Airtable 的数据超出上限,3 种常见应对方式
原文链接:https://www.nocobase.com/cn/blog/airtable-data-limit-reached-3-common-solutions。
最近,我们陆续收到一些用户的来信。他们大多在业务不断扩展,团队规模持续增长的过程中,开始认真思考一个问题:
是不是该从 Airtable,切换到一个更具性价比、能承载更多数据量的工具?
为此我搜索了一些社区讨论,也看到了很多开发者遇到类似的困扰。
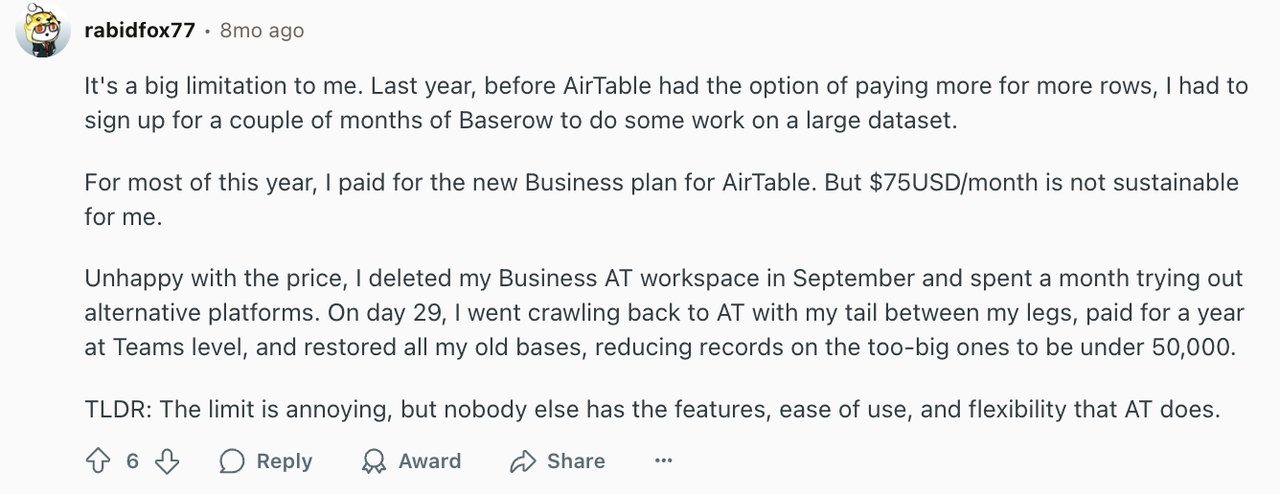
比如下面这位软件工程师就发帖求助:Airtable 的 50,000 条记录限制,已经让他在构建数据密集型项目时倍感吃力。

Airtable 是一个伟大的产品,它便捷、易用、上手快。
如果你的团队只有 10 人左右,使用起来会非常顺畅,成本也低。但是如果随时你的业务增长,你可能需要额外考虑一些问题。
比如我们来看一下 Airtable 当前的定价结构:

- Free(免费)— 每个 Base 限制 1,000 条记录
- Team($20/人/月)— 限制 50,000 条
- Business($45/人/月)— 限制 125,000 条
- Enterprise(定制价)— 限制 500,000 条
虽然这些限制在定价页面上写得非常清楚,但在实际使用初期往往不太容易察觉。直到某一天你突然发现:系统开始卡顿、自动化规则频繁报错、甚至无法继续添加记录——这才意识到,问题已经来到眼前。
也许你正是因为遇到了类似问题,才点开了这篇文章。
那么,当你开始遇到数据瓶颈时,接下来可以怎么做?
我们看到不同团队会采取不同的应对方式:
- 有人选择升级套餐,尽量把系统撑久一点;
- 有人拆分多个 Base,再用脚本或 API 做跨表同步;
- 也有一些人开始考虑从“表格工具”转向“更强大的业务系统构建平台”——特别是那些支持自托管、数据结构更自由的开源产品。
今天这篇文章,就想围绕这几种常见做法分享一些思路。希望能帮你找到适合自己的下一步。
💬 欢迎来到 NocoBase 的博客。NocoBase 是一个开源无代码开发平台,用于构建数据应用、内部工具和流程系统,支持自托管,插件化设计,开发者友好。→ 在 GitHub 上了解更多
1. 升级套餐:最简单
如果你认为你的团队处理的数据量不会再大量增长了,很好,升级套餐是最简单的做法。
正如这位 Reddit 用户所说:大多数人都使用不到 5-10k ,要么直接超过 100k。介于两者之间的不多。

以一个 10 人团队为例,从 Team 升级到 Business,每人每月价格从 $20 提升到 $45。这样一年下来,把每个 Base 的记录数从 5 万条扩展到 12.5 万条,你只需要多付 3,000 美元。
| 套餐 | 每 Base 限制 | 单价(年付) |
|---|---|---|
| Team | 50,000 条 | $20/人/月 |
| Business | 125,000 条 | $45/人/月 |
| Enterprise | 500,000 条 | Custom |
不过,一旦数据继续增长或结构变得复杂,升级套餐的边际效益就会开始下降。这时,有些团队会考虑另一种方式:把数据拆分到多个 Base 里。
2. 拆分 Base + 同步脚本
另一种常见的做法,是将数据拆分到多个 Base 中,并通过 Airtable 的 API 或脚本机制进行同步处理。
在社区里,不少开发者都分享了类似经验。
比如这位提到:

“通常没有人需要同时对 50 万条记录进行可视化编辑或工作流操作。所以我通过 API 做了一些绕过限制的方式,来让 Airtable 用于编辑交互,而不是记录数据库。”
他的做法是:
- 把 Airtable 当作“工作接口”,只加载团队当周需要处理的部分数据;
- 数据的完整记录和归档,仍然依赖一个真正的数据库(如 PostgreSQL、MongoDB),通过脚本或中间服务与 Airtable API 同步。
在技术实现上,通常会:
- 使用定时脚本(如 Node.js + cron job)或自动化平台(如 Zapier、Make)定期将核心数据写入 Airtable 供团队操作;
- 操作完成后,再将更新内容回写到主数据库,保持数据一致性;
- 对于敏感或高频数据,则完全留在主库中,仅通过接口提供查询和展示。
假设你用 Node.js + Airtable SDK + PostgreSQL:
// 示例:将 Airtable 中已更新记录同步回主数据库
const Airtable = require('airtable');
const { Pool } = require('pg');// 安全地从环境变量获取API密钥和数据库连接字符串,而非硬编码
const AIRTABLE_API_KEY = process.env.AIRTABLE_API_KEY;
const AIRTABLE_BASE_ID = process.env.AIRTABLE_BASE_ID;
const DATABASE_URL = process.env.DATABASE_URL;if (!AIRTABLE_API_KEY || !AIRTABLE_BASE_ID || !DATABASE_URL) {console.error("请确保设置了AIRTABLE_API_KEY, AIRTABLE_BASE_ID, 和 DATABASE_URL 环境变量。");process.exit(1);
}const base = new Airtable({ apiKey: AIRTABLE_API_KEY }).base(AIRTABLE_BASE_ID);
const pg = new Pool({ connectionString: DATABASE_URL });async function syncUpdatedRecords() {try {// 考虑分页处理,确保能获取所有未同步记录let allRecords = [];let offset = null;do {const response = await base('Orders').select({ filterByFormula: 'NOT({Synced} = TRUE)',pageSize: 100, // 每次请求的记录数offset: offset }).firstPage(); // 使用firstPage()并手动处理offsetallRecords = allRecords.concat(response);offset = response.offset;} while (offset);for (let record of allRecords) {const { id, fields } = record;// 假设Status和UpdatedAt字段存在const status = fields.Status || null; const updatedAt = fields.UpdatedAt || new Date().toISOString(); // 写入主数据库await pg.query(`INSERT INTO orders (airtable_id, status, updated_at)VALUES ($1, $2, $3)ON CONFLICT (airtable_id) DO UPDATE SETstatus = EXCLUDED.status,updated_at = EXCLUDED.updated_at`, [id, status, updatedAt]);// 标记为已同步await base('Orders').update(id, { Synced: true });}console.log(`成功同步了 ${allRecords.length} 条记录。`);} catch (error) {console.error('同步记录时发生错误:', error);} finally {// 确保连接池在脚本完成后关闭,或根据实际情况管理// await pg.end(); }
}// 调用同步函数
// syncUpdatedRecords(); // 在生产环境中可能通过cron job或其他调度器调用// 注意:此示例代码仅为演示核心逻辑,生产环境需考虑错误处理、增量同步、API速率限制、分页等复杂情况。
这种方式的核心理念是:Airtable 用来交互,数据库用来存储,两者之间用同步逻辑衔接。
在特定场景下,这种“前后端解耦”的做法可以运行得很好,比如商品 SKU 管理、流媒体内容目录、表单审批等结构稳定、操作可切割的业务。
但它也存在明显的限制:
- 需要开发能力:需要写脚本或构建同步机制来维持数据一致性,这要求你需要具备一定的编程和数据库管理知识。
- 系统复杂度上升:越拆越碎,不仅维护成本随时间增长而累积,团队成员在理解和使用整个系统时也会面临更高的学习和协作门槛。
- 权限和协作难统一:跨 Base 之间的权限配置、视图管理、审核流程都需要额外开发或人为管理,难以实现全局统一的权限控制和数据洞察。
如果你已经在写脚本、拆分 Base、维护同步逻辑——那可能说明你正在用 Airtable 做它本身并不擅长的事。
3. 搭建自托管且可扩展结构的系统
如果你能做到第二种方案,这也往往意味着:你已经具备了一定技术能力,可以考虑更灵活的解决方案,比如搭建一个可自定义数据结构和可扩展工作流的自托管系统。
从“用工具”到“搭系统”,你不再是将流程勉强塞进表格里,而是用一个支持复杂结构的平台,真正把业务模型一步步建出来。
这种思路有几个显著变化:
✅ 数据结构更自由
与其将一个业务拆成 5 个 Base、靠脚本打通,不如用一个具备“关系建模”能力的平台,把业务实体一次性建好。
你可以根据实际业务关系创建多表、多对多关系,处理嵌套对象、状态变化、子流程等复杂情况。
✅ 流程自动化能力更强
Airtable 的 Automations 足够轻巧,但当你需要:
- 多级审批
- 条件分支
- 多步骤的串联动作(比如:审批通过 → 更新客户状态 → 自动派发任务 → 发通知)
这时一个具备工作流引擎的平台就更合适了。你不再是“写脚本”来弥补流程的断点,而是“配置”出流程图。
✅ 数据更可控、系统更可拓展
当你选择自托管平台时,意味着:
- 你的数据完全在自己控制范围内(比如在本地或专有云部署)
- 你可以使用插件、接口,拓展出任何自己需要的功能,而不是受限于 SaaS 的边界
- 更重要的是,你不再需要为每个用户每个月按人头付费,而是按需、一次性地构建属于你的系统
这类平台适合谁?
不是每个人都需要走到这一步。我也看到有用户,他换到的其他平台,最后还是回到了 Airtable。原因是他认为 Airtable 的功能、易用性和灵活性无人能及。
但如果你和你的团队正面临以下问题:
- 数据结构越来越复杂,表越来越多,权限分配越来越混乱
- 审批流程、任务分发、角色控制无法靠 Airtable 实现
- 数据敏感或部署有合规要求(如金融、医疗、教育等行业)
- 想要长期控制成本,不希望随着人数增长而无限涨价
那你或许可以考虑试试这些平台。
你不需要马上迁移,而是可以从某一个模块开始,比如 CRM 的一部分功能或工单系统等轻量场景。
如果你有兴趣进一步了解这类平台,这里整理了一些常被团队采用的选项。每个工具的定位和适用范围略有不同,具体选择也取决于你的团队结构、技术背景和使用目的。
| 工具 | 部署方式 | 特点 | 适用场景 |
|---|---|---|---|
| NocoBase | 自托管 | 配置式建模 + 插件系统 + 工作流引擎 + 精细权限控制 | 需要搭建 CRM、审批系统、项目流程等完整业务系统;关注数据权限与自托管 |
| Appsmith | 自托管 / 云端 | 偏向前端开发,可自定义组件、连接 API | 内部工具构建(如仪表盘、查询界面);需要灵活写代码的技术团队 |
| Budibase | 自托管 / 云端 | 表单驱动、流程简洁,偏轻量级后台工具 | 小团队构建报表、审核、表单类应用;追求部署快、维护简单 |
| Baserow | 云端 / 私有化 | 更像 Airtable,可视化表格界面;支持 API 扩展 | 表格主导的数据录入与共享需求;轻度使用、希望降低切换成本 |
上表提到的这些工具都是开源项目,支持自托管部署。你可以根据自己的业务需求、部署环境和工程能力,自由选择适合的方案。
如果你想了解更多 Airtable 的开源替代品,可以阅读:
GitHub上 Star 数量最多的 Airtable 开源替代者
写在最后
Airtable 曾经是许多团队数字化的起点,它降低了搭建工具的门槛,也启发了我们对数据可视化、流程协作的新想象。但随着业务的复杂化,我们终究需要面对系统的可扩展性、可控性与性价比。
不同团队会选择不同的路径,没有一种方式是绝对正确的,重要的是理解你正在解决什么问题,和它对你未来意味着什么。
希望这篇文章能为你提供一个观察角度。
相关阅读:
- 替代 Airtable / 飞书表格?用零代码构建多对多关系的任务管理系统
- GitHub上 Star 数量最多的 Airtable 开源替代者
- 2025 年 AppSheet 最佳开源替代品
- 7 款最佳数据集成平台推荐
- 开发者推荐:6 款更灵活的 Firebase 开源替代品
- 四个强大的 Salesforce 开源替代方案(附成本对比)