论文阅读:BLIP-2 (2023.4)
文章目录
- BLIP-2:基于冻结图像编码器和大型语言模型的语言-图像预训练方法总结
- 一、研究背景与动机
- 二、核心方法
- 1. Q-Former 模型架构
- 2. 两阶段预训练过程
- 第一阶段:视觉-语言表示学习
- 第二阶段:视觉到语言生成学习
- 一些细节
- 1. 大batch size
- 2. 提前对齐
- 三、实验设置
- 四、实验结果
- 五、局限性
- 六、结论
BLIP-2:基于冻结图像编码器和大型语言模型的语言-图像预训练方法总结
论文题目: BLIP-2: Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models
论文链接: https://arxiv.org/pdf/2301.12597
- BLIPv2是Salesforce开始走向大模型的第一个工作
- Qformer将视觉信息对齐到文本空间
- 嵌入LLM进行视觉驱动的文本生成或问答
一、研究背景与动机
-
现有问题
视觉-语言预训练(VLP)因大规模模型的端到端训练,成本日益高昂,且难以灵活利用现成的单模态预训练模型(如视觉模型和大型语言模型(LLMs))。 -
研究目标
提出一种通用且高效的预训练策略 BLIP-2,利用现成的冻结预训练图像编码器和冻结大型语言模型进行视觉-语言预训练,以降低计算成本并提升性能。
二、核心方法
BLIP-2 通过轻量级的查询 Transformer(Q-Former) 弥合模态差距,并采用两阶段预训练策略。
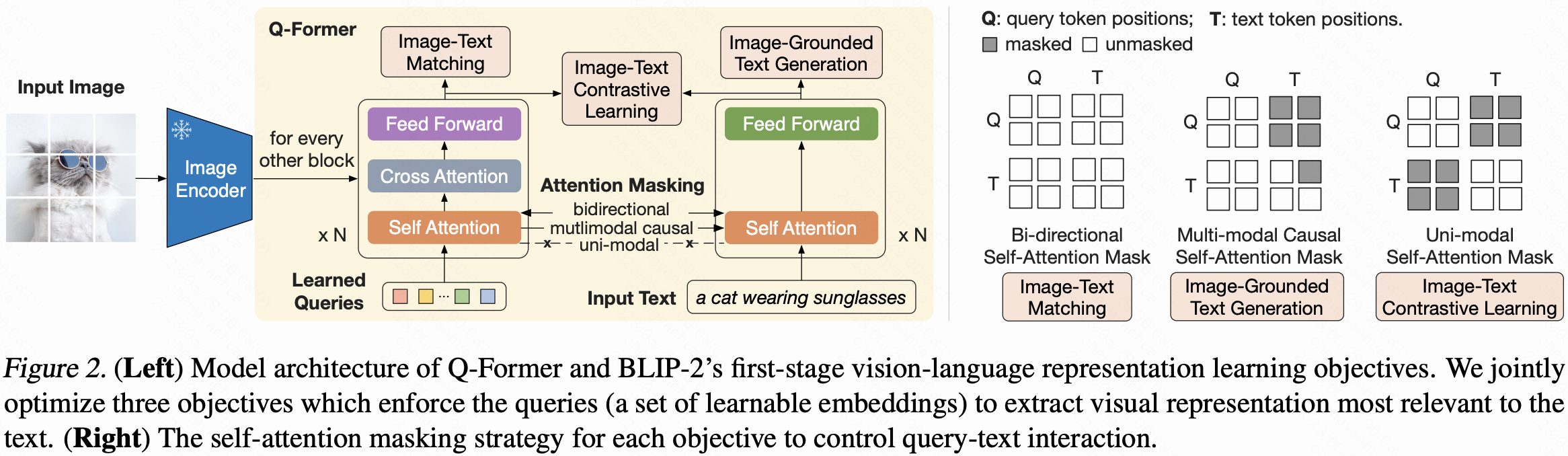
1. Q-Former 模型架构
- 可训练模块,含两个共享自注意力层的 Transformer 子模块:
- 图像 Transformer:与冻结图像编码器交互,提取视觉特征。
- 文本 Transformer:可作为文本编码器和解码器。
- 输入:一组可学习的查询嵌入
- 数量:32
- 维度:768
- 交互方式:
- 查询通过自注意力层相互作用
- 通过交叉注意力层与冻结图像特征交互
- 通过自注意力层与文本交互
- 信息瓶颈:总参数 188 M,迫使查询提取与文本最相关的视觉信息。
2. 两阶段预训练过程
第一阶段:视觉-语言表示学习
- 与冻结图像编码器连接,使用图像-文本对预训练。
- 三大优化目标:
- 图像-文本对比学习(ITC):对齐图像与文本表示,最大化互信息。
- 图像引导文本生成(ITG):训练 Q-Former 在图像条件下生成文本。
- 图像-文本匹配(ITM):学习细粒度对齐,预测图像-文本对是否匹配。
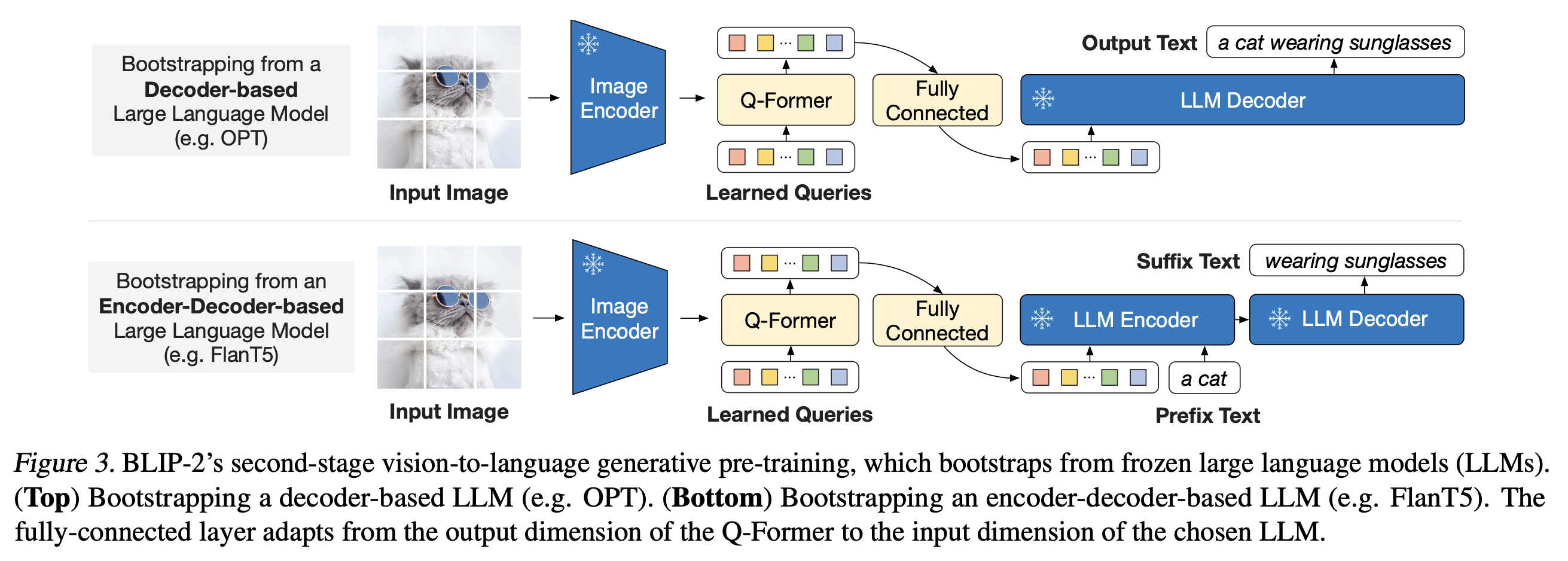
第二阶段:视觉到语言生成学习
- 将 Q-Former(附加冻结图像编码器)与冻结 LLM 连接。
- 软视觉提示:通过全连接层将查询嵌入投影到 LLM 文本嵌入维度。
- 损失函数:
- 解码器基 LLM:语言建模损失。
- 编码器-解码器基 LLM:前缀语言建模损失。
第二阶段网络结构图:
一些细节
1. 大batch size
第一阶段用了2320/1680 的 batch size, 第二阶段用了 1920/ 1520 的 batch size.

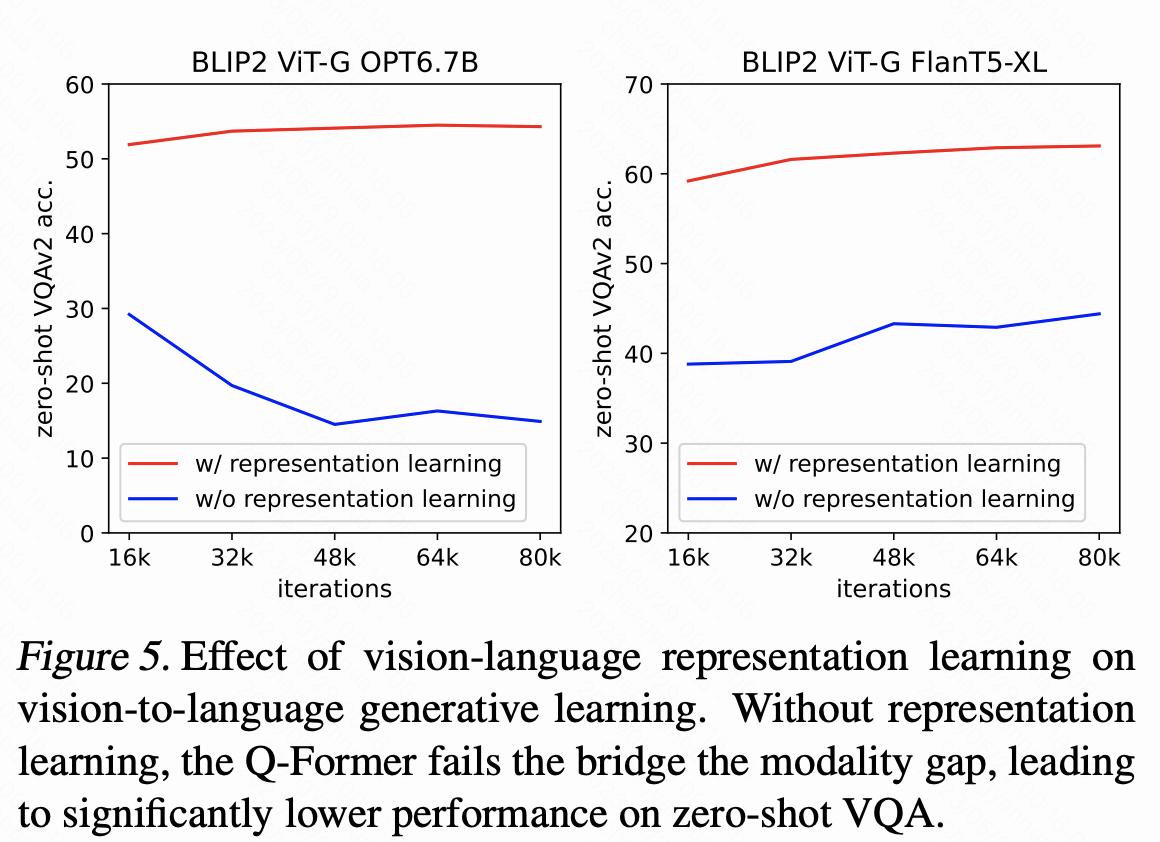
2. 提前对齐
不提前对齐 (representation learning )的话,大模型在 VQA 上的效果会大打折扣。
三、实验设置
-
预训练数据
1.29 亿张图像,含 COCO、Visual Genome 等,采用 CapFilt 生成合成标题。 -
预训练模型
- 图像编码器:ViT-L/14、ViT-g/14
- LLM:OPT(解码器基)、FlanT5(编码器-解码器基)
-
训练设置
- 第一阶段:250 k 步
- 第二阶段:80 k 步
- 优化器:AdamW,余弦学习率衰减
- 精度:FP16 / BFloat16 → 计算成本低
四、实验结果
BLIP-2 在多种任务上达到SOTA,且可训练参数显著更少:
| 任务 | 数据集 | 结果 | 对比 |
|---|---|---|---|
| 零样本 VQA | VQAv2 | 65.0% (108 M 可训练参数) | 超 Flamingo80B(10.2 B 参数)8.7% |
| 图像 Captioning | NoCaps | CIDEr 121.6, SPICE 15.8 | 优于 BLIP 等 |
| 图像-文本检索 | Flickr30K | 图像→文本 R@1 97.6% 文本→图像 R@1 89.7% | 优于现有方法 |
五、局限性
- 缺乏上下文学习能力:预训练数据每个样本仅含一个图像-文本对。
- 图像到文本生成可能不理想:
- LLM 知识不准确、推理错误
- 继承 LLM 风险(冒犯性语言等)
六、结论
BLIP-2 是一种通用且高效的视觉-语言预训练方法,通过两阶段预训练轻量级 Q-Former,利用冻结图像编码器和 LLM,在多种任务上表现优异,为构建多模态对话 AI 代理迈出重要一步。
BLIP v2 为现在的多模态 LLM 提供了很好的思路,比如 visual GLM 基本就是复制了改方案。