ollama基本配置
备注:
这篇帖子后面配置部分主要是参考网上https://cloud.tencent.com/developer/news/2149855
的帖子内容,非常感谢,因为我当时没有截图记录,就套用了。特此说明。
ollama启动
ollama serve
运行ollama,也可以使用ollama的快捷方式,双启动。
关于ollama host
在安装 Ollama 时配置环境变量 OLLAMA_HOST=0.0.0.0:11434 的主要目的是允许 Ollama 服务被局域网或远程设备访问,而不仅仅是本地主机(localhost)。
默认情况下,OLLAMA HOST 为 127.0.0.1:11434(即 localhost)。
我们在运行ollama serve的时候能够看到以下提示:
(D:\CondaEnv\openwebui) PS D:\pythonProject\openwebui> ollama serve
2025/07/20 19:47:00 routes.go:1233: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERS
ION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST
:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_
LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\Administrator\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OL
LAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localh
ost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-07-20T19:47:00.218+08:00 level=INFO source=images.go:463 msg="total blobs: 17"
time=2025-07-20T19:47:00.219+08:00 level=INFO source=images.go:470 msg="total unused blobs removed: 0"
time=2025-07-20T19:47:00.221+08:00 level=INFO source=routes.go:1300 msg="Listening on 127.0.0.1:11434 (version 0.6.8)"
time=2025-07-20T19:47:00.221+08:00 level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-07-20T19:47:00.221+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-07-20T19:47:00.221+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=8 efficiency=0 threads=16
time=2025-07-20T19:47:00.377+08:00 level=INFO source=types.go:130 msg="inference compute" id=GPU-1d37e160-9923-96ff-551c-e22742bab106 library=cuda variant=v12 compute=8.6 driver=12.4 name="NVIDIA GeForce RTX 3080 Laptop GPU" total="16.0 GiB" available="14.9 GiB"这里可以看到OLLAMA_HOST:http://127.0.0.1:11434这个配置。证明当前已经是localhost访问了。
如果要设置任何人都能访问,则需要按如下来设置:
export OLLAMA_HOST=0.0.0.0:11434
ollama serve # 启动服务
上述命令是当前运行这个服务的时候生效。但有个问题,如果我们在pycharm中运行这个命令,会出现以下报错:
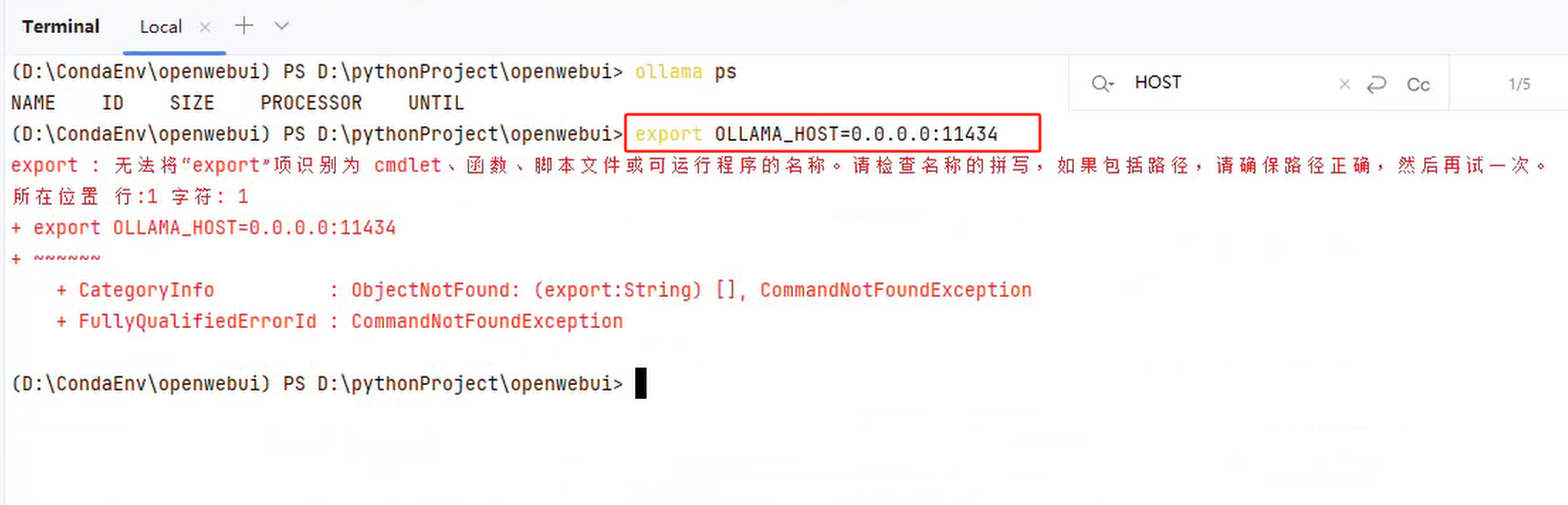
为了解决这个问题,我们在pycharm中可以输入以下命令来解决:
# 在pycharm的terminal终端中分别输入
$env:OLLAMA_HOST = "0.0.0.0:11434"
ollama serve可以看到以下内容:
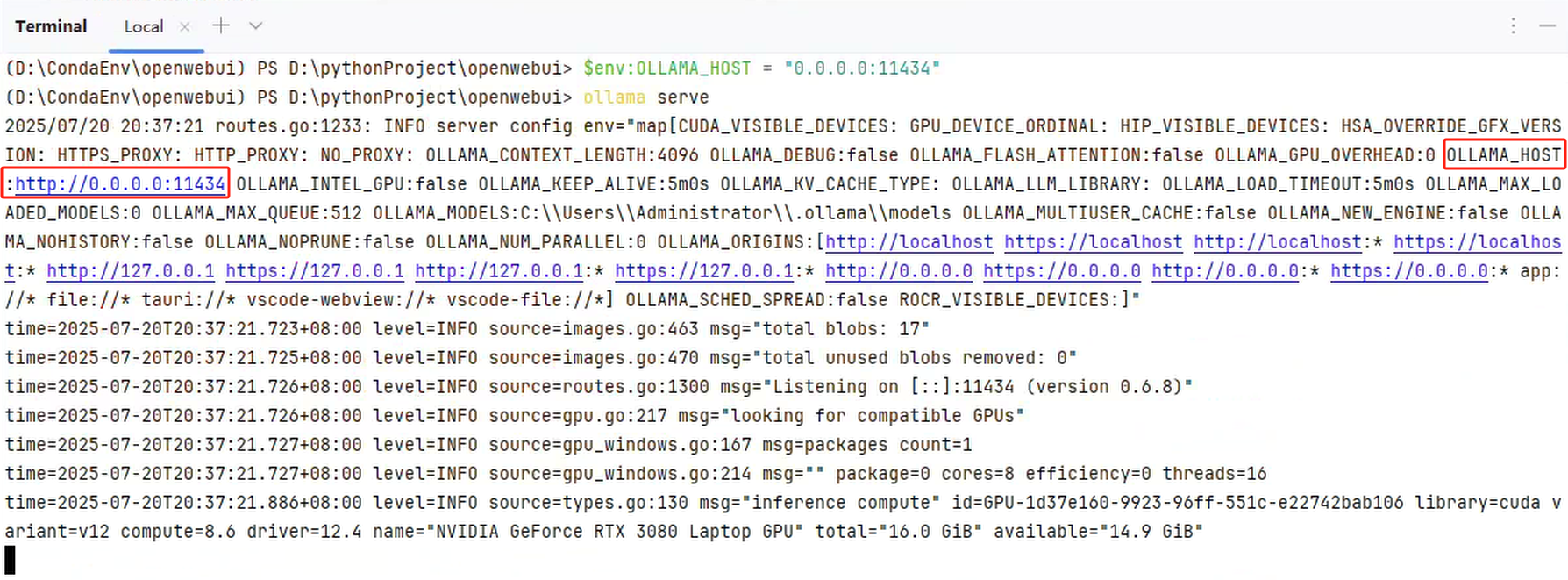
如果要永久生效,笔者检索发现可以用以下命令:
echo 'export OLLAMA_HOST=0.0.0.0:11434' >> ~/.bashrc # Linux/macOS
# 或 Windows:添加到系统环境变量!
添加环境变量的方式为:
打开「系统属性」 → 「高级」 → 「环境变量」
在「用户变量」或「系统变量」中点击「新建」
设置如下:
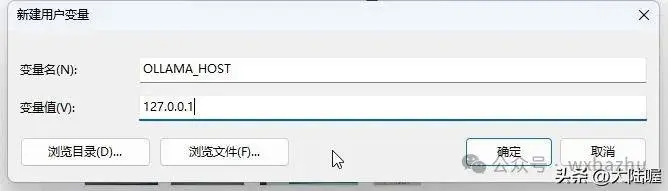
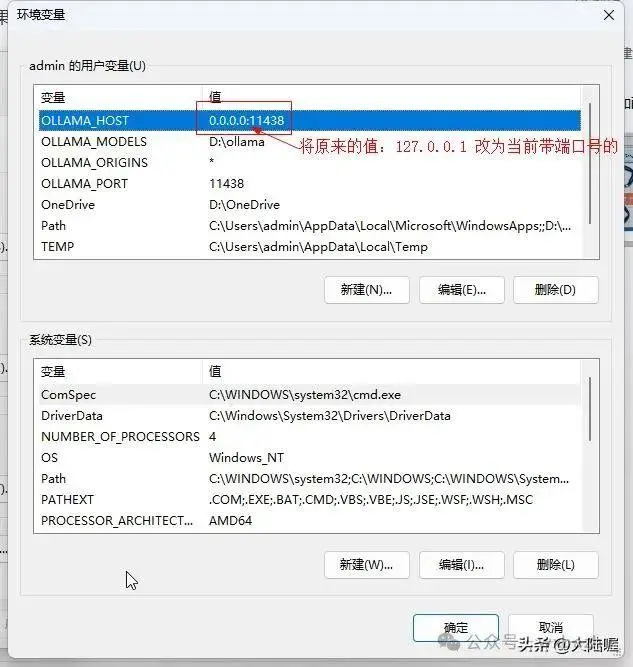
变量名:OLLAMA_HOST
变量值:127.0.0.1
点击「确定」,然后重启电脑或重新打开命令行窗口使配置生效
如果你之前设置过 OLLAMA_HOST=0.0.0.0(允许外部访问),改为 127.0.0.1 后将只允许本机访问
可以记住以下信息:
127.0.0.1:11434(默认) 仅本机 本地开发
0.0.0.0:11434 所有网络设备 跨设备/远程/容器部署
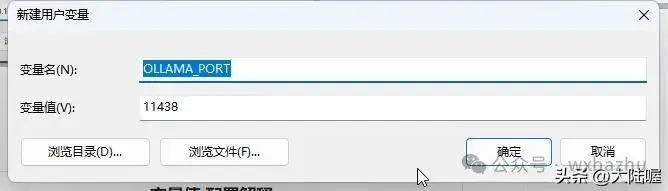
修改ollama 端口
“新建”环境变量,修改默认端口号,ollama默认使用11434端口,变量名为“OLLAMA_PORT”,变量值为可以自定义一个5为数字,我这里使用“11438”,这样就可以解决端口号被占用有冲突的问题,要是这个端口号还不行,那么再更换一个。
其他常用配置参数
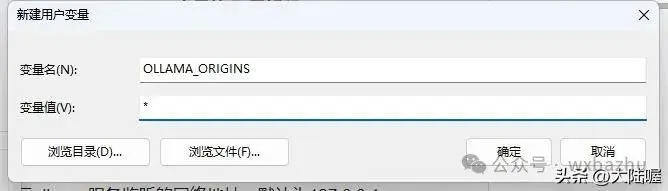
继续再新建变量,为http开放请求,变量名为“OLLAMA_ORIGINS”,变量值填写“*”(星号)即可,下图所示:
配置ollama的模型存储路径,默认是C盘,这里我们更改ollama的模型存储为D盘,先打开电脑的D盘创建一个名为“ollama”的文件夹。然后接上面弹出来的对话框中输入变量名和变量值:
变量名:OLLAMA_MODELS
变量值:D:\ollama
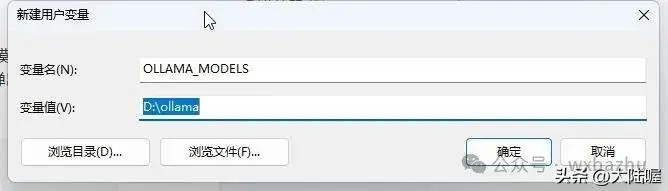
ollama更改模型存储搭配D盘
填写完成之后点“确定”。这样默认将下载的模型存储到C盘的问题就解决了,需要注意的是该设置需要重启电脑才能生效(我这里先不重启,设置后面的再重启电脑)。
上述四个变量设置后,可以看到如下样式:
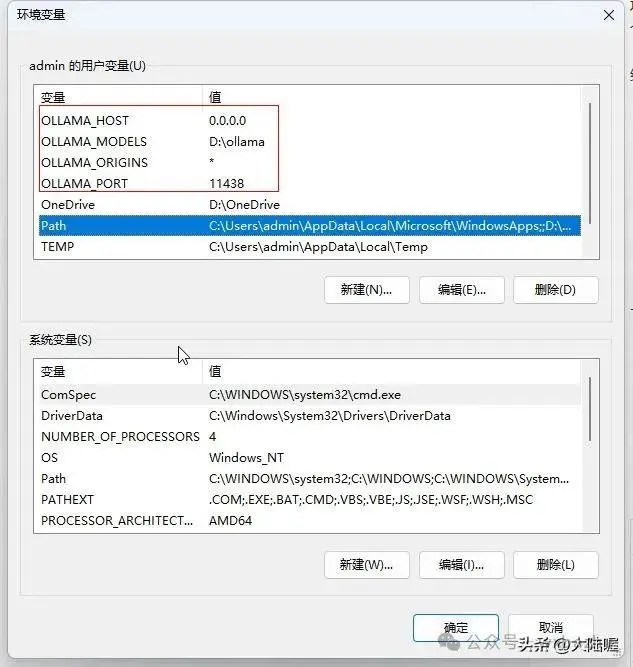
然后点“确定”,完成配置即可,其他的ollama环境变量如下表格所示,可以根据实际情况添加。
注意每次更改环境变量之后,需要重启电脑,配置才会生效,我们这里先不重启,再配置一下防火墙后再重启。
防火墙配置
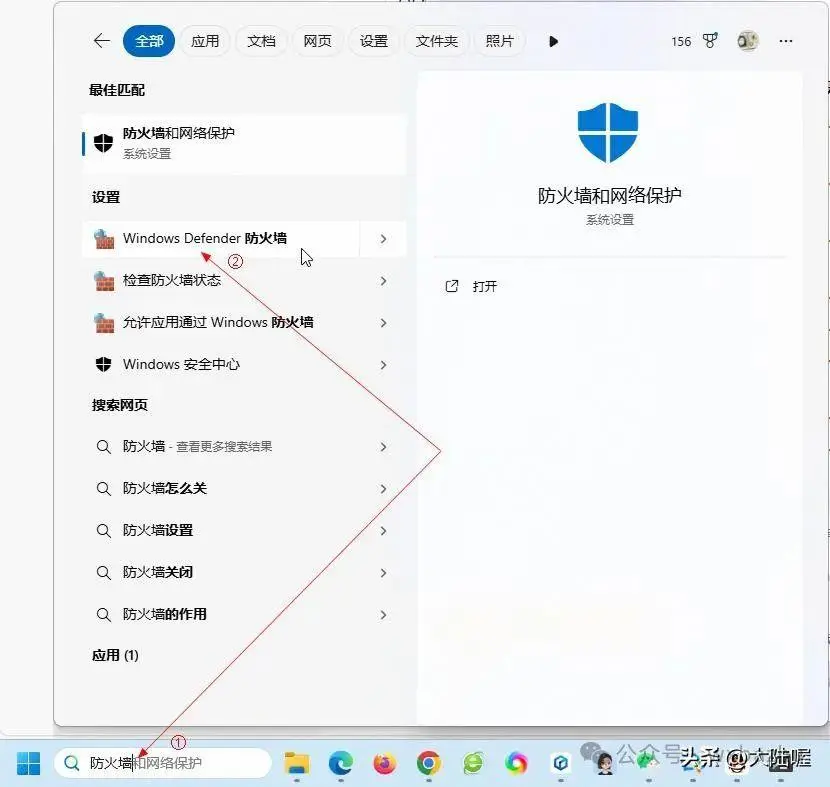
在电脑左下角搜索“防火墙”,下图所示(win10或Win11都有),点“Windows Defender 防火墙”并打开:
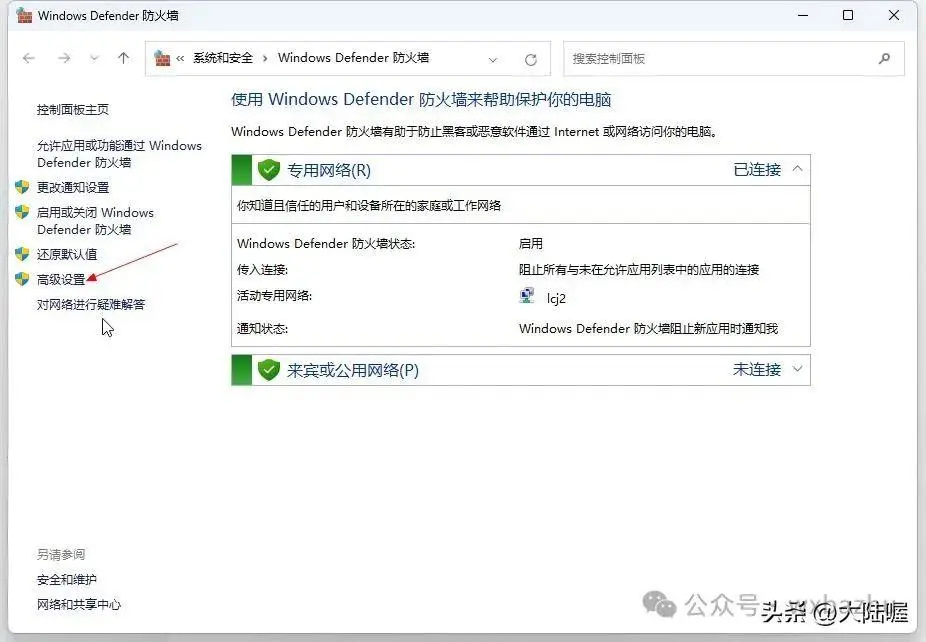
然后点下图所示的“高级设置”:
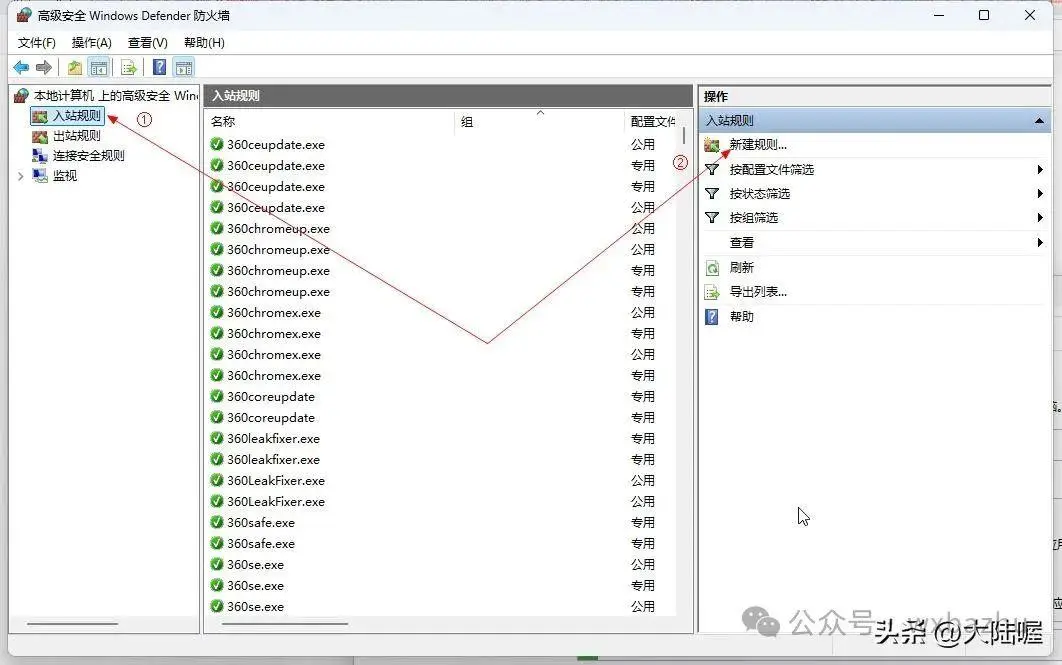
弹出的窗口如下图所示,点左上角“入站规则”,再点右上角“新建规则”:
弹出的窗口选择“端口”后,点“下一页”:
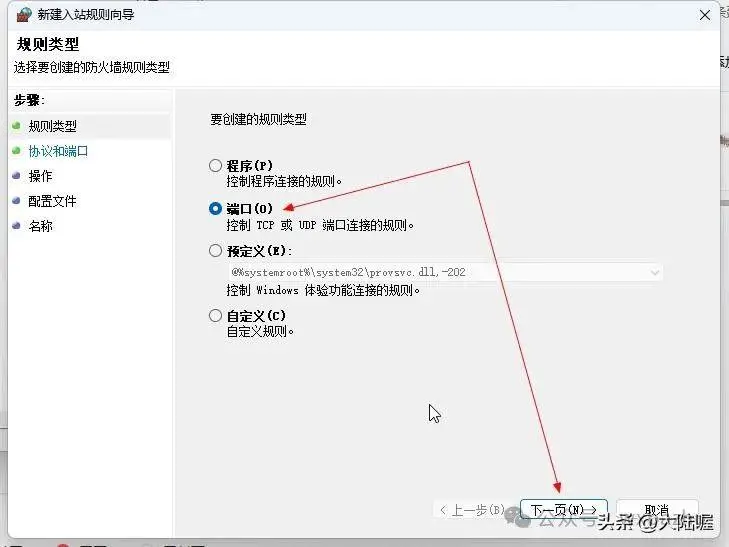
选择“TCP”,再选择“特定本地端口”,并输入前面我们配置环境变量时设置的端口号,如11438,再点“下一页”:
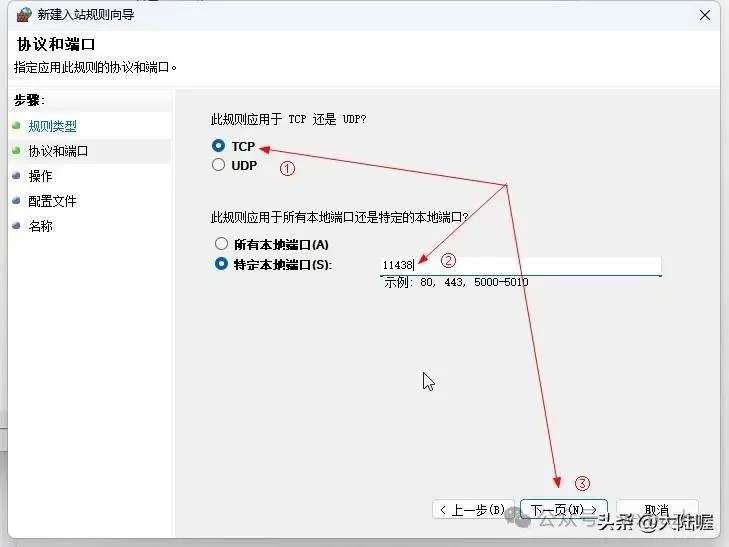
选择允许链接,然后点 下一页:
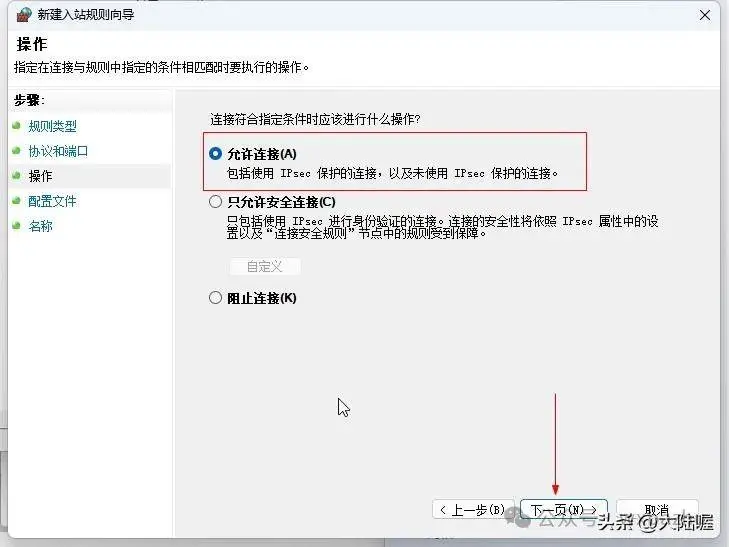
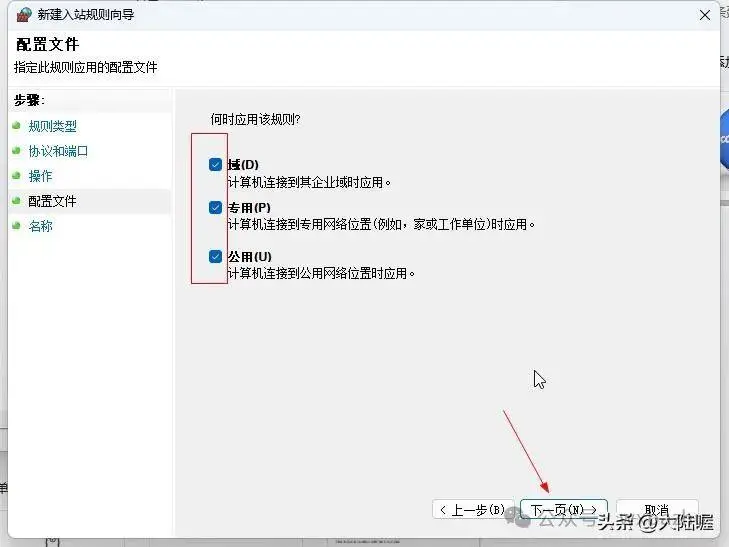
然后弹出来的对话框中把“域、专用、共用”前面的对勾都选上,点“下一页”继续,下图所示:
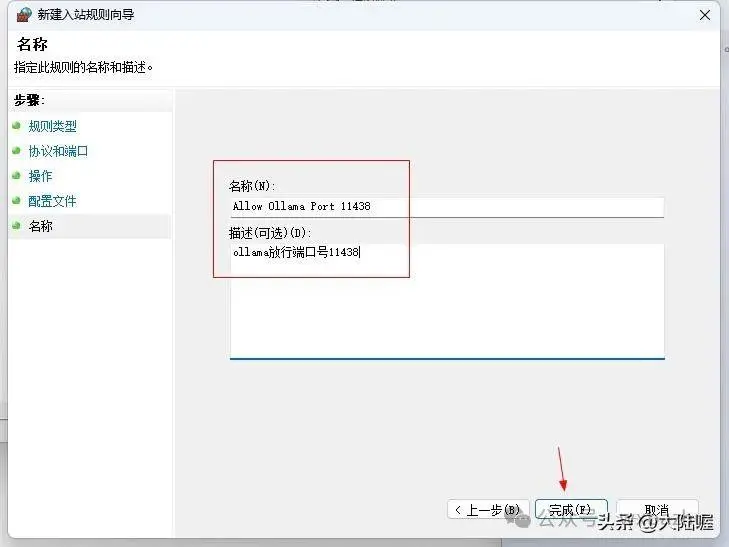
到此,关于ollama的所有配置就全部完成了,由于前面没有重启电脑,所以先重启电脑使配置的环境变量生效。
重启电脑之后,默认ollama是跟随系统自动启动的,在电脑的右下角可以看到ollama羊驼小图标,如下图所示,如果没有启动,可以在开始菜单中启动ollama。
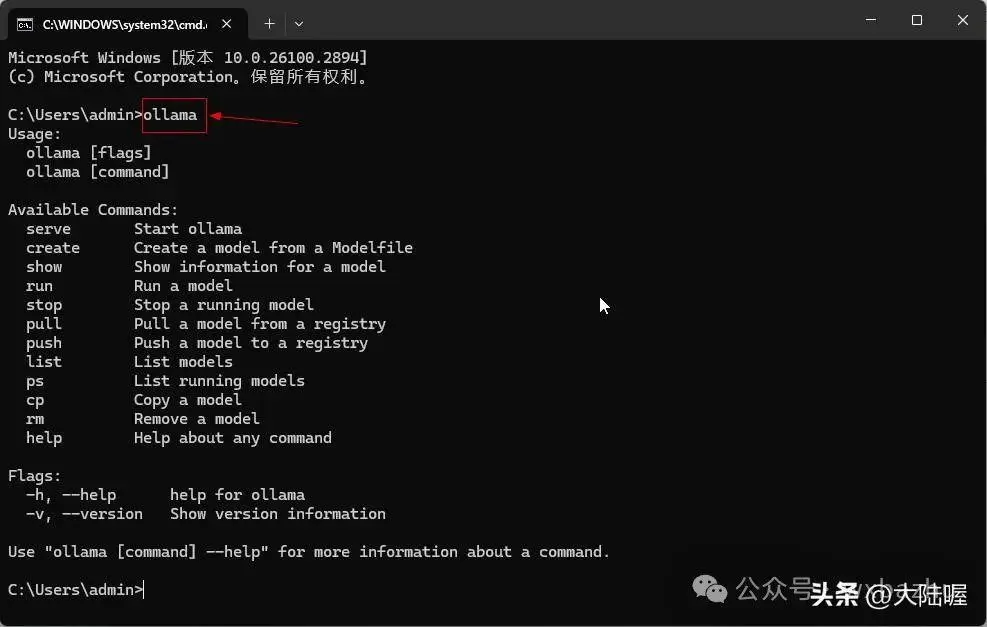
确认ollama已经启动,我们打开命令提示符,使用win键+R键输入 “cmd”打开命令提示符,下图所示,输入“ollama”然后回车,如果有下图所示的返回信息,就表示ollama没有问题了。
localhost访问
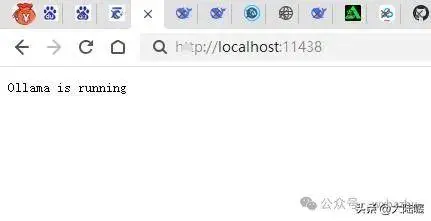
127本地IP访问
到此,ollama的全部安装配置就完成了,如还有其他问题可以留言评论。