Distilling Knowledge via Knowledge Revie
Distilling Knowledge via Knowledge Revie
发表:CVPR 2021
机构:The Chinese University of Hong Kong
连接:https://arxiv.org/pdf/2104.09044v1
Abstract
知识蒸馏旨在将教师网络的知识传递给学生网络,目标是大幅提升学生网络的性能。以往的方法大多侧重于设计同一级别特征之间的特征变换和损失函数,以提高蒸馏效果。而我们则不同,研究了教师网络和学生网络之间跨层级连接路径这一因素,并揭示了其极为重要的作用。首次在知识蒸馏中提出了跨阶段连接路径。我们设计的新型复审机制不仅高效且结构简单。最终构建的嵌套紧凑框架几乎不增加计算开销,同时在多种任务上优于其他方法。我们将该方法应用于分类、目标检测和实例分割任务,所有任务均显著提升了学生网络的性能。代码已开源,地址为 https://github.com/Jia-Research-Lab/ReviewKD。
1. Introduction
深度卷积神经网络(CNN)在多种计算机视觉任务中取得了显著的成功。然而,CNN的成功往往伴随着大量的计算和内存消耗,这使得其在资源有限的设备上应用成为一个挑战。针对这一问题,已经出现了多种训练快速且紧凑神经网络的技术,包括设计新型架构、网络剪枝、量化以及知识蒸馏等。
本文聚焦于知识蒸馏,考虑到它的实用性、高效性以及最大的潜力——几乎适用于所有网络架构,并且可以与诸如网络剪枝和量化等其他策略结合,进一步优化网络设计。知识蒸馏最早由相关研究提出,其过程是在较大网络(教师网络)的监督下训练较小网络(学生网络)。最初的知识蒸馏通过教师网络的logits进行,学生网络在真实标签和教师logits的双重监督下训练。近年来,研究者们致力于提升蒸馏的有效性,例如FitNet通过中间特征进行知识蒸馏,AT优化了FitNet并利用特征的注意力图传递知识,PKT将教师知识建模为概率分布,CRD则使用对比目标传递知识。这些方法主要集中于特征转换和损失函数设计。

本文提出了一个全新的视角,关注教师和学生之间的连接路径。以往方法如图1(a)-(c)所示,仅使用同一级别的信息来指导学生网络,例如在监督学生第四阶段输出时,总是利用教师第四阶段的信息。虽然这种方式直观且易于构建,但我们发现它实际上成为了整个知识蒸馏框架的瓶颈。对结构的快速更新能够显著提升整体性能。我们深入探讨了连接路径设计的重要性,提出了一个新颖且有效的框架,关键改进是利用教师网络的低层特征来监督学生网络的深层特征,从而显著提升整体表现。
进一步的结构分析表明,学生网络的高层阶段有很强的能力从教师网络的低层特征中学习有用信息,这一点在第4.4节有更详细的讨论。这一过程类似于人类的学习曲线:儿童在早期只能理解部分知识,随着成长,逐渐吸收和记忆过往的经验知识。
基于这些发现,我们提出利用教师网络的多层信息指导学生网络单层学习的新机制,称之为“知识复审”。如图1(d)所示,该机制通过利用先前(较浅层)特征指导当前特征,使学生网络不断回顾和刷新对“旧知识”的理解和上下文。这类似于人类在学习过程中连接不同时期知识的常见做法。
然而,如何从教师网络的多层信息中提取有用知识并有效传递给学生,仍是一个开放且具挑战性的问题。为此,我们设计了一个残差学习框架,使学习过程更加稳定和高效。同时,引入了基于注意力的融合(ABF)模块和分层上下文损失(HCL)函数,以进一步提升性能。我们的框架显著提升了学生网络的学习效果。
通过应用该方法,我们在多种计算机视觉任务中取得了更好的表现。第4节的广泛实验验证了知识复审策略的巨大优势。
主要贡献包括:
-
提出一种新的复审机制,在知识蒸馏中利用教师的多层信息指导学生单层学习;
-
设计了残差学习框架以更好地实现复审机制的学习过程;
-
引入基于注意力的融合模块(ABF)和分层上下文损失函数(HCL)以进一步提升复审机制的效果;
-
通过应用该蒸馏框架,在多个计算机视觉任务中使多种紧凑模型达到了最先进的性能。
2. Related Work
知识蒸馏的概念最早在文献[9]中提出,当时学生网络不仅从真实标签中学习,还利用教师网络提供的软标签。FitNet[25]通过单阶段的中间特征进行知识蒸馏,其核心思想十分简单,即通过卷积层将学生网络的特征转换成与教师网络相同形状,再用L2距离衡量两者之间的差异。
许多后续方法沿用了FitNet的思路,使用单阶段特征来进行知识蒸馏。例如,PKT[23]将教师的知识建模为概率分布,并使用KL散度来度量差异;RKD[22]通过多个样本间的关系来引导学生学习;CRD[28]则结合对比学习与知识蒸馏,采用对比目标来传递知识。
也有一些方法利用多阶段信息进行知识传递。AT[38]利用多个层的注意力图来传递知识;FSP[36]通过生成层特征的FSP矩阵,用该矩阵指导学生网络;SP[29]在AT的基础上进一步改进,不再仅使用单一输入信息,而是通过样本间的相似度来引导学生;OFD[8]则引入了一种新的距离函数,利用边缘ReLU来蒸馏教师与学生间的关键信息。
然而,所有这些方法都未曾涉及“复习知识”的可能性,而我们的工作发现这一机制对于快速提升系统性能非常有效。
3. Our Method
我们首先对知识蒸馏过程和“回顾机制”进行形式化描述。接着,我们提出一个新颖的框架,并介绍注意力融合模块(ABF)和层次上下文损失函数(HCL)。
3.1. Review Mechanism



3.2 Residual Learning Framework


3.3. ABF and HCL

4. Experiments
我们在多个任务上进行了实验验证。首先,我们将本文方法与其他知识蒸馏方法在图像分类任务上进行了比较,分别在不同架构和数据集下测试。然后,我们将本方法应用于目标检测和实例分割任务。在所有这些任务中,我们的方法都能持续显著提升学生模型的性能。
4.1. Classification
数据集 (1) CIFAR-100:包含 5 万张训练图像(每类 500 张)和 1 万张测试图像,共 100 类;(2) ImageNet [3] 是目前最具挑战性的分类数据集,包含 120 万张训练图像和 5 万张验证图像,涵盖 1000 个类别。
实现细节 在 CIFAR-100 数据集上,我们使用多种代表性神经网络架构进行实验,包括 VGG [27]、ResNet [7]、WideResNet [37]、MobileNet [26] 和 ShuffleNet [39, 21]。除初始学习率和批大小设置遵循 [5] 外,其余训练设置与 CRD [28] 保持一致。
具体地,我们对所有模型训练 240 个 epoch,第一个 150 个 epoch 后每 30 个 epoch 将学习率衰减 0.1 倍。MobileNet 和 ShuffleNet 的初始学习率设为 0.02,其它模型为 0.1,批大小统一为 128。每个模型训练 3 次,报告平均准确率。为保证公平性,我们或从原论文中引用其他方法的结果(若训练设置相同),或使用作者提供的公开代码,在我们统一的训练设置下重新训练并测试。
在 ImageNet 上,我们采用标准训练流程,对模型训练 100 个 epoch,每隔 30 个 epoch 学习率衰减一次,初始学习率设为 0.1,批大小设为 256。

在 CIFAR-100 上的结果 表 1 总结了教师和学生模型使用相同架构风格时的结果。我们根据使用的特征划分了不同的方法组:KD(仅使用 logits);FitNet 组使用单层中间特征;AT 组使用多层特征;而我们的方法同时利用多层特征并引入“回顾机制”。在所有架构设置下,我们的方法在性能上全面超越所有已有方法。

我们还测试了教师和学生模型架构风格不一致的设置,结果见表 2。OFD [8] 和我们的方法都使用多层特征进行蒸馏。实验结果表明,相比只使用最后一层进行蒸馏的方法,多层信息的蒸馏效果更好,进一步证明了我们提出的回顾机制能够打破以往“只能在中间层或最后一层进行蒸馏”的限制 [28]。

在 ImageNet 上的结果 由于 CIFAR-100 数据集图像较少,我们还在 ImageNet 上验证了本方法的扩展性。我们设置了两个蒸馏任务:ResNet50 → MobileNet [11] 和 ResNet34 → ResNet18。如表 3 所示,我们的方法再次在两个设置中均优于所有现有方法。设置 (a) 中,由于网络结构差异较大,任务更具挑战性,但我们的方法依然表现出显著优势;在设置 (b) 中,教师与学生网络之间差距已由现有最优方法压缩至 2.14 个点,而我们进一步缩小至 1.70,达成了约 20% 的相对性能提升。
4.2. Object Detection
我们进一步将本方法应用于目标检测任务。和图像分类任务类似,我们在学生和教师模型的骨干网络输出特征之间进行蒸馏。更多细节见附录部分。
我们在 COCO2017 数据集 [18] 上进行实验,并使用当前最主流的开源框架 Detectron2 [33] 作为训练与评估平台。教师模型选用 Detectron2 提供的预训练权重。学生模型遵循传统设定 [31] 使用标准策略进行训练,所有模型均在 COCO2017 的验证集上评估性能。
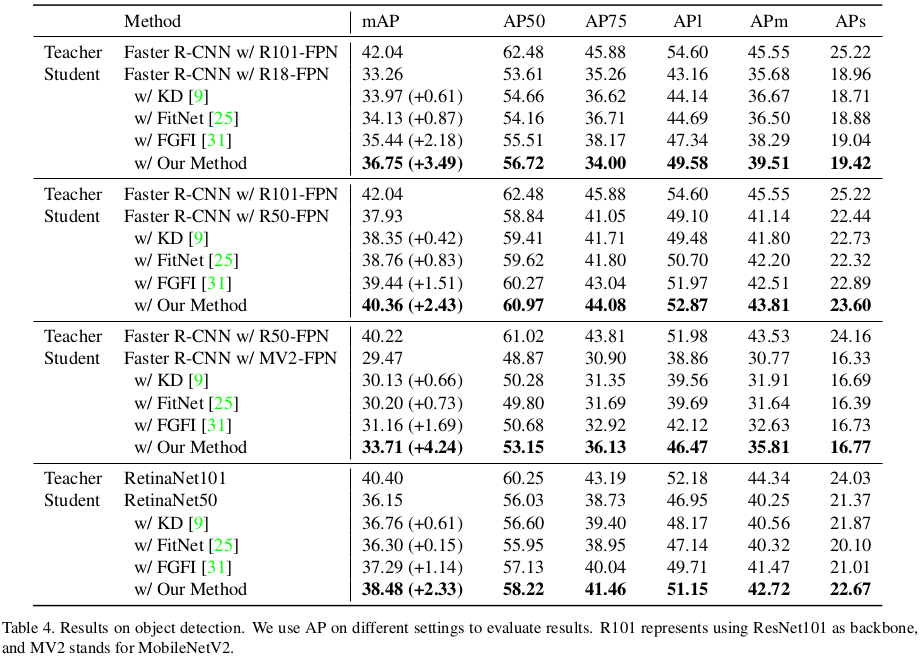
目前,仅有少量方法(如 FGFI [31], OFD [8])明确提出可用于检测任务。我们复现了代表性的 KD、FitNet 和最新的 FGFI 方法,并与我们的方法进行比较,结果见表 4。可以看出,即使是经典 KD、FitNet 等方法也能略微提升目标检测性能,但性能增幅有限。而 FGFI 是专为检测设计的方法,在该任务中表现优于一般蒸馏方法。尽管如此,我们的方法在所有配置下仍能显著优于 FGFI,提升幅度更大。
我们还对实验配置进行了多样化尝试,以验证方法的泛化性。在两阶段检测器 Faster R-CNN [24] 中,我们替换了不同的骨干网络,发现即使在结构相近的架构(如 ResNet18 和 ResNet50)之间进行蒸馏,也能将 ResNet18 的 mAP 提高 3.49,ResNet50 提高 2.43,这些是非常显著的提升。
对于跨结构蒸馏,如使用 ResNet50 教师和 MobileNetV2 学生,我们的框架也能将性能从 29.47 提升至 33.71。在一阶段检测器 RetinaNet [17] 上,尽管教师和学生之间差距本身就较小,我们的方法仍然带来了 2.33 的 mAP 增益。以上结果显示我们方法在目标检测任务中表现稳定、适用性广泛,具有强泛化能力。
4.3.Instance Segementation
本节中,我们将方法拓展到更具挑战性的实例分割任务。据我们所知,这是首次将知识蒸馏方法应用于实例分割中。我们同样基于 Detectron2 [33] 框架,以 Mask R-CNN [6] 为基础模型,进行不同骨干网络之间的蒸馏实验。

训练在 COCO2017 的训练集上完成,评估在验证集上进行。结果见表 5。实验表明,我们的方法在实例分割任务中也有显著提升。对于结构一致的蒸馏设置,ResNet18 和 ResNet50 分别提升 2.37 和 1.74,相当于将学生与教师之间的性能差距相对减少了 32% 和 51%。即便在结构不一致的设置(如 MobileNetV2)下,我们的方法依然可以将性能提升 3.19。
这些结果充分表明,我们提出的方法在图像分类、目标检测和实例分割这三类任务中都具有强大的适应性和高效性,并在所有任务中实现了当前最佳水平(SOTA)。
4.4. More Analysis
跨阶段的知识蒸馏
我们分析了跨阶段(stage-wise)的知识转移效果。在 CIFAR-100 数据集上,我们使用 ResNet20 作为学生模型,ResNet56 作为教师模型。两个网络都包含四个阶段(stage)。我们固定学生模型的一个阶段,然后尝试使用教师模型的不同阶段来进行监督。所有实验结果汇总在表 6 中。
该表清晰地展示了:当教师和学生的阶段保持一致时,蒸馏效果最佳。这与我们的直觉一致。此外,我们还观察到一个有趣的现象:使用教师的低层信息去监督学生的高层阶段同样具有积极作用。反过来,如果使用教师的高层特征去指导学生的低层阶段,则会显著降低学生模型的性能。
这说明,学生网络的深层阶段具备从教师浅层阶段中学习有效信息的能力。而反方向,即用教师更深层、更抽象的特征去监督学生浅层阶段,由于学生此时表达能力较弱,反而难以吸收过于复杂的语义信息,影响训练。这一观察与我们提出的“回顾机制”完全一致:用教师浅层知识来引导学生高层的学习更为有效。
消融实验
我们进行了系统性的消融实验,对本文提出的各个模块进行逐个叠加测试,以评估它们对最终性能的贡献。具体结果见表 7,表中包含模型在 CIFAR-100 上的准确率及其方差。
在实验中,我们采用 WRN16-2 作为学生模型,WRN40-2 作为教师模型。作为基线模型,我们使用了传统的 L2 距离,计算教师与学生相同层级特征之间的差异。
当引入我们提出的回顾机制(Review Mechanism, RM)后,模型准确率即获得提升。如第二行所示,此时使用的是图 2(b) 所示的简单结构。在此基础上,进一步引入残差学习框架(Residual Learning Framework, RLF),能够带来更大的性能增益。
随后,分别引入注意力融合模块(Attention-Based Fusion, ABF)和层次上下文损失函数(Hierarchical Context Loss, HCL),模型性能继续提升。最后,当我们将上述所有模块集成时,获得了最优性能,甚至超过了教师模型本身的表现。
5. Conclusion
在本文中,我们从一个全新的视角重新审视了知识蒸馏过程,并据此提出了一种名为**“回顾机制(Review Mechanism)”**的方法。该机制的核心思想是:使用教师网络的多个层级特征来监督学生网络的某一单独层级。通过引入这种跨层的信息传递方式,我们实现了显著的性能提升。
我们的蒸馏方法在图像分类、目标检测和实例分割等多个计算机视觉任务上都取得了持续稳定的性能增益,并且在所有任务中均达到了当前最优性能(state-of-the-art)。此外,值得注意的是,我们的方法仅利用教师模型的输出阶段特征(即各 stage 的输出),而非更复杂或精细的中间过程特征,便已实现了出色的蒸馏效果。
未来的工作方向包括:探索在阶段内部进一步提取细粒度特征以增强蒸馏效果,以及研究在当前框架下可进一步集成的其他类型损失函数,从而推动知识蒸馏方法向更高效、更广泛适用的方向发展。