0719代码调试记录
文章目录
- 工程介绍
- 一开始的方案
- 查找bug
- 问题1
- 问题2
- 问题3
工程介绍
今年3、4月参加了CVPR Workshop,赛道是XGC AI-Generated Video Assessment,主要考虑到实验室最近一年一直在做这方面的工作,参赛结果也还可以。我们的方案具体的可以去看我们的论文,代码也一并开源了。这两天觉得之前比赛的时候很多疑问没有完全解决好,比如对LLM结构的理解、每个token对结果的贡献度等等,再往后就是探索一下LLM在VQA任务中有没有一些比较有意思的实验性结论。于是这两天就开始在想怎么做一些可视化的实验,可以先直观地看出每个token的贡献度。
一开始的方案
项目里的LLM采用的是LLaMA2 7B,我看很多教程上说Hugging Face的transformer封装的模型可以直接通过设置output_attentions=True让outputs中返回每一层attention权重,于是我就直接做了修改
outputs = self.llm_model(inputs_embeds=inputs_embeds,attention_mask=attention_mask,output_attentions=True,output_hidden_states=True,·
)
但是返回的attentions全部都是None!
查找bug
既然如此其实就无非以下几个问题:
- LLaMA2不支持返回
attentions。 output_attentions参数没有正确传递到forward里。- attention计算的时候没有保存权重。
问题1
查看了一下hugging face里的LLaMA2的说明文档,确实是有返回attentions的,因此肯定是可以返回注意力权重的。
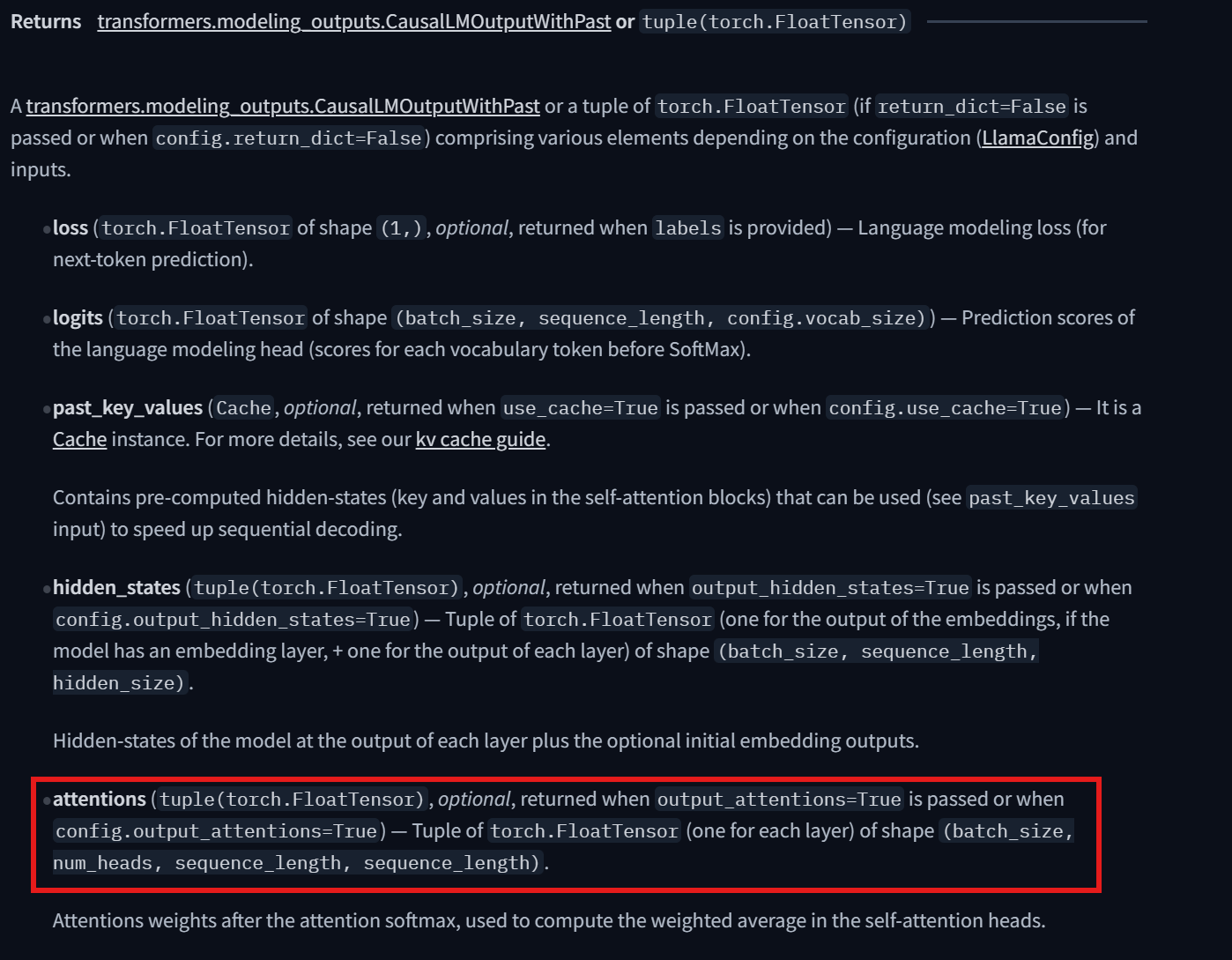
问题2
通过断点调试的方法,在LlamaForCausalLM的forward函数中查看output_attentions是否正确传入:
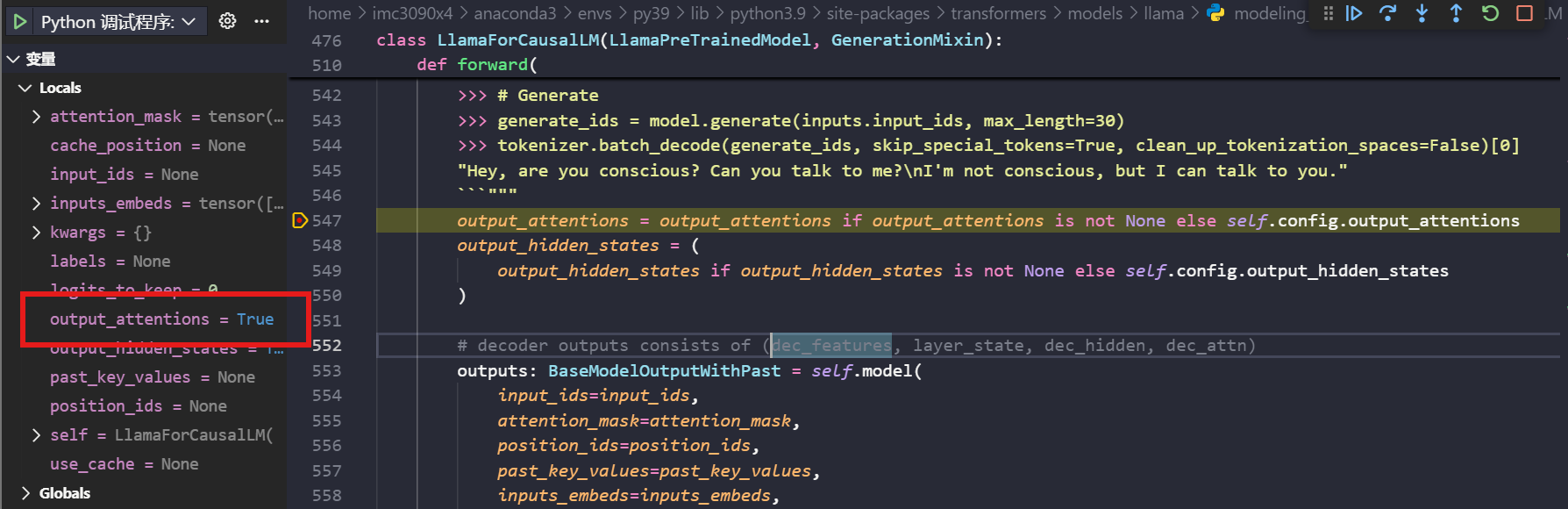
事实上确实传入了,那就只有第三种可能了。
问题3
Attention的计算是在LlamaAttention中,如下所示:

这里一开哦是调用的是eager方法,但是我们发现:
self.config._attn_implementation = sdpa
经查询后发现,sdpa和eager是两种注意力计算方法。如果采用sdpa计算,是无法返回注意力权重矩阵的,其采用了 FlashAttention 这样的底层实现,通过分块(Tiling)计算,完全避免了实例化和存储完整的注意力分数矩阵,从而极大节省了显存。但是Eager注意力计算方法需要存储中间结果。
因此,一个很简单的解决方案就是,把注意力计算方法直接换成eager就可以:

如此,我们就可以在主函数中获得attention矩阵!