft_config,train_dataset=train_dataset, processing_class=tokenizer,
)
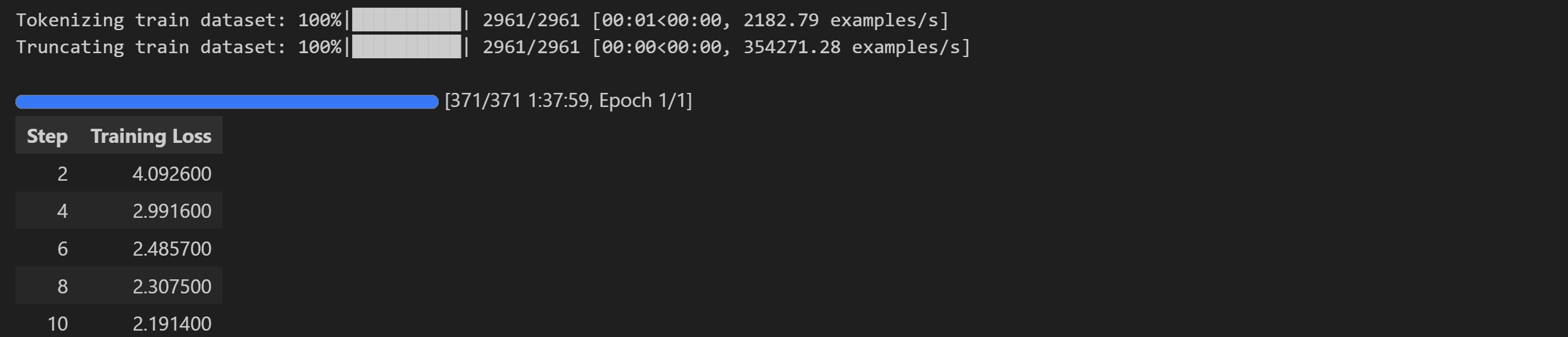
sft_trainer.train()这段代码定义了一个名为sft_trainer的对象,通过SFTTrainer类进行实例化。在实例化过程中,传入了多个参数:model表示模型,args为配置参数sft_config,train_dataset是训练数据集,processing_class使用了tokenizer。之后调用sft_trainer对象的train方法来启动训练过程。
训练过程如图所示:
if not USE_GPU: # move model to CPU when GPU isn’t requestedsft_trainer.model.to("cpu")
test_model_with_questions(sft_trainer.model, tokenizer, questions, title="Base Model (After SFT) Output")if not USE_GPU:这是一个条件判断语句,如果变量USE_GPU的值为假(即没有要求使用GPU),则执行后续代码块。sft_trainer.model.to("cpu"):在上述条件满足时,将sft_trainer对象中的模型移动到CPU上,意味着模型的计算将在CPU上进行test_model_with_questions(sft_trainer.model, tokenizer, questions, title="Base Model (After SFT) Output"):调用test_model_with_questions函数,使用sft_trainer的模型、tokenizer以及questions来测试模型,并且给这次测试的标题设置为Base Model (After SFT) Output。
测试结果如下图所示:



这里可以看到SFT微调的效果,和微调前形成鲜明的对比。