Florence2-通用表征完成多种视觉任务的视觉基础模型
Florence-2 是由微软于 2024 年 6 月发布的开源模型,目的是使用通用的表征完成一系列复杂任务,如QA问答、描述、检测、分割、OCR等。Florence-2-base和large模型的参数量分别为 0.23B和0.77B,参数量虽小,但实现了SOTA性能。
数据集:FLD-5B,包含 1.26 亿张图像的 54 亿条全面的视觉标注。
论文

在计算机视觉当中,希望能够实现通用的表征来完成一系列复杂的任务。 比如说QA问答任务、描述任务、检测任务、分割任务、OCR任务等等 。
这就要求模型首先在空间层次上边能够在不同的尺度上边来辨别空间的细节,理解图像级的概念以及精细的像素细节。第二是要求这个通用的表征能够覆盖多种语义颗粒度,比如说模型既可以实现高度的概括,也可以实现非常细致的描述,它可以实现多样化语义的理解。除了这个通用表征之外,还需要一个统一的训练框架来训练一个统一的视觉模型,这个统一的框架可以无缝的集成不同的空间层次,以及不同语义颗粒度的视觉任务。
Florence的关键点是要开发出一套统一的训练框架,这个训练框架可以在各种视觉任务当中实现统一,因此它就借用了NLP当中的语言建模,用Next Token预测的方式来统一视觉当中的各类任务。
任务格式统一(Prompt-based Unified Format):
所有任务被统一转化为 “给定图像 + 文本提示(prompt)→ 输出目标文本” 的序列生成任务。
不同任务通过文本提示词激活,例如:
"What does the image describe?" → 图像描述任务
"Locate the objects in the image." → 目标检测任务
一、模型架构
第一部分图像编码器是DaViT,第二个部分输入投影是一个线性的投影,第三部分是LLM主干, 它是一个标准的Encoder-Decoder Transformer的架构。
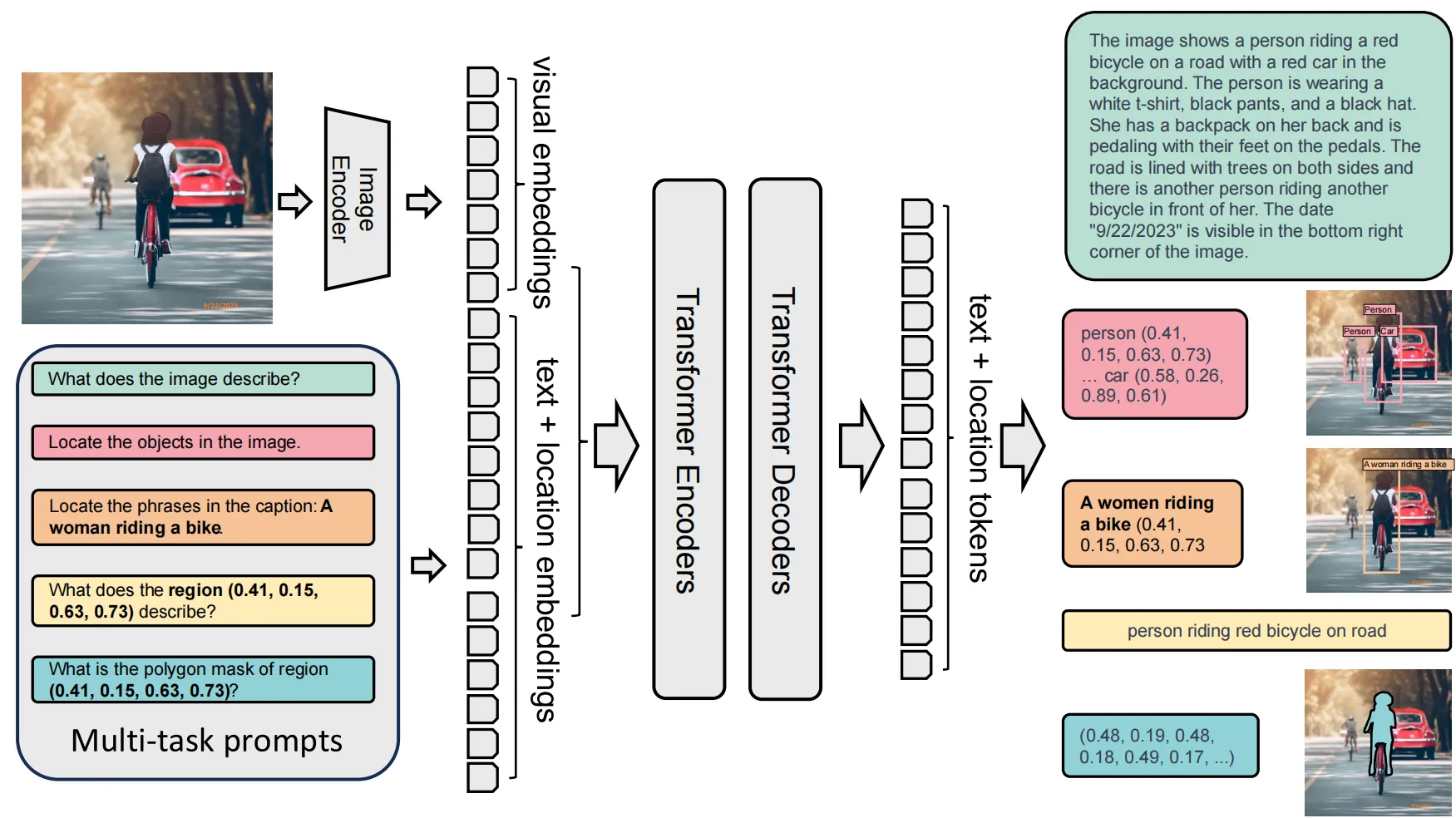
输入组成
图像:输入图像
文本提示(Prompt):自然语言任务说明或查询
图像编码器-DaViT
Dual Attention Vision Transformer,双向注意力指的就是空间注意力和通道注意力机制。这两种的Attention可以实现互补, 空间注意力能够提取空间内的局部特征, 通道注意力能够学习到全局的特征。且沿序列方向对空间和通道的Token进行了分组, 将Self-Attention的计算复杂度降低到线性。
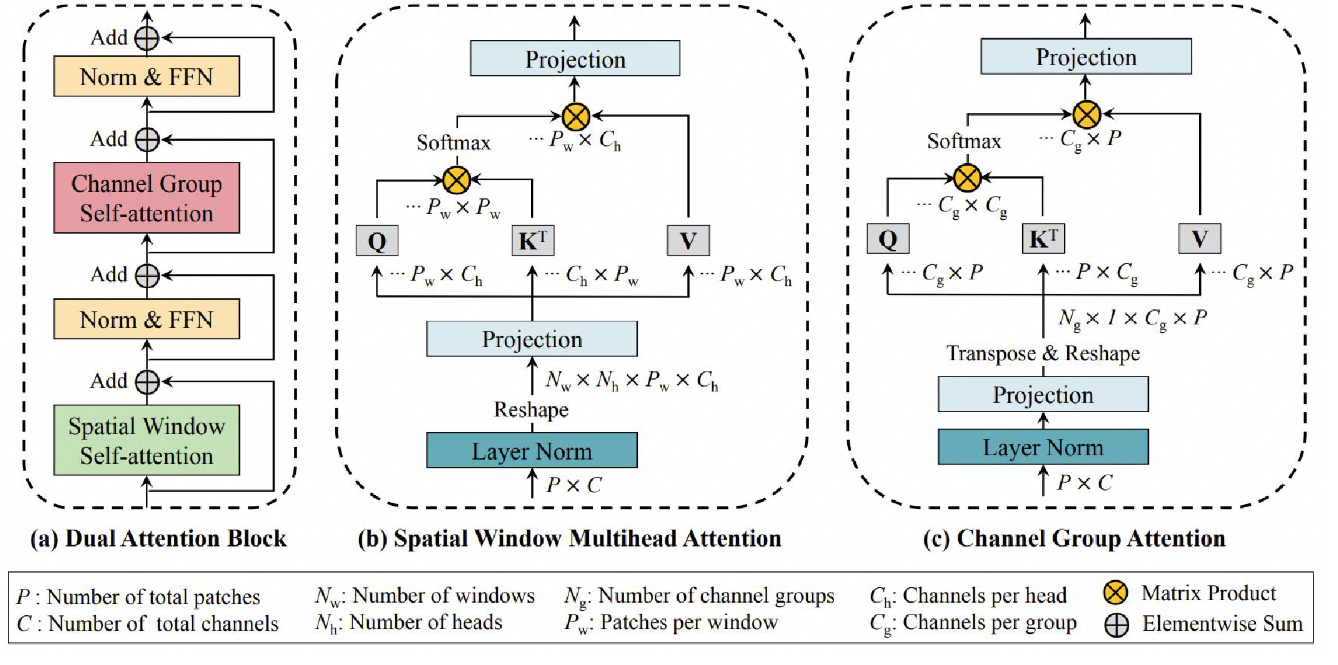
输出:V(NXD)的视觉 token embedding。
文本编码器
Florence-2 的文本编码器部分并不是一个独立存在的“文本编码器模块”(如 BERT 这样的 text encoder),而是嵌入在整个 多模态 Transformer 架构 中的一部分,用于对**任务提示文本(Prompt)**进行编码。
将任务提示(Prompt)通过 词嵌入 + 位置嵌入 → 多模态 Transformer Encoder/Decoder 输入的处理模块,并不是一个独立的 language encoder。
- Tokenizer + 词嵌入(Input Embedding)
使用一个支持特殊 token 的扩展 tokenizer(包括坐标 token、区域 token 等)。
将文本 prompt(如 “Describe the image.”)分词后,转换为 token id。
token id 输入到嵌入层,得到Tprompt,它是NXD维,N为文本token数,D为嵌入维度。
- 位置编码(Position Embedding)
对每个 token 位置添加固定或可学习的位置嵌入,和 token embedding 相加,表示序列位置信息。
如 box: (x0, y0, x1, y1)quad: (x0, y0, ..., x3, y3)polygon: (x0, y0, ..., xn, yn)
- 与视觉 token 合并输入
文本嵌入和视觉嵌入(DaViT 输出)concat合并后,形成 multi-modal encoder 的输入。
输入投影
x =x @ self.image_projection,是一个线性的投影,将 x 的维度压缩。投影完成后会再做一个 LN。完成image_embedding,这时得到的 image_feature 目的是和 text的input_embedding 做空间对齐。
如:image_embedding[2,577,768] 和 input_embedding[2,13,768]concat 起来,输入到编码器-解码器当中去,inputs_embedding[2,590,768],当然也要再对其加上位置编码。
多模态 Transformer 编码器-解码器
Florence2 Language for Conditional Generation,用于条件文本生成的语言模型。
该语言模型是一个标准的Transformer,对于输入和输出会有一个共享的Embedding,最后是一个 lm_Head,它输出的是字典当中每一个Token的概率,字典的大小是51289。
Encoder 输入 = [视觉 tokens, 文本 prompt tokens]
Decoder 输出 = 对应任务的文本响应(如标签、描述、坐标等)
以base模型为例:
- Encoder部分:包括Input Embedding,,Position Embedding以及6个Layer层,每个layer都由一个AttentionBlock组成,然后是LN,GELU激活函数,FeedForward以及最后一个LayerNorm。
- Decoder部分:包括Output Embedding,Position Embedding以及6个Layer层,每层都有因果推理mask multi head attention,GELU 激活函数,cross attention,feedfoward,LN。最后使用FeedForward和LN来收尾。
- lm_Head部分:通过线性变换将768 维的向量映射到 51289 维,每个维度对应一个词汇表中的 token。后面使用softmax转化为概率值表示每个 token 的生成概率。
位置编码
图像被处理成ImagePatch后,添加PositionEmbedding。Florence2中由两部分组成:一个是2D可学习的绝对位置编码;另一个是视觉序列的Embedding——>VisualTemporalEmbedding, 是一个Cosine1D 的Embedding。
二、损失函数
使用统一损失函数,Florence-2 的一个关键设计目标是:所有任务都转化为序列生成问题,使用统一的文本输出格式 + 相同的语言建模损失函数。
简化多任务训练流程
避免任务特定 head(如分类 head、box head)
实现任务无关的泛化能力(zero-shot/transfer)
Florence-2 的损失函数是标准的 自回归语言建模交叉熵损失(Cross-Entropy Loss),统一适用于图像描述、检测、分割、grounding 等所有任务,依赖于 prompt 作为条件输入,是典型的 sequence-to-sequence 多模态生成范式的核心优化目标。


三、评估指标
- 分类任务的评估指标是F-1 Score。
- 描述任务使用的指标是CIDEr。
- 分割来说用MIOU,检测使用mAP。
- 语义对齐任务使用mAP。
- 视觉问答任务使用Levenshtein距离、准确率(Accuracy)和余弦相似度(Cosine Similarity)。