顺理成章学RL-1(based Stanford CS234 Reinforcement Learning)
顺理成章学RL(based Stanford CS234 Reinforcement Learning)
感觉目前学习资源都很全面,但是一直没有自己喜欢的一个逻辑(很清晰的结构)总结RL 的知识点和学习路径。因此在学习CS234 的过程中,记录笔记和思考如下。希望给大家帮助🎉。
(本文中的练习题感觉数学含量太高,建议初学者可以跳过)
lecture 1 Introduction to Reinforcement Learning
这一章节主要来介绍为什么使用RL , 以及RL是什么的问题, 并且如何使用RL(based on what envs)
- 什么是RL
- 哪些场景必须用RL
- RL 和有监督学习,无监督学习的区别
- how? 过程中有什么挑战
什么是RL?
通过经验(通常从环境中交互获取)的方式来进行下一步(未来几步)决策(最大化某种累积奖励)的过程。
哪些场景必须用RL?
某种需要奖励 (我们无法直接找到标签,但是可以得到隐变量的某种reward的时候)的场景。
区别?
在监督学习(Supervised Learning)中,我们通常拥有一个数据集,其中包含了样本和标签。在监督学习的场景下,我们会被提供一个训练集,每个样本都附有正确的标签(分类问题)或正确的输出(回归问题)。相比之下,当数据集中没有标签时,无监督学习(Unsupervised Learning)指的是那些在没有为每个样本提供标签的情况下,试图发现数据中潜在结构的方法。
由于奖励信号只提供了弱和不完整的反馈,我们可以认为强化学习处于监督学习(有强反馈和标签数据)与无监督学习(没有反馈和标签)之间的某个位置
how? 过程中有什么挑战
-
我们已经知道,在进行最优策略探索的时,我们通常需要权衡 新的尝试和 基于经验的选择。这本质上是一个决策的哲学问题。
朴素的思考:
- 经验和探索之间应该存在某种权重 – 通过离线的学习可以学得这种权重
-
离线学习后,该权重在完全未知场景下的泛化性能如何?
- 这需要我们重新思考权重的定义 – 使用更复杂的策略去学习权重 – 而不是固定的值。(RL for weight based RL)
-
上面的思考依然道出RL 的本质,无论是面对无限大状态空间时,将有限采样作为离线学习的过程;还是在将问题描述为短期奖励和长期奖励的平衡,其依然在选择经验和探索之间的某个 best point
使用数学的方式定义问题:
动作和决策相关的数学定义:
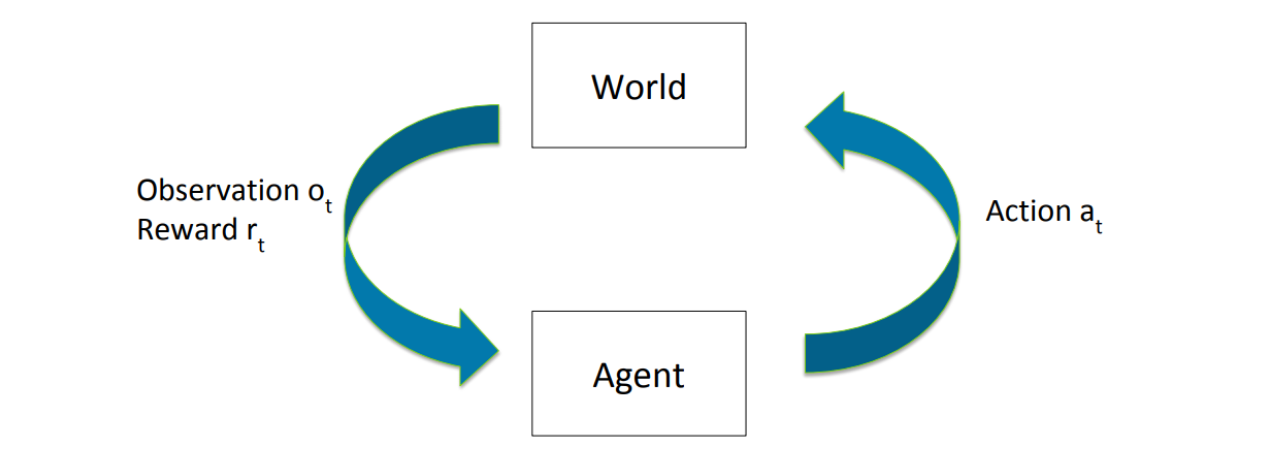
an agent will make sequence of actions {at}, observe a sequence of observations {ot} and receive a sequence of rewards {rt}. We define the history at time t to be ht = (a1, o1, r1, …, at, ot, rt).The agent’s choice of what action to take next can be viewed as a function of the history, that is, at+1 = f (ht)
(在某些确定性且有限的环境下,像A*搜索和极大极小(minimax)等人工智能技术可以用来找到最优的动作序列)
对世界的数学定义:
设 SSS 为我们世界可能处于的所有状态的集合,{st}\{s_t\}{st} 表示按时间索引的一系列观测到的状态,AAA 是所有可能动作的集合。我们通常希望考虑世界的转移动态 P(st+1∣st,at,...,s1,a1)P(s_{t+1}|s_t, a_t, ..., s_1, a_1)P(st+1∣st,at,...,s1,a1),这是一个在 SSS 上的概率分布,并且是前面一系列状态和动作的函数。
在强化学习中,我们通常假设马尔可夫性质(Markov Property)成立,即P(st+1∣st,at,...,s1,a1)=P(st+1∣st,at),P(s_{t+1}|s_t, a_t, ..., s_1, a_1) = P(s_{t+1}|s_t, a_t),P(st+1∣st,at,...,s1,a1)=P(st+1∣st,at),
这个假设在实际中已经足够灵活满足我们的需求。一个确保马尔可夫性质成立的有用技巧是将历史 hth_tht 作为我们的状态。
通常,我们认为奖励 rtr_trt 是在状态转移 st→atst+1s_t \xrightarrow{a_t} s_{t+1}statst+1 时获得的。奖励函数用于预测奖励,R(s,a,s′)=E[rt∣st=s,at=a,st+1=s′]R(s, a, s') = E[r_t|s_t = s, a_t = a, s_{t+1} = s']R(s,a,s′)=E[rt∣st=s,at=a,st+1=s′]。我们常常将奖励函数简化为以下形式之一:R(s)=E[rt∣st=s]R(s) = E[r_t|s_t = s]R(s)=E[rt∣st=s] 或 R(s,a)=E[rt∣st=s,at=a]R(s, a) = E[r_t|s_t = s, a_t = a]R(s,a)=E[rt∣st=s,at=a]。在很多情况下,rt∣st=sr_t|s_t = srt∣st=s 是退化(degenerate)的,即在已知 st=ss_t = sst=s 时,rtr_trt 只有一个固定值。
一个“模型”由上述的转移动态和奖励函数共同组成。
强化学习智能体的组成部分(数学定义):
首先,令智能体状态(agent state)为历史的一个函数,sta=g(ht)s_{ta} = g(h_t)sta=g(ht)。一个强化学习智能体通常会显式地表示以下三者之一或多个:策略(policy)、价值函数(value function)以及(可选的)模型(model)。
策略 π\piπ 是从智能体状态到动作的映射,π(sta)∈A\pi(s_{ta}) \in Aπ(sta)∈A;有时,策略也表示为对动作的一个随机分布 π(at∣sta)\pi(a_t|s_{ta})π(at∣sta)。当智能体想要采取一个动作且 π\piπ 是随机的时,它以概率 P(at=a)=π(a∣sta)P(a_t = a) = \pi(a|s_{ta})P(at=a)=π(a∣sta) 选择动作 a∈Aa \in Aa∈A。
给定策略 π\piπ 和折扣因子 γ∈[0,1]\gamma \in [0, 1]γ∈[0,1],价值函数 VπV^\piVπ 表示期望的折扣累计奖励之和:Vπ(s)=Eπ[rt+γrt+1+γ2rt+2+…∣st=s].V^\pi(s) = E_\pi[r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \ldots | s_t = s].Vπ(s)=Eπ[rt+γrt+1+γ2rt+2+…∣st=s].
这里的 EπE_\piEπ 表示期望是基于遵循策略 π\piπ 所遇到的状态计算的,折扣因子 γ\gammaγ 用来权衡即时奖励和延迟奖励。
最后,强化学习智能体还可能拥有一个模型,其定义见 2.2 节。如果智能体拥有模型,我们称之为基于模型(model-based)智能体;如果没有使用模型,则称为无模型(model-free)智能体。
(扩展:到目前为止,我们所讨论的定义都非常通用,并没有对 oto_tot 和 sts_tst 之间的关系做出任何假设。当 ot≠sto_t \neq s_tot=st 时,我们称之为部分可观测(partially observable)。在部分可观测的情况下,RL 算法通常会维护一个关于真实世界状态的概率分布来定义 stas_{ta}sta,这被称为信念状态(belief state)。
不过,在大多数情况下,我们会考虑完全可观测(fully observable)的情形,即 ot=sto_t = s_tot=st,并假设 sta=sts_{ta} = s_tsta=st。)
扩展-强化学习智能体的分类
我们可以用多种方式对智能体进行分类,如表1所示,而且每种类型的智能体并不一定是唯一的。例如,actor-critic(演员-评论家)智能体也可以是无模型(model-free)智能体。关于智能体分类的方法,也可以在图2中看到一个概览。
| 智能体类型 | 策略 | 价值函数 | 模型 |
|---|---|---|---|
| 基于价值(Value Based) | 隐式 | √ | ? |
| 基于策略(Policy Based) | √ | × | ? |
| Actor Critic | √ | √ | ? |
| 基于模型(Model Based) | ? | ? | √ |
| 无模型(Model Free) | ? | ? | × |
表1:不同类型强化学习智能体属性概览。表中的对号表示该智能体拥有该组件,叉号表示该智能体不能拥有该组件,问号表示该组件可有可无,不是必须的。至于这些模型具体的含义我们放到后面的内容
扩展 -连续域
为简单起见,我们的讨论仅聚焦于离散的状态空间、动作空间以及离散的时间步长。然而,在很多应用场景中,尤其是机器人学和控制领域,用连续的状态空间、动作空间以及连续时间来建模是最为合适的。上述讨论可推广到这些连续情形中 。
这里简单提一下,目前(25-7)很多Robot 都基于扩散模型和流匹配来进行动作连续化输出,目的就是丝滑。
References
[1] Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529-533.
[2] Pfau, David, and Oriol Vinyals. “Connecting generative adversarial networks and actor-critic methods.” arXiv preprint arXiv:1610.01945 (2016).
[3] Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” Nature 529.7587 (2016): 484-489.
[4] Silver, David. “Reinforcement Learning.” 15 Jan. 2016. Reinforcement Learning, UCL.