CKA考试知识点分享(15)---etcd
CKA 版本:1.32
第十五套题是涉及etcd相关。
注意:本文不是题目,只是为了学习相关知识点做的实验。仅供参考
实验目的
排查故障
root@master01:~# kubectl get pod -A
E0614 10:43:21.150568 27978 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://11.0.1.111:6443/api?timeout=32s\": dial tcp 11.0.1.111:6443: connect: connection refused"
E0614 10:43:21.152191 27978 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://11.0.1.111:6443/api?timeout=32s\": dial tcp 11.0.1.111:6443: connect: connection refused"
E0614 10:43:21.153669 27978 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://11.0.1.111:6443/api?timeout=32s\": dial tcp 11.0.1.111:6443: connect: connection refused"
E0614 10:43:21.155226 27978 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://11.0.1.111:6443/api?timeout=32s\": dial tcp 11.0.1.111:6443: connect: connection refused"
E0614 10:43:21.156823 27978 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://11.0.1.111:6443/api?timeout=32s\": dial tcp 11.0.1.111:6443: connect: connection refused"
The connection to the server 11.0.1.111:6443 was refused - did you specify the right host or port?
root@master01:~#
实验开始
可以看到 11.0.1.111:6443 提示被拒绝,6443 是api-server的接口地址,我们首先确定api-server的运行状态。
crictl ps -a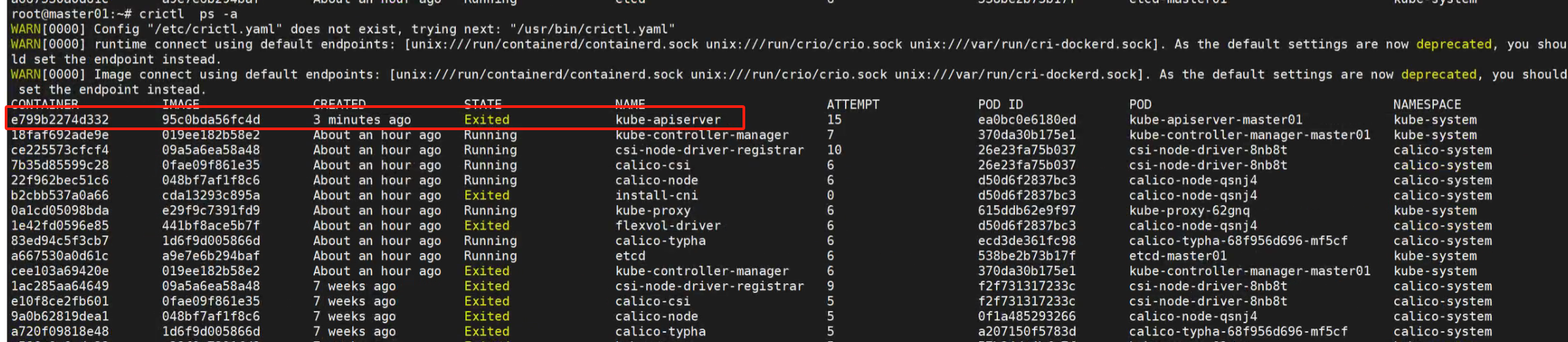
可以看到 api-server 是退出状态。
查看容器日志:
crictl logs -f e799b2274d332
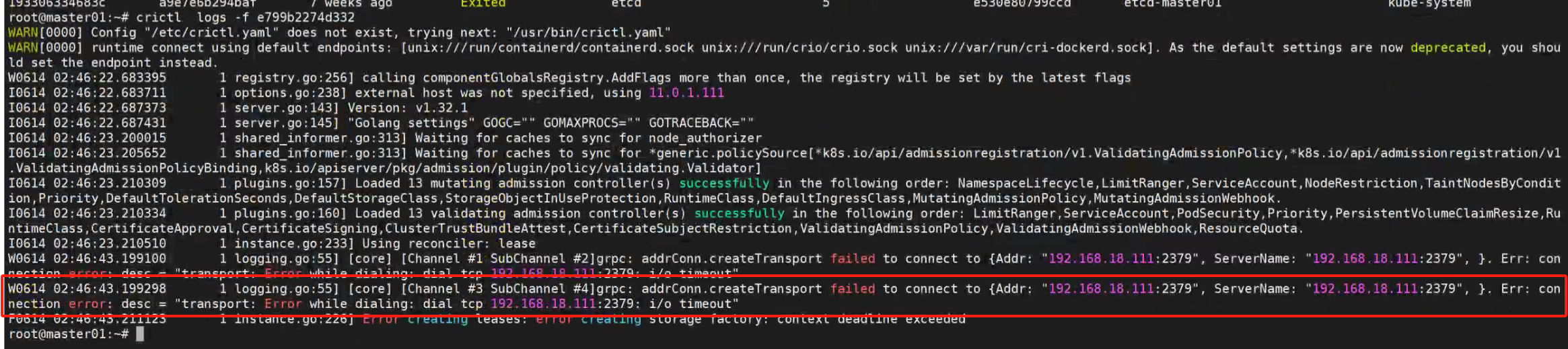
可以看到连接2379 端口错误,这个是etcd的相关接口。
检查etcd的配置,看到etcd的绑定端口ip和api-server访问的不一样。
crictl ps
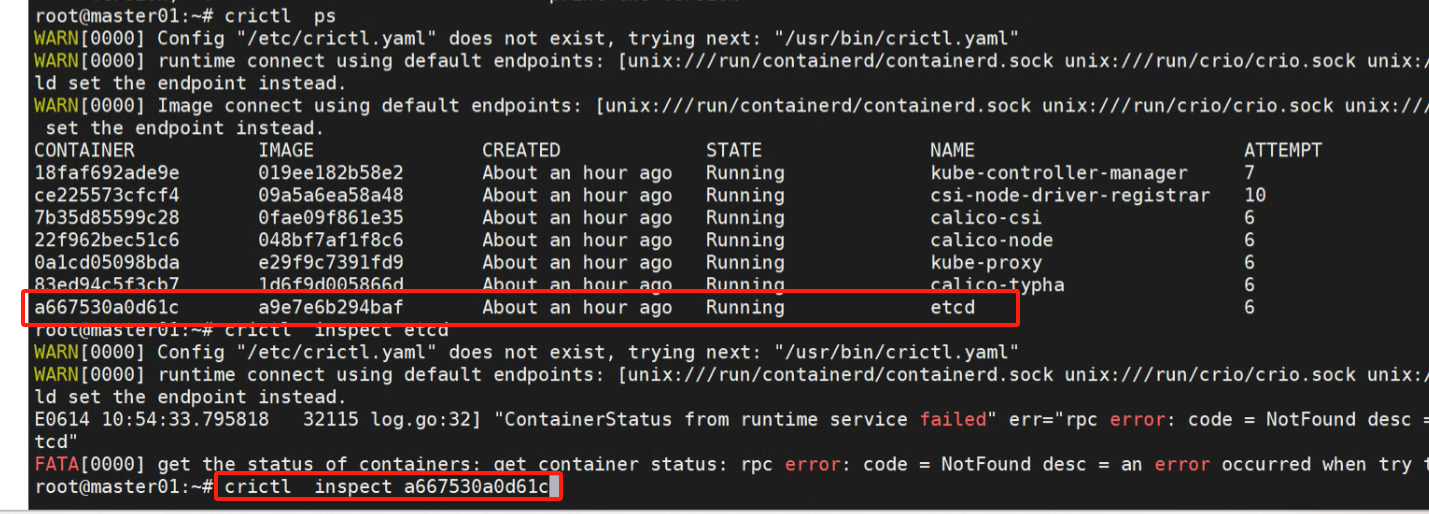
crictl inspect a667530a0d61c
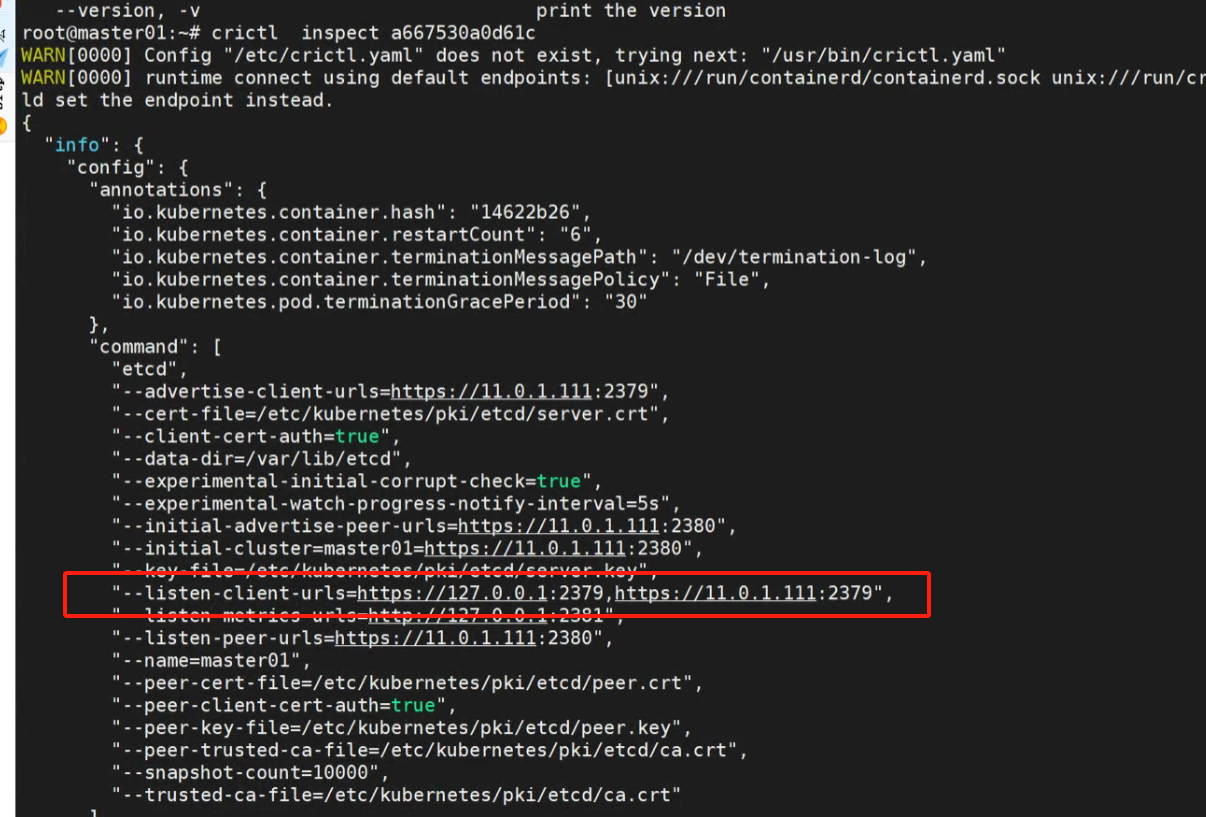
修改api-server的配置与etcd绑定的监控地址一样:
vim /etc/kubernetes/manifests/kube-apiserver.yaml
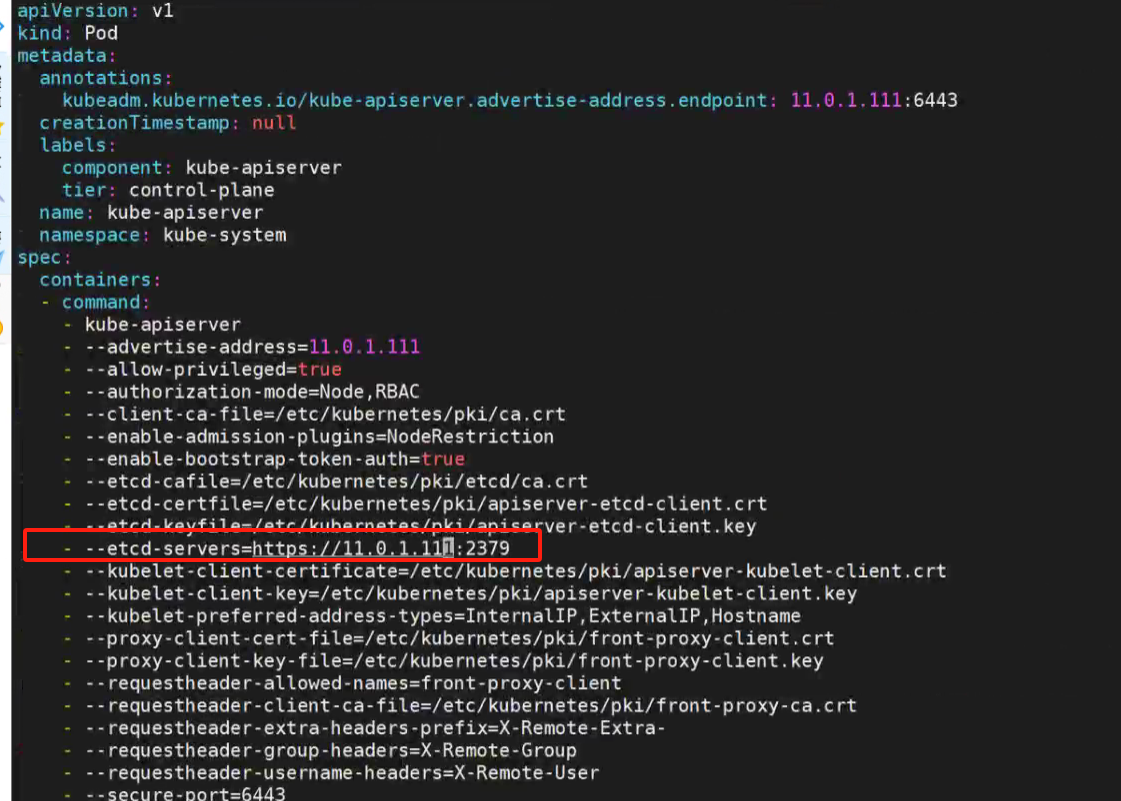
修改后,稍等一会,静态pod会重新创建。再次查看pod 运作状态。确定没有异常退出,api-server运行正常。
kubectl get pod -n kube-system
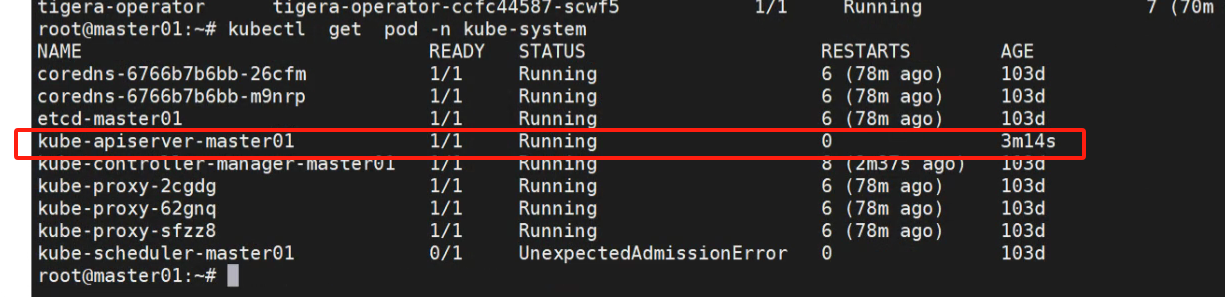
继续发现kube-scheduler-master01 提示错误。查看详细信息:
kubectl describe -n kube-system kube-scheduler-master01
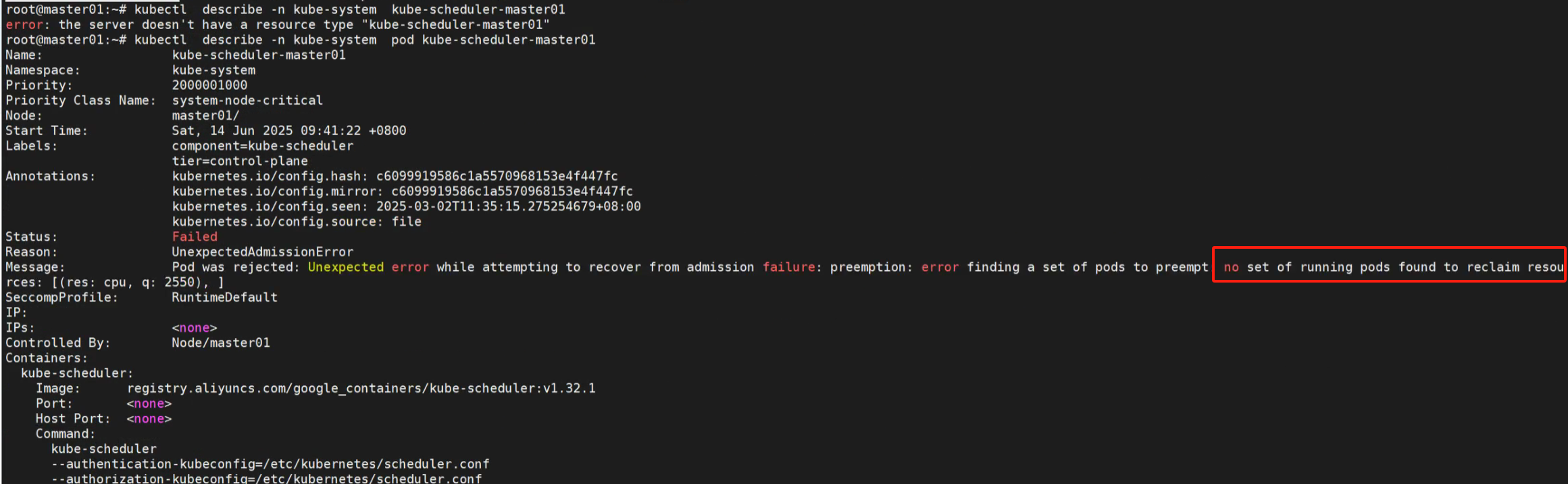
报错信息如下:
Pod was rejected: Unexpected error while attempting to recover from admission failure: preemption: error finding a set of pods to preempt: no set of running pods found to reclaim resources: [(res: cpu, q: 2550), ]
没办法回收资源调度这个pod。还需要2.5C的CPU。说明资源配置不合理,我们检查相关资源要求。
vim /etc/kubernetes/manifests/kube-scheduler.yaml
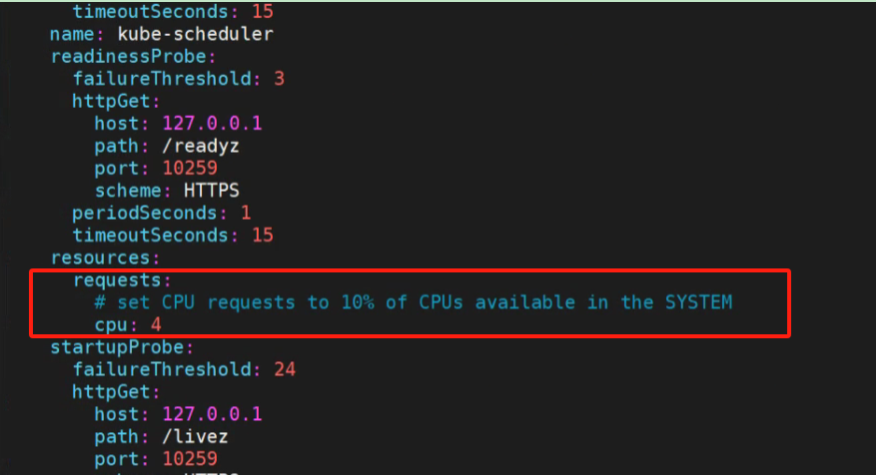
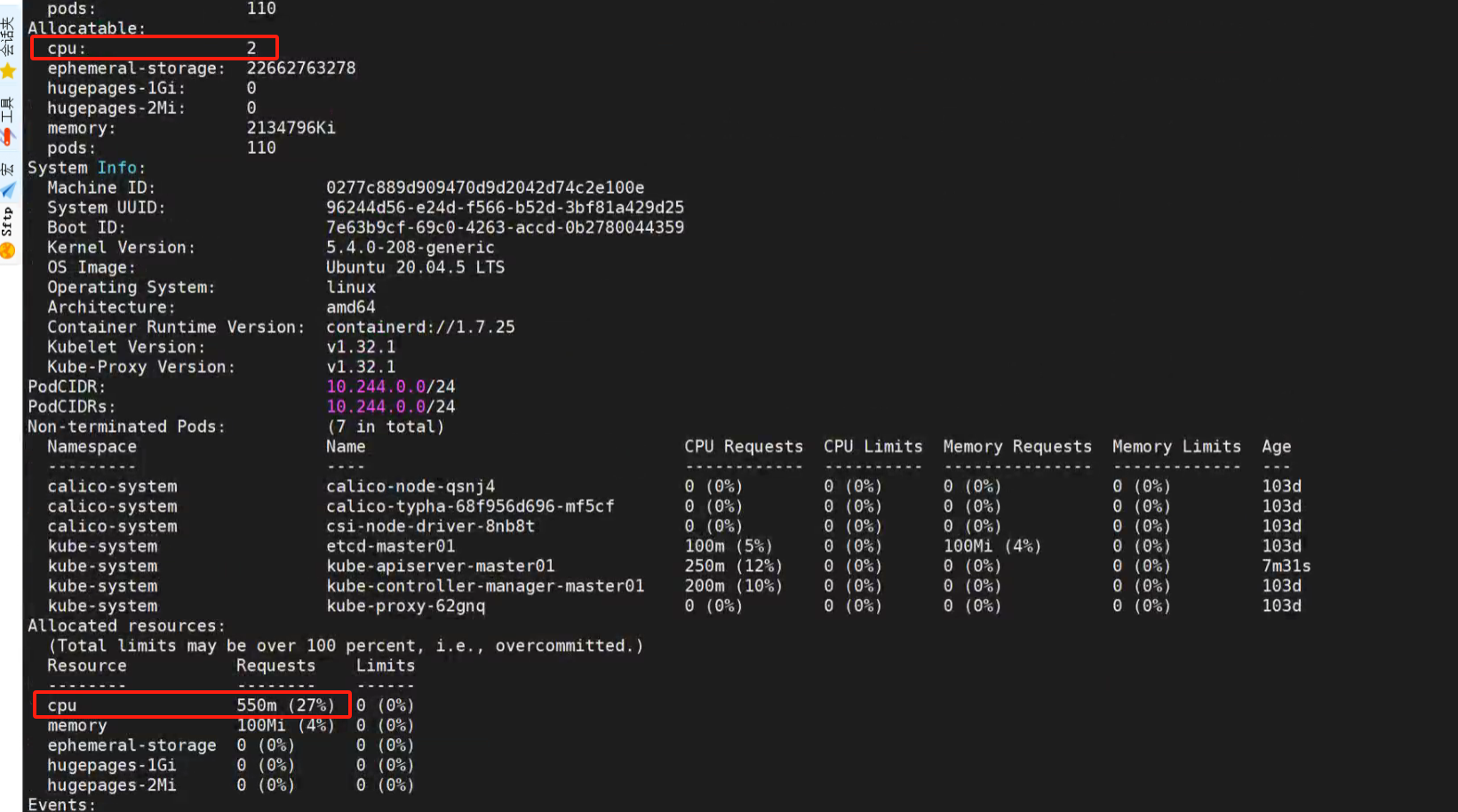
查看当前系统cpu情况:
总共2C 已经分配了550m,但是kube-scheduler 需要4C,实际资源只有1.5C。 缺少2.5C的CPU资源。所以不能成功调度。
修改资源申请为100m 就可以了。修改后再次查看pod状态,已经正常运行:
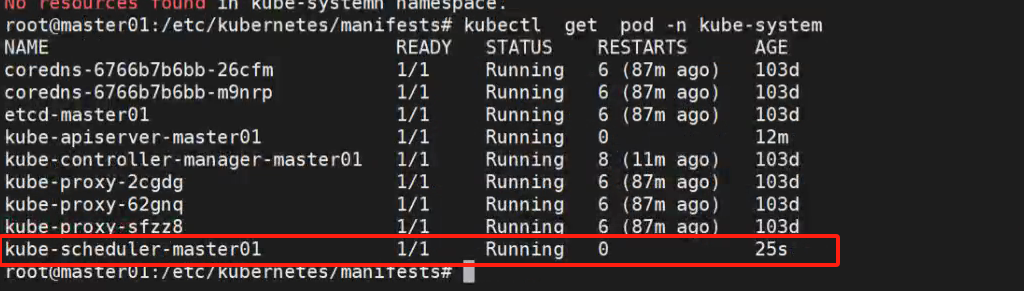
至此,所有pod成功运行,故障排查完毕。