论文阅读:arxiv 2025 Chain of Draft: Thinking Faster by Writing Less
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://www.doubao.com/chat/8749714891935490
https://arxiv.org/pdf/2502.18600
Chain of Draft: Thinking Faster by Writing Less
速览
这篇论文提出了一种名为“Chain of Draft(CoD)”的新方法,核心是让大语言模型在推理时用更简洁的中间步骤,就像人类解决问题时记要点而非详细步骤一样。以下是对文档内容的通俗解读:
1. 研究背景
- 大语言模型的推理方式:像GPT-4这样的大语言模型,在解决复杂问题时常用“Chain of Thought(CoT)”方法,即一步步详细推理,比如算数学题时把每一步都写得清清楚楚。这种方法确实有效,但会产生大量冗余内容,增加计算成本和响应延迟。
- 人类的推理习惯:人类解决问题时更倾向于记“要点”,比如算题时只写关键公式和中间结果,不会啰嗦地解释每一步。CoD就是受此启发,让模型用更简洁的方式推理。
2. CoD的核心思路
- 减少冗余,聚焦关键:CoD要求模型在推理时每个步骤最多用5个词,只保留对解题最关键的信息。比如算“20个棒棒糖给了Denny一些后剩12个,给了多少个”,CoT会详细解释“初始有20个,给了之后剩12个,所以用减法……”,而CoD直接写“20 - x = 12;x = 8”。
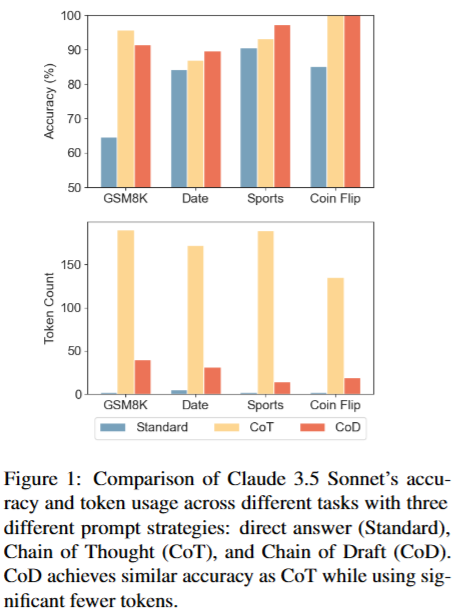
- 效果:在多个推理任务中,CoD的准确率和CoT相当甚至更高,但用的token(可以理解为“字数”)只有CoT的7.6%左右,大大降低了计算成本和延迟。
3. 实验验证
- 测试任务:涵盖算术推理(如GSM8K数学题)、常识推理(如日期和体育知识理解)、符号推理(如硬币翻转预测)。
- 主要结果:
- 算术推理:GPT-4o和Claude 3.5用CoD时准确率约91%,接近CoT的95%,但token用量减少80%,延迟降低约70%。
- 常识推理:在体育理解任务中,Claude 3.5用CoD的token用量从189.4骤降至14.3,准确率反而从87%提升到89.7%。
- 符号推理:CoD和CoT都能达到100%准确率,但CoD的token用量少68%-86%。
4. 局限性
- 零样本场景表现差:如果不给模型示例,直接让它用CoD推理,准确率会明显下降。比如Claude 3.5在零样本GSM8K测试中,CoD仅比直接回答高3.6%。
- 小模型效果有限:在参数小于30亿的小模型(如Qwen2.5、Llama 3.2)上,CoD虽然能减少token用量,但准确率比CoT低不少,可能因为小模型训练数据中缺乏CoD式的推理模式。
5. 实际意义
- 成本与效率优势:CoD能大幅降低大模型的使用成本,比如企业部署时可减少算力消耗,同时让模型响应更快,适合实时应用(如对话机器人、实时问答系统)。
- 未来方向:可以和其他优化方法(如并行推理)结合,进一步提升效率;也可以通过专门训练让小模型更好地适应CoD。
总结
CoD证明了大模型推理不必“啰嗦”,用简洁的“要点式”思考既能保证准确性,又能显著提升效率、降低成本,为大模型的实际应用(尤其是对延迟和成本敏感的场景)提供了新方向。