【专业数据库探索 05】ArangoDB多模数据库革命:一个数据库解决文档图关系三大数据模型
【专业数据库探索 05】ArangoDB多模数据库革命:一个数据库解决文档图关系三大数据模型
关键词:ArangoDB、多模数据库、文档数据库、图数据库、关系数据库、NoSQL、GraphQL、一体化数据管理、异构数据存储、数据建模、AQL查询语言
摘要:在微服务和数据多样化的时代,企业经常面临"数据孤岛"问题:用户信息存在MySQL,产品评论在MongoDB,社交关系在Neo4j,不同数据库之间的数据同步和查询成为开发噩梦。ArangoDB作为革命性的多模数据库,在同一个引擎中原生支持文档、图、键值三种数据模型,让开发者告别多数据库运维困扰。本文通过费曼学习法,从"为什么电商平台需要5个数据库才能搞定用户画像"这个现实痛点出发,深入解析ArangoDB的核心原理和实际应用。我们将构建一个完整的社交电商平台,展示如何用一个ArangoDB替代传统的MySQL+MongoDB+Neo4j架构,实现统一的数据管理和复杂的关联查询。
为什么现代应用需要这么多数据库?
想象一个场景:你在开发一个社交电商平台,需要存储用户信息、商品数据、评论内容、用户关系、推荐算法…你会发现需要这样的技术栈:
用户基础信息 → MySQL (关系型数据库)
商品目录数据 → MongoDB (文档数据库)
用户社交关系 → Neo4j (图数据库)
购物车状态 → Redis (键值数据库)
搜索索引 → Elasticsearch (搜索引擎)
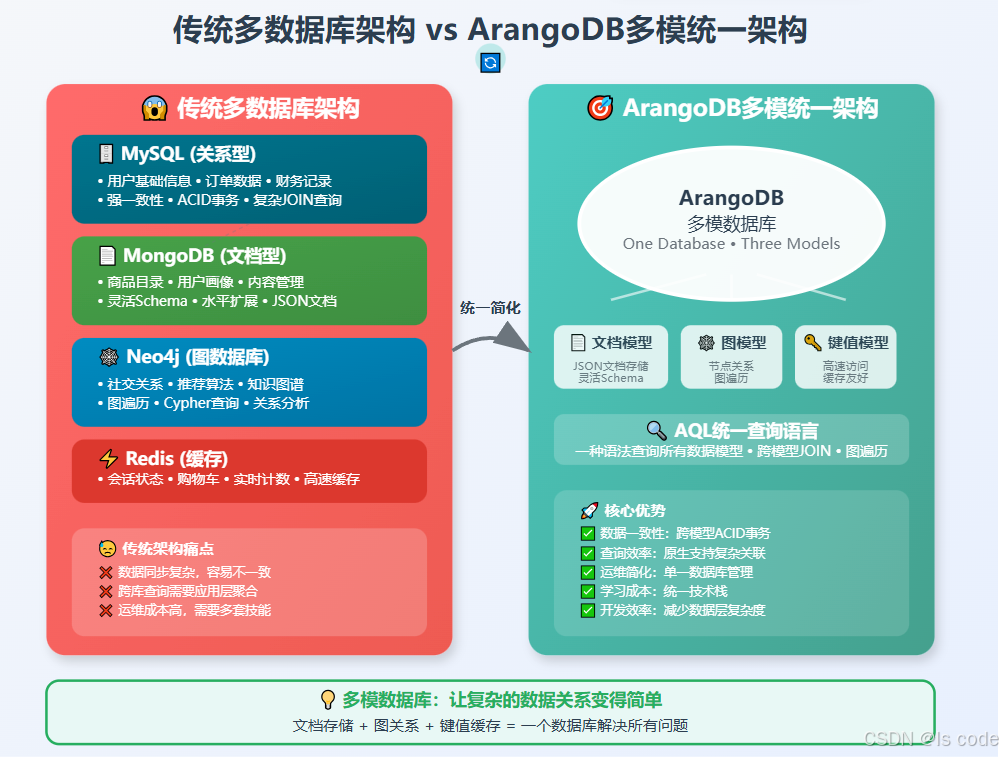
传统多数据库架构的痛点
数据同步噩梦:
# 传统方式:用户更新需要同步多个数据库
def update_user_profile(user_id, profile_data):# 1. 更新MySQL中的基础信息mysql_conn.execute("UPDATE users SET name=%s, email=%s WHERE id=%s",(profile_data['name'], profile_data['email'], user_id))# 2. 更新MongoDB中的详细档案mongo_db.users.update_one({"user_id": user_id},{"$set": {"profile": profile_data}})# 3. 更新Neo4j中的用户节点neo4j_session.run("MATCH (u:User {id: $user_id}) SET u.name = $name",user_id=user_id, name=profile_data['name'])# 如果任何一步失败,数据就不一致了!
复杂的关联查询:
# 获取用户的朋友购买的相同商品 - 需要跨3个数据库
def get_friends_same_purchases(user_id):# 1. 从Neo4j获取朋友关系friends = neo4j_query("MATCH (u:User)-[:FRIEND]->(f) WHERE u.id = $user_id", user_id)# 2. 从MySQL获取用户购买记录my_purchases = mysql_query("SELECT product_id FROM orders WHERE user_id = %s", user_id)# 3. 从MongoDB获取朋友们的购买记录和商品详情# ... 复杂的数据聚合逻辑# 4. 在应用层进行数据关联 - 性能和维护噩梦!
ArangoDB:多模数据库的革命性解决方案
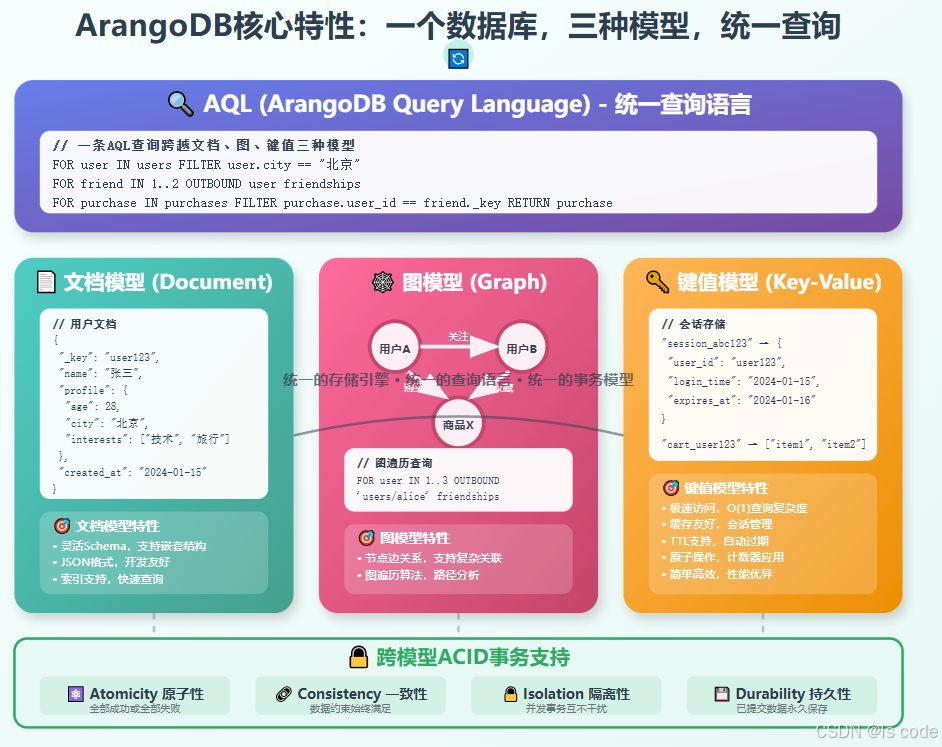
什么是多模数据库?
多模数据库就像一个"数据万能工具箱",在同一个存储引擎中支持多种数据模型:
// 同一个ArangoDB中的三种数据模型
// 1. 文档模型 - 类似MongoDB
db.users.save({_key: "user123",name: "张三",email: "zhangsan@example.com",profile: {age: 28,interests: ["技术", "旅行", "摄影"]}
});// 2. 图模型 - 类似Neo4j
db.friendships.save({_from: "users/user123",_to: "users/user456",since: "2023-01-15",strength: 0.8
});// 3. 键值模型 - 类似Redis
db.sessions.save({_key: "session_abc123",user_id: "user123",expires_at: "2024-01-15T10:30:00Z"
});
ArangoDB的核心优势
1. 统一的查询语言 (AQL)
// 一条AQL查询搞定复杂的关联需求
FOR user IN usersFILTER user._key == "user123"FOR friend IN 1..1 OUTBOUND user friendshipsFOR purchase IN purchasesFILTER purchase.user_id == friend._keyFOR product IN productsFILTER product._key == purchase.product_idCOLLECT product_name = product.name WITH COUNT INTO purchase_countSORT purchase_count DESCLIMIT 10RETURN {product: product_name,friend_purchases: purchase_count}
2. ACID事务支持
// 跨文档和图的原子性事务
db._executeTransaction({collections: {write: ["users", "orders", "friendships"]},action: function() {const users = require("@arangodb/users");// 创建用户const user = users.save({name: "新用户"});// 创建订单const order = orders.save({user_id: user._key,total: 299.99});// 建立朋友关系friendships.save({_from: `users/${user._key}`,_to: "users/existing_user",created_at: new Date()});return {success: true, user_id: user._key};}
});
实战项目:构建社交电商平台
让我们通过构建一个完整的社交电商平台来掌握ArangoDB的实际应用。
环境搭建与数据建模
Docker安装ArangoDB
# 快速启动ArangoDB
docker run -d \--name arangodb \-p 8529:8529 \-e ARANGO_ROOT_PASSWORD=your_password \arangodb:3.11# 验证安装
curl http://localhost:8529/_api/version
Python开发环境
# pip install python-arango pandasfrom arango import ArangoClient
import json
from datetime import datetime, timedelta
from typing import List, Dict, Optionalclass SocialEcommerceDB:def __init__(self, hosts='http://localhost:8529', username='root', password='your_password'):# 连接ArangoDBself.client = ArangoClient(hosts=hosts)self.sys_db = self.client.db('_system', username=username, password=password)# 创建或连接数据库if not self.sys_db.has_database('social_ecommerce'):self.sys_db.create_database('social_ecommerce')self.db = self.client.db('social_ecommerce', username=username, password=password)# 初始化数据结构self.init_collections()def init_collections(self):"""初始化集合和图结构"""# 文档集合 (类似MongoDB的Collection)collections = ['users', # 用户信息'products', # 商品信息'orders', # 订单信息'reviews', # 评论信息'categories' # 商品分类]for collection_name in collections:if not self.db.has_collection(collection_name):self.db.create_collection(collection_name)# 边集合 (图关系)edge_collections = ['friendships', # 用户关系'follows', # 关注关系'purchases', # 购买关系'likes', # 点赞关系'belongs_to', # 商品分类关系'recommends' # 推荐关系]for edge_name in edge_collections:if not self.db.has_collection(edge_name):self.db.create_collection(edge_name, edge=True)# 创建图if not self.db.has_graph('social_network'):self.db.create_graph('social_network',edge_definitions=[{'edge_collection': 'friendships','from_vertex_collections': ['users'],'to_vertex_collections': ['users']},{'edge_collection': 'follows','from_vertex_collections': ['users'],'to_vertex_collections': ['users']},{'edge_collection': 'purchases','from_vertex_collections': ['users'],'to_vertex_collections': ['products']},{'edge_collection': 'likes','from_vertex_collections': ['users'],'to_vertex_collections': ['products', 'reviews']}])print("数据库初始化完成!")
核心业务功能实现
用户管理与社交关系
def create_user(self, user_data: Dict) -> str:"""创建用户"""user_doc = {'name': user_data['name'],'email': user_data['email'],'phone': user_data.get('phone'),'profile': {'avatar': user_data.get('avatar'),'bio': user_data.get('bio', ''),'interests': user_data.get('interests', []),'location': user_data.get('location')},'stats': {'friends_count': 0,'orders_count': 0,'reviews_count': 0},'created_at': datetime.now().isoformat(),'updated_at': datetime.now().isoformat()}result = self.db.collection('users').insert(user_doc)return result['_key']def add_friendship(self, user1_key: str, user2_key: str, relationship_type: str = 'friend'):"""建立用户关系"""friendship = {'_from': f'users/{user1_key}','_to': f'users/{user2_key}','type': relationship_type,'created_at': datetime.now().isoformat(),'strength': 1.0 # 关系强度,可用于推荐算法}# 双向关系self.db.collection('friendships').insert(friendship)# 反向关系reverse_friendship = friendship.copy()reverse_friendship['_from'] = f'users/{user2_key}'reverse_friendship['_to'] = f'users/{user1_key}'self.db.collection('friendships').insert(reverse_friendship)# 更新用户统计self._update_user_stats(user1_key, 'friends_count', 1)self._update_user_stats(user2_key, 'friends_count', 1)def get_user_social_network(self, user_key: str, depth: int = 2) -> Dict:"""获取用户社交网络"""aql = """FOR user IN usersFILTER user._key == @user_keyLET direct_friends = (FOR friend IN 1..1 OUTBOUND user friendshipsRETURN {_key: friend._key,name: friend.name,profile: friend.profile})LET mutual_friends = (FOR friend IN 2..2 OUTBOUND user friendshipsCOLLECT friend_key = friend._key, friend_name = friend.name WITH COUNT INTO mutual_countFILTER mutual_count > 1RETURN {_key: friend_key,name: friend_name,mutual_connections: mutual_count})RETURN {user: user,direct_friends: direct_friends,mutual_friends: mutual_friends,network_size: LENGTH(direct_friends)}"""cursor = self.db.aql.execute(aql, bind_vars={'user_key': user_key})return next(cursor, None)
商品管理与分类
def create_product(self, product_data: Dict) -> str:"""创建商品"""product_doc = {'name': product_data['name'],'description': product_data['description'],'price': product_data['price'],'category': product_data['category'],'brand': product_data.get('brand'),'images': product_data.get('images', []),'attributes': product_data.get('attributes', {}),'inventory': {'stock': product_data.get('stock', 0),'reserved': 0,'sold': 0},'stats': {'views': 0,'likes': 0,'reviews_count': 0,'average_rating': 0.0},'created_at': datetime.now().isoformat(),'updated_at': datetime.now().isoformat()}result = self.db.collection('products').insert(product_doc)product_key = result['_key']# 建立商品与分类的关系if product_data.get('category'):self._link_product_to_category(product_key, product_data['category'])return product_keydef _link_product_to_category(self, product_key: str, category_name: str):"""建立商品与分类的关系"""# 确保分类存在category_key = self._ensure_category_exists(category_name)# 建立关系belongs_to_edge = {'_from': f'products/{product_key}','_to': f'categories/{category_key}','created_at': datetime.now().isoformat()}self.db.collection('belongs_to').insert(belongs_to_edge)def get_category_products(self, category_name: str, limit: int = 20) -> List[Dict]:"""获取分类下的商品"""aql = """FOR category IN categoriesFILTER category.name == @category_nameFOR product IN 1..1 INBOUND category belongs_toSORT product.stats.views DESC, product.created_at DESCLIMIT @limitRETURN {_key: product._key,name: product.name,price: product.price,brand: product.brand,stats: product.stats,images: product.images[0]}"""cursor = self.db.aql.execute(aql, bind_vars={'category_name': category_name,'limit': limit})return list(cursor)
智能推荐系统
def get_personalized_recommendations(self, user_key: str, limit: int = 10) -> List[Dict]:"""基于社交关系和购买历史的个性化推荐"""aql = """FOR user IN usersFILTER user._key == @user_key// 获取用户的朋友LET friends = (FOR friend IN 1..1 OUTBOUND user friendshipsRETURN friend._key)// 获取用户已购买的商品LET purchased_products = (FOR product IN 1..1 OUTBOUND user purchasesRETURN product._key)// 获取朋友们购买的商品(排除自己已买的)LET friend_purchases = (FOR friend_key IN friendsFOR product IN 1..1 OUTBOUND DOCUMENT(CONCAT('users/', friend_key)) purchasesFILTER product._key NOT IN purchased_productsCOLLECT product_key = product._key WITH COUNT INTO purchase_countRETURN {product_key: product_key,friend_purchase_count: purchase_count})// 获取同类商品推荐LET category_recommendations = (FOR purchased_key IN purchased_productsFOR product IN productsFILTER product._key == purchased_keyFOR category IN 1..1 OUTBOUND product belongs_toFOR similar_product IN 1..1 INBOUND category belongs_toFILTER similar_product._key NOT IN purchased_productsFILTER similar_product._key != product._keyCOLLECT similar_key = similar_product._key WITH COUNT INTO category_matchRETURN {product_key: similar_key,category_score: category_match})// 合并推荐结果LET all_recommendations = UNION(friend_purchases, category_recommendations)// 计算最终推荐分数FOR rec IN all_recommendationsCOLLECT product_key = rec.product_key AGGREGATE friend_score = SUM(rec.friend_purchase_count || 0),category_score = SUM(rec.category_score || 0)LET final_score = friend_score * 2 + category_score * 1FOR product IN productsFILTER product._key == product_keySORT final_score DESC, product.stats.average_rating DESCLIMIT @limitRETURN {product: product,recommendation_score: final_score,friend_influence: friend_score,category_similarity: category_score}"""cursor = self.db.aql.execute(aql, bind_vars={'user_key': user_key,'limit': limit})return list(cursor)def create_order_with_social_context(self, user_key: str, order_data: Dict) -> str:"""创建订单并记录社交上下文"""order_doc = {'user_id': user_key,'items': order_data['items'], # [{product_key, quantity, price}]'total_amount': order_data['total_amount'],'shipping_address': order_data['shipping_address'],'payment_method': order_data['payment_method'],'status': 'pending','social_context': {'recommended_by_friends': order_data.get('friend_recommendations', []),'influenced_by': order_data.get('social_proof', [])},'created_at': datetime.now().isoformat()}# 创建订单result = self.db.collection('orders').insert(order_doc)order_key = result['_key']# 建立用户与商品的购买关系for item in order_data['items']:purchase_edge = {'_from': f'users/{user_key}','_to': f'products/{item["product_key"]}','order_id': order_key,'quantity': item['quantity'],'price': item['price'],'purchased_at': datetime.now().isoformat()}self.db.collection('purchases').insert(purchase_edge)# 更新用户统计self._update_user_stats(user_key, 'orders_count', 1)return order_key
高级查询与分析
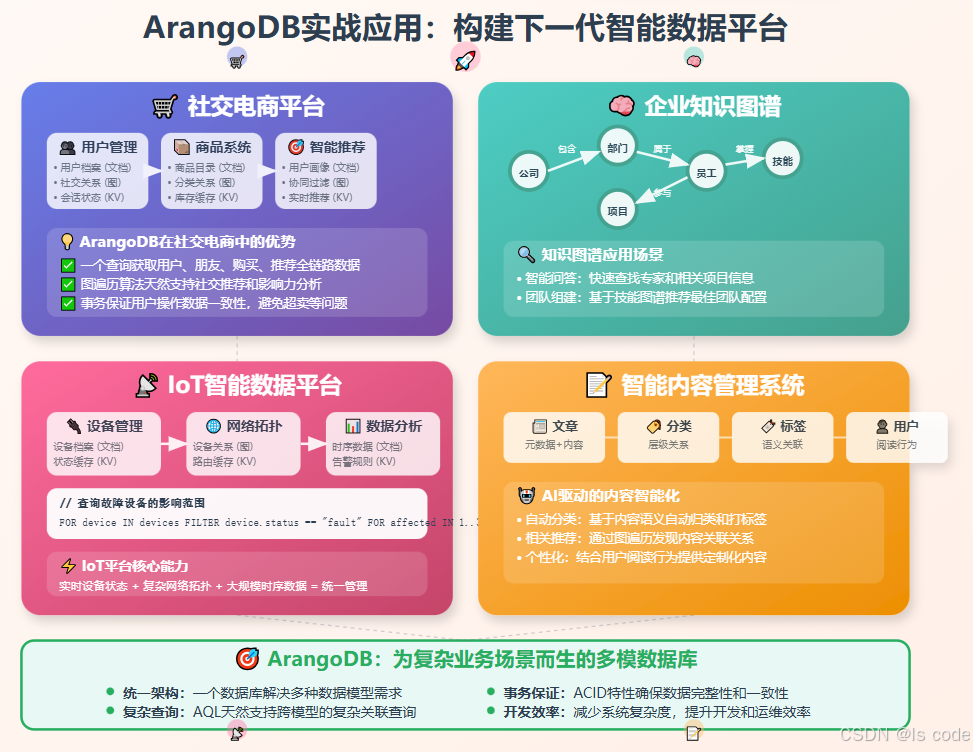
社交影响力分析
def analyze_social_influence(self, limit: int = 10) -> List[Dict]:"""分析用户社交影响力"""aql = """FOR user IN users// 计算直接影响力 (朋友数量)LET direct_friends = LENGTH(FOR friend IN 1..1 OUTBOUND user friendshipsRETURN friend)// 计算间接影响力 (朋友的朋友数)LET indirect_influence = SUM(FOR friend IN 1..1 OUTBOUND user friendshipsLET friend_count = LENGTH(FOR ff IN 1..1 OUTBOUND friend friendshipsFILTER ff._key != user._keyRETURN ff)RETURN friend_count)// 计算购买影响力 (朋友购买了该用户推荐的商品)LET purchase_influence = LENGTH(FOR friend IN 1..1 OUTBOUND user friendshipsFOR product IN 1..1 OUTBOUND friend purchasesFOR my_product IN 1..1 OUTBOUND user purchasesFILTER product._key == my_product._keyRETURN product)// 计算综合影响力分数LET influence_score = direct_friends * 1 + (indirect_influence / 100) * 0.5 + purchase_influence * 3SORT influence_score DESCLIMIT @limitRETURN {user: {_key: user._key,name: user.name,profile: user.profile},influence_metrics: {direct_friends: direct_friends,indirect_influence: indirect_influence,purchase_influence: purchase_influence,total_score: influence_score}}"""cursor = self.db.aql.execute(aql, bind_vars={'limit': limit})return list(cursor)def get_trending_products(self, time_range_days: int = 7, limit: int = 20) -> List[Dict]:"""获取趋势商品(基于社交传播)"""aql = """LET date_threshold = DATE_ADD(DATE_NOW(), -@days, 'day')FOR product IN products// 计算最近购买次数LET recent_purchases = LENGTH(FOR purchase IN purchasesFILTER purchase._to == product._idFILTER DATE_ISO8601(purchase.purchased_at) >= date_thresholdRETURN purchase)// 计算社交传播度(不同社交圈的购买)LET social_spread = LENGTH(FOR purchase IN purchasesFILTER purchase._to == product._idFILTER DATE_ISO8601(purchase.purchased_at) >= date_thresholdLET user = DOCUMENT(purchase._from)// 获取购买用户的朋友圈LET user_network = (FOR friend IN 1..1 OUTBOUND user friendshipsRETURN friend._key)COLLECT network_id = user_network[0] WITH COUNT INTO network_purchasesRETURN network_id)// 计算趋势分数LET trend_score = recent_purchases * 2 + social_spread * 3 + product.stats.likes * 1FILTER trend_score > 0SORT trend_score DESC, recent_purchases DESCLIMIT @limitRETURN {product: product,trend_metrics: {recent_purchases: recent_purchases,social_spread: social_spread,trend_score: trend_score}}"""cursor = self.db.aql.execute(aql, bind_vars={'days': time_range_days,'limit': limit})return list(cursor)# 使用示例
social_ecommerce = SocialEcommerceDB()# 创建用户
user1_key = social_ecommerce.create_user({'name': '张三','email': 'zhangsan@example.com','interests': ['数码', '摄影', '旅行']
})user2_key = social_ecommerce.create_user({'name': '李四','email': 'lisi@example.com','interests': ['时尚', '美食', '健身']
})# 建立社交关系
social_ecommerce.add_friendship(user1_key, user2_key)# 创建商品
product_key = social_ecommerce.create_product({'name': 'iPhone 15 Pro','description': '最新款iPhone,拍照功能强大','price': 8999,'category': '数码电子','brand': 'Apple','stock': 100
})# 获取个性化推荐
recommendations = social_ecommerce.get_personalized_recommendations(user1_key)
print("个性化推荐结果:", recommendations)# 分析社交影响力
influence_analysis = social_ecommerce.analyze_social_influence()
print("社交影响力排行:", influence_analysis)
性能优化与最佳实践
索引策略优化
def optimize_database_indexes(self):"""优化数据库索引"""# 用户集合索引self.db.collection('users').add_index({'type': 'persistent','fields': ['email'],'unique': True})self.db.collection('users').add_index({'type': 'persistent', 'fields': ['profile.interests[*]'] # 多值索引})# 商品集合索引self.db.collection('products').add_index({'type': 'persistent','fields': ['category', 'price']})self.db.collection('products').add_index({'type': 'persistent','fields': ['stats.average_rating', 'stats.reviews_count']})# 订单集合索引self.db.collection('orders').add_index({'type': 'persistent','fields': ['user_id', 'created_at']})# 边集合索引self.db.collection('purchases').add_index({'type': 'persistent','fields': ['purchased_at']})print("数据库索引优化完成!")def setup_ttl_indexes(self):"""设置TTL索引自动清理过期数据"""# 会话数据30天过期self.db.collection('sessions').add_index({'type': 'ttl','fields': ['created_at'],'expireAfter': 2592000 # 30天 (秒)})# 临时推荐数据7天过期self.db.collection('temp_recommendations').add_index({'type': 'ttl','fields': ['created_at'],'expireAfter': 604800 # 7天})
查询性能优化
def optimized_friend_recommendations(self, user_key: str, limit: int = 10):"""优化的朋友推荐查询"""aql = """FOR user IN usersFILTER user._key == @user_key// 使用索引快速获取朋友LET direct_friends = (FOR v, e IN 1..1 OUTBOUND user friendshipsOPTIONS {bfs: true, uniqueVertices: 'global'}RETURN v._key)// 朋友的朋友 - 排除已有朋友FOR friend IN direct_friendsFOR potential_friend IN 1..1 OUTBOUND DOCUMENT(CONCAT('users/', friend)) friendshipsFILTER potential_friend._key != user._keyFILTER potential_friend._key NOT IN direct_friendsCOLLECT friend_key = potential_friend._key WITH COUNT INTO mutual_countFILTER mutual_count >= 2 // 至少2个共同朋友SORT mutual_count DESCLIMIT @limitLET friend_doc = DOCUMENT(CONCAT('users/', friend_key))RETURN {user: friend_doc,mutual_friends: mutual_count,common_interests: LENGTH(INTERSECTION(user.profile.interests, friend_doc.profile.interests))}"""cursor = self.db.aql.execute(aql, bind_vars={'user_key': user_key,'limit': limit})return list(cursor)
ArangoDB与其他数据库对比
功能对比矩阵
| 特性 | ArangoDB | MongoDB + Neo4j + Redis | MySQL + ES |
|---|---|---|---|
| 数据模型 | 文档+图+KV统一 | 分离的多个数据库 | 关系+搜索分离 |
| 查询语言 | 统一AQL | MongoDB查询+Cypher+Redis命令 | SQL+DSL |
| 事务支持 | 跨模型ACID | 各自独立事务 | 有限跨库事务 |
| 运维复杂度 | 低 (单数据库) | 高 (多数据库同步) | 中等 |
| 学习成本 | 中等 (学习AQL) | 高 (多套语法) | 高 |
| 性能表现 | 优秀 | 需要应用层聚合 | 复杂查询慢 |
选型决策框架
def recommend_database_solution(requirements: Dict) -> str:"""数据库选型建议"""score = {'arangodb': 0,'traditional_stack': 0,'specialized_dbs': 0}# 数据模型复杂度if requirements.get('multiple_data_models', False):score['arangodb'] += 3score['traditional_stack'] -= 1# 查询复杂度 if requirements.get('complex_relationships', False):score['arangodb'] += 3score['specialized_dbs'] += 1# 团队规模和运维能力if requirements.get('small_team', False):score['arangodb'] += 2score['traditional_stack'] -= 2# 性能要求if requirements.get('high_performance', False):score['arangodb'] += 2score['specialized_dbs'] += 2# 数据一致性要求if requirements.get('strict_consistency', False):score['arangodb'] += 3score['traditional_stack'] += 1best_choice = max(score.items(), key=lambda x: x[1])return best_choice[0]# 使用示例
requirements = {'multiple_data_models': True,'complex_relationships': True, 'small_team': True,'high_performance': True,'strict_consistency': True
}recommendation = recommend_database_solution(requirements)
print(f"推荐方案: {recommendation}")
总结与展望
ArangoDB的核心价值
- 架构简化:一个数据库替代多个专业数据库,减少系统复杂度
- 开发效率:统一的AQL查询语言,减少学习和维护成本
- 数据一致性:跨模型的ACID事务,确保数据完整性
- 查询性能:原生支持复杂关联查询,无需应用层数据聚合
最佳适用场景
推荐使用ArangoDB的场景:
- 社交网络应用(用户关系+内容管理)
- 电商平台(商品目录+用户行为+推荐系统)
- 知识图谱应用(实体+关系+属性统一管理)
- IoT数据平台(设备信息+时序数据+关系网络)
需要谨慎考虑的场景:
- 纯粹的大规模分析型负载(可能需要专门的OLAP数据库)
- 极高并发的简单查询(可能Redis等专业KV数据库更合适)
- 遗留系统改造(迁移成本和风险需要评估)
技术发展趋势
ArangoDB的演进方向:
- 云原生增强:更好的Kubernetes集成和多云部署
- 机器学习集成:内置图算法和ML pipeline
- 实时流处理:集成流计算能力,支持实时数据处理
- 多模态AI:结合向量搜索,支持AI应用的复杂数据需求
学习路径建议
初学者路径:
- 掌握基础的文档操作(类似MongoDB)
- 学习AQL查询语法和图遍历
- 理解事务和一致性模型
- 实践复杂的多模型查询
进阶路径:
- 性能调优和索引设计
- 集群部署和高可用架构
- 与微服务架构的集成
- 自定义Foxx微服务开发
ArangoDB作为多模数据库的代表,为现代应用的复杂数据需求提供了一个优雅的解决方案。虽然它不能解决所有数据库问题,但在适合的场景下,它能够显著简化架构、提高开发效率、降低运维成本。
选择ArangoDB,就是选择了一种更简洁、更统一的数据管理方式。在数据多样化的时代,这种统一性正是许多企业迫切需要的。
扩展阅读:
- ArangoDB官方文档
- AQL查询语言教程
- 多模数据库设计模式
- ArangoDB最佳实践指南