Magenta RT 正式开源!实时生成多种风格音乐,让创作无门槛
非音乐生可以做出自己的原创歌曲嘛?
当然可以!音乐就位,灯光就位,现在迎面向我们走来的是,Google 团队和它发布的开源音乐生成模型 Magenta RT。Google 团队这次又会给大家带来什么惊喜呢?
作为一款专为实时音乐生成设计的开源 AI 模型,Magenta RT 首先展示了其优秀的创作能力。
(因音频文件格式限制,这里无法展示,生成音乐详情可到https://go.openbayes.com/wWRcx查看~)
Magenta RT 不仅能够实时生成音乐,还可以根据用户提供的动态风格提示即时调整音乐风格,填补了生成模型与人类参与创作之间的空白。Magenta RT 支持 48 kHz 立体声音质,能够实现实时的语义控制,涵盖音乐流派、乐器选择和风格演变。生成速度达到每 2 秒音频只需要 1.25 秒,实现了接近实时的数据生成(RTF 约为 0.625)。这一突破性发布标志着 Google 在 AI 音乐创作领域的又一重要进展,为音乐创作者和开发者提供了全新的创作工具。
教程链接:https://go.openbayes.com/wWRcx
使用云平台: OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
首先点击「公共教程」,在公共教程中找到「Magenta RT: 流式音乐生成!」,单击打开。
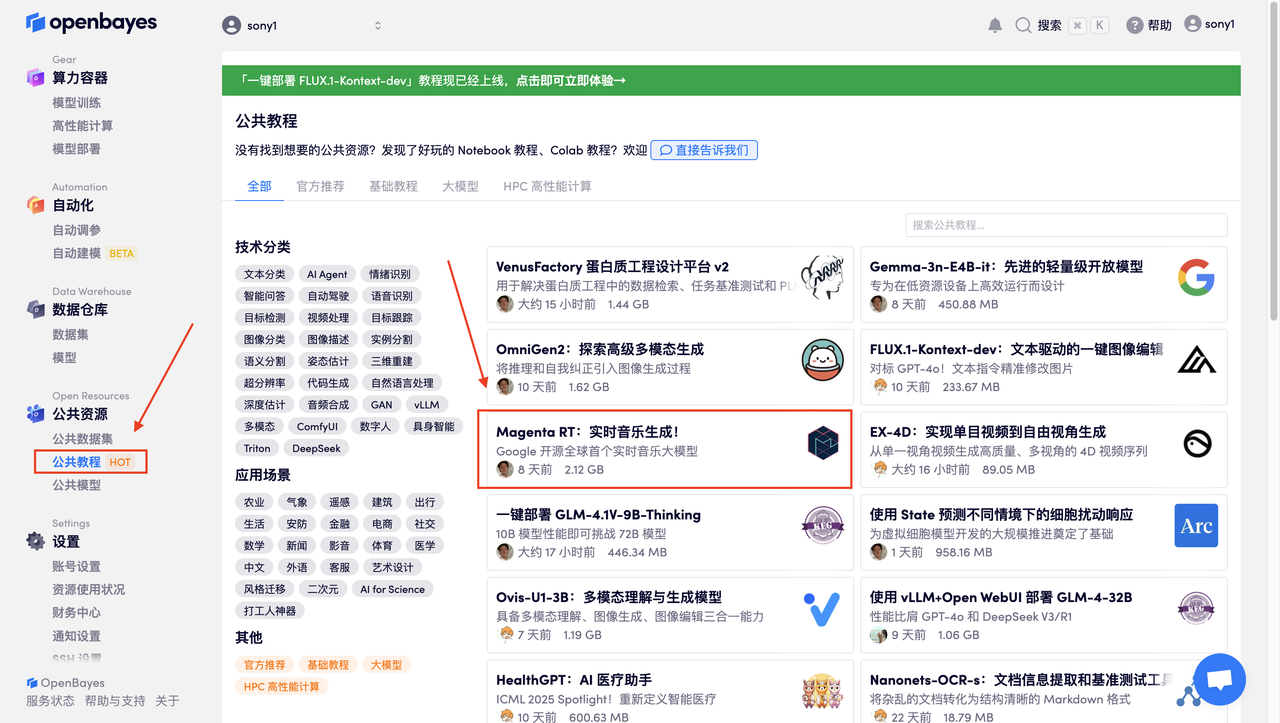
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
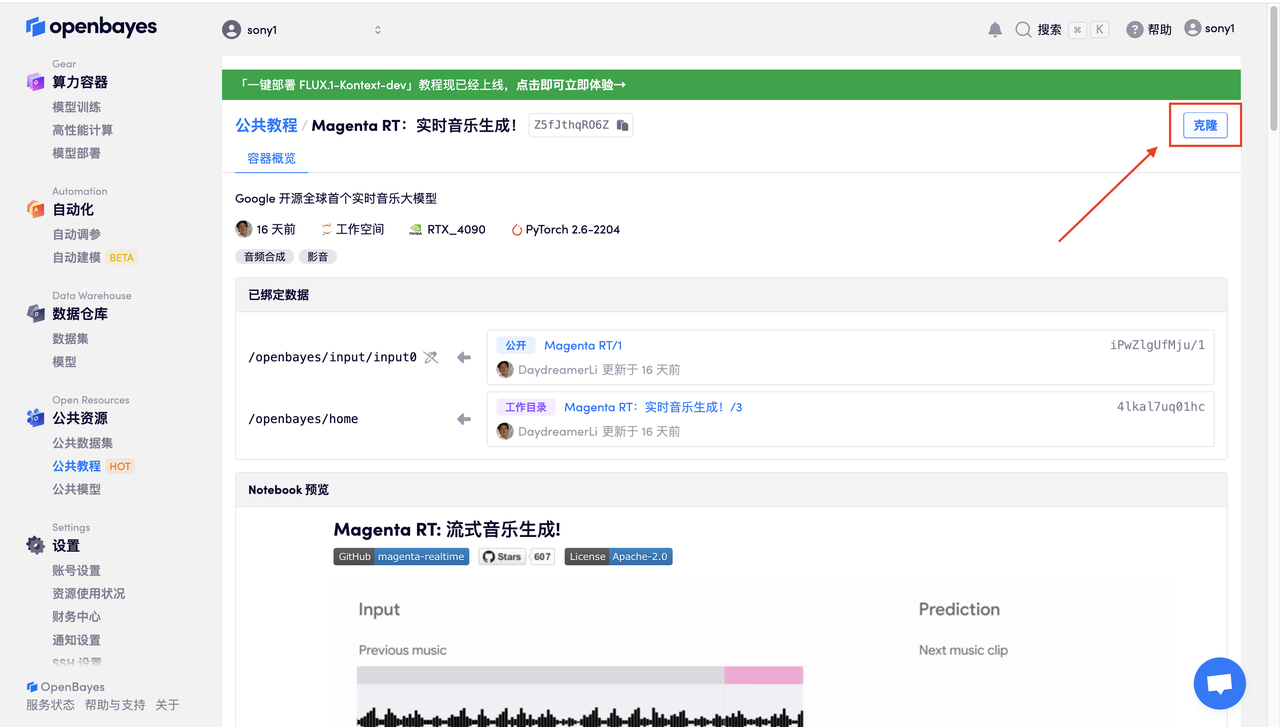
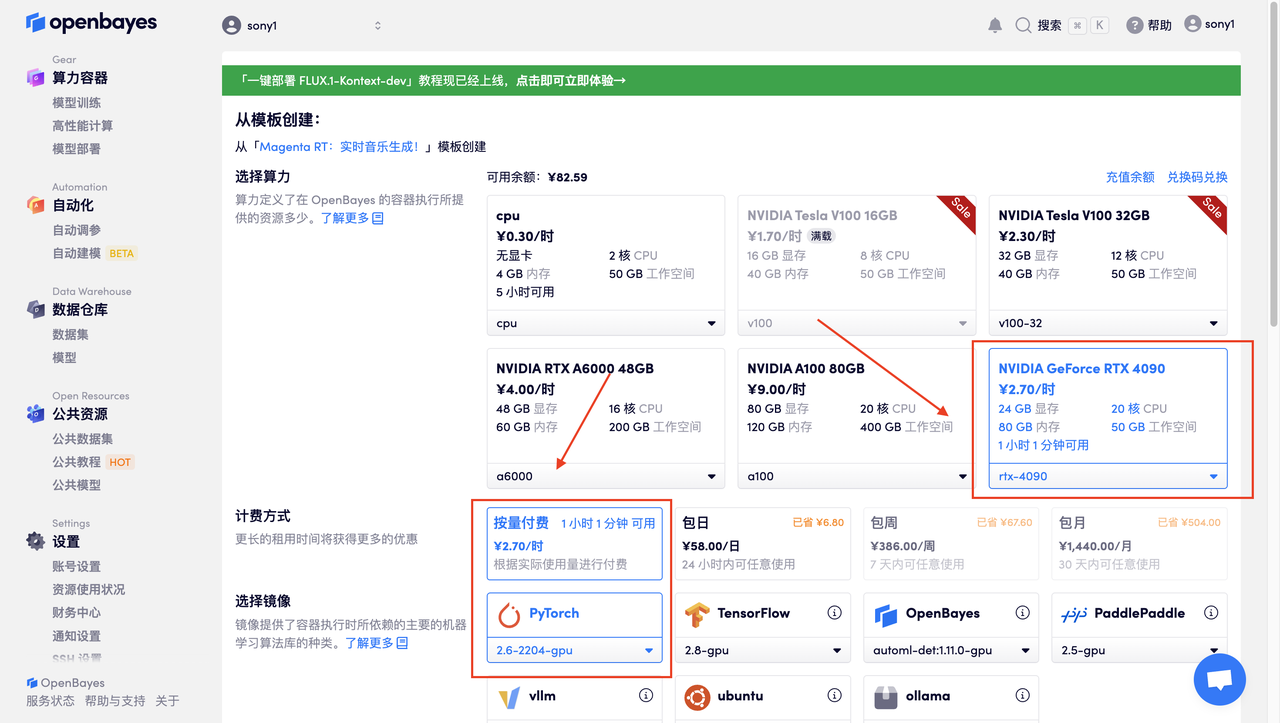
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
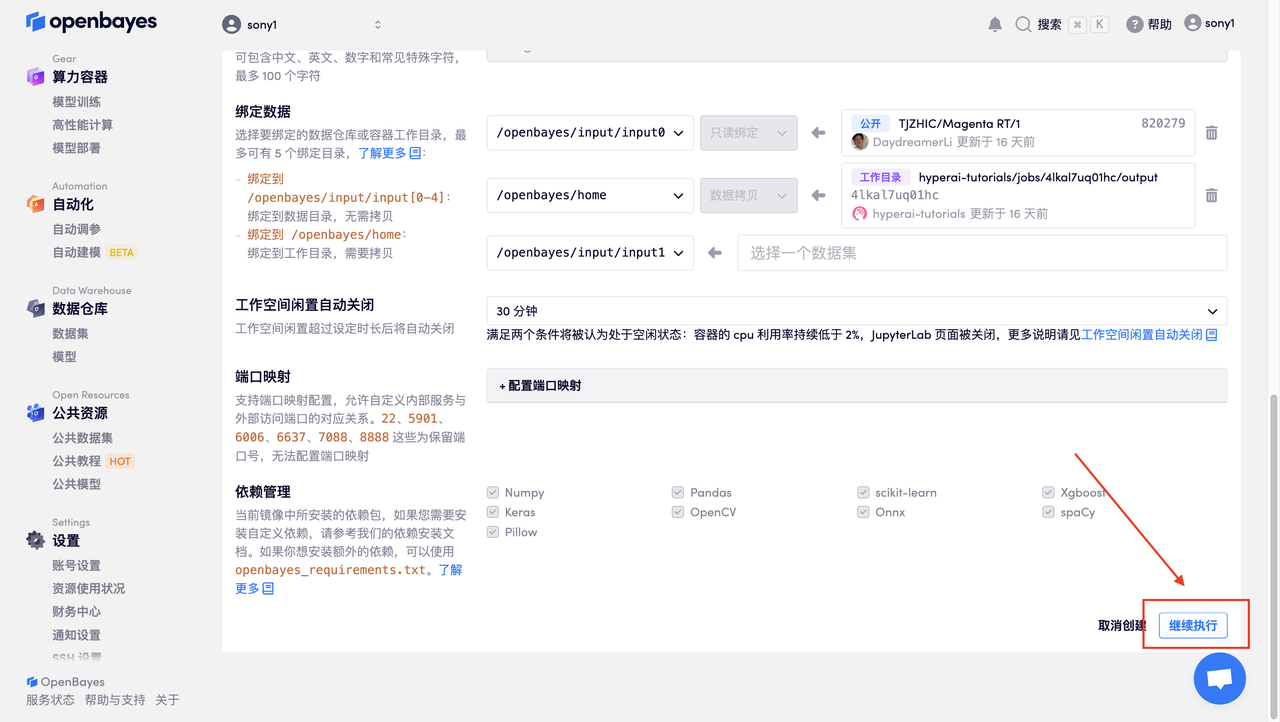
数据和代码都已经同步完成了。容器状态显示为「运行中」后,点击「 打开工作空间」,即可进入界面。
进入工作空间后,点击「README 文档」,可以看到该项目的教程简介和详细的教程示例。
教程示例
1、导入相关模块
import sys
import os
import nest_asyncio
nest_asyncio.apply()
sys.path.append('/output/magenta-realtime')
2、初始化音乐生成器
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "python"
from magenta_rt import audio, system
mrt = system.MagentaRT(checkpoint_dir='/openbayes/input/input0/magenta-realtime/checkpoints/llm_large_x3047_c1860k')
2025-07-02 06:53:36.988764: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1751439217.001395 371 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1751439217.005072 371 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1751439217.015380 371 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1751439217.015397 371 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1751439217.015398 371 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1751439217.015399 371 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
3、设置相关参数
具体参数:
- num_seconds:生成音乐的时长
- prompt:音乐风格
prompt = 'Guitar' # 在这里输入生成音乐的风格
num_seconds = 10 # 生成多少秒的音乐
from magenta_rt import system
sys = system.MockMagentaRT()
style = sys.embed_style(prompt)
4、生成音乐
from IPython.display import display, Audio
chunks = []
state = None
for i in range(round(num_seconds / mrt.config.chunk_length)):chunk, state = mrt.generate_chunk(state=state)chunks.append(chunk)
generated = audio.concatenate(chunks, crossfade_time=mrt.crossfade_length)
display(Audio(generated.samples.swapaxes(0, 1), rate=mrt.sample_rate))
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:291, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:314, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:330, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:337, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:349, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:291, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:314, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:330, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:337, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
WARNING:absl:In /openbayes/input/input0/python310/lib/python3.10/site-packages/flaxformer/architectures/t5/t5_architecture.py:349, activation_partitioning_dims was set, but it is deprecated and will be removed soon.
I0000 00:00:1751439284.552094 371 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 4118 MB memory: -> device: 0, name: NVIDIA GeForce RTX 4090, pci bus id: 0000:25:00.0, compute capability: 8.9
2025-07-02 06:56:14.534485: W external/xla/xla/tsl/framework/bfc_allocator.cc:310] Allocator (GPU_0_bfc) ran out of memory trying to allocate 130.18GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2025-07-02 06:56:14.844065: W external/xla/xla/tsl/framework/bfc_allocator.cc:310] Allocator (GPU_0_bfc) ran out of memory trying to allocate 32.52GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2025-07-02 06:56:14.910632: W external/xla/xla/tsl/framework/bfc_allocator.cc:310] Allocator (GPU_0_bfc) ran out of memory trying to allocate 32.52GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
2025-07-02 06:56:14.974383: W external/xla/xla/tsl/framework/bfc_allocator.cc:310] Allocator (GPU_0_bfc) ran out of memory trying to allocate 32.52GiB with freed_by_count=0. The caller indicates that this is not a failure, but this may mean that there could be performance gains if more memory were available.
5、混合文本和音频风格
允许使用任意数量的文本和音频提示无缝混合风格。 具体参数:
- my_audio:音频文件(mp3、wav等格式)
- prompt_style:融合风格
from magenta_rt import audio, system
import numpy as np
from IPython.display import display, Audiomy_audio = audio.Waveform.from_file('/openbayes/home/1.wav') # 这里填写待融合音频文件所在的系统路径
prompt_style = 'funk' # 这里填写待融合的风格weighted_styles = [(1.6, my_audio), # 用户音频(权重,可自行微调)(1.4, prompt_style), # 文本风格(权重,可自行微调)
]style_vectors = []
for weight, source in weighted_styles:if isinstance(source, str): style_vec = sys.embed_style(source)else: style_vec = sys.embed_style(source)style_vectors.append(style_vec)style_vectors = np.array(style_vectors)
weights = np.array([w for w, _ in weighted_styles])weights_norm = weights / weights.sum()
blended_style = (weights_norm[:, np.newaxis] * style_vectors).sum(axis=0)num_seconds = 10
chunks = []
state = Nonenum_chunks = round(num_seconds / mrt.config.chunk_length)for i in range(num_chunks):chunk, state = mrt.generate_chunk(state=state)chunks.append(chunk)generated_audio = audio.concatenate(chunks, crossfade_time=mrt.crossfade_length)display(Audio(generated_audio.samples.swapaxes(0, 1), rate=mrt.sample_rate))
6、SpectroStream 对音频进行分词
SpectroStream 是一个离散音频编解码器模型,用于处理高保真音乐音频(立体声,48kHz)。在底层,Magenta RT 模型使用语言模型对 SpectroStream 音频标记进行建模。
- naudio_path:音频文件(mp3、wav等格式)
from magenta_rt import audio, spectrostreamcodec = spectrostream.SpectroStream()
audio_path = '/openbayes/home/1.wav' # 这里填写待音频分词的音频所在系统路径
my_audio = audio.Waveform.from_file(audio_path)
my_tokens = codec.encode(my_audio)
my_audio_reconstruction = codec.decode(my_tokens)
display(Audio(my_audio_reconstruction.samples.swapaxes(0, 1), rate=mrt.sample_rate))