Kubernetes生命周期管理:深入理解 Pod 生命周期
云原生学习路线导航页(持续更新中)
- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:API Server详解(一)
- Kubernetes控制平面组件:API Server详解(二)
- Kubernetes控制平面组件:调度器Scheduler(一)
- Kubernetes控制平面组件:调度器Scheduler(二)
- Kubernetes控制平面组件:Controller Manager 之 内置Controller详解
- Kubernetes控制平面组件:Controller Manager 之 NamespaceController 全方位讲解
- Kubernetes控制平面组件:Kubelet详解(一):架构 及 API接口层介绍
- Kubernetes控制平面组件:Kubelet详解(二):核心功能层
- Kubernetes控制平面组件:Kubelet详解(三):CRI 容器运行时接口层
- Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
- Kubernetes控制平面组件:Kubelet详解(五):切换docker运行时为containerd
- Kubernetes控制平面组件:Kubelet详解(六):pod sandbox(pause)容器
- Kubernetes控制平面组件:Kubelet详解(七):容器网络接口 CNI
- Kubernetes控制平面组件:Kubelet详解(八):容器存储接口 CSI
本文是Kubernetes生命周期管理系列文章:深入理解 Pod 生命周期,主要对 Pod的状态流转、如何保证Pod的高可用做了详细介绍,包括:pod资源限制、Qos质量级别、pod的驱逐、健康检查探针、readinessGates、pod的生命周期钩子等,最后还介绍了kubernetes上部署应用的一些挑战
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.Pod状态机 及 状态流转

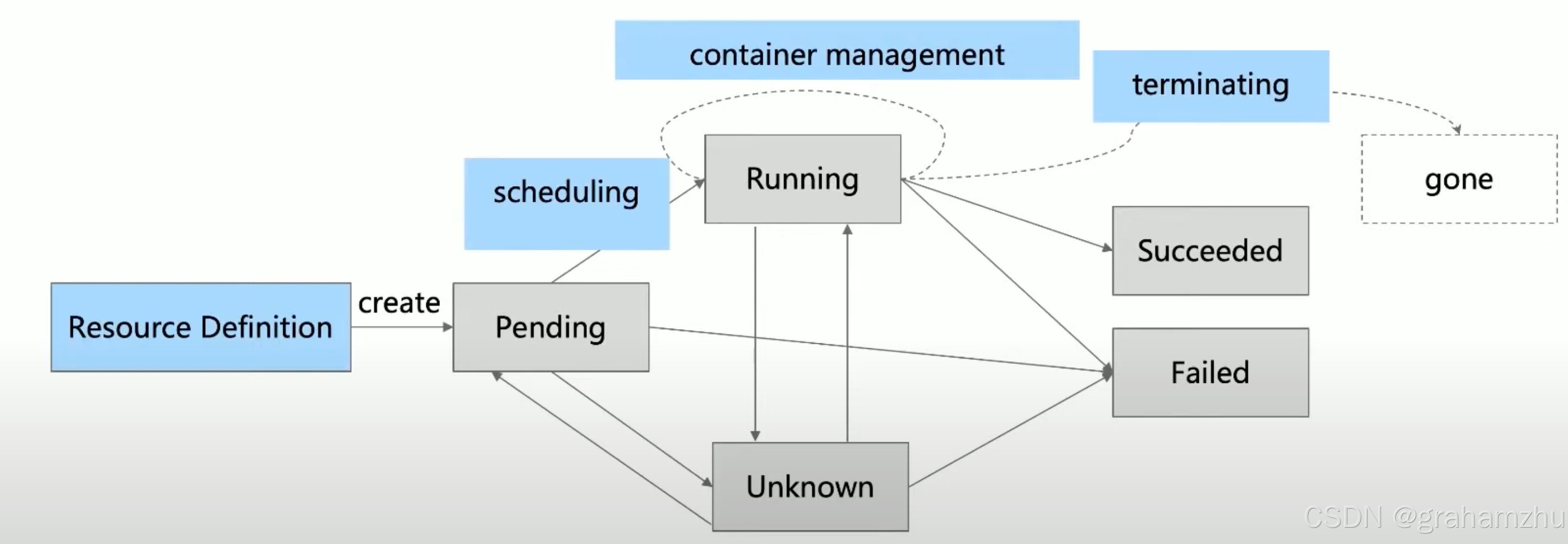
- 用户(应用程序、Deployment、Statefulset等)发起Pod创建,Pod被Apiserver写入etcd,此时会 进入 Pending 状态
- 调度器在充分考虑 资源、污点、亲和反亲和、拓扑打散 等配置后,为Pod选中一个Node节点,Pod 会 进入 ContainerCreating 状态
- 被调度到node上 的 kubelet 监听到有被调度到自身的Pod,会进行pod的启动,pod启动成功后 进入 Running 状态
- 如果用户发起Pod的Delete,Pod会 进入 Terminating 状态,删除完成后 API会响应 Gone
- 如果 Pod 中所有容器都正常退出,退出码为0,且Pod重启策略为Never,则 Pod会 进入Succeeded状态
- 如果 Pod 所有容器进程都已终止,且 至少有一个容器进程退出码不为0,且Pod重启策略不为
Never,则Pod 会 进入 Failed 状态 - 如果因为网络问题等,无法获取Pod状态,则Pod 显示为 Unknown 状态
- 如果因为节点承压/节点故障等原因,导致Pod被驱逐,则Pod会显示 Evicted 状态
2.Pod状态字段解析
2.1.Pod Phase
- Pod Phase是一个比较高层的状态,代表Pod所处的阶段
- Pod Phase只有5个枚举值:
Pending、Running、Succeeded、Failed、Unknown


2.2.Kubernetes Pod 状态全景解析表
| 用户可见状态 | Phase (阶段) | Conditions (关键状态) | 容器状态 | 描述 | 典型事件 | 持续时间 | 排查建议 |
|---|---|---|---|---|---|---|---|
| Pending | Pending | PodScheduled=False | - | Pod 已提交但未调度(资源不足、节点污点等) | Scheduled | 短时 | 检查节点资源/污点/标签 |
| ContainerCreating | Pending | PodScheduled=TrueContainersReady=False | Waiting(Reason: ContainerCreating) | 容器创建中(拉取镜像、挂载卷等) | Pulling imageCreating container | 短时 | 检查镜像大小/网络/存储卷 |
| ImagePullBackOff | Pending | PodScheduled=TrueInitialized=False | Waiting(Reason: ImagePullBackOff) | 镜像拉取失败(权限/镜像名错误/仓库不可用) | Failed to pull image | 持续 | 检查镜像名称/密钥/仓库可达性 |
| Init:0/3 | Pending | Initialized=False | Running(仅 Init 容器) | 初始化容器执行中(需顺序完成) | Started init container | 依赖任务 | 检查 Init 容器日志 |
| Init:Error | Pending | Initialized=False | Terminated(Init 容器 exit ≠0) | 初始化容器失败(依赖服务未就绪等) | Init container error | 持续 | 检查 Init 容器退出码/依赖服务 |
| PodInitializing | Pending | Initialized=TrueContainersReady=False | - | 主容器启动准备中(Init 容器完成,主容器未启动) | Initialized | 短时 | 等待主容器启动 |
| Running | Running | ContainersReady=False/TrueReady=False/True | Running | 至少一个容器在运行(可能部分容器未就绪) | Started | 正常 | 检查就绪探针/容器日志 |
| CrashLoopBackOff | Running | Ready=False | Waiting(Reason: CrashLoopBackOff) | 容器反复崩溃重启(程序错误/资源不足/探针误杀) | Back-off restarting failed container | 持续 | 检查容器日志/资源限制/探针配置 |
| Terminating | - | 保持删除前状态 | Terminating → Terminated | Pod 删除中(执行 PreStop 钩子) | KillingStopping container | ≤30s | 检查 PreStop 钩子是否阻塞 |
| Succeeded | Succeeded | Ready=False | Terminated(exit 0) | 所有容器成功退出(Job 任务完成) | Completed | 永久 | - |
| Failed | Failed | Ready=False | Terminated(exit ≠0 或 OOMKilled) | 至少一个容器异常退出(程序崩溃/启动失败) | FailedCreateContainerError | 永久 | 检查退出码/启动命令/镜像完整性 |
| Unknown | Unknown | Ready=Unknown | Unknown | 节点失联(网络中断/kubelet 故障/相关的某个插件故障,比如CSI Driver) | NodeNotReadyNodeUnreachable | 持续 | 检查节点状态/kubelet 日志 |
2.3.关键点解释
-
状态归类
CrashLoopBackOff的 Phase 应为Running
该状态表示容器已启动但反复崩溃,属于运行期问题(Phase 仍为Running)。Init:Error的 Phase 明确为Pending
初始化容器失败属于启动阶段问题,不直接触发Failed(仅当主容器启动失败才进入Failed)。Terminating无 Phase 状态
删除操作独立于生命周期阶段(Phase),需单独标注。
-
Conditions 精细化
- 区分
Initialized和ContainersReady:Initialized=True仅表示 Init 容器完成(主容器可能未启动)。ContainersReady=True表示 主容器全部就绪(通过 Readiness 探针)。
Running状态下Ready可能为False:容器运行中但未通过就绪探针。
- 区分
-
容器状态与原因绑定
- 明确
Waiting状态的子原因(如ImagePullBackOff、CrashLoopBackOff),直接关联诊断路径。 - 区分
Terminated的退出码(0 或 ≠0)及特殊原因(如OOMKilled)。
- 明确
-
Running≠ 服务可用- 即使 Phase 为
Running,若未通过 Readiness 探针,流量不会进入 Pod(kubectl get endpoints验证)。
- 即使 Phase 为
-
Succeeded仅适用于一次性任务- 若 Deployment 的 Pod 进入
Succeeded,表明 副本数应归零(如 Job/CronJob),否则需检查控制器配置。
- 若 Deployment 的 Pod 进入
-
Failed的触发条件- 主容器 启动失败(如启动命令错误)或 运行中崩溃且不再重启(重启策略为
Never)才会进入Failed。
- 主容器 启动失败(如启动命令错误)或 运行中崩溃且不再重启(重启策略为
-
Terminating卡住的处理- 若 PreStop 钩子执行超 30s,需调整
terminationGracePeriodSeconds或优化钩子逻辑。
- 若 PreStop 钩子执行超 30s,需调整
3.如何保证Pod高可用
3.1.资源限制

3.2.Pod的 三种服务质量Qos

3.2.1.QoS 核心概念
- QoS(Quality of Service)是 Kubernetes 用于管理 Pod 资源分配与驱逐优先级的核心机制。
- QoS通过 Pod 容器的资源请求(
requests)和限制(limits)配置自动分配 QoS 类别,决定资源紧张时 Pod 的驱逐顺序。
3.2.2.QoS 分类规则

3.2.2.1.Guaranteed 有保证的(最高优先级)
- 核心条件:
- 所有容器必须同时设置 CPU 和内存的
requests和limits; - 每个容器的
requests必须等于limits(如cpu: 500m,memory: 1Gi)。
- 所有容器必须同时设置 CPU 和内存的
- 特点:
- 资源完全保障,仅在 Pod 自身超限或节点无更低优先级 Pod 时被驱逐;
- 可使用独占 CPU 核(通过
staticCPU 管理策略)。
3.2.2.2.Burstable 可超售的(中优先级)
- 核心条件:
- 不满足 Guaranteed 条件;
- 至少一个容器设置了 CPU 或内存的
requests或limits。
- 特点:
- 资源使用有下限保障,但允许弹性扩展(如未设
limits时默认使用节点剩余资源); - 驱逐优先级低于 BestEffort,但高于 Guaranteed。
- 资源使用有下限保障,但允许弹性扩展(如未设
3.2.2.3.BestEffort 尽力而为的(最低优先级)
- 核心条件:
- 所有容器均未设置 CPU 和内存的
requests和limits。
- 所有容器均未设置 CPU 和内存的
- 特点:
- 无资源保障,优先被驱逐;
- 适用于非关键任务(如日志收集)以最大化资源利用率。
3.2.3.QoS 对资源管理的具体影响
3.2.3.1.调度与资源分配
- 调度依据:Kubernetes 调度器仅基于
requests分配节点,limits不影响调度;- 比如一个node只有4个cpu,配置limits.cpu==5没有问题,可以调度。但是如果配置requests.cpu==5,pod就会一直Pending,事件报错 InSufficient Cpu 即cpu不足。
- 资源使用限制:
- CPU(可压缩资源):超限时被节流(Throttled),但进程不被终止;
- 内存(不可压缩资源):超限时触发 OOM Killer,进程被终止。
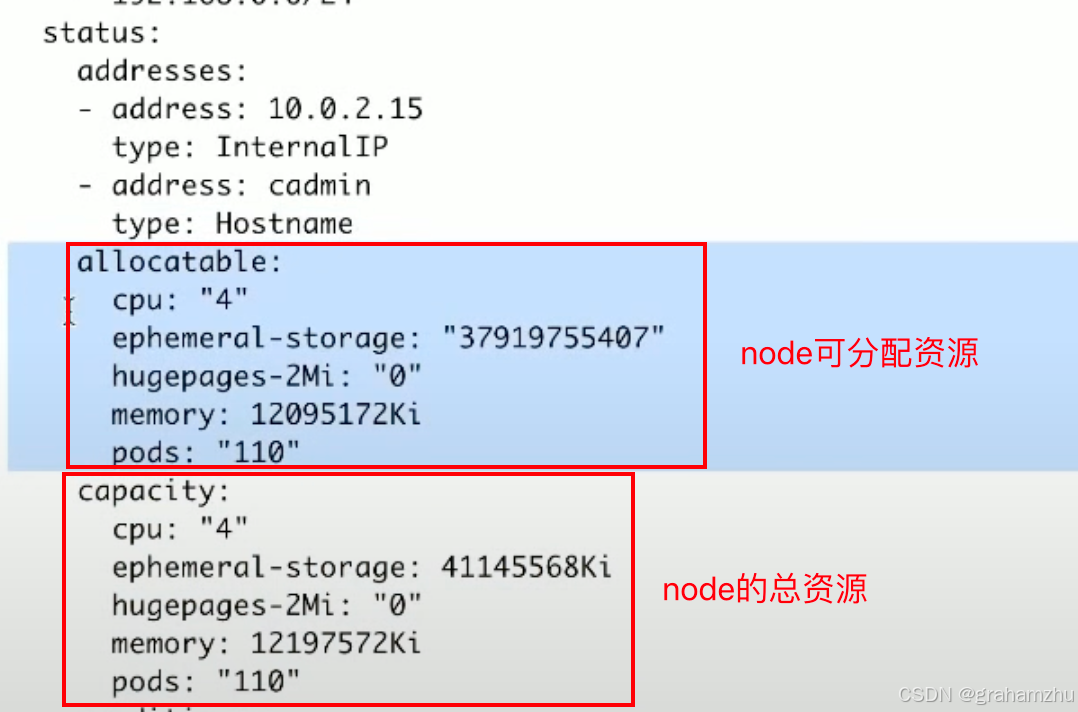
- 调度器完成调度后,会把对应node上的资源信息,扣除掉这个requests
- 比如在node中可以看到总资源、可分配资源(去除系统预留资源之后的)
- 调度器看node是否满足资源要求时,看的就是这里
3.2.3.2.不同QoS适用业务
- 核心服务:使用 Guaranteed 确保稳定性(如数据库)
- 弹性服务:Burstable 适合 Web 服务等需灵活扩展的场景
- 临时任务:BestEffort 用于批处理或监控工具
- 节点分级:结合节点亲和性策略将不同 QoS Pod 调度到专用节点
3.2.4.应用如何规划自己的Pod Qos

- 根据需要做一些压测,清楚自己的应用边界在哪里,设置相应的request/limit值
3.2.5.Pod 的 Qos 和 Priority 对比
- Priority:发生在pod调度时,如果调度发现资源不够/调度条件不满足,可能根据优先级抢占部分pod
- Qos:发生在pod启动时,如果kubelet发现资源不够,可能会根据Qos驱逐部分正在运行的pod,实现 高级别Qos pod的启动
- 二者作用不同,没有关系。如有需求,可以自行设计让他们产生关系
3.3.基于 Taint 的 Evictions

3.4.健康检查探针

3.4.1.健康检查探针参数列表
- 所有三种探针(
startupProbe,livenessProbe,readinessProbe)具有完全相同的结构。
3.4.1.1.参数列表
| 字段名称 | 类型 | 必填 | 默认值 | 描述 | 使用建议 |
|---|---|---|---|---|---|
| exec | Object | ✗ | - | 在容器内执行命令检查 | 命令应快速退出(0=成功,非0=失败) |
| httpGet | Object | ✗ | - | 发送HTTP GET请求检查 | 推荐用于Web服务 |
| tcpSocket | Object | ✗ | - | TCP端口检查 | 简单高效,适合非HTTP服务 |
| grpc | Object | ✗ | - | gRPC健康检查(v1.24+) | 适合gRPC微服务 |
| initialDelaySeconds | integer | ✗ | 0 | 容器启动后等待多少时间才开始本probe探测(秒) | 关键参数:慢启动应用需设置足够长(如30秒) |
| periodSeconds | integer | ✗ | 10 | 检查间隔时间(秒) | 根据服务特性调整: - 启动探针:5-10秒 - 就绪探针:2-5秒 - 存活探针:10-30秒 |
| timeoutSeconds | integer | ✗ | 1 | 单次检查超时时间(秒) | 网络延迟高时适当增加(如3秒) |
| successThreshold | integer | ✗ | 1 | 连续成功次数视为成功 | 就绪探针建议设为2(避免抖动) |
| failureThreshold | integer | ✗ | 3 | 连续失败次数视为失败 | 启动探针需设置较大值(如30) |
- 子字段详解(当使用特定检查方法时)
3.4.1.2.httpGet 字段
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
host | string | ✗ | 连接的主机名(默认Pod IP) | my-service |
path | string | ✓ | 访问的HTTP路径 | /healthz |
port | int/string | ✓ | 访问的端口号(数字或命名端口) | 8080 或 http |
scheme | string | ✗ | HTTP或HTTPS(默认HTTP) | HTTPS |
httpHeaders | []Object | ✗ | 自定义请求头 | {name: "X-Token", value: "secret"} |
httpHeaders[] | Object | ✓ | 包含name和value字段的头信息 |
3.4.1.3.tcpSocket 字段
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
host | string | ✗ | 连接的主机名 | 10.0.0.1 |
port | int/string | ✓ | 访问的端口号 | 3306 |
3.4.1.4.grpc 字段(v1.24+)
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
port | integer | ✓ | gRPC服务端口 | 50051 |
service | string | ✗ | 服务名称(用于健康检查) | grpc.health.v1.Health |
3.4.1.5.exec 字段
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
command | []string | ✓ | 执行的命令及参数 | ["/bin/sh", "-c", "echo test"] |
3.4.2.三种探针的配置差异
| 特性 | startupProbe | livenessProbe | readinessProbe |
|---|---|---|---|
| 核心目的 | 保护慢启动应用 | 检测运行时死锁/异常 | 判断是否可接收流量 |
| 失败后果 | 重启容器进程 | 重启容器进程,但不会重建Pod | 从Service端点移除,但不会重启容器进程 |
| initialDelaySeconds | 必须设置(覆盖启动时间) | 通常设为0(由startup接管) | 通常设为0 |
| periodSeconds | 建议较短(5-10秒) | 建议中等(10-30秒) | 建议较短(2-5秒) |
| failureThreshold | 建议较大(20-30) | 建议较小(3-5) | 建议较小(3-5) |
| successThreshold | 建议固定为1 | 建议固定为1 | 建议设为2(防抖动) |
| 检查方法优先级 | TCP > Exec > HTTP | HTTP > Exec > TCP | HTTP > gRPC > TCP |
3.4.3.配置示例对比
- 一般在startupProbe中配置initialDelaySeconds,表示多少秒之后才开始startupProbe的检查,等startupProbe通过后再开启liveness/readinessProbes
3.4.3.1.startupProbe (启动探针)
startupProbe:httpGet:path: /health-startupport: 8080initialDelaySeconds: 20 # 重要:给足启动时间periodSeconds: 5 # 较频繁检查failureThreshold: 30 # 总容忍时间 = 20+30×5 = 170秒timeoutSeconds: 3
3.4.3.2.livenessProbe (存活探针)
livenessProbe:httpGet:path: /health-liveport: 8080initialDelaySeconds: 0 # 立即开始(启动由startupProbe保护)periodSeconds: 15 # 中等频率failureThreshold: 4 # 60秒无响应重启timeoutSeconds: 3
3.4.3.3.readinessProbe (就绪探针)
readinessProbe:httpGet:path: /health-readyport: 8080initialDelaySeconds: 0periodSeconds: 5 # 高频检查successThreshold: 2 # 连续2次成功才标记就绪(防抖动)failureThreshold: 3 # 15秒失败即标记未就绪timeoutSeconds: 3
3.4.4.startupProbe的重要作用
- Startup Probe(启动探针) 是 Kubernetes 1.16+ 引入的专用健康检查机制,用于解决慢启动应用的致命问题:
- 关键痛点
- 传统应用(如 Java/Tomcat)冷启动可能耗时 1-5 分钟
- 数据库服务启动需加载大量数据(如 PostgreSQL 大表)
- AI 模型服务加载大型权重文件
⚠️ 若无 Startup Probe:livenessProbe 会在启动期间持续失败,导致容器被反复杀死
3.4.5.三大探针执行顺序
3.4.6.注意事项
-
参数计算公式
- 最大启动时间 =
initialDelaySeconds + (failureThreshold × periodSeconds) - 故障响应时间 =
failureThreshold × periodSeconds
- 最大启动时间 =
-
避免使用Exec的场景
场景 问题 替代方案 高频率检查 CPU浪费 TCP/HTTP 复杂脚本 执行时间不可控 专用健康端点 资源受限容器 OOM风险 轻量级检查
3.5.ReadinessGates字段
3.5.1.Readiness Gates 是什么
- Readiness Gates 是 Kubernetes 1.14+ 引入的高级就绪状态控制机制,允许用户通过自定义条件扩展 Pod 的就绪判定逻辑。它解决了传统就绪检测无法覆盖的复杂场景需求:
3.5.2.核心设计原理
3.5.2.1.工作原理
3.5.2.2.状态聚合规则
- Pod 的最终就绪状态由 内置Conditions + 自定义Conditions 共同决定:
Pod Ready = ContainersReady == True AND PodScheduled == True AND Initialized == True AND 所有ReadinessGates定义的自定义Condition == True
3.5.3.核心字段详解
3.5.3.1.Pod Spec 配置
apiVersion: v1
kind: Pod
metadata:name: my-app
spec:readinessGates: # 就绪门控定义- conditionType: "gate1.example.com/feature-ready"- conditionType: "gate2.example.com/external-dependency"
3.5.3.2.Status Conditions 结构
status:conditions:# 内置条件- type: "ContainersReady"status: "True"lastProbeTime: nulllastTransitionTime: "2023-07-20T01:23:45Z"# 自定义条件(由控制器更新)- type: "gate1.example.com/feature-ready" # 必须匹配spec中定义的typestatus: "True" # 必须为True/False/UnknownlastUpdateTime: "2023-07-20T01:24:30Z"reason: "FeatureEnabled" # 可选原因message: "Required feature activated" # 可选详情
3.5.4.ReadinessGates 完整工作流程
3.5.4.1.步骤 1:定义 Readiness Gates
# pod-with-gates.yaml
apiVersion: v1
kind: Pod
metadata:name: payment-service
spec:readinessGates:- conditionType: "infra.example.com/db-connection-ready"- conditionType: "infra.example.com/cache-init-complete"containers:- name: appimage: payment-app:latest
3.5.4.2.步骤 2:部署自定义控制器
// 控制器伪代码
for {pod := watch.Pods("payment-service")dbReady := checkDatabaseConnection(pod)cacheReady := checkCacheInitialization(pod)patch := []byte(fmt.Sprintf(`{"status": {"conditions": [{"type": "infra.example.com/db-connection-ready","status": "%s","lastUpdateTime": "%s"},{"type": "infra.example.com/cache-init-complete","status": "%s","lastUpdateTime": "%s"}]}}`, dbReady, time.Now(), cacheReady, time.Now()))kubernetes.CoreV1().Pods(pod.Namespace).PatchStatus(pod.Name, patch)
}
3.5.4.3.步骤 3:状态验证
kubectl get pod payment-service -o jsonpath='{.status.conditions[?(@.type=="Ready")].status}'
# 输出:False(直到所有门控条件满足)kubectl get endpoints payment-service
# 当所有条件为True时,Pod IP才会出现在Endpoint
3.5.5.典型应用场景
3.5.5.1.场景 1:等待外部依赖
- 如果有自定义的一些依赖/检查,要等到这些过了之后才能让整个Pod Ready,就可以用这个readinessGates
3.5.5.2.场景 2:Sidecar 协调
spec:readinessGates:- conditionType: "sidecar.proxy.io/config-loaded"containers:- name: appimage: my-app- name: sidecarimage: proxy-sidecarlifecycle:postStart:exec:command: - "/bin/sh"- "-c"- "load-config && kubectl patch pod $POD_NAME --patch '{\"status\":{\"conditions\":[{\"type\":\"sidecar.proxy.io/config-loaded\",\"status\":\"True\"}]}}'"
3.5.5.3.场景 3:渐进式功能启用
spec:readinessGates:- conditionType: "features.example.com/advanced-mode-enabled"# 业务逻辑
if checkCondition("advanced-mode-enabled"):enableAdvancedFeatures()
3.5.6.与 Readiness Probe 对比
| 特性 | Readiness Probe | Readiness Gates |
|---|---|---|
| 检测范围 | 容器内部状态 | 任意外部系统状态 |
| 执行者 | Kubelet | 自定义控制器 |
| 更新频率 | 周期性探测 | 事件驱动 |
| 检测逻辑 | 简单命令/HTTP/TCP | 复杂业务逻辑 |
| 依赖关系 | 无法跨容器协调 | 支持多组件协同 |
| 适用场景 | 单容器就绪检测 | 分布式系统集成 |
3.5.7.生产案例:Istio 实现
-
Istio 使用 Readiness Gates 控制 Envoy sidecar 初始化:
# Istio注入的Pod配置 spec:readinessGates:- conditionType: "sidecar.istio.io/ready"containers:- name: istio-proxy# 简化的就绪探针readinessProbe:httpGet:path: /healthz/readyport: 15021 -
工作流程:
istio-sidecar-injector自动添加 readinessGatepilot-agent启动后检测 Envoy 状态- 当
/healthz/ready返回 200 时更新条件 - Kubelet 聚合条件后标记 Pod 就绪
3.6.如何保证Pod的优雅启动/优雅终止

3.6.1.生命周期钩子的概念与设计
3.6.1.1.生命周期钩子是什么
- 属性字段:
pod.spec.containers.lifecycle - Kubernetes 为容器提供了两个关键生命周期钩子,允许在容器生命周期的特定时刻注入自定义操作:
3.6.1.2.设计目标
| 钩子 | 核心目标 | 关键特性 | Pod状态影响 |
|---|---|---|---|
postStart | 容器启动后初始化操作 | 异步执行(不阻塞主进程启动) | postStart结束之前,Pod不会Running |
preStop | 容器终止前优雅清理操作 | 同步执行(阻塞终止流程) | pod正常退出或Completed,不会执行preStop,只有发起Terminating才会执行 |
3.6.2.postStart 钩子详解
3.6.2.1.postStart 工作机制
3.6.2.2.postStart 配置参数
以下是 Kubernetes 中 postStart 与 preStop 生命周期钩子的完整属性说明表格。字段按作用范围分类,相同字段合并标注,并在备注中说明支持情况(✅ 表示支持):
| 字段分类 | 字段名 | 数据类型 | 是否必填 | 描述 | 备注 |
|---|---|---|---|---|---|
| 钩子类型选择 | exec | Object | 选其一 | 在容器内执行指定命令 | 支持范围:postStart✅、preStop✅ |
httpGet | Object | 选其一 | 发送 HTTP GET 请求到容器指定端点 | 支持范围:postStart✅、preStop✅ | |
tcpSocket | Object | 选其一 | 检测 TCP 端口连通性 | 支持范围:postStart✅、preStop✅ | |
sleep | Object | 选其一 | 暂停容器指定秒数(Kubernetes 1.30+) | 支持范围:preStop✅(postStart 暂不支持) | |
exec 方式字段 | command | []string | 必填 | 在容器内执行的命令(如 ["/bin/sh", "-c", "echo hello"]) | 注意:命令在容器根目录执行,不支持 Shell 管道符(需显式调用 Shell) |
httpGet 方式字段 | path | string | 必填 | HTTP 请求路径(如 /health) | 响应码 200~399 视为成功 |
port | IntOrString | 必填 | 请求的容器端口(可填数字或命名端口) | ||
host | string | 可选 | 请求的主机名(默认 Pod IP) | 若需请求外部服务需显式指定 | |
scheme | string | 可选 | 协议类型(HTTP 或 HTTPS,默认 HTTP) | ||
httpHeaders | []Object | 可选 | 自定义请求头(如 { name: "X-Token", value: "abc123" }) | ||
tcpSocket 方式字段 | host | string | 可选 | 请求的主机名(默认 Pod IP) | |
port | IntOrString | 必填 | 检测的容器端口(可填数字或命名端口) | TCP 连接建立成功视为通过 | |
sleep 方式字段 | seconds | integer | 必填 | 暂停的秒数(如 10) | 仅 preStop 支持,用于延迟终止 |
apiVersion: v1
kind: Pod
metadata:name: poststart
spec:containers:- name: lifecycle-demo-containerimage: nginxlifecycle:postStart:exec:command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
3.6.2.3.postStart 典型应用场景
| 场景 | 实现方式 | 目的 |
|---|---|---|
| 配置文件生成 | command: ["/bin/sh", "-c", "echo $CONFIG > /app/config.yaml"] | 动态生成配置 |
| 服务注册 | httpGet: { path: "/register?ip=$(POD_IP)", port: 8080 } | 向服务发现系统注册 |
| 数据预热 | command: ["python", "preload_data.py"] | 加载缓存/预计算数据 |
| 权限初始化 | command: ["chmod", "600", "/secrets/token"] | 设置敏感文件权限 |
3.6.2.4.postStart 关键注意事项
# 危险配置示例(避免阻塞)
postStart:exec:command: ["/bin/sh", "-c", "sleep 30"] # 长时间阻塞# 正确实践:后台执行
postStart:exec:command: ["/bin/sh", "-c", "nohup ./init.sh &"]
3.6.3.preStop 钩子详解
3.6.3.1.preStop 工作机制
3.6.3.2.preStop 配置参数
| 字段分类 | 字段名 | 数据类型 | 是否必填 | 描述 | 备注 |
|---|---|---|---|---|---|
| 钩子类型选择 | exec | Object | 选其一 | 在容器内执行指定命令 | 支持范围:postStart✅、preStop✅ |
httpGet | Object | 选其一 | 发送 HTTP GET 请求到容器指定端点 | 支持范围:postStart✅、preStop✅ | |
tcpSocket | Object | 选其一 | 检测 TCP 端口连通性 | 支持范围:postStart✅、preStop✅ | |
sleep | Object | 选其一 | 暂停容器指定秒数(Kubernetes 1.30+) | 支持范围:preStop✅(postStart 暂不支持) | |
exec 方式字段 | command | []string | 必填 | 在容器内执行的命令(如 ["/bin/sh", "-c", "echo hello"]) | 注意:命令在容器根目录执行,不支持 Shell 管道符(需显式调用 Shell) |
httpGet 方式字段 | path | string | 必填 | HTTP 请求路径(如 /health) | 响应码 200~399 视为成功 |
port | IntOrString | 必填 | 请求的容器端口(可填数字或命名端口) | ||
host | string | 可选 | 请求的主机名(默认 Pod IP) | 若需请求外部服务需显式指定 | |
scheme | string | 可选 | 协议类型(HTTP 或 HTTPS,默认 HTTP) | ||
httpHeaders | []Object | 可选 | 自定义请求头(如 { name: "X-Token", value: "abc123" }) | ||
tcpSocket 方式字段 | host | string | 可选 | 请求的主机名(默认 Pod IP) | |
port | IntOrString | 必填 | 检测的容器端口(可填数字或命名端口) | TCP 连接建立成功视为通过 | |
sleep 方式字段 | seconds | integer | 必填 | 暂停的秒数(如 10) | 仅 preStop 支持,用于延迟终止 |
pod.spec | terminationGracePeriodSeconds | integer | 可选 | 优雅终止超时时间 | 默认30s,超过这个时间还没有完成preStop/清理工作,则强制终止 |
apiVersion: v1
kind: Pod
metadata:name: no-sigterm
spec:terminationGracePeriodSeconds: 60containers:- name: no-sigtermimage: centoscommand: ["/bin/sh"]args: ["-c", "while true; do echo hello; sleep 10;done"]
---
apiVersion: v1
kind: Pod
metadata:name: prestop
spec:terminationGracePeriodSeconds: 30containers:- name: lifecycle-demo-containerimage: nginxlifecycle:preStop:exec:command: [ "/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done" ]
3.6.3.3.preStop 与优雅终止的关系
- Pod终止的完整过程:
- 用户发起Delete,API层面Pod进入Terminating状态,停止接收新流量
- 触发优雅终止计时,后续操作如果超过terminationGracePeriodSeconds,会被强制终止
- 如果有preStop,会去执行preStop
- 没有preStop,或preStop执行结束,kubelet 会发送SigTerm信号终止容器进程
- 如果时间还没超时,进程正常退出,则终止结束。不会发起SigKill
- 如果此过程时间超时terminationGracePeriodSeconds,kubelet会发起SigKill强制终止容器进程
- ⚠️ 注意:PreStop是发生在SigTerm信号之前的,等待PreStop执行结束才会发SigTerm
3.6.3.4.应用自行优雅终止
- 应用也可以自行捕获SigTerm信号,自己控制超时时间,自行进行优雅终止
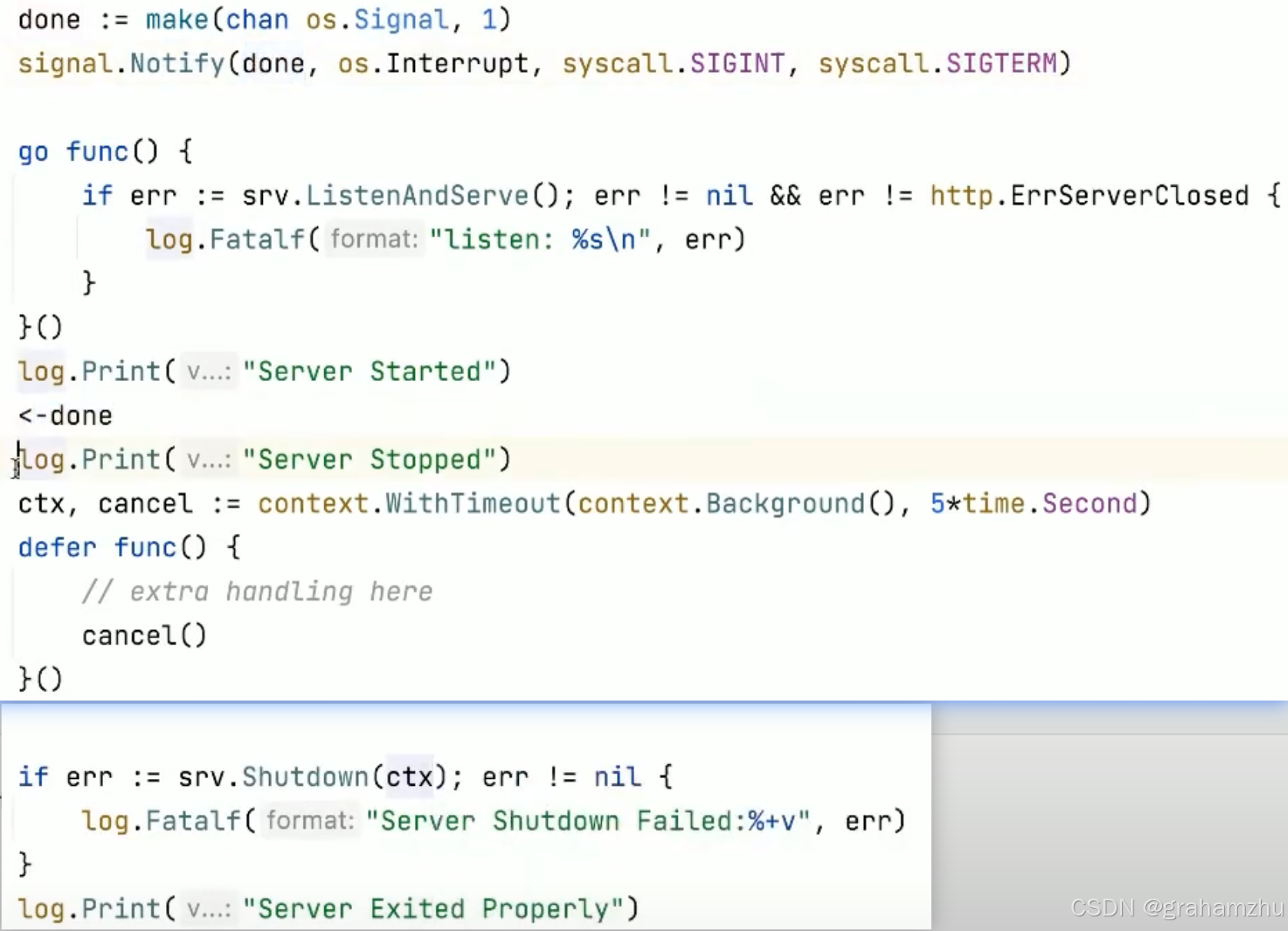
3.6.3.5.terminationGracePeriodSeconds时间分解

- 从preStop开始,terminationGracePeriodSeconds已经开始计时了
- 等待preStop结束,才会发送SigTerm。发起进程的正常结束
- 如果上述过程 任何一个节点,或累计发生超时,都会发起进程的SigKill
3.6.3.6.preStop 典型应用场景
| 场景 | 实现方式 | 目的 |
|---|---|---|
| 服务优雅下线 | command: ["curl", "-X", "POST", "http://localhost:8080/deregister"] | 从负载均衡移除 |
| 会话保持 | command: ["/bin/sh", "-c", "flush_sessions.sh"] | 保存用户会话状态 |
| 数据库连接清理 | httpGet: { path: "/close-connections", port: 8080 } | 避免事务中断 |
| 监控通知 | command: ["/bin/sh", "-c", "echo 'Container stopping' | nc monitoring:9090"] | 发送停止事件到监控系统 |
3.6.3.7.生产实践案例:会议应用优雅发布
- 比如当前有个会议应用,有很多人开会议时间非常久,比如1天/2天,那么这个过程里后台就无法发新版本,否则就会把已经打开的会议停止掉,影响到使用
- 那么怎么实现优雅发布?
- 发布的时候把terminationGracePeriodSeconds设置的非常久,保证不会发生超时而强制终止
- 应用代码自行捕获SigTerm信号,检查当前有没有活跃状态的会议,如果有,则等待。如果没有,则发起进程的正常退出
- 这样再去发布,就没问题了。
- 发布新版本,pod进入Terminating,不会再接收新请求,当前Pod不会再有新会议打开
- terminationGracePeriodSeconds超级久,保证发布时间可以超级久
- 应用自行捕获 SigTerm,等待尚未结束的会议
- 所有存量会议结束后,应用进程正常退出,不会发起SigKill,pod就可以正常delete,重建出新的Pod
3.6.3.8.生产经验
- TerminatingPod的误用


- 有个用于管理进程生命周期的开源项目:https://github.com/krallin/tini
3.6.4.配置对比与最佳实践
3.6.4.1.参数对比表
| 特性 | postStart | preStop |
|---|---|---|
| 执行时机 | 容器创建后立即触发 | 容器终止前触发 |
| 阻塞性 | 非阻塞(异步) | 阻塞(同步) |
| 失败处理 | 导致容器重启 | 导致优雅终止失败 |
| 超时控制 | 无显式超时 | 受 terminationGracePeriodSeconds 限制 |
| 推荐操作类型 | 轻量级初始化 | 关键清理操作 |
| 与主进程关系 | 并行执行 | 在主进程收到 SIGTERM 前执行 |
| 服务可用性影响 | 不影响服务启动 | 直接影响停止延迟 |
3.6.4.2.生产级配置示例
apiVersion: apps/v1
kind: Deployment
spec:template:spec:terminationGracePeriodSeconds: 60 # 延长优雅终止期containers:- name: web-appimage: nginx:1.25lifecycle:postStart:exec:command: ["/bin/sh", "-c", "echo 'Started at $(date)' > /app/start.log"]preStop:exec:command: ["/bin/sh", "-c", "nginx -s quit; while [ -f /var/run/nginx.pid ]; do sleep 1; done"]readinessProbe:httpGet:path: /readyport: 80
3.6.4.3.调试技巧
# 查看钩子执行状态
kubectl describe pod <pod-name> | grep -A 10 "Events"# 典型事件日志
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Started 5s kubelet Started container web-appWarning FailedPostStart 3s kubelet Failed to run postStart hook...
3.6.5.高级模式与集成方案
3.6.5.1.与 Init 容器的协作
3.6.5.2.服务网格集成(Istio)
# Istio sidecar 的 preStop 配置
- name: istio-proxylifecycle:preStop:exec:command: ["/bin/sh", "-c", "while curl -sf http://127.0.0.1:15000/healthz/ready; do sleep 1; done"]
3.6.5.3.分布式系统协调
preStop:exec:command: ["/bin/sh", "-c", """# 1. 标记节点为离开状态curl -X PUT http://cluster-manager/leave?node=$(HOSTNAME)# 2. 等待数据迁移完成while ! curl -sf http://cluster-manager/migration-complete; do sleep 5; done"""]
3.6.6.常见陷阱与解决方案
3.6.6.1.postStart 阻塞启动
- 现象:容器卡在
ContainerCreating状态 - 解决方案:
# 后台执行长时间任务 postStart:exec:command: ["/bin/sh", "-c", "(nohup ./long-init.sh &)"]
3.6.6.2.preStop 超时导致强制终止
- 现象:
kubectl describe pod显示TerminationGracePeriodSeconds超时 - 优化方案:
# 增加优雅终止时间 spec:terminationGracePeriodSeconds: 120 # 默认30秒# 拆分清理步骤 preStop:exec:command: ["/bin/sh", "-c", "send_stop_signal && wait_for_cleanup"]
3.6.6.3.钩子执行权限问题
- 现象:
Permission denied错误 - 解决方案:
securityContext:runAsUser: 1000capabilities:add: ["CHOWN", "SETGID"]lifecycle:postStart:exec:command: ["chown", "appuser:appgroup", "/data"]
3.6.7.最佳实践总结
3.6.7.1.postStart 黄金法则
1. **轻量化**:执行时间 < 1秒
2. **幂等性**:支持重复执行不报错
3. **后台化**:长时间任务用 `&` 或 `nohup`
4. **可观测**:记录操作日志到标准输出
3.6.7.2.preStop 关键策略
1. **快速响应**:10秒内完成关键操作
2. **渐进式清理**:- 先停止接收新请求- 再处理进行中任务- 最后释放资源
3. **超时控制**:监控 terminationGracePeriodSeconds
4. **跨容器协调**:通过共享卷同步状态
3.6.7.3.全局生命周期管理
apiVersion: apps/v1
kind: Deployment
spec:template:spec:terminationGracePeriodSeconds: 90containers:- name: main-applifecycle:postStart:exec: command: ["/app/init.sh"]preStop:httpGet:path: /pre-stopport: 8080readinessProbe:httpGet:path: /readyport: 8080livenessProbe:httpGet:path: /liveport: 8080
架构师洞察:
postStart 和 preStop 是 Kubernetes 应用实现自管理能力的关键工具:
- postStart = 赋予容器"出生后第一声啼哭"的能力
- preStop = 给予容器"临终遗言"的机会
合理运用这两个钩子,能显著提升系统的:
✅ 可靠性 - 确保服务平滑上线/下线
✅ 可维护性 - 自动化初始化/清理流程
✅ 弹性 - 优雅处理节点驱逐和滚动更新
4.在Kubernetes部署应用的挑战
4.1.应用资源规划

4.2.存储带来的挑战

4.3.应用配置

4.4.数据的保存


- hostPath/localVolume 在pod重建后,pod可能漂移,数据就认为不存在了,实际上数据留在原节点了。生产上hostPath一般不对外暴露使用,只有管理pod有权限使用
- rootFS 是容器生命周期相关的,容器重启后数据就不存在了
4.5.容器应用可能面临的进程中断

4.6.高可用部署方式

4.7.课后作业
