(SAM)Segment Anything论文精读(逐段解析)
Segment Anything论文精读(逐段解析)
论文地址:https://arxiv.org/abs/2304.02643
Meta AI Research, FAIR
2023
【论文总结】SAM (Segment Anything Model) 是一个可提示的通用图像分割基础模型,其核心目标是通过统一的提示接口实现对任意对象的零样本分割能力。1、技术特点:
- 可提示分割任务设计:将分割问题重新定义为条件生成任务,支持点击、框选、掩码和文本等多种提示形式,使同一模型能适应从交互式分割到自动对象检测的各种应用场景。
- 三组件架构设计:
- 重量级图像编码器:基于MAE预训练的ViT-H,一次性提取图像特征可复用于多次提示交互
- 轻量级提示编码器:统一处理稀疏提示(点、框、文本)和密集提示(掩码)的多模态输入
- 快速掩码解码器:通过双向交叉注意力融合视觉特征与提示信息,50ms内完成掩码生成
- 歧义感知机制:模型可为单个提示输出多个有效掩码并提供置信度评分,自然处理现实世界中普遍存在的分割歧义问题(如点击衬衫可能指代衣服本身或穿衣服的人)。
2、关键技术创新:
- 数据引擎三阶段策略:从人工辅助标注→半自动标注→全自动标注的渐进式数据生产流程,最终实现平均每图100个高质量掩码的自动生成。
- SA-1B数据集构建:通过数据引擎创建1100万图像、11亿掩码的大规模数据集,比现有最大分割数据集多400倍掩码数量。
- 零样本迁移能力:通过提示工程适应边缘检测、对象提议生成、实例分割等多种下游任务,无需针对性训练。
论文基本上都是在描述模型制作过程和性能,没有太多算法点需要解析,所以大部分都是译文。
Abstract
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
【翻译】我们介绍Segment Anything (SA)项目:一个用于图像分割的新任务、模型和数据集。使用我们高效的模型在数据收集循环中,我们构建了迄今为止最大的分割数据集,在1100万张有许可证且保护隐私的图像上拥有超过10亿个掩码。该模型被设计和训练为可提示的,因此它可以零样本迁移到新的图像分布和任务。我们在众多任务上评估了其能力,发现其零样本性能令人印象深刻——通常与之前的完全监督结果相比具有竞争力,甚至更优越。我们在https://segment-anything.com发布Segment Anything Model (SAM)和相应的数据集(SA-1B),包含10亿个掩码和1100万张图像,以促进计算机视觉基础模型的研究。
【解析】SAM项目的三个关键创新点。首先是"数据收集循环"概念,这是一个自我强化的训练过程:模型帮助标注数据,新数据又反过来改进模型,这种循环机制使得数据集规模能够达到前所未有的10亿级别。其次是"可提示性"设计,这打破了传统分割模型只能处理固定任务的局限性,通过提示工程使模型能够适应各种不同的分割需求。最后是"零样本迁移"能力,模型无需针对新任务进行重新训练,仅凭提示就能在未见过的数据分布上表现出色。
Figure 1: We aim to build a foundation model for segmentation by introducing three interconnected components: a promptable segmentation task, a segmentation model (SAM) that powers data annotation and enables zero-shot transfer to a range of tasks via prompt engineering, and a data engine for collecting SA-1B, our dataset of over 1 billion masks.
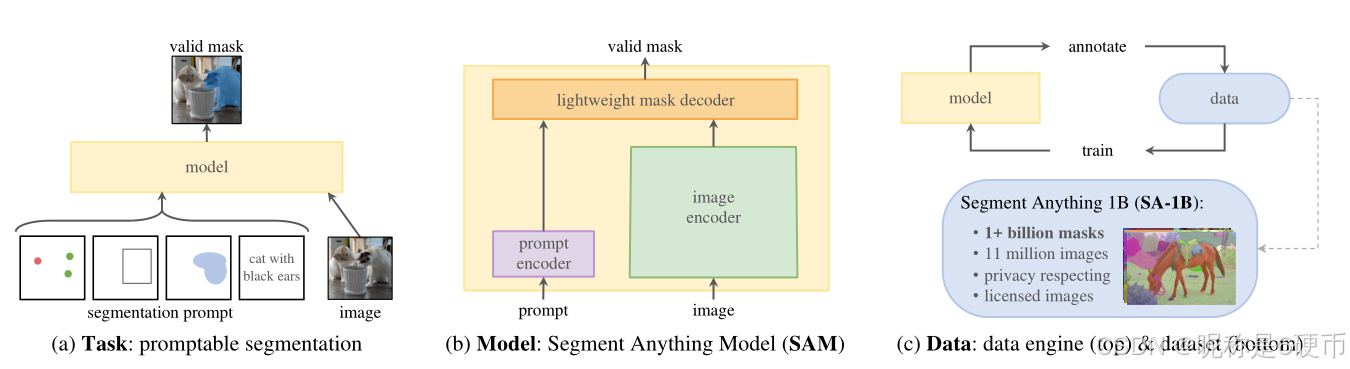
【翻译】图1:我们旨在通过引入三个相互关联的组件来构建分割的基础模型:一个可提示的分割任务、一个支持数据标注并通过提示工程实现向一系列任务零样本迁移的分割模型(SAM),以及一个用于收集SA-1B(我们超过10亿个掩码的数据集)的数据引擎。
【解析】这个图展示了SAM项目的系统架构,三个组件之间的协同关系。可提示分割任务定义了问题框架,即如何通过各种形式的提示来指导分割;SAM模型是核心执行组件,它既能理解提示又能生成高质量分割结果;数据引擎是规模化的关键,它自动化地生成大量标注数据。这三个组件形成了一个闭环系统:任务定义指导模型设计,模型执行驱动数据生成,大规模数据又反过来提升模型性能。
1. Introduction
Large language models pre-trained on web-scale datasets are revolutionizing NLP with strong zero-shot and few-shot generalization [10]. These “foundation models” [8] can generalize to tasks and data distributions beyond those seen during training. This capability is often implemented with prompt engineering in which hand-crafted text is used to prompt the language model to generate a valid textual response for the task at hand. When scaled and trained with abundant text corpora from the web, these models’ zero and few-shot performance compares surprisingly well to (even matching in some cases) fine-tuned models [10, 21]. Empirical trends show this behavior improving with model scale, dataset size, and total training compute [56, 10, 21, 51].
【翻译】在网络规模数据集上预训练的大型语言模型正在通过强大的零样本和少样本泛化能力彻底改变自然语言处理领域[10]。这些"基础模型"[8]能够泛化到训练期间未见过的任务和数据分布。这种能力通常通过提示工程来实现,其中使用手工制作的文本来提示语言模型为手头的任务生成有效的文本响应。当这些模型在网络上丰富的文本语料库上进行规模化训练时,它们的零样本和少样本性能与微调模型相比表现惊人地好(在某些情况下甚至相匹配)[10, 21]。经验趋势表明,这种行为随着模型规模、数据集大小和总训练计算量的增加而改善[56, 10, 21, 51]。
Foundation models have also been explored in computer vision, albeit to a lesser extent. Perhaps the most prominent illustration aligns paired text and images from the web. For example, CLIP [82] and ALIGN [55] use contrastive learning to train text and image encoders that align the two modalities. Once trained, engineered text prompts enable zero-shot generalization to novel visual concepts and data distributions. Such encoders also compose effectively with other modules to enable downstream tasks, such as image generation (e.g., DALL·E [83]). While much progress has been made on vision and language encoders, computer vision includes a wide range of problems beyond this scope, and for many of these, abundant training data does not exist.
【翻译】基础模型在计算机视觉领域也得到了探索,尽管程度较小。也许最突出的例子是对齐来自网络的成对文本和图像。例如,CLIP [82]和ALIGN [55]使用对比学习来训练文本和图像编码器,使两种模态对齐。一旦训练完成,精心设计的文本提示能够实现对新颖视觉概念和数据分布的零样本泛化。这样的编码器还能与其他模块有效组合,以实现下游任务,如图像生成(例如,DALL·E [83])。虽然在视觉和语言编码器方面已经取得了很大进展,但计算机视觉包含了超出这个范围的广泛问题,对于其中的许多问题,并不存在丰富的训练数据。
In this work, our goal is to build aaa foundation model for image segmentation. That is, we seek to develop a promptable model and pre-train it on a broad dataset using a task that enables powerful generalization. With this model, we aim to solve a range of downstream segmentation problems on new data distributions using prompt engineering.
【翻译】在这项工作中,我们的目标是构建一个用于图像分割的基础模型。也就是说,我们寻求开发一个可提示的模型,并在一个广泛的数据集上使用能够实现强大泛化的任务对其进行预训练。利用这个模型,我们旨在使用提示工程来解决新数据分布上的一系列下游分割问题。
【解析】这里作者指出SAM项目的目标:将基础模型的成功经验迁移到图像分割领域。可提示性是关键特征,它使得同一个模型能够通过不同的输入提示来适应各种分割任务,而不需要针对每个特定任务重新训练。广泛数据集的预训练策略确保模型能够学习到丰富的视觉表示和分割知识。
The success of this plan hinges on three components: task, model, and data. To develop them, we address the following questions about image segmentation:
【翻译】这个计划的成功取决于三个组成部分:任务、模型和数据。为了开发它们,我们解决了关于图像分割的以下问题:
- What task will enable zero-shot generalization?
- What is the corresponding model architecture?
- What data can power this task and model?
【翻译】1. 什么任务将能够实现零样本泛化?
2. 相应的模型架构是什么?
3. 什么数据能够支撑这个任务和模型?
【解析】第一个问题关于任务设计,需要找到一个既足够通用又能提供强监督信号的学习目标,使得模型在训练后能够无需额外调整就适应新的分割场景。第二个问题涉及架构选择,需要设计一个既能理解多样化提示又能高效生成分割结果的网络结构。第三个问题是数据获取,即如何在缺乏大规模现成标注数据的情况下,创造性地构建足够支撑基础模型训练的数据集。
These questions are entangled and require a comprehensive solution. We start by defining a promptable segmentation task that is general enough to provide a powerful pretraining objective and to enable a wide range of downstream applications. This task requires a model that supports flexible prompting and can output segmentation masks in realtime when prompted to allow for interactive use. To train our model, we need a diverse, large-scale source of data. Unfortunately, there is no web-scale data source for segmentation; to address this, we build a “data engine”, i.e., we iterate between using our efficient model to assist in data collection and using the newly collected data to improve the model. We introduce each interconnected component next, followed by the dataset we created and the experiments that demonstrate the effectiveness of our approach.
【翻译】这些问题是相互关联的,需要一个综合的解决方案。我们首先定义一个可提示的分割任务,该任务足够通用,可以提供强大的预训练目标并支持广泛的下游应用。这个任务需要一个支持灵活提示并能在提示时实时输出分割掩码的模型,以允许交互式使用。为了训练我们的模型,我们需要一个多样化的大规模数据源。不幸的是,分割没有网络规模的数据源;为了解决这个问题,我们构建了一个"数据引擎",即我们在使用高效模型协助数据收集和使用新收集的数据改进模型之间进行迭代。接下来我们将介绍每个相互关联的组件,然后是我们创建的数据集和证明我们方法有效性的实验。
【解析】三个问题(任务设计、模型架构、数据获取)相互制约,须协同考虑。可提示分割任务的设计,要能作为有效的预训练目标学到丰富的视觉表示,又要能通过提示工程适应各种下游任务。实时性要求在性能和效率之间找到最佳平衡点。数据引擎概念解决数据稀缺问题,通过模型辅助标注和数据驱动改进之间的循环迭代,实现数据规模的指数级扩张。
Task (§2). In NLP and more recently computer vision, foundation models are a promising development that can perform zero-shot and few-shot learning for new datasets and tasks often by using “prompting” techniques. Inspired by this line of work, we propose the promptable segmentation task, where the goal is to return a valid segmentation mask given any segmentation prompt (see Fig. 1a). A prompt simply specifies what to segment in an image, e.g., a prompt can include spatial or text information identifying an object. The requirement of a valid output mask means that even when a prompt is ambiguous and could refer to multiple objects (for example, a point on a shirt may indicate either the shirt or the person wearing it), the output should be a reasonable mask for at least one of those objects. We use the promptable segmentation task as both a pre-training objective and to solve general downstream segmentation tasks via prompt engineering.
【翻译】任务(§2)。在自然语言处理以及最近的计算机视觉中,基础模型是一个有前途的发展,通常通过使用"提示"技术能够对新数据集和任务执行零样本和少样本学习。受这一研究方向的启发,我们提出了可提示分割任务,其目标是在给定任何分割提示的情况下返回有效的分割掩码(见图1a)。提示只是指定在图像中要分割什么,例如,提示可以包括识别对象的空间或文本信息。有效输出掩码的要求说明,即使当提示模糊且可能指向多个对象时(例如,衬衫上的一个点可能表示衬衫或穿着它的人),输出也应该是这些对象中至少一个的合理掩码。我们将可提示分割任务既用作预训练目标,也通过提示工程用于解决一般的下游分割任务。
【解析】可提示分割任务的设计源于大语言模型的成功经验,将提示机制从文本领域迁移到视觉分割领域。将分割问题重新定义为条件生成问题:给定图像和提示,生成相应的分割掩码。提示的多样性(点击、框选、文本描述)使得同一个模型能够适应不同的交互方式和应用场景。"有效掩码"的要求处理了现实世界中普遍存在的歧义性问题,通过允许模型在面对歧义时选择任一合理解释,避免了完全错误的输出。
Model (§3). The promptable segmentation task and the goal of real-world use impose constraints on the model architecture. In particular, the model must support flexible prompts, needs to compute masks in amortized real-time to allow interactive use, and must be ambiguity-aware. Surprisingly, we find that a simple design satisfies all three constraints: a powerful image encoder computes an image embedding, a prompt encoder embeds prompts, and then the two information sources are combined in a lightweight mask decoder that predicts segmentation masks. We refer to this model as the Segment Anything Model, or SAM (see Fig. 1b). By separating SAM into an image encoder and a fast prompt encoder / mask decoder, the same image embedding can be reused (and its cost amortized) with different prompts. Given an image embedding, the prompt encoder and mask decoder predict a mask from a prompt in ∼50ms{\sim}50\mathrm{ms}∼50ms in a web browser. We focus on point, box, and mask prompts, and also present initial results with free-form text prompts. To make SAM ambiguity-aware, we design it to predict multiple masks for a single prompt allowing SAM to naturally handle ambiguity, such as the shirt vs. person example.
【翻译】模型(§3)。可提示分割任务和现实世界使用的目标对模型架构施加了约束。特别是,模型必须支持灵活的提示,需要在摊销实时中计算掩码以允许交互式使用,并且必须具有歧义感知能力。令人惊讶的是,我们发现一个简单的设计满足了所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源在一个轻量级掩码解码器中结合,该解码器预测分割掩码。我们将这个模型称为分割一切模型,或SAM(见图1b)。通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,相同的图像嵌入可以在不同提示下重复使用(并且其成本被摊销)。给定图像嵌入,提示编码器和掩码解码器在网络浏览器中从提示预测掩码需要∼50ms{\sim}50\mathrm{ms}∼50ms。我们专注于点、框和掩码提示,同时也展示了自由文本提示的初步结果。为了使SAM具有歧义感知能力,我们设计它为单个提示预测多个掩码,允许SAM自然地处理歧义,如衬衫与人的例子。
Data engine (§4). To achieve strong generalization to new data distributions, we found it necessary to train SAM on a large and diverse set of masks, beyond any segmentation dataset that already exists. While a typical approach for foundation models is to obtain data online [82], masks are not naturally abundant and thus we need an alternative strategy. Our solution is to build a “data engine”, i.e., we co-develop our model with model-in-the-loop dataset annotation (see Fig. 1c). Our data engine has three stages: assisted-manual, semi-automatic, and fully automatic. In the first stage, SAM assists annotators in annotating masks, similar to a classic interactive segmentation setup. In the second stage, SAM can automatically generate masks for a subset of objects by prompting it with likely object locations and annotators focus on annotating the remaining objects, helping increase mask diversity. In the final stage, we prompt SAM with a regular grid of foreground points, yielding on average ∼100\mathord{\sim}100∼100 high-quality masks per image.
【翻译】数据引擎(§4)。为了实现对新数据分布的强泛化,我们发现有必要在大量多样的掩码集合上训练SAM,超越任何现有的分割数据集。虽然基础模型的典型方法是在线获取数据[82],但掩码并不是自然丰富的,因此我们需要一种替代策略。我们的解决方案是构建一个"数据引擎",即我们与模型在环数据集标注共同开发我们的模型(见图1c)。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM协助标注者标注掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以通过用可能的对象位置提示它来自动为对象子集生成掩码,标注者专注于标注剩余对象,帮助增加掩码多样性。在最后阶段,我们用前景点的规则网格提示SAM,平均每张图像产生∼100\mathord{\sim}100∼100个高质量掩码。
【解析】数据引擎采用渐进式自举策略,第一阶段建立基础能力,人工标注者使用SAM作为辅助工具,类似传统的交互式分割,但人机协作模式显著提高了标注效率和质量。第二阶段实现部分自动化,SAM开始承担更多标注工作,能够自主处理一部分明确的分割目标,而人工标注者则专注于处理更复杂和边缘的情况。第三阶段达到全自动化生产,SAM通过规则网格点击实现完全自主的掩码生成,平均每张图像可产生∼100\mathord{\sim}100∼100个高质量掩码,实现了数据规模的指数级扩张。
Dataset (§5). Our final dataset, SA-1B, includes more than lB masks from 11M11M11M licensed and privacy-preserving images (see Fig. 2). SA-1B, collected fully automatically using the final stage of our data engine, has 400×400\times400× more masks than any existing segmentation dataset [66, 44, 117, 60], and as we verify extensively, the masks are of high quality and diversity. Beyond its use in training SAM to be robust and general, we hope SA-1B becomes a valuable resource for research aiming to build new foundation models.
【翻译】数据集(§5)。我们的最终数据集SA-1B包含来自11M11M11M张经过许可且保护隐私的图像的超过1B个掩码(见图2)。SA-1B使用我们数据引擎的最终阶段完全自动收集,比任何现有分割数据集[66, 44, 117, 60]的掩码多400×400\times400×,并且如我们广泛验证的那样,这些掩码具有高质量和多样性。除了用于训练SAM使其具有鲁棒性和通用性外,我们希望SA-1B成为旨在构建新基础模型研究的宝贵资源。
【解析】SA-1B数据集的构建采用了完全自动化的标注流程,1100万张图像包含超过10亿个分割掩码。
Responsible AI (§6). We study and report on potential fairness concerns and biases when using SA-1B and SAM. Images in SA-1B span a geographically and economically diverse set of countries and we found that SAM performs similarly across different groups of people. Together, we hope this will make our work more equitable for real-world use cases. We provide model and dataset cards in the appendix.
【翻译】负责任的AI(§6)。我们研究并报告在使用SA-1B和SAM时的潜在公平性担忧和偏见。SA-1B中的图像跨越地理和经济多样的国家集合,我们发现SAM在不同人群中表现相似。总的来说,我们希望这将使我们的工作在现实世界使用案例中更加公平。我们在附录中提供了模型和数据集卡片。
Experiments (§7). We extensively evaluate SAM. First, using a diverse new suite of 23 segmentation datasets, we find that SAM produces high-quality masks from a single foreground point, often only slightly below that of the manually annotated ground truth. Second, we find consistently strong quantitative and qualitative results on a variety of downstream tasks under a zero-shot transfer protocol using prompt engineering, including edge detection, object proposal generation, instance segmentation, and a preliminary exploration of text-to-mask prediction. These results suggest that SAM can be used out-of-the-box with prompt engineering to solve a variety of tasks involving object and image distributions beyond SAM’s training data. Nevertheless, room for improvement remains, as we discuss in §8\S8§8 .
【翻译】实验(§7)。我们广泛评估了SAM。首先,使用23个分割数据集的多样化新套件,我们发现SAM从单个前景点产生高质量掩码,通常仅略低于手动标注的真实标准。其次,我们在使用提示工程的零样本迁移协议下,在各种下游任务上发现了持续强劲的定量和定性结果,包括边缘检测、对象提议生成、实例分割以及文本到掩码预测的初步探索。这些结果表明,SAM可以通过提示工程开箱即用地解决涉及SAM训练数据之外的对象和图像分布的各种任务。尽管如此,仍有改进空间,正如我们在§8\S8§8中讨论的。
Release. We are releasing the SA-1B dataset for research purposes and making SAM available under a permissive open license (Apache 2.0) at https://segment-anything.com. We also showcase SAM’s capabilities with an online demo.
【翻译】发布。我们发布SA-1B数据集用于研究目的,并在https://segment-anything.com 以宽松的开源许可证(Apache 2.0)提供SAM。我们还通过在线演示展示SAM的能力。
Figure 2: Example images with overlaid masks from our newly introduced dataset, SA-1B. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as we verify by human ratings and numerous experiments, are of high quality and diversity. We group images by number of masks per image for visualization (there are ∼100\mathord{\sim}100∼100 masks per image on average).

【翻译】图2:来自我们新引入的数据集SA-1B的带有叠加掩码的示例图像。SA-1B包含1100万张多样化、高分辨率、经许可且保护隐私的图像和11亿个高质量分割掩码。这些掩码完全由SAM自动标注,正如我们通过人工评级和众多实验验证的那样,具有高质量和多样性。我们按每张图像的掩码数量对图像进行分组以进行可视化(平均每张图像有∼100\mathord{\sim}100∼100个掩码)。
2. Segment Anything Task
We take inspiration from NLP, where the next token prediction task is used for foundation model pre-training and to solve diverse downstream tasks via prompt engineering [10]. To build a foundation model for segmentation, we aim to define a task with analogous capabilities.
【翻译】我们从自然语言处理中汲取灵感,其中下一个词元预测任务用于基础模型预训练,并通过提示工程解决各种下游任务[10]。为了构建分割的基础模型,我们旨在定义一个具有类似能力的任务。
Task. We start by translating the idea of a prompt from NLP to segmentation, where a prompt can be a set of foreground / background points, a rough box or mask, free-form text, or, in general, any information indicating what to segment in an image. The promptable segmentation task, then, is to return a valid segmentation mask given any prompt. The requirement of a “valid” mask simply means that even when a prompt is ambiguous and could refer to multiple objects (e.g., recall the shirt vs. person example, and see Fig. 3), the output should be a reasonable mask for at least one of those objects. This requirement is similar to expecting a language model to output a coherent response to an ambiguous prompt. We choose this task because it leads to a natural pre-training algorithm and a general method for zero-shot transfer to downstream segmentation tasks via prompting.
【翻译】任务。我们首先将提示的概念从NLP转换到分割,其中提示可以是一组前景/背景点、粗略的框或掩码、自由文本,或者一般来说,任何指示在图像中分割什么的信息。因此,可提示分割任务是在给定任何提示的情况下返回有效的分割掩码。"有效"掩码的要求简单地说明即使当提示模糊且可能指向多个对象时(例如,回想衬衫与人的例子,见图3),输出也应该是这些对象中至少一个的合理掩码。这个要求类似于期望语言模型对模糊提示输出连贯的响应。我们选择这个任务是因为它导致了自然的预训练算法和通过提示进行下游分割任务零样本迁移的通用方法。
【解析】可提示分割任务的核心在于将NLP中的提示概念具体化为视觉分割领域的多模态输入:点击提示模拟用户的直接交互,框选提示类似目标检测的输出,掩码提示可以来自其他分割模型的结果,文本提示则实现了语义级别的分割指令。"有效掩码"处理了现实世界中无处不在的歧义性问题。当用户点击一个人的衬衫时,可能想要分割衬衫本身,也可能想要分割整个人,模型需要在这种歧义情况下给出至少一个合理的解释,而不是完全错误的结果。零样本迁移能力的实现依赖于预训练阶段学到的通用分割知识,通过不同类型的提示,同一个模型可以适应从交互式分割到自动对象检测等各种应用场景。
Pre-training. The promptable segmentation task suggests a natural pre-training algorithm that simulates a sequence of prompts (e.g., points, boxes, masks) for each training sample and compares the model’s mask predictions against the ground truth. We adapt this method from interactive segmentation [109, 70], although unlike interactive segmentation whose aim is to eventually predict a valid mask after enough user input, our aim is to always predict a valid mask for any prompt even when the prompt is ambiguous. This ensures that a pre-trained model is effective in use cases that involve ambiguity, including automatic annotation as required by our data engine §4\S4§4 . We note that performing well at this task is challenging and requires specialized modeling and training loss choices, which we discuss in §3\S3§3 .
【翻译】预训练。可提示分割任务建议了一种自然的预训练算法,该算法为每个训练样本模拟一系列提示(例如,点、框、掩码),并将模型的掩码预测与真实标准进行比较。我们从交互式分割[109, 70]中采用了这种方法,尽管与交互式分割的目标是在足够的用户输入后最终预测有效掩码不同,我们的目标是即使在提示模糊时也总是为任何提示预测有效掩码。这确保预训练模型在涉及歧义的使用案例中有效,包括我们数据引擎§4\S4§4所需的自动标注。我们注意到在这个任务上表现良好是具有挑战性的,需要专门的建模和训练损失选择,我们在§3\S3§3中讨论。
Zero-shot transfer. Intuitively, our pre-training task endows the model with the ability to respond appropriately to any prompt at inference time, and thus downstream tasks can be solved by engineering appropriate prompts. For example, if one has a bounding box detector for cats, cat instance segmentation can be solved by providing the detector’s box output as a prompt to our model. In general, a wide array of practical segmentation tasks can be cast as prompting. In addition to automatic dataset labeling, we explore five diverse example tasks in our experiments in §7{\S7}§7 .
【翻译】零样本迁移。直观地,我们的预训练任务赋予模型在推理时对任何提示适当响应的能力,因此下游任务可以通过设计适当的提示来解决。例如,如果有一个猫的边界框检测器,猫实例分割可以通过将检测器的框输出作为提示提供给我们的模型来解决。一般来说,广泛的实际分割任务可以被构造为提示。除了自动数据集标注外,我们在§7{\S7}§7的实验中探索了五个不同的示例任务。
Related tasks. Segmentation is a broad field: there’s interactive segmentation [57, 109], edge detection [3], super pixelization [85], object proposal generation [2], foreground segmentation [94], semantic segmentation [90], instance segmentation [66], panoptic segmentation [59], etc. The goal of our promptable segmentation task is to produce a broadly capable model that can adapt to many (though not all) existing and new segmentation tasks via prompt engineering. This capability is a form of task generalization [26]. Note that this is different than previous work on multi-task segmentation systems. In a multi-task system, a single model performs a fixed set of tasks, e.g., joint semantic, instance, and panoptic segmentation [114, 19, 54], but the training and test tasks are the same. An important distinction in our work is that a model trained for promptable segmentation can perform a new, different task at inference time by acting as a component in a larger system, e.g., to perform instance segmentation, a promptable segmentation model is combined with an existing object detector.
【翻译】相关任务。分割是一个广泛的领域:有交互式分割[57, 109]、边缘检测[3]、超像素化[85]、对象提议生成[2]、前景分割[94]、语义分割[90]、实例分割[66]、全景分割[59]等。我们可提示分割任务的目标是产生一个广泛能力的模型,可以通过提示工程适应许多(虽然不是全部)现有和新的分割任务。这种能力是任务泛化的一种形式[26]。注意这与之前多任务分割系统的工作不同。在多任务系统中,单个模型执行固定的任务集合,例如,联合语义、实例和全景分割[114, 19, 54],但训练和测试任务是相同的。我们工作中的一个重要区别是,为可提示分割训练的模型可以通过在更大系统中作为组件在推理时执行新的、不同的任务,例如,为了执行实例分割,可提示分割模型与现有对象检测器结合。
Figure 3: Each column shows 3 valid masks generated by SAM from a single ambiguous point prompt (green circle).

【翻译】图3:每列显示SAM从单个模糊点提示(绿色圆圈)生成的3个有效掩码。
Discussion. Prompting and composition are powerful tools that enable a single model to be used in extensible ways, potentially to accomplish tasks unknown at the time of model design. This approach is analogous to how other foundation models are used, e.g., how CLIP [82] is the text-image alignment component of the DALL E [83] image generation system. We anticipate that composable system design, powered by techniques such as prompt engineering, will enable a wider variety of applications than systems trained specifically for a fixed set of tasks. It’s also interesting to compare promptable and interactive segmentation through the lens of composition: while interactive segmentation models are designed with human users in mind, a model trained for promptable segmentation can also be composed into a larger algorithmic system as we will demonstrate.
【翻译】讨论。提示和组合是强大的工具,使单个模型能够以可扩展的方式使用,可能完成在模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如,CLIP[82]是DALL E[83]图像生成系统的文本-图像对齐组件。我们预期由提示工程等技术驱动的可组合系统设计将比专门为固定任务集合训练的系统支持更广泛的应用。通过组合的角度比较可提示和交互式分割也很有趣:虽然交互式分割模型是以人类用户为设计考虑的,但为可提示分割训练的模型也可以组合到更大的算法系统中,正如我们将演示的。
Figure 4: Segment Anything Model (SAM) overview. A heavyweight image encoder outputs an image embedding that can then be efficiently queried by a variety of input prompts to produce object masks at amortized real-time speed. For ambiguous prompts corresponding to more than one object, SAM can output multiple valid masks and associated confidence scores.
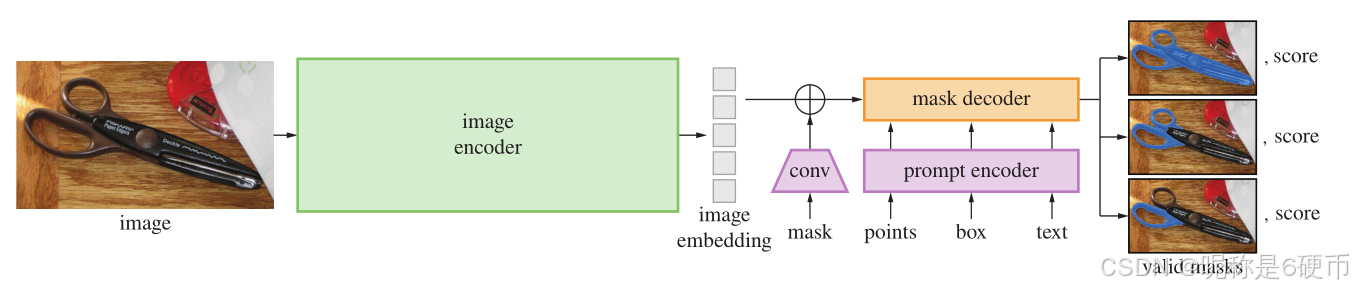
【翻译】图4:分割一切模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以被各种输入提示高效查询,以摊销实时速度产生对象掩码。对于对应多个对象的模糊提示,SAM可以输出多个有效掩码和相关置信度分数。
3. Segment Anything Model
We next describe the Segment Anything Model (SAM) for promptable segmentation. SAM has three components, illustrated in Fig. 4: an image encoder, a flexible prompt encoder, and a fast mask decoder. We build on Transformer vision models [14, 33, 20, 62] with specific tradeoffs for (amortized) real-time performance. We describe these components at a high-level here, with details in §A\S\mathrm{A}§A .
【翻译】接下来我们描述用于可提示分割的分割一切模型(SAM)。SAM有三个组件,如图4所示:图像编码器、灵活的提示编码器和快速掩码解码器。我们在Transformer视觉模型[14, 33, 20, 62]的基础上构建,为(摊销)实时性能做出特定权衡。我们在这里从高层次描述这些组件,详细信息在§A\S\mathrm{A}§A中。
【解析】SAM的三组件:图像编码器负责提取视觉特征表示,这是一个计算密集的过程,但由于图像内容固定,可以预计算并复用。提示编码器处理多模态输入,包括点击、框选、文本等不同类型的用户指令,统一的编码方式使得模型能够灵活应对各种交互场景。掩码解码器将视觉特征与提示信息融合,生成最终的分割结果。"摊销实时性能"指的是虽然图像编码需要较长时间,但一旦完成,后续的提示响应可以达到实时速度,总体上实现了交互式应用的性能要求。这种设计避免了每次交互都重新处理整张图像的开销。
Image encoder. Motivated by scalability and powerful pretraining methods, we use an MAE [47] pre-trained Vision Transformer (ViT) [33] minimally adapted to process high resolution inputs [62]. The image encoder runs once per image and can be applied prior to prompting the model.
【翻译】图像编码器。出于可扩展性和强大预训练方法的考虑,我们使用经过MAE[47]预训练的视觉Transformer(ViT)[33],并进行最小化适配以处理高分辨率输入[62]。图像编码器每张图像运行一次,可以在提示模型之前应用。
【解析】MAE(Masked Autoencoder)预训练为ViT提供了强大的视觉表示学习能力,通过掩盖图像块并重建的自监督学习方式,模型学会了丰富的视觉特征。ViT将图像切分为补丁序列,每个补丁通过线性投影得到token表示,再加上位置编码输入到Transformer中。图像编码器的一次性运行特性使得系统可以预计算图像嵌入,为后续的交互式提示响应奠定基础。
Prompt encoder. We consider two sets of prompts: sparse (points, boxes, text) and dense (masks). We represent points and boxes by positional encodings [95] summed with learned embeddings for each prompt type and free-form text with an off-the-shelf text encoder from CLIP [82]. Dense prompts (i.e., masks) are embedded using convolutions and summed element-wise with the image embedding.
【翻译】提示编码器。我们考虑两类提示:稀疏提示(点、框、文本)和密集提示(掩码)。我们通过位置编码[95]与每种提示类型的学习嵌入相加来表示点和框,自由文本使用来自CLIP[82]的现成文本编码器。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素相加。
【解析】稀疏与密集提示:稀疏提示包含离散的位置信息和语义信息,点击和框选提供空间约束,文本提供语义约束。位置编码将几何坐标转换为高维表示,结合类型特定的学习嵌入,使模型能够理解不同提示的语义。CLIP文本编码器的使用利用了视觉-语言预训练的优势,无需从头训练文本理解能力。密集提示如掩码本身就是空间分布的,通过卷积操作可以提取其空间模式特征,与图像嵌入的逐元素相加实现了空间对齐的特征融合,这种设计使得模型能够基于已有的粗糙分割结果进行精细化。
Mask decoder. The mask decoder efficiently maps the image embedding, prompt embeddings, and an output token to a mask. This design, inspired by [14, 20], employs a modification of a Transformer decoder block [103] followed by a dynamic mask prediction head. Our modified decoder block uses prompt self-attention and cross-attention in two directions (prompt-to-image embedding and vice-versa) to update all embeddings. After running two blocks, we upsample the image embedding and an MLP maps the output token to a dynamic linear classifier, which then computes the mask foreground probability at each image location.
【翻译】掩码解码器。掩码解码器高效地将图像嵌入、提示嵌入和输出token映射到掩码。这种设计受到[14, 20]的启发,采用修改的Transformer解码器块[103],然后是动态掩码预测头。我们修改的解码器块使用提示自注意力和双向交叉注意力(提示到图像嵌入以及相反方向)来更新所有嵌入。运行两个块后,我们上采样图像嵌入,MLP将输出token映射到动态线性分类器,然后计算每个图像位置的掩码前景概率。
【解析】掩码解码器的核心是注意力机制的运用。自注意力允许不同提示之间的信息交互,这对于处理多个提示或复杂提示场景很重要。双向交叉注意力建立了提示与图像特征的深度交互:提示到图像的注意力让模型关注与提示相关的图像区域,图像到提示的注意力则让提示根据图像内容进行自适应调整。两个解码器块的堆叠提供了足够的表示学习深度。上采样操作恢复空间分辨率,确保输出掩码与原图尺寸匹配。动态线性分类器的"动态"特性说明分类权重根据输出token动态生成,而非固定参数,这使得同一个解码器能够适应不同的分割任务和对象类别。最终的前景概率计算为每个像素提供分割置信度。
Resolving ambiguity. With one output, the model will average multiple valid masks if given an ambiguous prompt. To address this, we modify the model to predict multiple output masks for a single prompt (see Fig. 3). We found 3 mask outputs is sufficient to address most common cases (nested masks are often at most three deep: whole, part, and subpart). During training, we backprop only the minimum loss [15, 45, 64] over masks. To rank masks, the model predicts a confidence score (i.e., estimated IoU) for each mask.
【翻译】解决歧义性。对于单个输出,如果给定模糊提示,模型将平均多个有效掩码。为了解决这个问题,我们修改模型以预测单个提示的多个输出掩码(见图3)。我们发现3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多有三层深:整体、部分和子部分)。在训练过程中,我们只对掩码上的最小损失[15, 45, 64]进行反向传播。为了对掩码排序,模型为每个掩码预测置信度分数(即估计的IoU)。
Efficiency. The overall model design is largely motivated by efficiency. Given a precomputed image embedding, the prompt encoder and mask decoder run in a web browser, on CPU, in ∼50ms{\sim}50\mathrm{ms}∼50ms . This runtime performance enables seamless, real-time interactive prompting of our model.
【翻译】效率。整体模型设计很大程度上以效率为动机。给定预计算的图像嵌入,提示编码器和掩码解码器在网页浏览器中的CPU上运行,耗时约50毫秒。这种运行时性能使我们的模型能够无缝、实时的交互式提示。
Losses and training. We supervise mask prediction with the linear combination of focal loss [65] and dice loss [73] used in [14]. We train for the promptable segmentation task using a mixture of geometric prompts (for text prompts see §7.5)\S7.5)§7.5) . Following [92, 37], we simulate an interactive setup by randomly sampling prompts in 11 rounds per mask, allowing SAM to integrate seamlessly into our data engine.
【翻译】损失和训练。我们使用[14]中使用的焦点损失[65]和dice损失[73]的线性组合来监督掩码预测。我们使用几何提示的混合来训练可提示分割任务(文本提示见§7.5\S7.5§7.5)。遵循[92, 37],我们通过每个掩码随机采样11轮提示来模拟交互式设置,使SAM能够无缝集成到我们的数据引擎中。
4. Segment Anything Data Engine
As segmentation masks are not abundant on the internet, we built a data engine to enable the collection of our 1.1B mask dataset, SA-1B. The data engine has three stages: (1) a model-assisted manual annotation stage, (2) a semi-automatic stage with a mix of automatically predicted masks and model-assisted annotation, and (3) a fully automatic stage in which our model generates masks without annotator input. We go into details of each next.
【翻译】由于分割掩码在互联网上并不丰富,我们构建了一个数据引擎来实现我们11亿掩码数据集SA-1B的收集。数据引擎有三个阶段:(1)模型辅助的手动标注阶段,(2)自动预测掩码和模型辅助标注混合的半自动阶段,(3)我们的模型在没有标注员输入的情况下生成掩码的全自动阶段。我们接下来详细介绍每个阶段。
Assisted-manual stage. In the first stage, resembling classic interactive segmentation, a team of professional annotators labeled masks by clicking foreground / background object points using a browser-based interactive segmentation tool powered by SAM. Masks could be refined using pixelprecise “brush” and “eraser” tools. Our model-assisted annotation runs in real-time directly inside a browser (using precomputed image embeddings) enabling a truly interactive experience. We did not impose semantic constraints for labeling objects, and annotators freely labeled both “stuff” and “things” [1]. We suggested annotators label objects they could name or describe, but did not collect these names or descriptions. Annotators were asked to label objects in order of prominence and were encouraged to proceed to the next image once a mask took over 30 seconds to annotate.
【翻译】辅助手动阶段。在第一阶段,类似于经典的交互式分割,一组专业标注员使用由SAM驱动的基于浏览器的交互式分割工具,通过点击前景/背景对象点来标记掩码。掩码可以使用像素精确的"画笔"和"橡皮擦"工具进行精细化。我们的模型辅助标注直接在浏览器内实时运行(使用预计算的图像嵌入),实现了真正的交互式体验。我们没有对标记对象施加语义约束,标注员自由标记"材质"和"物体"[1]。我们建议标注员标记他们能够命名或描述的对象,但没有收集这些名称或描述。标注员被要求按显著性顺序标记对象,并在掩码标注超过30秒时被鼓励进入下一张图像。
At the start of this stage, SAM was trained using common public segmentation datasets. After sufficient data annotation, SAM was retrained using only newly annotated masks. As more masks were collected, the image encoder was scaled from ViT-B to ViT-H and other architectural details evolved; in total we retrained our model 6 times. Average annotation time per mask decreased from 34 to 14 seconds as the model improved. We note that 14 seconds is 6.5×6.5\times6.5× faster than mask annotation for COCO [66] and only 2×2\times2× slower than bounding-box labeling with extreme points [76, 71]. As SAM improved, the average number of masks per image increased from 20 to 44 masks. Overall, we collected 4.3M masks from 120k images in this stage.
【翻译】在这个阶段开始时,SAM使用常见的公共分割数据集进行训练。在充分的数据标注后,SAM仅使用新标注的掩码进行重新训练。随着更多掩码的收集,图像编码器从ViT-B扩展到ViT-H,其他架构细节也在演进;总共我们重新训练了模型6次。随着模型的改进,每个掩码的平均标注时间从34秒减少到14秒。我们注意到14秒比COCO[66]的掩码标注快6.5×6.5\times6.5×,仅比使用极点的边界框标记慢2×2\times2×[76, 71]。随着SAM的改进,每张图像的平均掩码数量从20个增加到44个。总体而言,我们在这个阶段从120k张图像中收集了430万个掩码。
Semi-automatic stage. In this stage, we aimed to increase the diversity of masks in order to improve our model’s ability to segment anything. To focus annotators on less prominent objects, we first automatically detected confident masks. Then we presented annotators with images prefilled with these masks and asked them to annotate any additional unannotated objects. To detect confident masks, we trained a bounding box detector [84] on all first stage masks using a generic “object” category. During this stage we collected an additional 5.9M masks in 180k images (for a total of 10.2M masks). As in the first stage, we periodically retrained our model on newly collected data (5 times). Average annotation time per mask went back up to 34 seconds (excluding the automatic masks) as these objects were more challenging to label. The average number of masks per image went from 44 to 72 masks (including the automatic masks).
【翻译】半自动阶段。在这个阶段,我们旨在增加掩码的多样性,以提高我们模型分割任何物体的能力。为了让标注员专注于不太显著的对象,我们首先自动检测置信掩码。然后我们向标注员展示预填充了这些掩码的图像,并要求他们标注任何额外的未标注对象。为了检测置信掩码,我们使用通用"对象"类别在所有第一阶段掩码上训练了边界框检测器[84]。在这个阶段,我们在180k张图像中收集了额外的590万个掩码(总计1020万个掩码)。与第一阶段一样,我们定期在新收集的数据上重新训练我们的模型(5次)。每个掩码的平均标注时间回升到34秒(不包括自动掩码),因为这些对象更难标记。每张图像的平均掩码数量从44个增加到72个(包括自动掩码)。
Fully automatic stage. In the final stage, annotation was fully automatic. This was feasible due to two major enhancements to our model. First, at the start of this stage, we had collected enough masks to greatly improve the model, including the diverse masks from the previous stage. Second, by this stage we had developed the ambiguity-aware model, which allowed us to predict valid masks even in ambiguous cases. Specifically, we prompted the model with a 32×3232\times3232×32 regular grid of points and for each point predicted a set of masks that may correspond to valid objects. With the ambiguity-aware model, if a point lies on a part or subpart, our model will return the subpart, part, and whole object. The IoU prediction module of our model is used to select confident masks; moreover, we identified and selected only stable masks (we consider a mask stable if thresholding the probability map at 0.5−δ0.5-\delta0.5−δ and 0.5+δ0.5+\delta0.5+δ results in similar masks). Finally, after selecting the confident and stable masks, we applied non-maximal suppression (NMS) to filter duplicates. To further improve the quality of smaller masks, we also processed multiple overlapping zoomed-in image crops. For further details of this stage, see §B\S\mathrm{B}§B . We applied fully automatic mask generation to all 11M images in our dataset, producing a total of 1.1B high-quality masks. We describe and analyze the resulting dataset, SA-1B, next.
【翻译】全自动阶段。在最后阶段,标注是完全自动的。这之所以可行,是由于我们模型的两个主要增强。首先,在这个阶段开始时,我们已经收集了足够的掩码来大大改进模型,包括来自前一阶段的多样化掩码。其次,到这个阶段,我们已经开发了歧义感知模型,它允许我们即使在模糊情况下也能预测有效掩码。具体来说,我们用32×3232\times3232×32规则点网格提示模型,对每个点预测一组可能对应有效对象的掩码。使用歧义感知模型,如果一个点位于部分或子部分上,我们的模型将返回子部分、部分和整个对象。我们模型的IoU预测模块用于选择置信掩码;此外,我们识别并仅选择稳定掩码(如果在0.5−δ0.5-\delta0.5−δ和0.5+δ0.5+\delta0.5+δ处阈值化概率图产生相似掩码,我们认为掩码是稳定的)。最后,在选择置信和稳定掩码后,我们应用非极大值抑制(NMS)来过滤重复项。为了进一步提高较小掩码的质量,我们还处理了多个重叠的放大图像裁剪。有关此阶段的更多详细信息,请参见§B\S\mathrm{B}§B。我们对数据集中所有1100万张图像应用了全自动掩码生成,总共产生了11亿个高质量掩码。我们接下来描述和分析生成的数据集SA-1B。
Figure 5: Image-size normalized mask center distributions.

【翻译】图5:图像尺寸归一化的掩码中心分布。
5. Segment Anything Dataset
Our dataset, SA-1B, consists of 11M diverse, highresolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks collected with our data engine. We compare SA-1B with existing datasets and analyze mask quality and properties. We are releasing SA-1B to aid future development of foundation models for computer vision. We note that SA-1B will be released under a favorable license agreement for certain research uses and with protections for researchers.
【翻译】我们的数据集SA-1B由1100万张多样化、高分辨率、授权且隐私保护的图像和11亿个通过我们数据引擎收集的高质量分割掩码组成。我们将SA-1B与现有数据集进行比较,并分析掩码质量和属性。我们发布SA-1B是为了帮助计算机视觉基础模型的未来发展。我们注意到SA-1B将在特定研究用途的有利许可协议下发布,并为研究人员提供保护。
Images. We licensed a new set of 11M images from a provider that works directly with photographers. These images are high resolution 3300×49503300\times49503300×4950 pixels on average), and the resulting data size can present accessibility and storage challenges. Therefore, we are releasing downsampled images with their shortest side set to 1500 pixels. Even after downsampling, our images are significantly higher resolution than many existing vision datasets (e.g., COCO [66] images are ∼480×640{\sim}480{\times}640∼480×640 pixels). Note that most models today operate on much lower resolution inputs. Faces and vehicle license plates have been blurred in the released images.
【翻译】图像。我们从直接与摄影师合作的提供商处授权了一套新的1100万张图像。这些图像是高分辨率的(平均3300×49503300\times49503300×4950像素),由此产生的数据大小可能会带来可访问性和存储挑战。因此,我们发布的是将最短边设置为1500像素的下采样图像。即使经过下采样,我们的图像分辨率也明显高于许多现有的视觉数据集(例如,COCO[66]图像约为∼480×640{\sim}480{\times}640∼480×640像素)。请注意,今天的大多数模型都在更低分辨率的输入上运行。已发布图像中的面部和车牌已被模糊处理。
Masks. Our data engine produced 1.1B masks, 99.1%99.1\%99.1% of which were generated fully automatically. Therefore, the quality of the automatic masks is centrally important. We compare them directly to professional annotations and look at how various mask properties compare to prominent segmentation datasets. Our main conclusion, as borne out in the analysis below and the experiments in §7{\S7}§7 , is that our automatic masks are high quality and effective for training models. Motivated by these findings, SA-1B only includes automatically generated masks.
【翻译】掩码。我们的数据引擎产生了11亿个掩码,其中99.1%99.1\%99.1%是完全自动生成的。因此,自动掩码的质量至关重要。我们将它们直接与专业标注进行比较,并观察各种掩码属性与著名分割数据集的比较情况。我们的主要结论,如下面的分析和§7{\S7}§7中的实验所证实的,是我们的自动掩码质量很高,对训练模型有效。基于这些发现,SA-1B只包含自动生成的掩码。
Mask quality. To estimate mask quality, we randomly sampled 500 images ( ∼50k\mathord{\sim}50\mathrm{k}∼50k masks) and asked our professional annotators to improve the quality of all masks in these images. Annotators did so using our model and pixel-precise “brush” and “eraser” editing tools. This procedure resulted in pairs of automatically predicted and professionally corrected masks. We computed IoU between each pair and found that 94%94\%94% of pairs have greater than 90%90\%90% IoU (and 97%97\%97% of pairs have greater than 75%75\%75% IoU). For comparison, prior work estimates inter-annotator consistency at 85⋅91%85{\cdot}91\%85⋅91% IoU [44, 60]. Our experiments in §7{\S7}§7 confirm by human ratings that mask quality is high relative to a variety of datasets and that training our model on automatic masks is nearly as good as using all masks produced by the data engine.
【翻译】掩码质量。为了估计掩码质量,我们随机采样了500张图像(约∼50k\mathord{\sim}50\mathrm{k}∼50k个掩码),并要求我们的专业标注员改进这些图像中所有掩码的质量。标注员使用我们的模型和像素精确的"画笔"和"橡皮擦"编辑工具来完成这项工作。这个过程产生了自动预测和专业修正掩码的配对。我们计算了每对之间的IoU,发现94%94\%94%的配对具有大于90%90\%90%的IoU(97%97\%97%的配对具有大于75%75\%75%的IoU)。相比之下,先前的工作估计标注员间一致性为85⋅91%85{\cdot}91\%85⋅91%的IoU[44, 60]。我们在§7{\S7}§7中的实验通过人工评分确认,相对于各种数据集,掩码质量很高,在自动掩码上训练我们的模型几乎与使用数据引擎产生的所有掩码一样好。
Figure 6: Dataset mask properties. The legend references the number of images and masks in each dataset. Note, that SA-1B has 11×11\times11× more images and 400×400\times400× more masks than the largest existing segmentation dataset Open Images [60].

【翻译】图6:数据集掩码属性。图例引用了每个数据集中图像和掩码的数量。注意,SA-1B比最大的现有分割数据集Open Images[60]多11×11\times11×张图像和400×400\times400×个掩码。
Figure 7: Estimated geographic distribution of SA-1B images. Most of the world’s countries have more than 1000 images in SA-1B, and the three countries with the most images are from different parts of the world.

【翻译】图7:SA-1B图像的估计地理分布。世界上大多数国家在SA-1B中都有超过1000张图像,图像最多的三个国家来自世界不同地区。
Mask properties. In Fig. 5 we plot the spatial distribution of object centers in SA-1B compared to the largest existing segmentation datasets. Common photographer biases are present in all datasets. We observe that SA-1B has greater coverage of image corners compared to LVIS v1 [44] and ADE20K [117], the two most similarly distributed datasets, while COCO [66] and Open Images V5 [60] have a more prominent center bias. In Fig. 6 (legend) we compare these datasets by size. SA-1B has 11×11\times11× more images and 400×400\times400× more masks than the second largest, Open Images. On average, it has 36×36\times36× more masks per image than Open Images. The closest dataset in this respect, ADE20K, still has 3.5×3.5\times3.5× fewer masks per image. Fig. 6 (left) plots the masks-perimage distribution. Next, we look at image-relative mask size (square root of the mask area divided by image area) in Fig. 6 (middle). As expected, since our dataset has more masks per image, it also tends to include a greater percentage of small and medium relative-size masks. Finally, to analyze shape complexity, we look at mask concavity (1 minus mask area divided by area of mask’s convex hull) in Fig. 6 (right). Since shape complexity is correlated with mask size, we control for the datasets’ mask size distributions by first performing stratified sampling from binned mask sizes. We observe that the concavity distribution of our masks is broadly similar to that of other datasets.
【翻译】掩码属性。在图5中,我们绘制了SA-1B中对象中心的空间分布,与最大的现有分割数据集进行比较。所有数据集中都存在常见的摄影师偏见。我们观察到,与分布最相似的两个数据集LVIS v1[44]和ADE20K[117]相比,SA-1B对图像角落有更大的覆盖,而COCO[66]和Open Images V5[60]有更突出的中心偏见。在图6(图例)中,我们按大小比较这些数据集。SA-1B比第二大的Open Images多11×11\times11×张图像和400×400\times400×个掩码。平均而言,它比Open Images每张图像多36×36\times36×个掩码。在这方面最接近的数据集ADE20K每张图像仍然少3.5×3.5\times3.5×个掩码。图6(左)绘制了每张图像掩码分布。接下来,我们在图6(中)中观察图像相对掩码大小(掩码面积的平方根除以图像面积)。正如预期的那样,由于我们的数据集每张图像有更多掩码,它也倾向于包含更大百分比的小型和中型相对大小掩码。最后,为了分析形状复杂性,我们在图6(右)中观察掩码凹度(1减去掩码面积除以掩码凸包面积)。由于形状复杂性与掩码大小相关,我们首先从分组掩码大小中执行分层采样来控制数据集的掩码大小分布。我们观察到我们掩码的凹度分布与其他数据集大致相似。
6. Segment Anything RAI Analysis
We next perform a Responsible AI (RAI) analysis of our work by investigating potential fairness concerns and biases when using SA-1B and SAM. We focus on the geographic and income distribution of SA-1B and fairness of SAM across protected attributes of people. We also provide dataset, data annotation, and model cards in §F\S\mathrm{F}§F .
【翻译】接下来,我们通过调查使用SA-1B和SAM时潜在的公平性关注和偏见来进行我们工作的负责任AI(RAI)分析。我们专注于SA-1B的地理和收入分布以及SAM在人员受保护属性方面的公平性。我们还在§F\S\mathrm{F}§F中提供数据集、数据注释和模型卡片。
Table 1: Comparison of geographic and income representation. SA-1B has higher representation in Europe and Asia & Oceania as well as middle income countries. Images from Africa, Latin America & Caribbean, as well as low income countries, are underrepresented in all datasets.
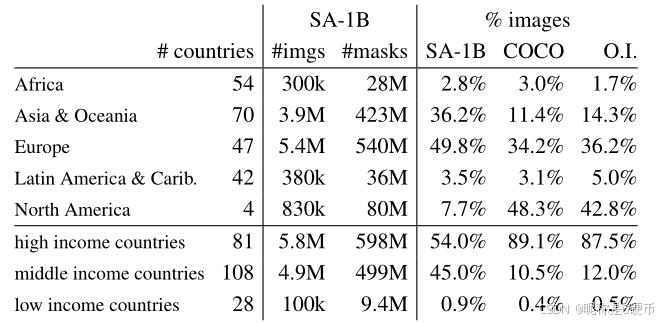
【翻译】表1:地理和收入代表性的比较。SA-1B在欧洲和亚洲及大洋洲以及中等收入国家中有更高的代表性。来自非洲、拉丁美洲和加勒比海以及低收入国家的图像在所有数据集中都代表性不足。
Geographic and income representation. We infer the country images were photographed in using standard methods (see §\S§ C). In Fig. 7 we visualize the per-country image counts in SA-1B (left) and the 50 countries with the most images (right). We note that the top-three countries are from different parts of the world. Next, in Table 1 we compare the geographic and income representation of SA-1B, COCO [66], and Open Images [60]. SA-1B has a substantially higher percentage of images in Europe and Asia & Oceania as well as in middle income countries. All datasets underrepresent Africa as well as low income countries. We note that in SA-1B, all regions, including Africa, have at least 28 million masks, 10×10\times10× more than the total number of masks of any previous dataset. Finally, we observe that the average number of masks per image (not shown) is fairly consistent across region and income (94-108 per image).
【翻译】地理和收入代表性。我们使用标准方法推断图像拍摄的国家(见§\S§ C)。在图7中,我们可视化了SA-1B中每个国家的图像计数(左)和图像最多的50个国家(右)。我们注意到前三个国家来自世界不同地区。接下来,在表1中,我们比较了SA-1B、COCO[66]和Open Images[60]的地理和收入代表性。SA-1B在欧洲和亚洲及大洋洲以及中等收入国家中拥有更高比例的图像。所有数据集都低估了非洲以及低收入国家的代表性。我们注意到在SA-1B中,包括非洲在内的所有地区都至少有2800万个掩码,比任何以前数据集的掩码总数多10×10\times10×。最后,我们观察到每张图像的平均掩码数(未显示)在不同地区和收入水平上相当一致(每张图像94-108个)。
Table 2: SAM’s performance segmenting people across perceived gender presentation, age group, and skin tone. 95%95\%95% confidence intervals are shown. Within each grouping, all confidence intervals overlap except older vs. middle.
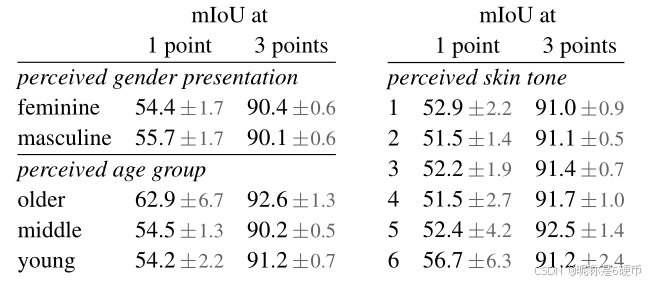
【翻译】表2:SAM在感知性别表现、年龄组和肤色方面分割人物的性能。显示了95%95\%95%置信区间。在每个分组内,除了老年与中年组外,所有置信区间都有重叠。
Fairness in segmenting people. We investigate potential fairness concerns across perceived gender presentation, perceived age group, and perceived skin tone by measuring the performance discrepancy of SAM between groups. We use the More Inclusive Annotations for People (MIAP) [87] dataset for gender presentation and age and a proprietary dataset for skin tone (see §C\S C§C ). Our evaluation uses simulated interactive segmentation with random sampling of 1 and 3 points (see §D\S D§D ). Table 2 (top left) shows results for perceived gender presentation. We note that females have been shown to be underrepresented in detection and segmentation datasets [115], but observe that SAM performs similarly across groups. We repeat the analysis for perceived age in Table 2 (bottom left), noting that those who are perceived to be younger and older have been shown to be underrepresented in large-scale datasets [110]. SAM performs best on those who are perceived older (although the confidence interval is large). Finally, we repeat the analysis for perceived skin tone in Table 2 (right), noting that those with lighter apparent skin tones have been shown to be overrepresented and those with darker skin tones underrepresented in large-scale datasets [110]. As MIAP does not contain perceived skin tone annotations, we use a proprietary dataset that contains annotations for the perceived Fitzpatrick skin type [36], which ranges from 1 (lightest skin tone) to 6 (darkest skin tone). While the means vary somewhat, we do not find a significant difference across groups. We believe our findings stem from the nature of the task, and acknowledge biases may arise when SAM is used as a component in larger systems. Finally, in §\S§ C we extend the analysis to segmenting clothing where we find an indication of bias across perceived gender presentation.
【翻译】分割人物的公平性。我们通过测量SAM在不同组别间的性能差异来调查感知性别表现、感知年龄组和感知肤色方面的潜在公平性关注。我们使用更包容的人物注释(MIAP)[87]数据集进行性别表现和年龄分析,使用专有数据集进行肤色分析(见§C\S C§C)。我们的评估使用随机采样1个和3个点的模拟交互式分割(见§D\S D§D)。表2(左上)显示了感知性别表现的结果。我们注意到女性在检测和分割数据集中代表性不足[115],但观察到SAM在各组间表现相似。我们在表2(左下)中重复了感知年龄的分析,注意到那些被认为更年轻和更年长的人在大规模数据集中代表性不足[110]。SAM在那些被认为年长的人身上表现最好(尽管置信区间很大)。最后,我们在表2(右)中重复了感知肤色的分析,注意到那些明显肤色较浅的人在大规模数据集中代表性过度,而肤色较深的人代表性不足[110]。由于MIAP不包含感知肤色注释,我们使用包含感知Fitzpatrick肤色类型注释的专有数据集[36],范围从1(最浅肤色)到6(最深肤色)。虽然均值有所变化,但我们没有发现各组间存在显著差异。我们认为我们的发现源于任务的性质,并承认当SAM用作更大系统的组件时可能会出现偏见。最后,在§\S§ C中,我们将分析扩展到服装分割,在那里我们发现了感知性别表现方面的偏见迹象。
7. Zero-Shot Transfer Experiments
In this section, we present zero-shot transfer experiments with SAM, the Segment Anything Model. We consider five tasks, four of which differ significantly from the promptable segmentation task used to train SAM. These experiments evaluate SAM on datasets and tasks that were not seen during training (our usage of “zero-shot transfer” follows its usage in CLIP [82]). The datasets may include novel image distributions, such as underwater or ego-centric images (e.g. Fig. 8) that, to our knowledge, do not appear in SA-1B.
【翻译】在本节中,我们展示了SAM(Segment Anything Model)的零样本迁移实验。我们考虑了五个任务,其中四个与用于训练SAM的可提示分割任务有显著差异。这些实验在训练期间未见过的数据集和任务上评估SAM(我们对"零样本迁移"的使用遵循其在CLIP[82]中的用法)。数据集可能包括新颖的图像分布,如水下或自我中心图像(例如图8),据我们所知,这些图像不会出现在SA-1B中。
Our experiments begin by testing the core goal of promptable segmentation: producing a valid mask from any prompt. We emphasize the challenging scenario of a single foreground point prompt, since it is more likely to be ambiguous than other more specific prompts. Next, we present a sequence of experiments that traverse low, mid, and highlevel image understanding and roughly parallel the historical development of the field. Specifically, we prompt SAM to (1) perform edge detection, (2) segment everything, i.e. object proposal generation, (3) segment detected objects, i.e. instance segmentation, and (4), as a proof-of-concept, to segment objects from free-form text. These four tasks differ significantly from the promptable segmentation task that SAM was trained on and are implemented via prompt engineering. Our experiments conclude with an ablation study.
【翻译】我们的实验首先测试可提示分割的核心目标:从任何提示中产生有效的掩码。我们强调单个前景点提示的挑战性场景,因为它比其他更具体的提示更可能产生歧义。接下来,我们展示了一系列实验,这些实验遍历了低级、中级和高级图像理解,大致平行于该领域的历史发展。具体来说,我们提示SAM(1)执行边缘检测,(2)分割所有内容,即对象提议生成,(3)分割检测到的对象,即实例分割,以及(4)作为概念验证,从自由形式文本中分割对象。这四个任务与SAM训练的可提示分割任务有显著差异,并通过提示工程实现。我们的实验以消融研究结束。
Implementation. Unless otherwise specified: (1) SAM uses an MAE [47] pre-trained ViT-H [33] image encoder and (2) SAM was trained on SA-1B, noting that this dataset includes only automatically generated masks from the final stage of our data engine. For all other model and training details, such as hyperparameters, refer to §A\S\mathrm{A}§A .
【翻译】实现。除非另有说明:(1)SAM使用MAE[47]预训练的ViT-H[33]图像编码器,(2)SAM在SA-1B上训练,注意该数据集仅包含我们数据引擎最终阶段自动生成的掩码。对于所有其他模型和训练细节,如超参数,请参考§A\S\mathrm{A}§A。
7.1. Zero-Shot Single Point Valid Mask Evaluation
Task. We evaluate segmenting an object from a single foreground point. This task is ill-posed as one point can refer to multiple objects. Ground truth masks in most datasets do not enumerate all possible masks, which can make automatic metrics unreliable. Therefore, we supplement the standard mIoU metric (i.e., the mean of all IoUs between predicted and ground truth masks) with a human study in which annotators rate mask quality from 1 (nonsense) to 10 (pixel-perfect). See §D.1\S\mathrm{D}.1§D.1 , §E\S\mathrm{E}§E , and §G\S\mathrm{G}§G for additional details.
【翻译】任务。我们评估从单个前景点分割对象。这个任务是不适定的,因为一个点可以指向多个对象。大多数数据集中的真实掩码没有枚举所有可能的掩码,这可能使自动指标不可靠。因此,我们用人类研究来补充标准的mIoU指标(即预测掩码和真实掩码之间所有IoU的平均值),其中注释者对掩码质量从1(无意义)到10(像素完美)进行评分。有关更多详细信息,请参见§D.1\S\mathrm{D}.1§D.1、§E\S\mathrm{E}§E和§G\S\mathrm{G}§G。
By default, we sample points from the “center” of ground truth masks (at a maximal value of the mask’s interior distance transform), following the standard evaluation protocol in interactive segmentation [92]. Since SAM is capable of predicting multiple masks, we evaluate only the model’s most confident mask by default. The baselines are all single-mask methods. We compare mainly to RITM [92], a strong interactive segmenter that performs best on our benchmark compared to other strong baselines [67, 18].
【翻译】默认情况下,我们从真实掩码的"中心"采样点(在掩码内部距离变换的最大值处),遵循交互式分割中的标准评估协议[92]。由于SAM能够预测多个掩码,我们默认只评估模型最有信心的掩码。基线都是单掩码方法。我们主要与RITM[92]进行比较,这是一个强大的交互式分割器,与其他强基线[67, 18]相比,在我们的基准测试中表现最佳。
Datasets. We use a newly compiled suite of 23 datasets with diverse image distributions. Fig. 8 lists the datasets and shows a sample from each one (see appendix Table 7 for more details). We use all 23 datasets for mIoU evaluation. For the human study, we use the subset listed in Fig. 9b (due to the resource requirements of such studies). This subset includes both datasets for which SAM outperforms and underperforms RITM according to automatic metrics.
【翻译】数据集。我们使用新编译的23个具有不同图像分布的数据集套件。图8列出了数据集并显示了每个数据集的样本(有关更多详细信息,请参见附录表7)。我们使用所有23个数据集进行mIoU评估。对于人类研究,我们使用图9b中列出的子集(由于此类研究的资源要求)。该子集包括根据自动指标SAM优于和劣于RITM的数据集。
Figure 8: Samples from the 23 diverse segmentation datasets used to evaluate SAM’s zero-shot transfer capabilities.

【翻译】图8:用于评估SAM零样本迁移能力的23个不同分割数据集的样本。
Figure 9: Point to mask evaluation on 23 datasets. (a) Mean IoU of SAM and the strongest single point segmenter, RITM [92]. Due to ambiguity, a single mask may not match ground truth; circles show “oracle” results of the most relevant of SAM’s 3 predictions. (b) Per-dataset comparison of mask quality ratings by annotators from 1 (worst) to 10 (best). All methods use the ground truth mask center as the prompt. (c, d) mIoU with varying number of points. SAM significantly outperforms prior interactive segmenters with 1 point and is on par with more points. Low absolute mIoU at 1 point is the result of ambiguity.
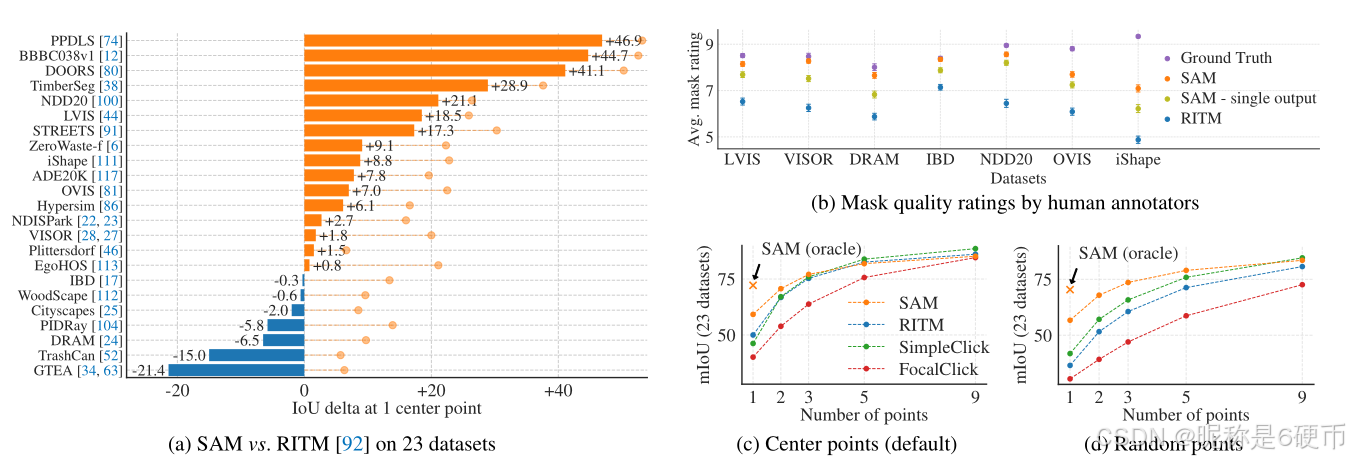
【翻译】图9:在23个数据集上的点到掩码评估。(a)SAM和最强单点分割器RITM[92]的平均IoU。由于歧义性,单个掩码可能与真实值不匹配;圆圈显示SAM的3个预测中最相关的"预言机"结果。(b)注释者对掩码质量评分的逐数据集比较,从1(最差)到10(最佳)。所有方法都使用真实掩码中心作为提示。(c, d)不同点数的mIoU。SAM在1个点时显著优于之前的交互式分割器,在更多点时表现相当。1个点时的低绝对mIoU是歧义性的结果。
Results. First, we look at automatic evaluation on the full suite of 23 datasets using mIoU. We compare per-dataset results in Fig. 9a against RITM. SAM yields higher results on 16 of the 23 datasets, by as much as ∼47{\sim}47∼47 IoU. We also present an “oracle” result, in which the most relevant of SAM’s 3 masks is selected by comparing them to the ground truth, rather than selecting the most confident mask. This reveals the impact of ambiguity on automatic evaluation. In particular, with the oracle to perform ambiguity resolution, SAM outperforms RITM on all datasets.
【翻译】结果。首先,我们使用mIoU在全套23个数据集上进行自动评估。我们在图9a中将逐数据集结果与RITM进行比较。SAM在23个数据集中的16个上产生了更高的结果,最多高出∼47{\sim}47∼47 IoU。我们还提供了"预言机"结果,其中通过将SAM的3个掩码与真实值进行比较来选择最相关的掩码,而不是选择最有信心的掩码。这揭示了歧义性对自动评估的影响。特别是,通过预言机执行歧义解决,SAM在所有数据集上都优于RITM。
Results of the human study are presented in Fig. 9b. Error bars are 95%95\%95% confidence intervals for mean mask ratings (all differences are significant; see §E\S\mathrm{E}§E for details). We observe that the annotators consistently rate the quality of SAM’s masks substantially higher than the strongest baseline, RITM. An ablated, “ambiguity-unaware” version of SAM with a single output mask has consistently lower ratings, though still higher than RITM. SAM’s mean ratings fall between 7 and 9, which corresponds to the qualitative rating guideline: “A high score (7-9): The object is identifiable and errors are small and rare (e.g., missing a small, heavily obscured disconnected component, …).” These results indicate that SAM has learned to segment valid masks from a single point. Note that for datasets like DRAM and IBD, where SAM is worse on automatic metrics, it receives consistently higher ratings in the human study.
【翻译】人类研究的结果在图9b中呈现。误差条是平均掩码评分的95%95\%95%置信区间(所有差异都是显著的;详情见§E\S\mathrm{E}§E)。我们观察到注释者一致地将SAM掩码的质量评分显著高于最强基线RITM。一个具有单个输出掩码的消融"歧义不感知"版本的SAM评分一致较低,但仍高于RITM。SAM的平均评分在7到9之间,这对应定性评分指南:"高分(7-9):对象是可识别的,错误很小且罕见(例如,缺少一个小的、严重遮挡的断开组件,…)。"这些结果表明SAM已经学会从单个点分割有效掩码。注意,对于像DRAM和IBD这样SAM在自动指标上表现较差的数据集,它在人类研究中获得了一致更高的评分。
Fig. 9c shows additional baselines, SimpleClick [67] and FocalClick [18], which obtain lower single point performance than RITM and SAM. As the number of points increases from 1 to 9, we observe that the gap between methods decreases. This is expected as the task becomes easier; also, SAM is not optimized for the very high IoU regime. Finally, in Fig. 9d we replace the default center point sampling with random point sampling. We observe that the gap between SAM and the baselines grows and SAM is able to achieve comparable results under either sampling method.
【翻译】图9c显示了额外的基线,SimpleClick[67]和FocalClick[18],它们获得了比RITM和SAM更低的单点性能。随着点数从1增加到9,我们观察到方法之间的差距减少。这是预期的,因为任务变得更容易;此外,SAM没有针对非常高的IoU范围进行优化。最后,在图9d中,我们将默认的中心点采样替换为随机点采样。我们观察到SAM和基线之间的差距增大,SAM能够在任一采样方法下实现可比较的结果。
igure 10: Zero-shot edge prediction on BSDS500. SAM was not trained to predict edge maps nor did it have access to BSDS images or annotations during training.

【翻译】图10:在BSDS500上的零样本边缘预测。SAM没有被训练来预测边缘图,在训练期间也没有访问BSDS图像或注释。
Table 3: Zero-shot transfer to edge detection on BSDS500.
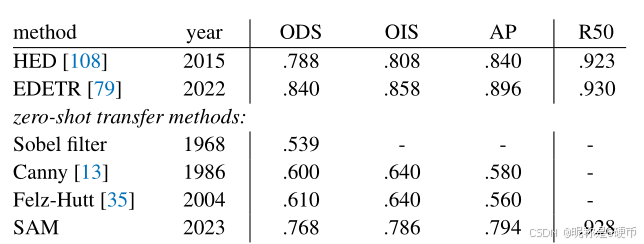
【翻译】表3:在BSDS500上零样本迁移到边缘检测。
7.2. Zero-Shot Edge Detection
Approach. We evaluate SAM on the classic low-level task of edge detection using BSDS500 [72, 3]. We use a simplified version of our automatic mask generation pipeline. Specifically, we prompt SAM with a 16×1616\times1616×16 regular grid of foreground points resulting in 768 predicted masks (3 per point). Redundant masks are removed by NMS. Then, edge maps are computed using Sobel filtering of unthresholded mask probability maps and standard lightweight postprocessing, including edge NMS (see §D.2\S\mathrm{D}.2§D.2 for details).
【翻译】方法。我们使用BSDS500[72, 3]在边缘检测这一经典低级任务上评估SAM。我们使用自动掩码生成流水线的简化版本。具体来说,我们用16×1616\times1616×16的前景点规则网格提示SAM,产生768个预测掩码(每个点3个)。冗余掩码通过NMS去除。然后,使用未阈值化掩码概率图的Sobel滤波和标准轻量级后处理(包括边缘NMS)计算边缘图(详见§D.2\S\mathrm{D}.2§D.2)。
Results. We visualize representative edge maps in Fig. 10 (see Fig. 15 for more). Qualitatively, we observe that even though SAM was not trained for edge detection, it produces reasonable edge maps. Compared to the ground truth, SAM predicts more edges, including sensible ones that are not annotated in BSDS500. This bias is reflected quantitatively in Table 3: recall at 50%50\%50% precision (R50) is high, at the cost of precision. SAM naturally lags behind state-of-the-art methods that learn the biases of BSDS500, i.e., which edges to suppress. Nevertheless, SAM performs well compared to pioneering deep learning methods such as HED [108] (also trained on BSDS500) and significantly better than prior, though admittedly outdated, zero-shot transfer methods.
【翻译】结果。我们在图10中可视化了代表性的边缘图(更多请参见图15)。定性地,我们观察到尽管SAM没有为边缘检测进行训练,但它产生了合理的边缘图。与真实值相比,SAM预测了更多边缘,包括在BSDS500中未标注的合理边缘。这种偏差在表3中定量反映:在50%50\%50%精确度下的召回率(R50)很高,但以精确度为代价。SAM自然落后于学习BSDS500偏差的最先进方法,即哪些边缘需要抑制。尽管如此,与先驱深度学习方法如HED[108](也在BSDS500上训练)相比,SAM表现良好,并且显著优于之前的零样本迁移方法,尽管承认这些方法已经过时。
7.3. Zero-Shot Object Proposals
Approach. Next, we evaluate SAM on the mid-level task of object proposal generation [2, 102]. This task has played an important role in object detection research, serving as an intermediate step in pioneering systems (e.g., [102, 41, 84]). To generate object proposals, we run a slightly modified version of our automatic mask generation pipeline and output the masks as proposals (see §D.3\S\mathrm{D}.3§D.3 for details).
【翻译】方法。接下来,我们在对象提议生成[2, 102]这一中级任务上评估SAM。这项任务在目标检测研究中发挥了重要作用,在开创性系统中作为中间步骤(例如,[102, 41, 84])。为了生成对象提议,我们运行自动掩码生成流水线的略微修改版本,并将掩码作为提议输出(详见§D.3\S\mathrm{D}.3§D.3)。
Table 4: Object proposal generation on LVIS v1. SAM is applied zero-shot, i.e. it was not trained for object proposal generation nor did it access LVIS images or annotations.
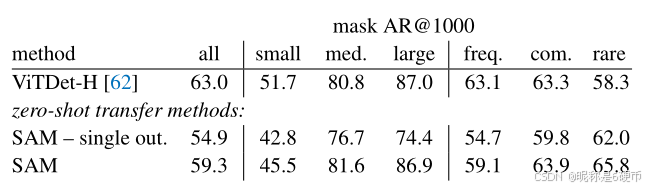
【翻译】表4:在LVIS v1上的对象提议生成。SAM以零样本方式应用,即它没有为对象提议生成进行训练,也没有访问LVIS图像或注释。
We compute the standard average recall (AR) metric on LVIS v1 [44]. We focus on LVIS because its large number of categories presents a challenging test. We compare to a strong baseline implemented as a ViTDet [62] detector (with cascade Mask R-CNN [48, 11] ViT-H). We note that this “baseline” corresponds to the “Detector Masquerading as Proposal generator” (DMP) method [16] that was shown to game AR, making it a truly demanding comparison.
【翻译】我们在LVIS v1[44]上计算标准平均召回率(AR)指标。我们专注于LVIS,因为其大量类别呈现了一个具有挑战性的测试。我们与作为ViTDet[62]检测器(带有级联Mask R-CNN[48, 11] ViT-H)实现的强基线进行比较。我们注意到这个"基线"对应于"伪装成提议生成器的检测器"(DMP)方法[16],该方法被显示能够钻AR的空子,使其成为真正苛刻的比较。
Results. In Table 4 we see unsurprisingly that using the detections from ViTDet-H as object proposals (i.e., the DMP method [16] that games AR) performs the best overall. However, SAM does remarkably well on several metrics. Notably, it outperforms ViTDet-H on medium and large objects, as well as rare and common objects. In fact, SAM only underperforms ViTDet-H on small objects and frequent objects, where ViTDet-H can easily learn LVISspecific annotation biases since it was trained on LVIS, unlike SAM. We also compare against an ablated ambiguityunaware version of SAM (“single out.”), which performs significantly worse than SAM on all AR metrics.
【翻译】结果。在表4中,我们毫不意外地看到使用ViTDet-H的检测作为对象提议(即钻AR空子的DMP方法[16])整体表现最佳。然而,SAM在多个指标上表现得非常好。值得注意的是,它在中等和大型对象以及稀有和常见对象上优于ViTDet-H。实际上,SAM仅在小对象和频繁对象上表现不如ViTDet-H,在这些方面ViTDet-H可以轻易学习LVIS特定的注释偏差,因为它在LVIS上训练过,而SAM没有。我们还与SAM的消融歧义不感知版本(“单一输出”)进行比较,该版本在所有AR指标上的表现都显著差于SAM。
7.4. Zero-Shot Instance Segmentation
Approach. Moving to higher-level vision, we use SAM as the segmentation module of an instance segmenter. The implementation is simple: we run a object detector (the ViTDet used before) and prompt SAM with its output boxes. This illustrates composing SAM in a larger system.
【翻译】方法。转向更高级的视觉任务,我们将SAM用作实例分割器的分割模块。实现很简单:我们运行一个目标检测器(之前使用的ViTDet)并用其输出框提示SAM。这说明了在更大系统中组合SAM的方法。
Results. We compare the masks predicted by SAM and ViTDet on COCO and LVIS in Table 5. Looking at the mask AP metric we observe gaps on both datasets, where SAM is reasonably close, though certainly behind ViTDet. By visualizing outputs, we observed that SAM masks are often qualitatively better than those of ViTDet, with crisper boundaries (see §D.4\S\mathrm{D}.4§D.4 and Fig. 16). To investigate this observation, we conducted an additional human study asking annotators to rate the ViTDet masks and SAM masks on the 1 to 10 quality scale used before. In Fig. 11 we observe that SAM consistently outperforms ViTDet in the human study.
【翻译】结果。我们在表5中比较SAM和ViTDet在COCO和LVIS上预测的掩码。观察掩码AP指标,我们在两个数据集上都观察到差距,SAM相当接近,但肯定落后于ViTDet。通过可视化输出,我们观察到SAM掩码在质量上通常比ViTDet的更好,具有更清晰的边界(见§D.4\S\mathrm{D}.4§D.4和图16)。为了调查这一观察,我们进行了额外的人类研究,要求注释者按照之前使用的1到10质量评分标准对ViTDet掩码和SAM掩码进行评分。在图11中我们观察到SAM在人类研究中始终优于ViTDet。
Table 5: Instance segmentation results. SAM is prompted with ViTDet boxes to do zero-shot segmentation. The fullysupervised ViTDet outperforms SAM, but the gap shrinks on the higher-quality LVIS masks. Interestingly, SAM outperforms ViTDet according to human ratings (see Fig. 11).
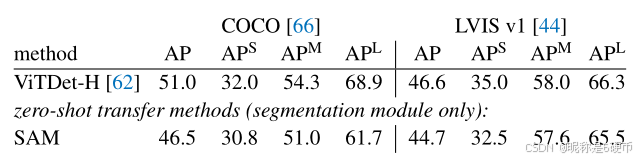
【翻译】表5:实例分割结果。SAM用ViTDet框提示进行零样本分割。完全监督的ViTDet优于SAM,但在更高质量的LVIS掩码上差距缩小。有趣的是,根据人类评分,SAM优于ViTDet(见图11)。
Figure 11: Mask quality rating distribution from our human study for ViTDet and SAM, both applied to LVIS ground truth boxes. We also report LVIS and COCO ground truth quality. The legend shows rating means and 95%95\%95% confidence intervals. Despite its lower AP (Table 5), SAM has higher ratings than ViTDet, suggesting that ViTDet exploits biases in the COCO and LVIS training data.
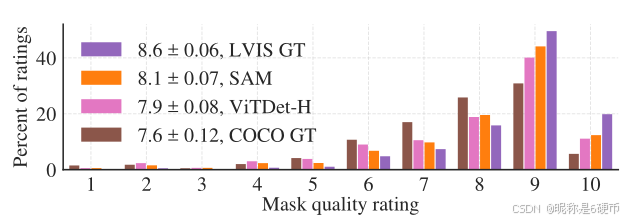
【翻译】图11:我们人类研究中ViTDet和SAM的掩码质量评分分布,两者都应用于LVIS真实框。我们还报告了LVIS和COCO真实值质量。图例显示评分均值和95%95\%95%置信区间。尽管AP较低(表5),SAM的评分高于ViTDet,表明ViTDet利用了COCO和LVIS训练数据中的偏差。
We hypothesize that on COCO, where the mask AP gap is larger and the ground truth quality is relatively low (as borne out by the human study), ViTDet learns the specific biases of COCO masks. SAM, being a zero-shot method, is unable to exploit these (generally undesirable) biases. The LVIS dataset has higher quality ground truth, but there are still specific idiosyncrasies (e.g., masks do not contain holes, they are simple polygons by construction) and biases for modal vs. amodal masks. Again, SAM is not trained to learn these biases, while ViTDet can exploit them.
【翻译】我们假设在COCO上,掩码AP差距较大且真实值质量相对较低(如人类研究所证实),ViTDet学习了COCO掩码的特定偏差。SAM作为零样本方法,无法利用这些(通常不受欢迎的)偏差。LVIS数据集具有更高质量的真实值,但仍存在特定的特殊性(例如,掩码不包含孔洞,它们在构造上是简单多边形)以及对模态与非模态掩码的偏差。同样,SAM没有被训练来学习这些偏差,而ViTDet可以利用它们。
7.5. Zero-Shot Text-to-Mask
Approach. Finally, we consider an even higher-level task: segmenting objects from free-form text. This experiment is a proof-of-concept of SAM’s ability to process text prompts. While we used the exact same SAM in all prior experiments, for this one SAM’s training procedure is modified to make it text-aware, but in a way that does not require new text annotations. Specifically, for each manually collected mask with area larger than 1002\mathrm{100}^{2}1002 we extract the CLIP image embedding. Then, during training, we prompt SAM with the extracted CLIP image embeddings as its first interaction. The key observation here is that because CLIP’s image embeddings are trained to align with its text embeddings, we can train with image embeddings, but use text embeddings for inference. That is, at inference time we run text through CLIP’s text encoder and then give the resulting text embedding as a prompt to SAM (see §D.5\S\mathrm{D}.5§D.5 for details).
【翻译】方法。最后,我们考虑一个更高级的任务:从自由形式文本中分割对象。这个实验是SAM处理文本提示能力的概念验证。虽然我们在之前的所有实验中使用了完全相同的SAM,但在这个实验中,SAM的训练过程被修改以使其具有文本感知能力,但不需要新的文本注释。具体来说,对于每个面积大于1002\mathrm{100}^{2}1002的手动收集掩码,我们提取CLIP图像嵌入。然后,在训练期间,我们用提取的CLIP图像嵌入作为第一次交互来提示SAM。这里的关键观察是,由于CLIP的图像嵌入被训练来与其文本嵌入对齐,我们可以用图像嵌入进行训练,但在推理时使用文本嵌入。也就是说,在推理时我们通过CLIP的文本编码器运行文本,然后将得到的文本嵌入作为提示给SAM(详见§D.5\S\mathrm{D}.5§D.5)。
Figure 12: Zero-shot text-to-mask. SAM can work with simple and nuanced text prompts. When SAM fails to make a correct prediction, an additional point prompt can help.

【翻译】图12:零样本文本到掩码。SAM可以处理简单和细致的文本提示。当SAM无法根据文本提示做出正确预测时,额外的点提示可以帮助。
Results. We show qualitative results in Fig. 12. SAM can segment objects based on simple text prompts like “a wheel” as well as phrases like “beaver tooth grille”. When SAM fails to pick the right object from a text prompt only, an additional point often fixes the prediction, similar to [31].
【翻译】结果。我们在图12中显示了定性结果。SAM可以基于简单的文本提示如"一个轮子"以及短语如"海狸牙格栅"来分割对象。当SAM仅根据文本提示无法选择正确对象时,额外的点通常可以修正预测,类似于[31]。
7.6. Ablations
We perform several ablations on our 23 dataset suite with the single center point prompt protocol. Recall that a single point may be ambiguous and that ambiguity may not be represented in the ground truth, which contains only a single mask per point. Since SAM is operating in a zeroshot transfer setting there can be systematic biases between SAM’s top-ranked mask vs. the masks resulting from data annotation guidelines. We therefore additionally report the best mask with respect to the ground truth (“oracle”).
【翻译】我们在23个数据集组合上使用单个中心点提示协议执行了几项消融实验。回想一下,单个点可能是模糊的,且这种模糊性可能没有在真实值中体现,真实值每个点只包含一个掩码。由于SAM在零样本迁移设置中运行,SAM的最高排名掩码与数据注释准则产生的掩码之间可能存在系统性偏差。因此,我们还报告了相对于真实值的最佳掩码(“oracle”)。
Fig. 13 (left) plots SAM’s performance when trained on cumulative data from the data engine stages. We observe that each stage increases mIoU. When training with all three stages, the automatic masks vastly outnumber the manual and semi-automatic masks. To address this, we found that oversampling the manual and semi-automatic masks during training by 10×10\times10× gave best results. This setup complicates training. We therefore tested a fourth setup that uses only the automatically generated masks. With this data, SAM performs only marginally lower than using all data (∼0.5(\mathord{\sim}0.5(∼0.5 mIoU). Therefore, by default we use only the automatically generated masks to simplify the training setup.
【翻译】图13(左)绘制了SAM在数据引擎阶段累积数据上训练时的性能。我们观察到每个阶段都提高了mIoU。当使用所有三个阶段进行训练时,自动掩码数量远远超过手动和半自动掩码。为了解决这个问题,我们发现在训练期间将手动和半自动掩码过采样10×10\times10×能获得最佳结果。这种设置使训练复杂化。因此,我们测试了第四种只使用自动生成掩码的设置。使用这些数据,SAM的性能仅比使用所有数据略低(∼0.5(\mathord{\sim}0.5(∼0.5 mIoU)。因此,默认情况下我们只使用自动生成的掩码来简化训练设置。
In Fig. 13 (middle) we look at the impact of data volume. The full SA-1B contains 11M images, which we uniformly subsample to 1M and 0.1M for this ablation. At 0.1M images, we observe a large mIoU decline under all settings. However, with 1M images, about 10%10\%10% of the full dataset, we observe results comparable to using the full dataset. This data regime, which still includes approximately 100M masks, may be a practical setting for many use cases.
【翻译】在图13(中间)我们查看数据量的影响。完整的SA-1B包含1100万张图像,我们对此消融实验均匀子采样到100万和10万张。在10万张图像时,我们在所有设置下都观察到mIoU大幅下降。然而,使用100万张图像(约占完整数据集的10%10\%10%),我们观察到与使用完整数据集相当的结果。这种数据规模仍包含大约1亿个掩码,对许多用例来说可能是一个实用的设置。
Figure 13: Ablation studies of our data engine stages, image encoder scaling, and training data scaling. (Left) Each data engine stage leads to improvements on our 23 dataset suite, and training with only the automatic data (our default) yields similar results to using data from all three stages. (Middle) SAM trained with ∼10%\sim10\%∼10% of SA-1B and full SA-1B is comparable. We train with all 11M images by default, but using 1M images is a reasonable practical setting. (Right) Scaling SAM’s image encoder shows meaningful, yet saturating gains. Nevertheless, smaller image encoders may be preferred in certain settings.

【翻译】图13:我们数据引擎阶段、图像编码器缩放和训练数据缩放的消融研究。(左)每个数据引擎阶段都导致我们23个数据集组合的改进,仅使用自动数据进行训练(我们的默认设置)产生与使用所有三个阶段数据相似的结果。(中间)使用SA-1B的∼10%\sim10\%∼10%和完整SA-1B训练的SAM是可比的。我们默认使用所有1100万张图像进行训练,但使用100万张图像是一个合理的实用设置。(右)缩放SAM的图像编码器显示有意义但饱和的收益。尽管如此,在某些设置中可能更喜欢较小的图像编码器。
Finally, Fig. 13 (right) shows results with ViT-B, ViT-L, and ViT-H image encoders. ViT-H improves substantially over ViT-B, but has only marginal gains over ViT-L. Further image encoder scaling does not appear fruitful at this time.
【翻译】最后,图13(右)显示了ViT-B、ViT-L和ViT-H图像编码器的结果。ViT-H相比ViT-B有显著改进,但相比ViT-L只有边际收益。进一步的图像编码器缩放目前看起来不太有效。
8. Discussion
Foundation models. Pre-trained models have been adapted to downstream tasks since the early days of machine learning [99]. This paradigm has become increasingly important in recent years with a growing emphasis on scale, and such models have recently been (re-)branded as “foundation models”: i.e. models that are “trained on broad data at scale and are adaptable to a wide range of downstream tasks” [8]. Our work correlates well with this definition, though we note that a foundation model for image segmentation is an inherently limited scope, since it represents an important, yet fractional, subset of computer vision. We also contrast one aspect of our approach with [8], which emphasizes the role of self-supervised learning in foundation models. While our model is initialized with a selfsupervised technique (MAE [47]), the vast majority of its capabilities come from large-scale supervised training. In cases where data engines can scale available annotations, like ours, supervised training provides an effective solution.
【翻译】基础模型。自机器学习早期以来,预训练模型就被用于适应下游任务[99]。这种范式在近年来变得越来越重要,越来越强调规模,这些模型最近被(重新)标记为"基础模型":即"在大规模广泛数据上训练并能适应广泛下游任务"的模型[8]。我们的工作与这个定义相符,尽管我们注意到图像分割的基础模型本质上是一个有限的范围,因为它代表了计算机视觉中一个重要但只是部分的子集。我们还将我们方法的一个方面与[8]进行对比,后者强调自监督学习在基础模型中的作用。虽然我们的模型使用自监督技术(MAE [47])进行初始化,但其绝大部分能力来自大规模监督训练。在数据引擎可以扩展可用注释的情况下,比如我们的情况,监督训练提供了一个有效的解决方案。
Compositionality. Pre-trained models can power new capabilities even beyond ones imagined at the moment of training. One prominent example is how CLIP [82] is used as a component in larger systems, such as DALL E [83]. Our goal is to make this kind of composition straightforward with SAM. We aim to achieve this by requiring SAM to predict a valid mask for a wide range of segmentation prompts. The effect is to create a reliable interface between SAM and other components. For example, MCC [106] can easily use SAM to segment an object of interest and achieve strong generalization to unseen objects for 3D reconstruction from a single RGB-D image. In another example, SAM can be prompted with gaze points detected by a wearable device, enabling new applications. Thanks to SAM’s ability to generalize to new domains like ego-centric images, such systems work without need for additional training.
【翻译】组合性。预训练模型能够支持新功能,甚至超越训练时想象的功能。一个突出的例子是CLIP [82]如何作为更大系统中的组件使用,比如DALL E [83]。我们的目标是使SAM的这种组合变得简单。我们通过要求SAM为广泛的分割提示预测有效掩码来实现这一目标。效果是在SAM和其他组件之间创建一个可靠的接口。例如,MCC [106]可以轻松使用SAM分割感兴趣的对象,并在从单个RGB-D图像进行3D重建时对未见过的对象实现强泛化。在另一个例子中,SAM可以被可穿戴设备检测到的注视点提示,从而实现新的应用。由于SAM能够泛化到新领域如以自我为中心的图像,这样的系统无需额外训练即可工作。
Limitations. While SAM performs well in general, it is not perfect. It can miss fine structures, hallucinates small disconnected components at times, and does not produce boundaries as crisply as more computationally intensive methods that “zoom-in”, e.g. [18]. In general, we expect dedicated interactive segmentation methods to outperform SAM when many points are provided, e.g. [67]. Unlike these methods, SAM is designed for generality and breadth of use rather than high IoU interactive segmentation. Moreover, SAM can process prompts in real-time, but nevertheless SAM’s overall performance is not real-time when using a heavy image encoder. Our foray into the text-to-mask task is exploratory and not entirely robust, although we believe it can be improved with more effort. While SAM can perform many tasks, it is unclear how to design simple prompts that implement semantic and panoptic segmentation. Finally, there are domain-specific tools, such as [7], that we expect to outperform SAM in their respective domains.
【翻译】局限性。虽然SAM总体表现良好,但它并不完美。它可能会遗漏精细结构,有时会产生小的断开组件的幻觉,并且不会像更计算密集的"放大"方法那样产生清晰的边界,例如[18]。一般来说,我们预期当提供许多点时,专门的交互式分割方法会优于SAM,例如[67]。与这些方法不同,SAM是为通用性和使用广度而设计的,而不是高IoU交互式分割。此外,SAM可以实时处理提示,但当使用重型图像编码器时,SAM的整体性能并非实时。我们对文本到掩码任务的尝试是探索性的,并非完全鲁棒,尽管我们相信通过更多努力可以改进。虽然SAM可以执行许多任务,但如何设计实现语义和全景分割的简单提示尚不清楚。最后,存在特定领域的工具,比如[7],我们预期它们在各自领域会优于SAM。
Conclusion. The Segment Anything project is an attempt to lift image segmentation into the era of foundation models. Our principal contributions are a new task (promptable segmentation), model (SAM), and dataset (SA-1B) that make this leap possible. Whether SAM achieves the status of a foundation model remains to be seen by how it is used in the community, but regardless we expect the perspective of this work, the release of over 1B masks, and our promptable segmentation model will help pave the path ahead.
【翻译】结论。Segment Anything项目是将图像分割提升到基础模型时代的尝试。我们的主要贡献是一个新任务(可提示分割)、模型(SAM)和数据集(SA-1B),这些使这一跃进成为可能。SAM是否达到基础模型的地位有待于它在社区中的使用情况来判断,但无论如何,我们期望这项工作的视角、超过10亿个掩码的发布以及我们的可提示分割模型将有助于铺平前进的道路。