【数据结构】栈(stack)
目录
一、栈的定义
二、顺序栈(sequential stack)
1. 顺序表的存储结构定义
2. 顺序栈的实现(动态)
(1)初始化
(2)判空操作
(3)入栈
(4)出栈
(5)取栈顶元素
(6)栈的销毁
三、链栈(linked stack)
1. 链栈的存储结构定义
2. 链栈的实现
(1)初始化
(2)判空操作
(3)入栈
(4)出栈
(5)取栈顶元素
(6)链栈的销毁
四、总结
一、栈的定义
栈(stack)是 限定仅在表的一端进行插入和删除操作的线性表。允许插入和删除的一端称为栈顶,另一端称为栈底,不含任何数据元素的栈称为空栈。
栈的插入操作,又称为入栈、进栈、压栈。
栈的删除操作,又称为出栈、弹栈。
它们都只能在栈顶进行操作。所以栈具有后进先出(last in first out)的特性。
栈的示意图:
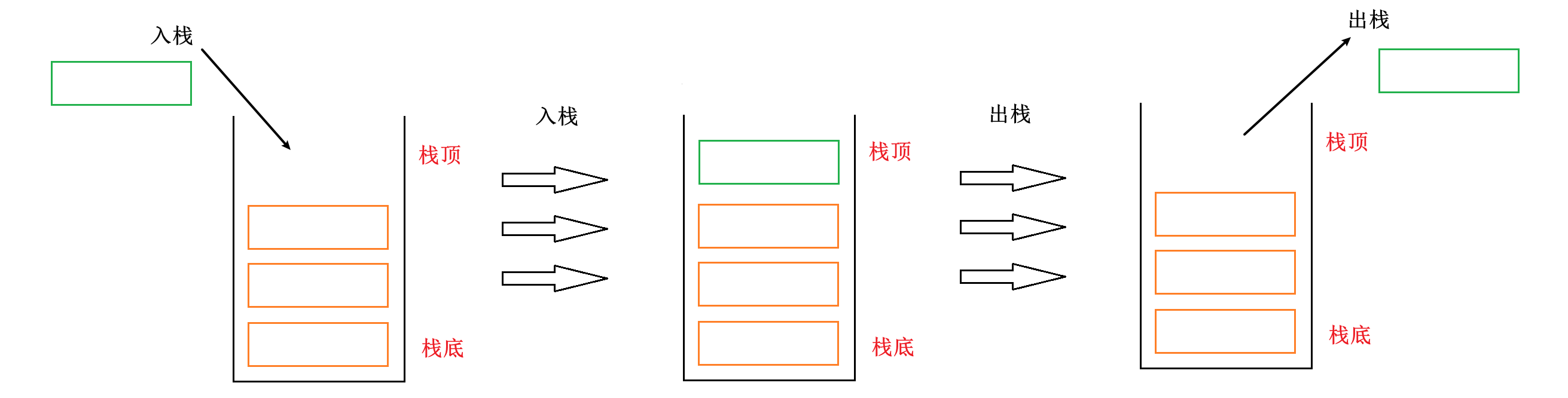
入栈与出栈操作就像一叠落在一起的盘子,想要从这叠盘子中取出或放入一个盘子,只有在其顶部操作才最方便。
栈在存储结构上可以分为两种:顺序栈(顺序存储)和 链栈(链接存储)。顺序栈是用数组实现,链栈常用链表实现。相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。
二、顺序栈(sequential stack)
1. 顺序表的存储结构定义
顺序栈(sequential stack)是栈的顺序存储结构。顺序栈本质上是顺序表的简化,当然也分为静态栈和动态栈。顺序栈是通过数组存储数据的,在数组中,把下标为0的一端作为栈底,同时设置变量top指示栈顶元素在数组中的位置。入栈则 top 加 1,出栈则 top 减 1。
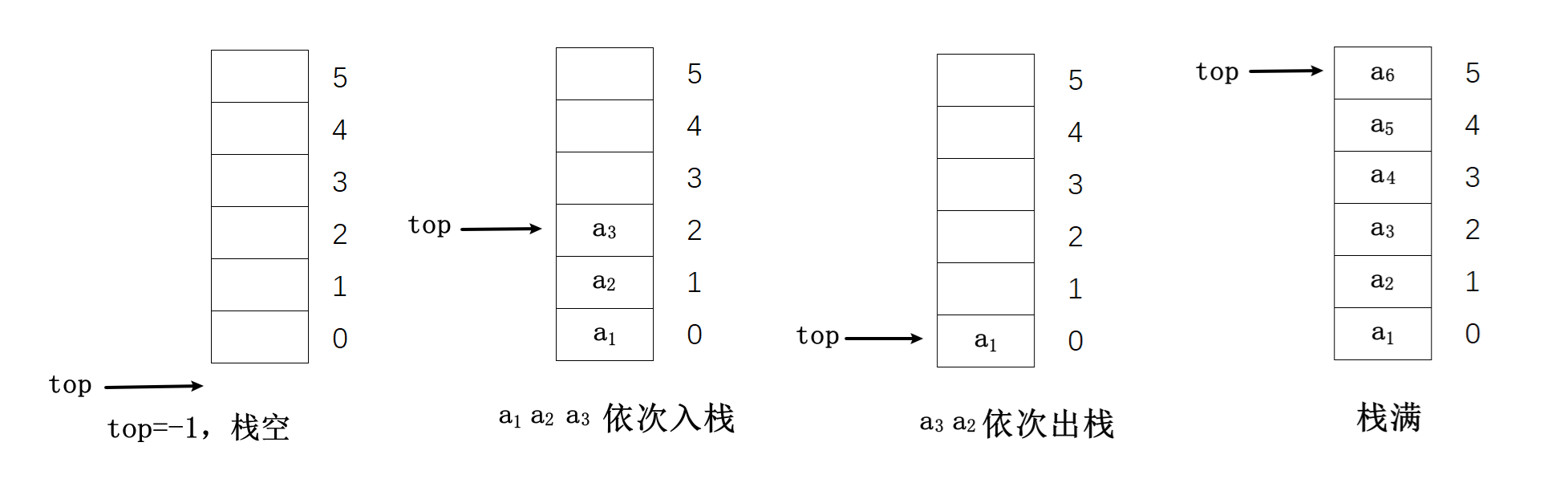
则顺序栈的存储结构定义为:
/*-------------------------静态栈------------------------------*/
#define StackSize 100
typedef int DataType;
typedef struct Stack
{DataType data[StackSize];int top;
}Stack;
/*--------------------------动态栈-----------------------------*/
typedef int DataType;
typedef struct Stack
{DataType* a;int top;int capicity;//容量
}Stack;在我们实际应用时,静态的顺序栈在实际中一般不实用,所以下面要实现的是动态的顺序栈。
2. 顺序栈的实现(动态)
动态顺序栈的实现个动态顺序表的实现很类似,只是栈规定了插入和删除的位置。
(1)初始化
在主函数中创建一个结构体变量,将它的地址传递到初始化函数中,再对它的成员进行初始化。
其中,需要注意的是,这里的top可以初始化为-1,也可以初始化为0,但它们表示的意义是不同的,在后续其他操作的代码中也会有差异。初始化为-1,表示的是top指的是栈顶元素,初始化为0,表示的是栈顶元素的下一个元素。
下面一初始化为-1为例,则C语言实现如下:
//初始化
void Init(Stack* ps)
{assert(ps);ps->a = (DataType*)malloc(sizeof(DataType) * 4);if (ps->a == NULL){printf("malloc fail");return;}ps->capicity = 4;//将初始容量设为4ps->top = -1;
}(2)判空操作
判空只需要判断指向栈顶的top是否指向-1,若尾-1,则栈空。如果栈空则为真,返回true;若非空,则为假,返回false。C语言实现如下:
//判空
bool IsEmpty(Stack* ps)
{assert(ps);return ps->top == -1;
}(3)入栈
在栈顶位置插入元素,由于是动态的栈,所以栈满时,就需要扩容。C语言实现如下:
//入栈
void Push(Stack* ps, DataType x)
{assert(ps);if (ps->top == ps->capicity - 1){//栈满则扩容DataType* tmp = (DataType*)realloc(ps->a, sizeof(DataType) * ps->capicity * 2);if (tmp == NULL){printf("relloc fail");return;}ps->a = tmp;ps->capicity *= 2;}ps->top++;ps->a[ps->top] = x;
}(4)出栈
只需将top减一就可以了,而数组的元素值不需要考虑。C语言实现如下:
//出栈
void Pop(Stack* ps)
{assert(ps);assert(!IsEmpty(ps));ps->top--;
}(5)取栈顶元素
若为空,则不能返回,就断言;若不为空,则返回栈顶元素的值。C语言实现如下:
//取栈顶
DataType GetTop(Stack* ps)
{assert(ps);assert(!IsEmpty(ps));return ps->a[ps->top];
}(6)栈的销毁
将在初始化时开辟了的空间释放,并将结构体其余元素改变。C语言实现如下:
//销毁
void Destroy(Stack* ps)
{assert(ps);free(ps->a);ps->a = NULL;ps->capicity = 0;ps->top = -1;
}三、链栈(linked stack)
1. 链栈的存储结构定义
链栈(linked stack)是栈的链接存储结构。通常是用单链表来表示的。由于只能在栈顶进行插入和删除操作,所以将单链表的头部作为栈顶是最为方便的。下面是一个不带哨兵头结点的单链表实现的栈,而top指向栈顶元素,如图所示:
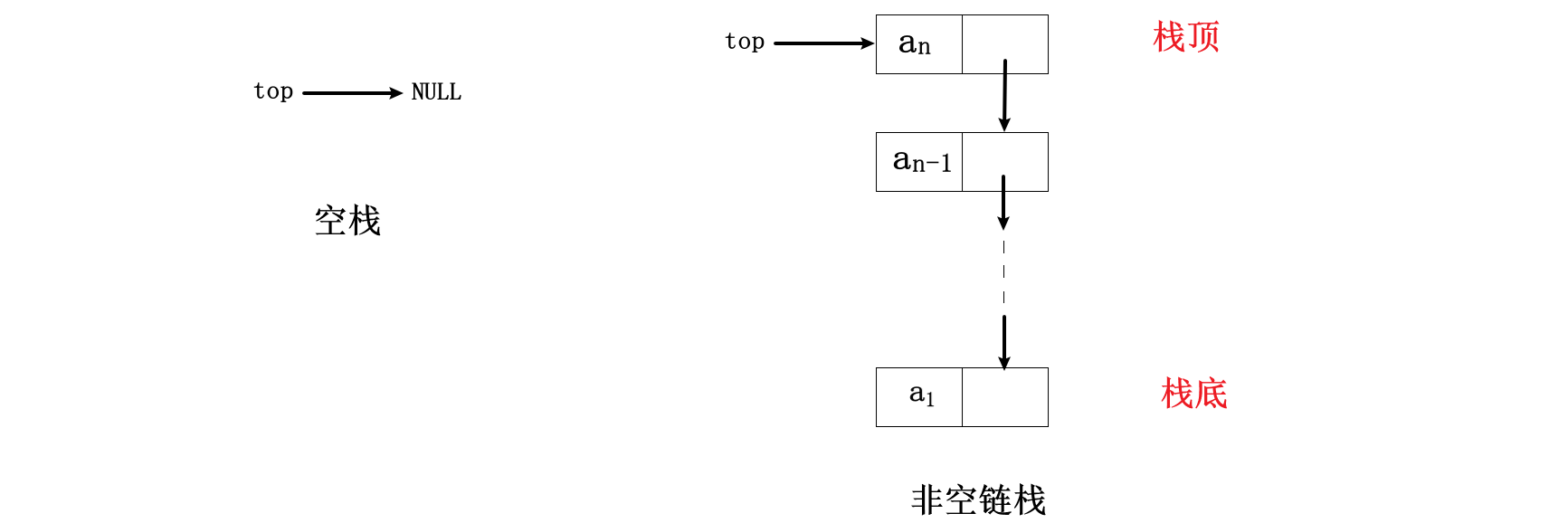
则链栈的存储结构定义为:
typedef int DataType;
typedef struct Stack
{DataType data;struct Stack* next;
}StackNode;2. 链栈的实现
链栈的操作和单链表类似。
(1)初始化
对于一个不带哨兵头结点的单链表的初始化,只需要在主函数定义一个空指针就行了。
如果这样做的话,后续在进行插入和删除时,就必需要传递二级指针,因为这两个操作(在某些情况下)可能需要对头指针进行修改。为保持统一性,以下内容皆是传递二级指针。
C语言实现如下:
StackNode* top = NULL;(2)判空操作
判断头指针是否为空。若为空,则链栈就空。C语言实现如下:
//判空
bool IsEmpty(StackNode** ptop)
{assert(*ptop);return *ptop == NULL;
}(3)入栈
入栈即在单链表中头插数据。C语言实现如下:
//入栈
void Push(StackNode** ptop, DataType x)
{assert(ptop);StackNode* newNode = (StackNode*)malloc(sizeof(StackNode));if (newNode == NULL){printf("malloc fail\n");return;}newNode->data = x;newNode->next = *ptop;*ptop = newNode;
}(4)出栈
出栈比顺序栈更加复杂些,因为链栈需要将栈顶的结点空间释放掉才能完成出栈。C语言实现如下:
//出栈
void Pop(StackNode** ptop)
{assert(ptop);assert(!IsEmpty(ptop));//出栈一定不能为空栈//删除头结点StackNode* head = *ptop;*ptop = (*ptop)->next;free(head);head = NULL;
}(5)取栈顶元素
若栈空则无法返回栈顶元素,就需要对栈空断言。C语言实现如下:
//取栈顶
DataType GetTop(StackNode** ptop)
{assert(ptop);assert(!IsEmpty(ptop));//取栈顶一定不能为空栈return (*ptop)->data;
}(6)链栈的销毁
和单链表一样,都需要依次释放每一个结点的存储空间。C语言实现如下:
//销毁
void Destroy(StackNode** ptop)
{StackNode* cur = *ptop;while (cur != NULL){StackNode* next = cur->next;free(cur);cur = next;}
}四、总结
总的来说,栈的实现都比较简单,它没有顺序表和单链表那样复杂。因为限定了仅在表的一段进行插入和删除操作的规定,所以栈是一种具有后进先出(last in first out)操作特性的线性表。其中对比顺序栈和链栈,在大多数情况下,很明显动态顺序栈实现的栈结构更优,比如:在出栈时,链栈需要释放空间,而顺序栈则就不会。
比较:
时间性能:顺序栈和链栈及基本算法的时间复杂度均为O(1)。
空间性能:对于静态顺序栈,在初始化时必须先确定一个固定的长度,所以有存储数据个数的限制和存储空间的的浪费。虽然动态顺序栈优化了这一点,当扩容是也有时会产生空间的浪费。对于链栈,没有栈满的问题,只有当内存没有可用空间是才会出现栈满,但每个元素都需要一个指针域,从而会产生结构性开销。
所以,当栈使用的数据个数变化较大时,应该采用链栈,反之,则应该采用顺序栈
- 在此感谢各位的阅读!