RLHF(基于人类反馈的强化学习),DPO(直接偏好优化), GRPO(组相对偏好优化)技术概述
一、RLHF(基于人类反馈的强化学习)概述
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) 是一种让AI模型对齐人类价值观和意图的关键技术。它通过将人类偏好转化为强化学习的奖励信号,指导模型生成更安全、有用、符合期望的输出。
1.1 为什么需要RLHF?
SFT的局限性
-
监督微调(SFT)依赖静态的“输入-输出”数据,无法覆盖开放场景。
-
模型可能生成无害但无用(如“我不确定”)、有用但不安全(如提供危险建议)或偏离人类偏好的回答。
目标差异:语言模型的预训练目标是预测下一个token(概率最大化),而人类需要的是安全、真实、有帮助的对话。
💡 核心矛盾:模型的目标函数与人类期望的行为之间存在鸿沟。
RLHF的使命:将人类偏好注入模型优化过程,弥合这一鸿沟。
1.2 RLHF 技术框架(三阶段流程)

阶段1:监督微调(SFT)
-
输入:预训练基础模型(如LLaMA、GPT)。
-
过程:在高质量指令-回答数据集上微调,使模型初步学会遵循指令。
-
输出:SFT模型(后续流程的起点)。
阶段2:奖励模型训练(Reward Modeling, RM)
-
目标:构建一个能量化回答质量的“人类偏好评判器”。
-
关键步骤:
-
数据收集:对同一提示(prompt),让SFT模型生成4-9个不同回答。然后进行人工标注:让标注员对这些回答按质量排序(如A > B > C)。
-
模型构建:
-
使用对比学习框架(如Bradley-Terry模型)。
-
输入:提示
x+ 回答y -
输出:标量奖励值
r(x,y)
-
-
损失函数(Pairwise Ranking Loss):
强制高质量回答
y_win的奖励 > 低质量回答y_lose的奖励。
-
-
输出:奖励模型(RM),可自动评估回答是否符合人类偏好。
🔍 奖励模型特点:
参数量通常小于SFT模型(如6B RM配13B SFT)
训练数据量:约10万-100万条排序样本
阶段3:强化学习微调(PPO)
-
目标:用RM的奖励信号优化SFT模型,使其生成高奖励回答。
-
框架:近端策略优化(Proximal Policy Optimization, PPO)
-
关键组件:
组件 角色 策略模型 待优化的SFT模型(参数θ) 奖励模型 提供奖励信号 r(x,y)参考模型 固定参数的SFT模型(防偏离) 价值模型 估计状态价值(可选) -
优化目标函数:
-
:RM对回答
y的奖励评分 -
:当前策略与参考策略的KL散度(防过度偏离原始能力)
-
:KL惩罚系数(典型值:0.1-0.2)
-
-
训练流程:
-
对每个提示
x,策略模型生成回答y。 -
RM计算奖励
r(x,y)。 -
计算KL惩罚项。
-
用PPO算法更新策略模型参数θ。
-
1.3 RLHF 的核心技术挑战
1. 奖励黑客(Reward Hacking)
-
问题:模型通过欺骗RM获取高奖励(如生成冗长但空洞的回答)。
-
解法:KL散度约束(锚定参考模型);多维度奖励模型(分别评估安全性、有用性等)
2. 人类标注偏差
-
问题:标注员偏好不一致;文化/认知偏差被植入RM。
-
解法:多标注员投票 + 模糊样本剔除;对抗性提示检测(Adversarial Prompting)
3. 训练不稳定性
-
问题:PPO超参数敏感,易发散。
-
解法:自适应KL系数(如
β随训练动态调整);混合监督微调(定期用SFT数据“校准”模型)
1.4 RLHF vs. 替代方案
| 技术 | 所需资源 | 优势 | 局限 |
|---|---|---|---|
| RLHF | 大量人工标注 + 高算力 | 行为控制精准,对齐效果好 | 实现复杂,成本极高 |
| DPO | 偏好数据 + 中等算力 | 无需RM训练,简化流程 | 对参考模型质量敏感 |
| RLAIF | AI反馈(替代人工) + 高算力 | 可扩展性强,降低成本 | AI反馈质量依赖基础模型 |
二、DPO(直接偏好优化) 概述
DPO(Direct Preference Optimization,直接偏好优化) 技术是一种替代 RLHF(基于人类反馈的强化学习) 来微调和对齐大语言模型的新兴、高效方法。理解 DPO 的核心在于认识到它要解决的问题以及它如何巧妙地绕过了传统 RLHF 的复杂性。
2.1 背景:RLHF 的痛点
在介绍 DPO 之前,回顾一下它要替代的 RLHF 流程很重要:
-
监督微调: 在高质量指令-响应对数据集上微调基础模型,得到 SFT 模型。关于什么是SFT,请参考:大模型微调(Fine-tuning)技术综述-CSDN博客
 https://blog.csdn.net/qq_54708219/article/details/149268823?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_54708219/article/details/149268823?spm=1001.2014.3001.5502 -
奖励模型训练:首先,收集人类对模型生成结果(通常是成对的输出
x,偏好响应的奖励分数应高于非偏好响应)。 -
强化学习微调:使用训练好的奖励模型
RM作为奖励信号。利用强化学习算法(最常用的是 PPO - Proximal Policy Optimization)来优化 SFT 模型。这一步的目标是: 最大化从 RM 获得的期望奖励,同时通过 KL 散度惩罚确保微调后的模型不会偏离原始 SFT 模型太远(防止模型“胡说八道”或过度优化奖励模型的弱点)。
根据以上内容,总结出RLHF 的主要痛点:
1.复杂性高: RL(尤其是 PPO)本身就是一个复杂且难以稳定训练的领域。它涉及多个组件(策略网络、价值网络、奖励模型)、超参数敏感、需要精心设计的技巧来稳定训练。
2.计算成本高: RL 训练过程通常需要大量的采样(模型生成)和多次模型前向/反向传播,计算开销巨大。
3.不稳定: PPO 训练可能不稳定,容易崩溃或陷入局部最优,导致结果不可预测。
4.奖励模型瓶颈: RLHF 的性能高度依赖于奖励模型的质量和鲁棒性。如果 RM 有缺陷(如易被“欺骗”、不能泛化、有偏见),RL 优化的模型也会继承这些缺陷,甚至更糟(过度优化)。
而DPO就是一种优雅的替代方案。DPO 的核心思想非常巧妙:它绕过了显式训练奖励模型和复杂的强化学习过程,直接将人类偏好数据转化为一个简单的、仅使用监督学习(SFT风格)的目标函数来优化语言模型本身。
2.2 DPO 的核心原理
-
理论基础 - Bradley-Terry 模型: DPO 假设人类偏好数据的生成遵循 Bradley-Terry 模型。该模型认为,给定一对响应
x,人类选择
其中:-
是 sigmoid 函数 (
)。
-
-
-
关键洞察 - 奖励即策略: DPO 论文做出了一个关键的数学洞察:在最优 RLHF 解中(即通过 RL 优化得到的最终策略模型
和最优奖励函数
通过以下关系紧密相连:
其中:-
是参考策略(通常是 SFT 模型)。
-
β是一个控制偏离参考策略程度的超参数(类似于 RLHF 中的 KL 惩罚强度)。 -
Z(x)是一个只依赖于提示x的配分函数(归一化项)。
-
-
从奖励到策略的转变: 这个公式意味着,最优策略
-
构建 DPO 损失函数:
-
将上述
-
神奇的事情发生了:复杂的配分函数
Z(x)和显式的 -
最终得到的偏好概率只依赖于 待优化的策略
和 参考策略
-
DPO 损失函数: 目标就是最大化人类偏好数据(
-
2.3 DPO 的直观理解
-
目标: 损失函数的核心部分
对偏好响应
-
优化方向:
-
模型被鼓励增加生成偏好响应
-
模型被鼓励降低生成非偏好响应
-
-
KL 约束:
β参数至关重要:-
低
β: 模型可以更自由地调整策略以适应偏好数据,但也可能过度偏离参考模型(SFT),导致不可控或“胡说八道”。 -
高
β: 模型被强烈约束在参考模型 -
这本质上实现了 RLHF 中 KL 惩罚项的作用,但以一种内嵌的方式在损失函数中完成。
-
2.4 DPO 的训练流程(对比 RLHF)
输入:
- 一个经过监督微调(SFT)的基础模型
- 一个包含提示
x和成对人类偏好响应的数据集
D。 - 超参数
β。
过程:
-
像训练一个分类器一样,使用标准梯度下降优化器(如 AdamW)。
-
对于数据集
D中的每个样本-
用当前模型
,
-
计算损失
。
-
反向传播梯度并更新模型
θ。
-
输出: 优化后的策略模型 ,其行为更符合人类偏好。
2.5 DPO 的主要优势和局限性
优势:
-
简单性: 最大的优势!完全避免了复杂的 RL 训练框架(PPO)和显式奖励模型的训练。训练过程就是一个标准的监督学习任务(带有一个特殊设计的损失函数)。
-
高效性: 计算成本显著低于 RLHF。不需要在训练过程中采样新响应,也不需要维护额外的策略网络、价值网络或奖励模型。只需要计算现有响应序列的对数概率。
-
稳定性: 训练过程通常比 RLHF/PPO 更稳定、更鲁棒。超参数调整相对简单(主要是
β)。 -
性能: 在多项基准测试和人类评估中,DPO 已被证明能够达到甚至超越 RLHF 的性能,同时训练更简单更快。
-
隐式奖励建模: 模型
局限性与挑战:
-
对参考模型的依赖: DPO 的性能依赖于初始 SFT 模型
-
对偏好数据质量的敏感: 和 RLHF 一样,DPO 高度依赖偏好数据的质量、一致性和覆盖范围。噪声大或有偏见的偏好数据会导致模型学到错误的偏好。
-
处理复杂/多轮偏好: 标准的 DPO 处理的是单轮提示下的成对偏好。处理多轮对话中的复杂偏好或绝对评分(而非相对比较)可能需要扩展。
-
离线训练: DPO 是离线算法,使用静态的偏好数据集进行训练。它不像在线 RL 那样可以在训练过程中主动探索和收集新数据(尽管可以结合迭代数据收集策略)。
-
“赢家通吃”风险: DPO 损失强烈鼓励模型将概率质量从
。如果偏好数据集中某个
更好),或者存在多个合理响应,DPO 可能会过度抑制其他合理的响应模式。
2.6 总结
DPO(Direct Preference Optimization)是一种革命性的技术,用于直接使用人类偏好数据来微调和对齐大语言模型。
-
核心创新: 它通过数学推导,揭示了在最优解中策略和奖励函数的内在联系,从而能够将最大化人类偏好似然的目标,转化为一个仅依赖于待优化策略和参考策略的简单监督损失函数。
-
核心优势: 简单、高效、稳定。它完全绕过了显式奖励模型训练和复杂的强化学习(如 PPO),大大降低了训练的计算成本和工程复杂度。
-
核心目标: 通过优化损失函数
,模型学习调整其生成概率分布,使其相对于参考模型更倾向于生成人类偏好的响应,同时抑制非偏好响应,并通过参数
β控制偏离参考模型的程度。 -
意义: DPO 已成为 RLHF 的有力替代品,显著推动了开源社区和工业界在高效、高性能语言模型对齐方面的进展。它使得训练出更符合人类意图和价值观的聊天助手、指令跟随模型等变得更加可行。
简而言之,DPO 提供了一条更直接、更高效的路径,让语言模型学会“什么才是人类更喜欢的回答”。
| 特性 | RLHF | DPO |
|---|---|---|
| 核心方法 | 强化学习 (RL - 通常用 PPO) | 监督学习 (带特殊损失函数) |
| 关键组件 | 奖励模型 (RM) + 策略模型 + 价值模型 (可选) | 待优化策略模型 + 固定的参考策略模型 (SFT) |
| 训练流程 | 复杂:RM 训练 + RL 微调 (在线采样/训练) | 简单:单阶段监督微调 (离线) |
| 计算成本 | 高 (需采样、多模型、RL 迭代) | 低 (只需计算响应概率,标准梯度下降) |
| 稳定性 | 较低 (PPO 调参敏感,易崩溃) | 较高 (更类似 SFT,更鲁棒) |
| 显式 RM | 需要 训练和维护单独的 RM | 不需要 (偏好信息内嵌在策略优化中) |
| 理论基础 | 强化学习理论 | Bradley-Terry 模型 + 策略-奖励对偶性 |
| 主要优势 | 理论上可在线交互收集数据 | 简单、高效、稳定、易于实现 |
| 主要挑战 | 工程复杂、成本高、不稳定、RM 瓶颈 | 依赖参考模型质量、偏好数据质量敏感、离线学习 |
| 代表应用 | ChatGPT (早期版本), Claude, InstructGPT | Zephyr-7B, Mistral Instruct, 众多开源微调模型 |
三、GRPO(组相对偏好优化)概述
GRPO(Group Relative Preference Optimization,组相对偏好优化) 是一种新兴的大语言模型对齐技术,可视为 DPO(Direct Preference Optimization)的增强变体。它通过引入组内对比学习和显式KL约束,显著提升了偏好学习的稳定性和效果。
3.1 GRPO 诞生的背景
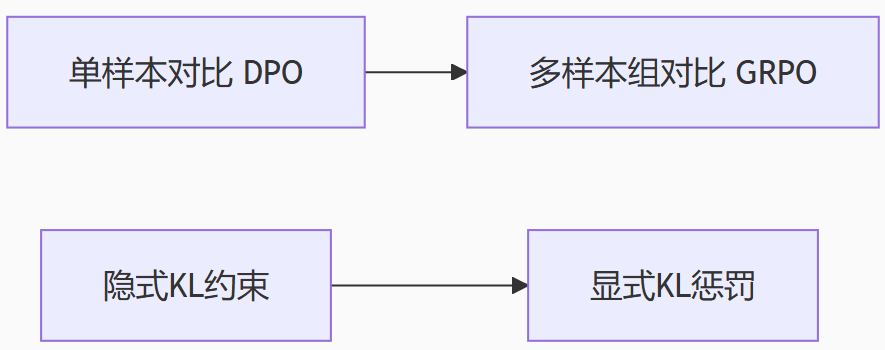
DPO 的局限性:
-
单样本敏感:DPO 使用单对样本
-
隐式KL约束:DPO 的KL散度约束通过参考模型实现,控制力不足,可能导致模型偏离基础能力。
-
偏好建模粗糙:无法建模多回答间的细粒度排序关系(如
GRPO 的突破:
3.2 GRPO 核心原理
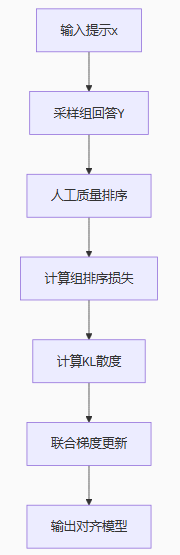
1. 组偏好构建(Group Preference)
-
输入:
-
提示
x -
组回答:
(含1个正向样本 +
k-1个负向样本)
-
-
排序关系:人工标注组内回答的质量排序(如
)
-
优势:单提示下建模多级质量差异,抗噪能力更强。
2. 损失函数设计
GRPO 损失函数融合两个关键部分:
-
组排序损失(GroupRank Loss):
-
其中:
(隐含奖励函数)
-
实质:强制高质量回答的奖励分数 > 低质量回答(组内对比)。
-
-
显式KL惩罚:
-
添加显式KL散度项
,直接约束策略模型偏离参考模型的程度。
-
系数
-
3. 训练流程
3.3 GRPO 的技术优势
1. 稳定性提升
| 指标 | DPO | GRPO |
|---|---|---|
| 训练波动 | 高(单样本噪声敏感) | 低(组平均抑制噪声) |
| KL控制 | 隐式/间接 | 显式/直接 |
| 灾难性遗忘 | 易发生 | 显著缓解 |
2. 数据效率优化
-
组内信息复用:单组数据包含
C(k,2)个偏好对(如k=4→ 6对关系) -
减少标注需求:同等数据量下,GRPO 比 DPO 收敛快 ≈30%(论文实证)。
3. 细粒度对齐能力
-
可建模多级偏好(如
),避免DPO的二值化信息损失。
-
支持部分排序(Partial Ordering):允许组内存在质量等价样本。
3.4 GRPO vs. 主流对齐方法
| 方法 | 训练目标 | 数据需求 | 稳定性 | 计算开销 |
|---|---|---|---|---|
| RLHF | 奖励最大化 + KL约束 | 极高(需RM训练) | 中 | 极高 |
| DPO | 偏好对概率排名 | 中等 | 低 | 低 |
| CPO | 条件偏好优化 | 中等 | 中 | 中 |
| GRPO | 组排序 + 显式KL | 低 | 高 | 中低 |
💡 适用场景:
GRPO 在小规模高质量数据集上表现最佳(医疗/法律等专业领域)
DPO 更适合大规模通用偏好数据
RLHF 仍是计算资源充足时的黄金标准
3.5 GRPO 的局限性
-
组标注成本:需人工对组内样本排序,标注效率低于二值偏好(DPO)。
-
超参数敏感:
k需精细调参(建议网格搜索\in [0.1,0.3], k \in {4,5,6})。 -
长文本挑战:组内长文本比较对奖励建模提出更高要求。
3.6 总结
GRPO 通过“组对比学习+显式KL约束”双机制,实现了更稳定、更高效的偏好对齐:
-
技术本质:
-
组排序损失 → 提升抗噪性和细粒度理解
-
显式KL项 → 锚定模型基础能力,防止过偏离
-
-
适用场景:高价值领域(医疗/金融/法律);小规模高质量偏好数据
-
未来方向:半自动组构建(LLM辅助排序);多目标GRPO(同时优化安全性/有用性/简洁性)