FLASH:GPU 集群全连接通信的近最优极速调度
在高性能计算与分布式机器学习领域,全连接通信(All-to-All Communication)如同集群系统的"血液循环系统",其效率直接决定着大规模计算任务的成败。当GPU集群规模突破百卡级别时,传统调度算法如同拥堵的城市交通系统,"数据堵车"现象频发——这正是FLASH算法试图破解的难题。这篇由卡内基梅隆大学与MangoBoost联合发布的研究,以极具颠覆性的分层调度思想,重新定义了GPU集群中全连接通信的性能边界。

一、问题溯源:数据洪流中的"交通拥堵"

想象这样一个场景:32块GPU同时需要向其他所有GPU发送数据,如同32辆卡车同时驶入单车道隧道——这就是All-to-All通信中典型的"incast"问题。
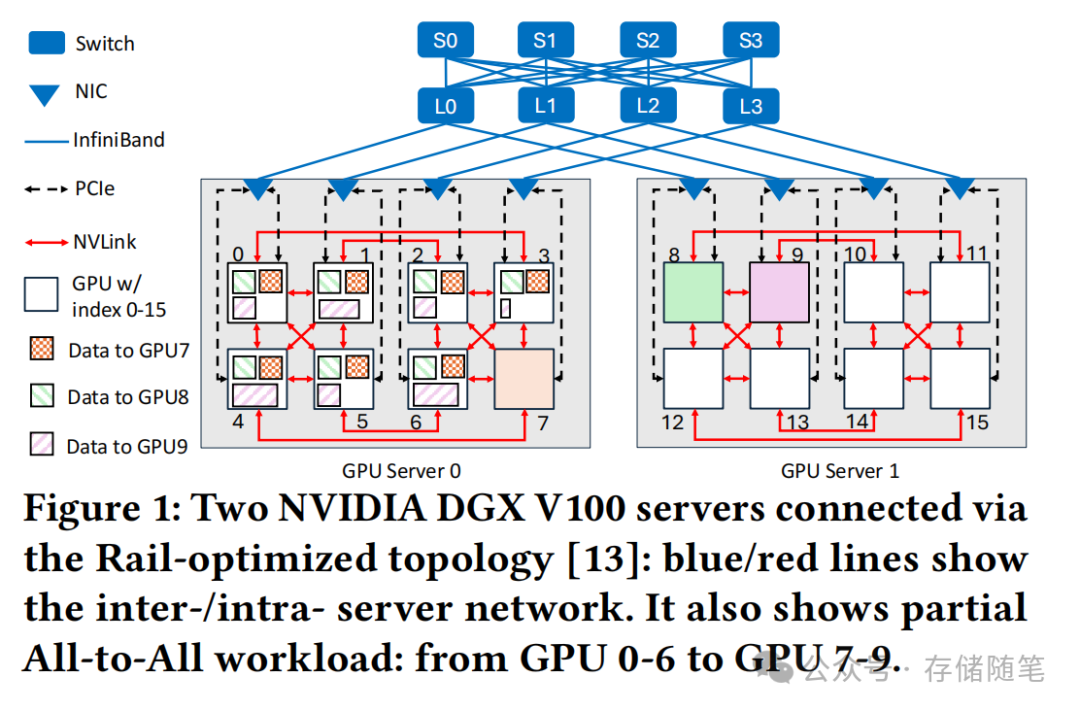
传统FanOut算法放任所有GPU同时传输,结果如同隧道内百车齐发,最终因缓冲区溢出导致大面积"数据丢包"事故。实验数据显示,当每GPU传输量超过500MB时,FanOut的算法带宽(AlgoBW)会暴跌至理论值的1/10,丢包率飙升至25%以上。
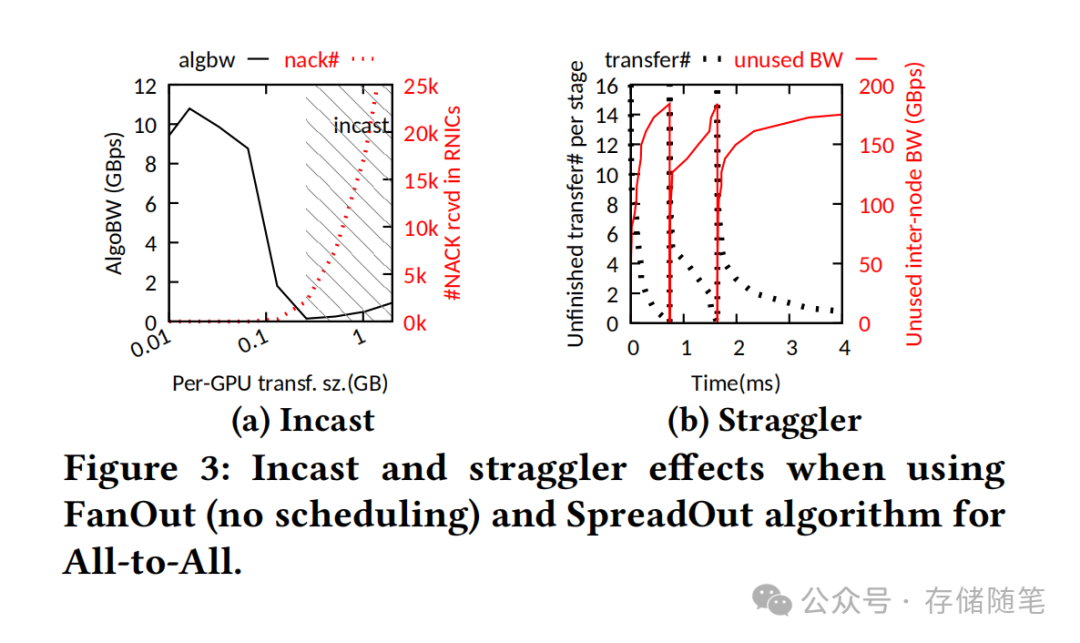
更棘手的是"stragglers"现象——少数大流量传输如同高速公路上的慢车,拖累整个车队的行进速度。在GPU集群中,这种现象因网络异构性被放大:NVLink intra-server网络带宽达1200Gbps,而Ethernet inter-server网络仅400Gbps,相同数据量的传输完成时间可能相差3个数量级。
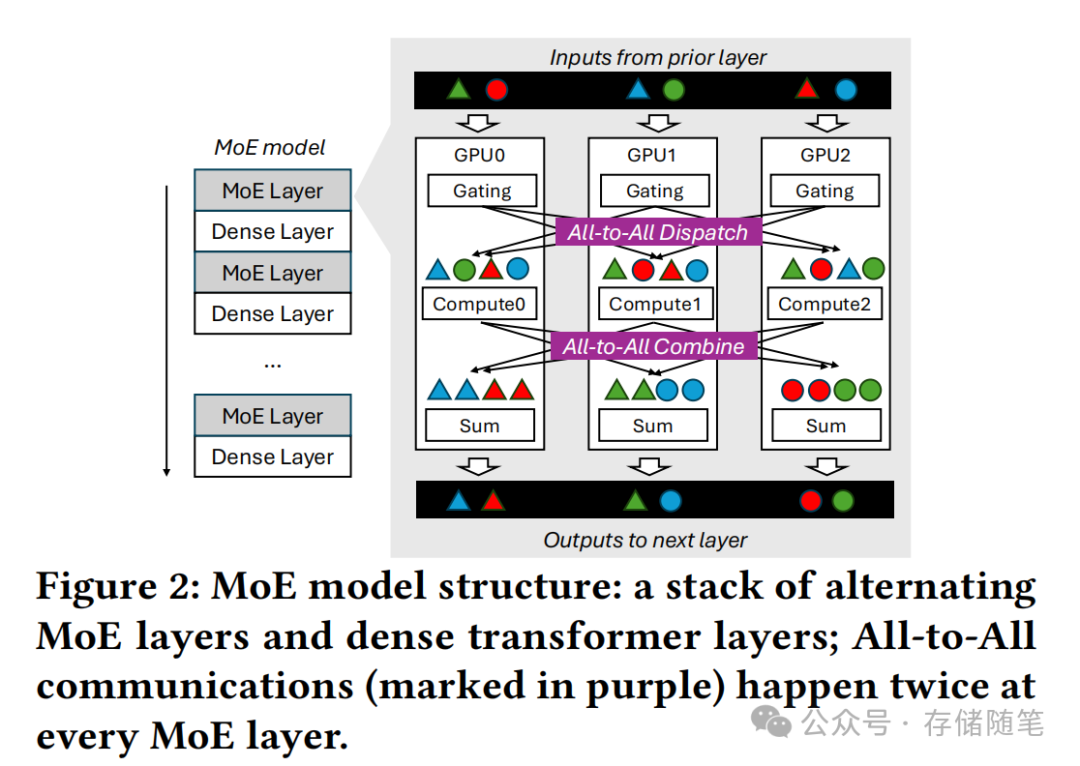
Megatron-LM的实测数据显示,MoE模型训练中90%分位的流量大小是中位数的12.5倍,这种天然的负载不均衡让传统调度算法捉襟见肘。
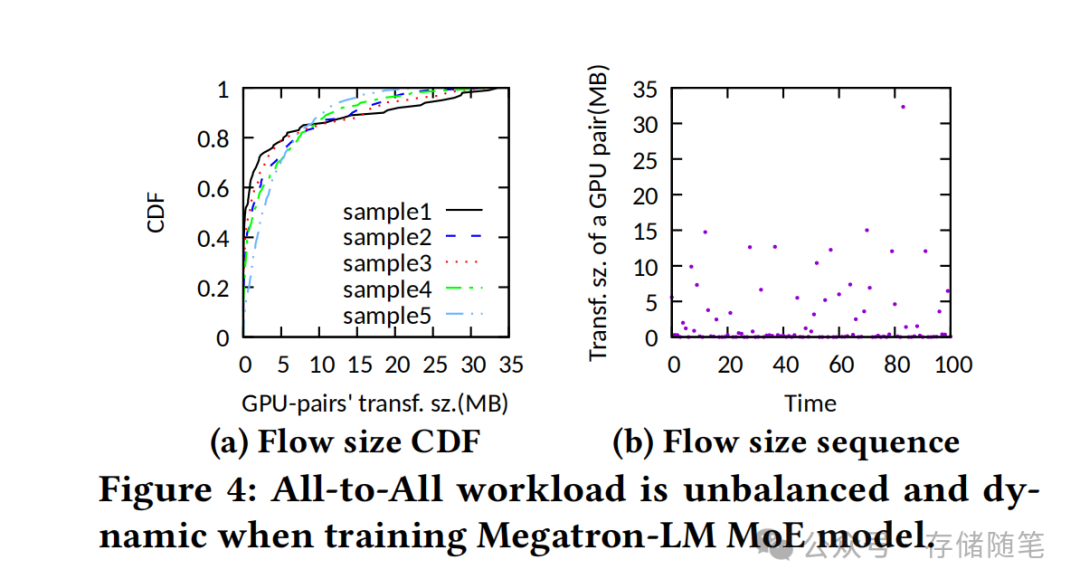
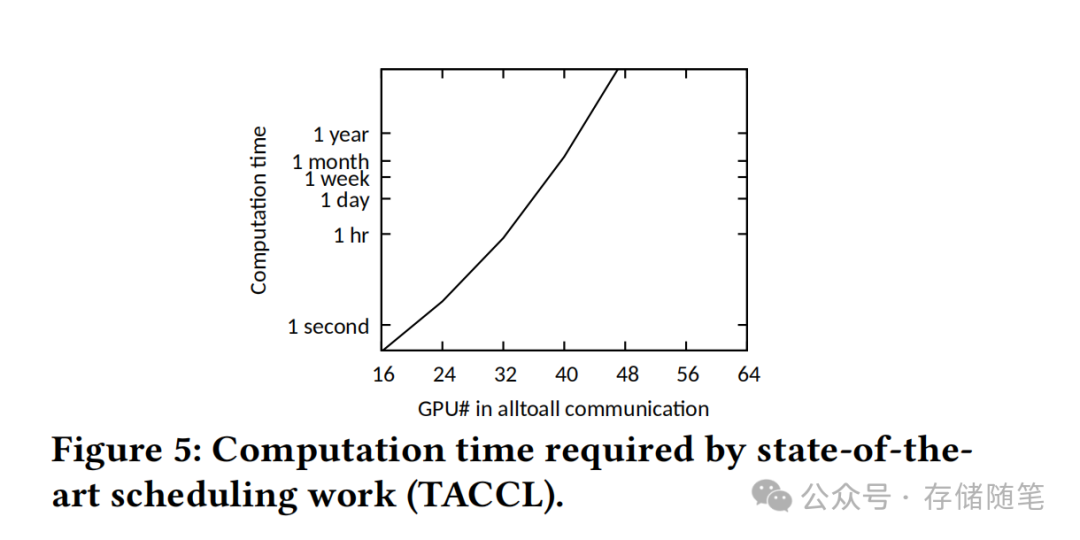
现有解决方案陷入两难困境:SpreadOut算法通过阶段化传输避免incast,但面对stragglers时网络利用率低于30%;TACCL等优化算法虽能接近理论最优,但计算一个调度方案需要数小时甚至数天——当数据传输本身仅需毫秒级时,这种"用卡车运信封"的开销显然不可接受。
二、FLASH架构:分层调度的"立体交通网络"
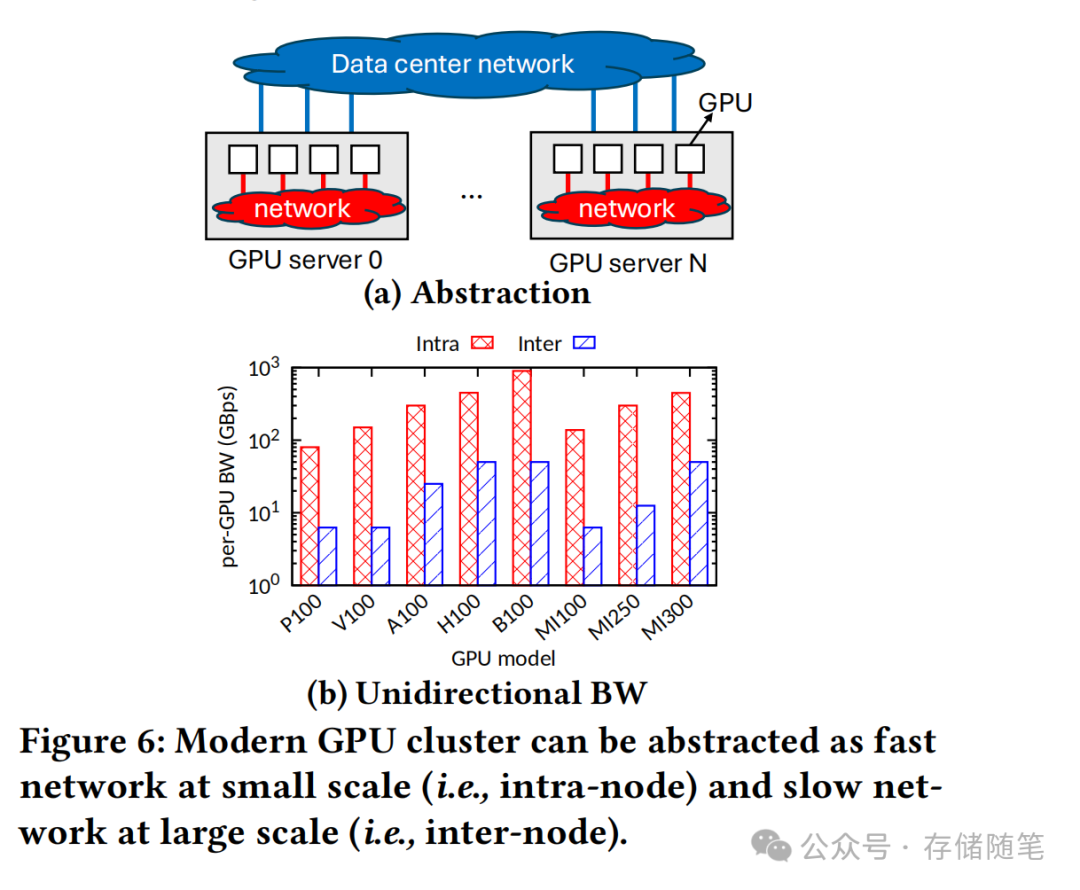
FLASH的核心创新在于将GPU集群抽象为"高速公路+城市路网"的分层模型:inter-server网络是决定整体效率的"高速公路",而intra-server网络则是灵活调度的"城市支路"。这种抽象打破了传统算法对网络同构性的假设,让数据传输如同智能导航系统般动态优化路径。
2.1 两阶段调度:负载平衡的"数据预处理"
以2服务器场景为例,传统SpreadOut算法需要2阶段完成传输,但因流量不均衡导致阶段2中30%的带宽闲置。FLASH则引入3阶段流程: