论文阅读:arxiv 2025 Not All Tokens Are What You Need In Thinking
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2505.17827
https://www.doubao.com/chat/8814790364572162
文章目录
- 速览
- 研究背景
- 提出的解决方案:条件token选择(CTS)
- 实验结果
- 核心贡献
- 研究局限
- 总结
速览
这篇论文主要探讨了如何优化大型语言模型在推理过程中产生的冗长思维链(CoT),以提高模型的效率。
研究背景
- 问题发现:像OpenAI的o1和DeepSeek-R1这类先进的推理模型,虽然解决问题的能力很强,但存在明显的效率问题,比如推理时延迟高、消耗大量计算资源,还容易“过度思考”,生成的思维链里有很多冗余的token(语言模型的基本处理单元,比如词语或子词),这些冗余内容对得出最终答案没什么太大帮助。
- 现有方法不足:之前的一些压缩方法,在处理较短的思维链时还能起作用,但面对强化学习生成的长达数千token的长思维链数据时,就无法有效应对了,而且它们还忽略了问题和答案等关键的上下文信息。
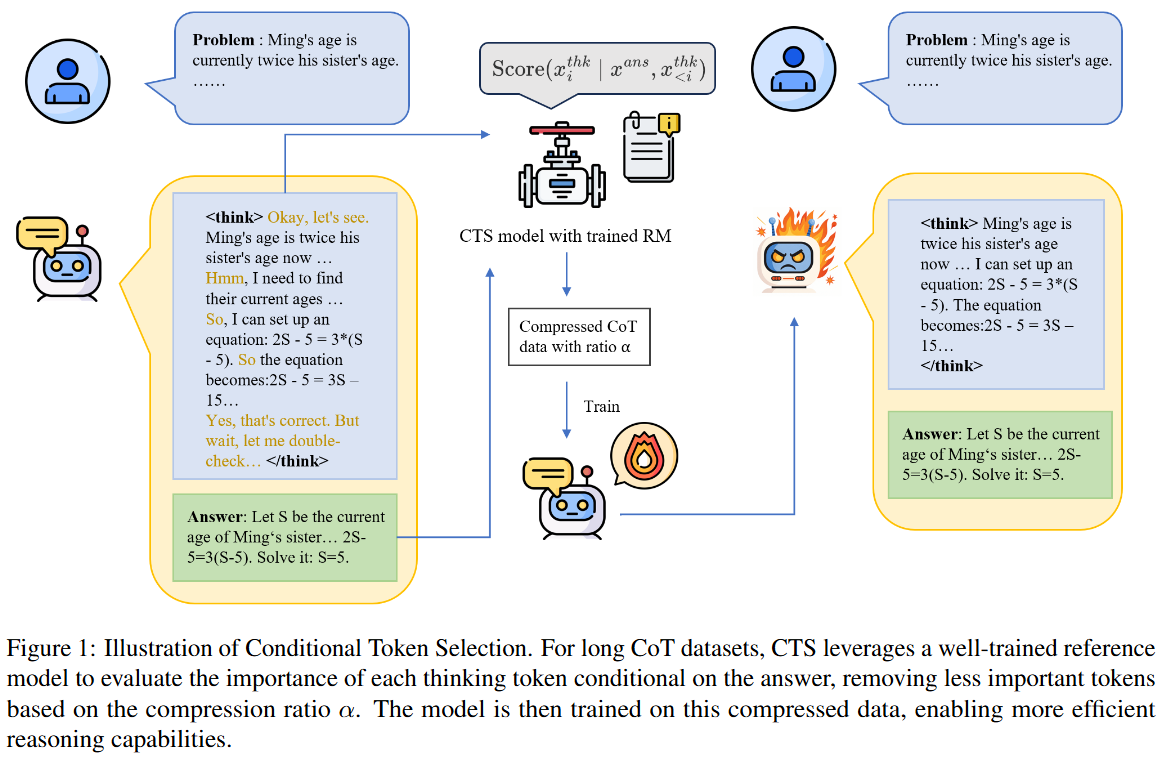
提出的解决方案:条件token选择(CTS)
- 核心思路:CTS是一个token层面的压缩框架,它能根据不同需求灵活调整压缩比例,只识别和保留思维链中对得出正确答案最关键的token,把冗余的部分去掉。
- 具体做法:
- 重要性评分:利用一个在高质量推理语料库上训练好的参考模型(RM),基于问题和答案等关键上下文,给每个token计算条件重要性分数,以此评估每个token对推导正确答案的贡献。
- 压缩与训练:按照设定的压缩比例过滤掉不重要的token,得到压缩后的思维链数据,然后用这些数据对模型进行微调,让模型在推理时学会跳过不必要的token。
实验结果
- 效率与准确性提升:在GPQA基准测试上,用CTS训练的Qwen2.5 - 14B - Instruct模型,推理token减少了13.2%(训练token减少13%),同时准确性提高了9.1%。
- 压缩潜力验证:当训练token减少42%时,虽然准确性只下降了5%,但推理token大幅减少了75.8%,这充分说明现有的思维链数据中存在大量冗余。
- 广泛有效性:在MATH500、AIME24等其他基准测试以及Llama - 3.1 - 8B - Instruct等不同模型上,使用CTS压缩后的训练数据进行训练,模型的准确性都比使用原始数据有所提高。
核心贡献
- 框架创新:提出了CTS框架,能根据上下文给思维链中的token赋予条件重要性分数,按不同压缩比例选择性保留关键推理token。
- 参考模型价值:开发了一个在高质量推理数据上训练的参考模型,它能更准确地评估推理思维链中token的条件重要性,还能应用到提示压缩等其他独立任务中。
- 方法对比验证:全面比较了针对强化学习生成的长思维链数据的条件和非条件token压缩方法,验证了CTS中token选择策略的有效性。
研究局限
- 数据与模型限制:用于训练参考模型的有价值推理token数量不够,在代码等专业领域的token重要性评估能力有限,而且受资源限制,没有对32B和72B等更大规模的模型进行实验。
- 推理模式与评估局限:主要侧重于压缩现有推理模式,而不是开发新的推理策略,并且需要高质量的推理数据集,而这类数据集可能不是在所有领域或任务中都存在。此外,token重要性评估只是对每个token在推理过程中真实贡献的近似估计。
- 高压缩比的影响:很高的压缩比可能会影响思维链对人类读者的可解释性,在对透明度要求高的应用中,可能会限制其教育或解释价值。而且,虽然在多个推理基准测试中证明了有效性,但这些基准测试可能无法完全代表现实世界推理任务的复杂性和多样性。
总结
CTS方法通过参考模型计算条件困惑度差异,识别长思维链数据中的关键token,在保持模型推理能力和输出效率的同时,实现了更高效的训练。这一研究为在资源受限环境中实现强大的推理能力做出了贡献,也为开发高效推理模型开辟了新方向。