Transformers KV Caching 图解
点击下方链接,关注VX公号:每日早参,免费获取AI数据、资讯和编程分享!
https://free-img.400040.xyz/4/2025/04/29/6810a50b7ac8b.jpg
原文:Transformers KV Caching Explained
KV-Cache已经存在了一段时间,但也许您需要了解它到底是什么,以及如何推理加速。
Transformer 原理
Key和Value状态用于计算按比例缩放的点积注意力,如下图所示。
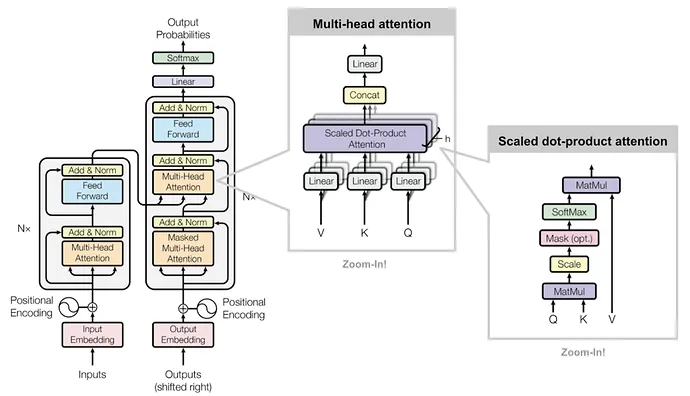
为什么只适用decoder架构?
- KV Cache 发生在多个Token逐步生成过程中,并且仅发生在解码器中(即,在GPT等仅解码器模型中,或在T5等编码器-解码器模型的解码器部分中)。像BERT这样的模型不是生成的,因此没有KV缓存。
- 预测新的token只与输入的最后一个token相关,输入的最后一个token因为只需要计算注意力值,而注意力的值需要将输入token的V值进行加权即得到结果,进行加权就需要将当前的Q与与所有的K进行计算得到权重,所以只需要缓存历史token的KV值。
为什么存在重复计算
解码器以自回归方式工作,如此GPT-2文本生成示例所示。
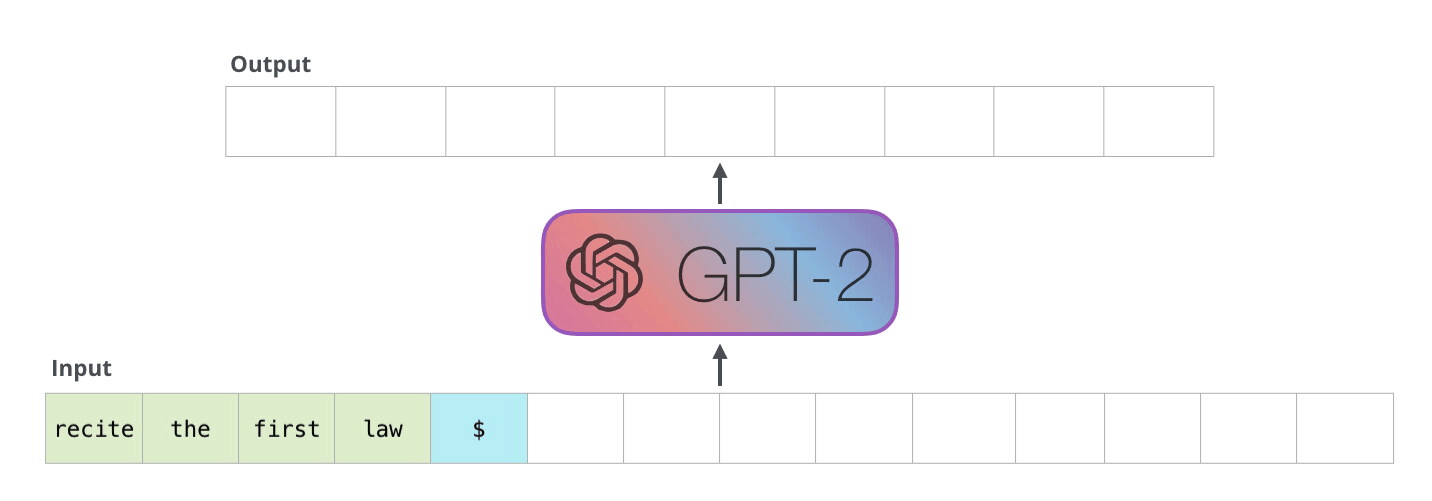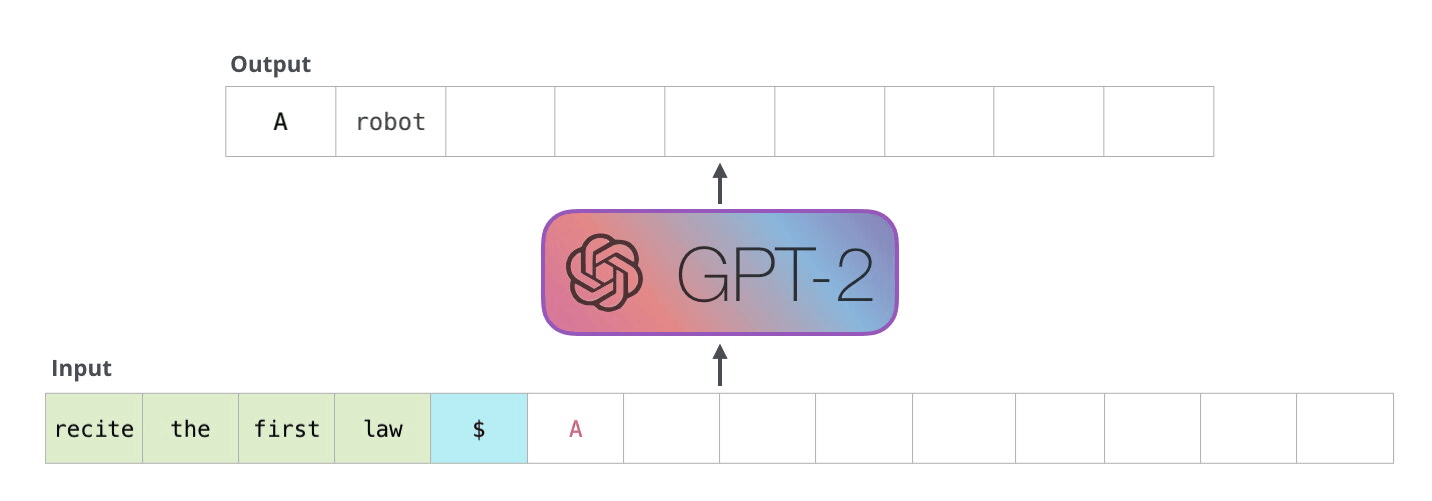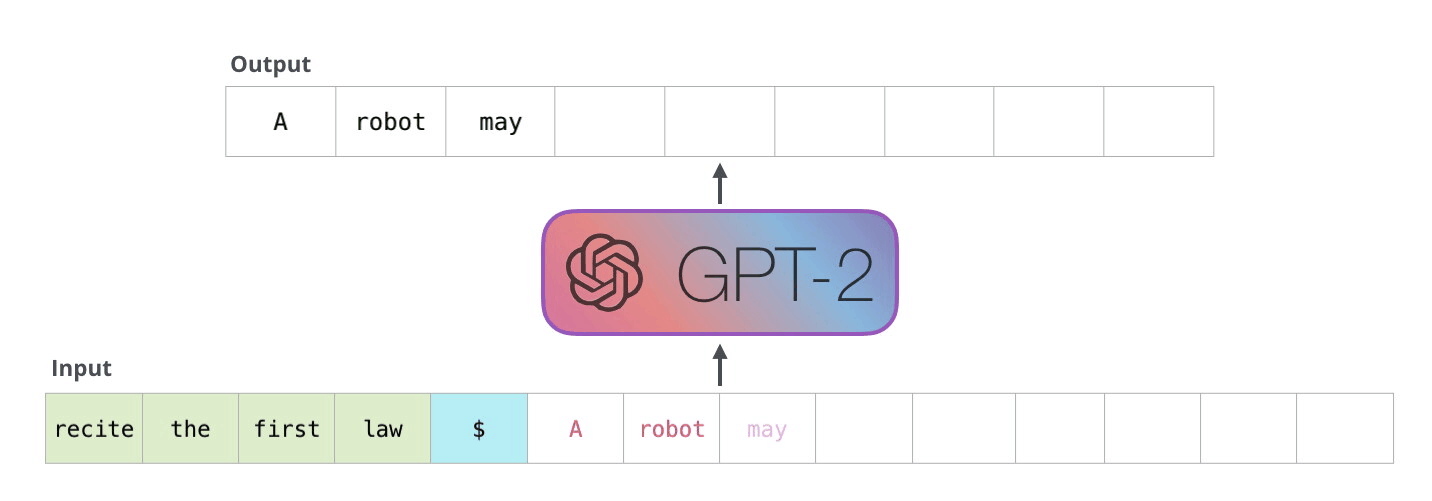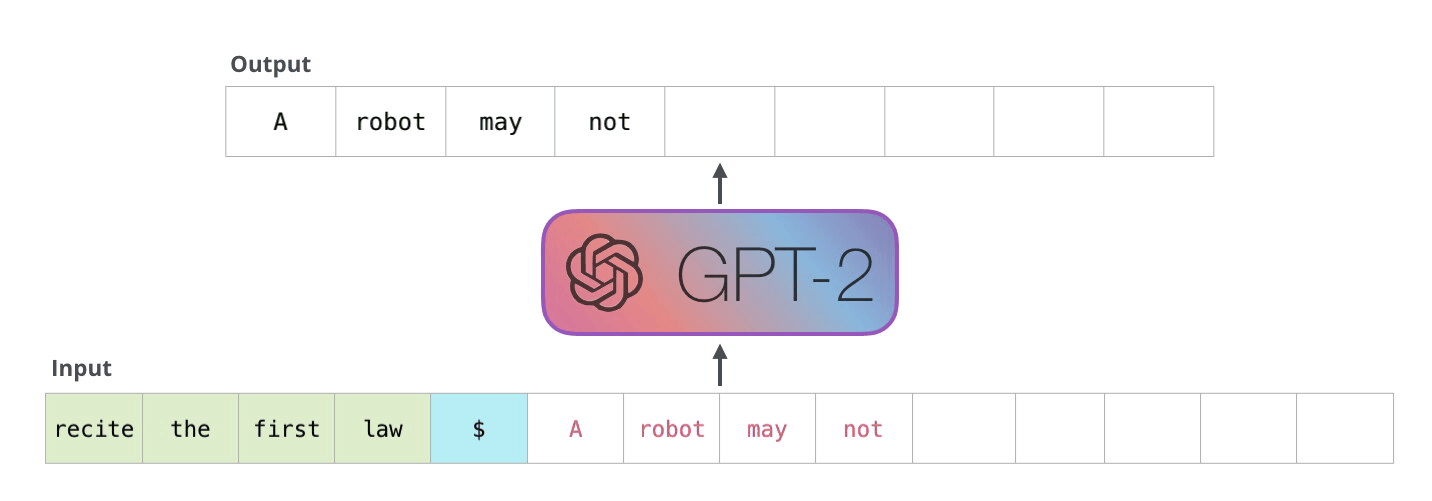
在解码器的自回归生成中,给定一个输入,模型预测下一个标记,然后在下一步中采用组合输入进行下一个预测。(图片来源:https://jalammar.github.io/illustrated-gpt2/)。
这种自回归行为重复了一些操作,我们可以通过放大解码器的 masked scaled dot-product attention 来更好地理解这一点。
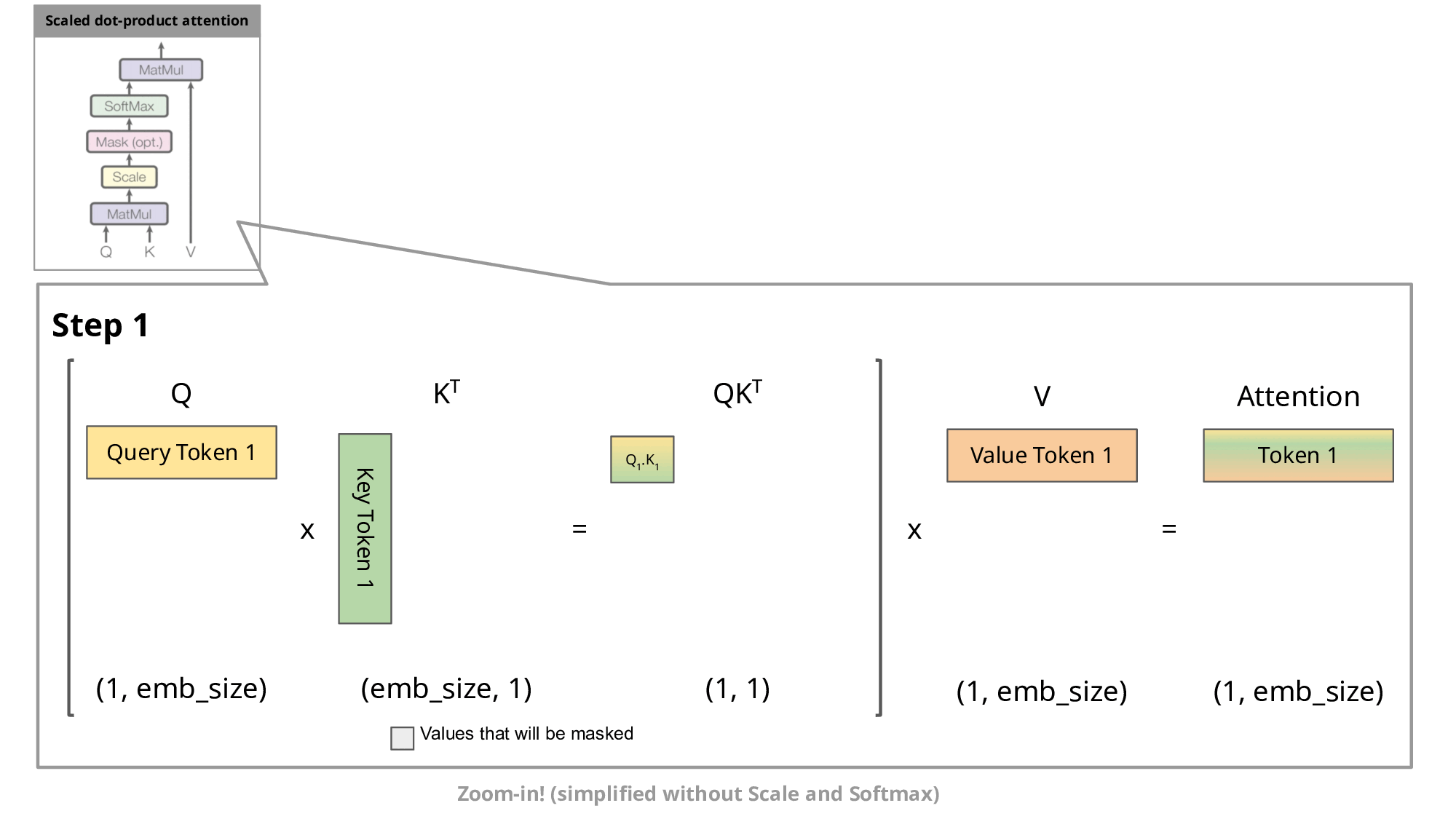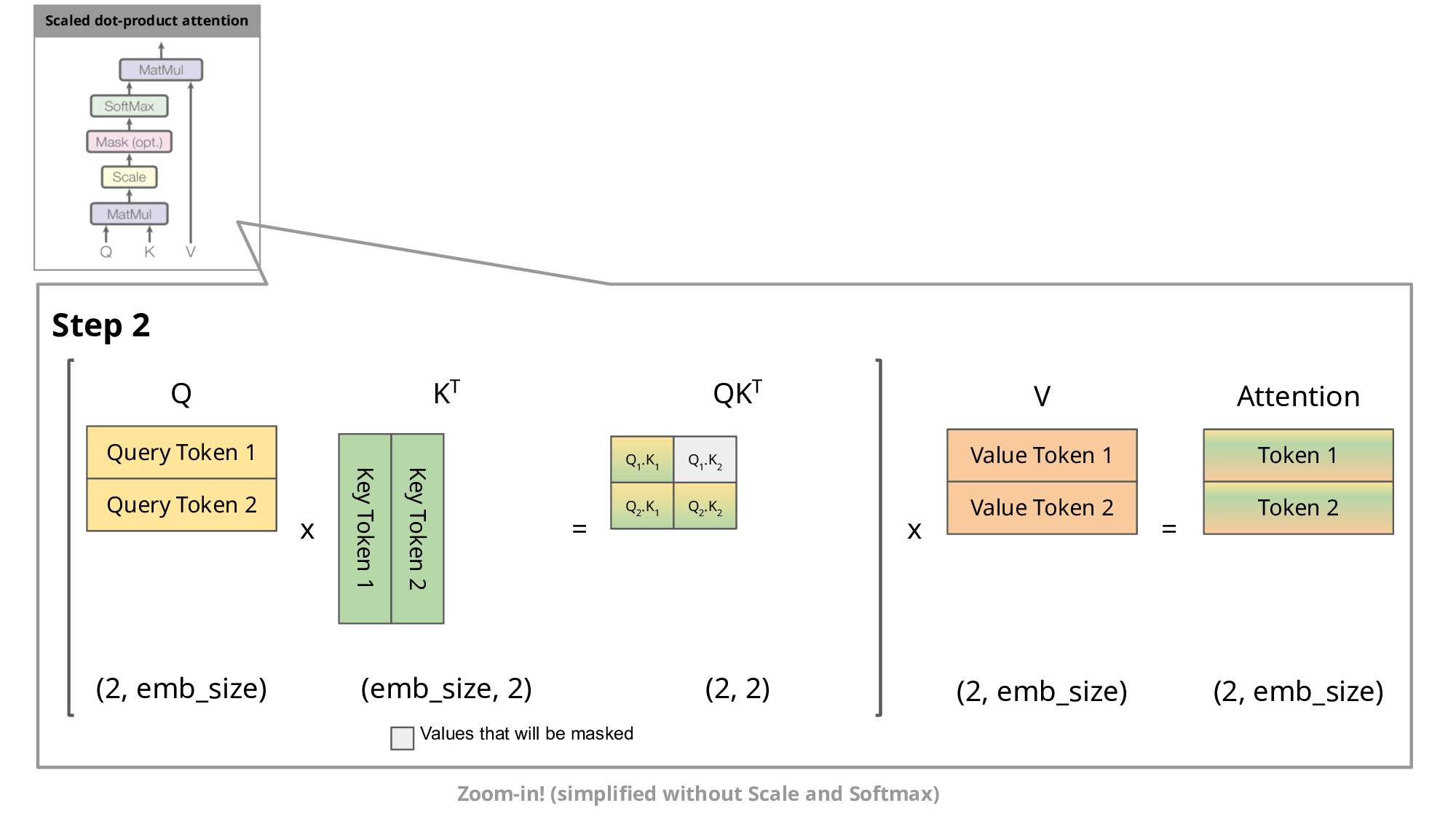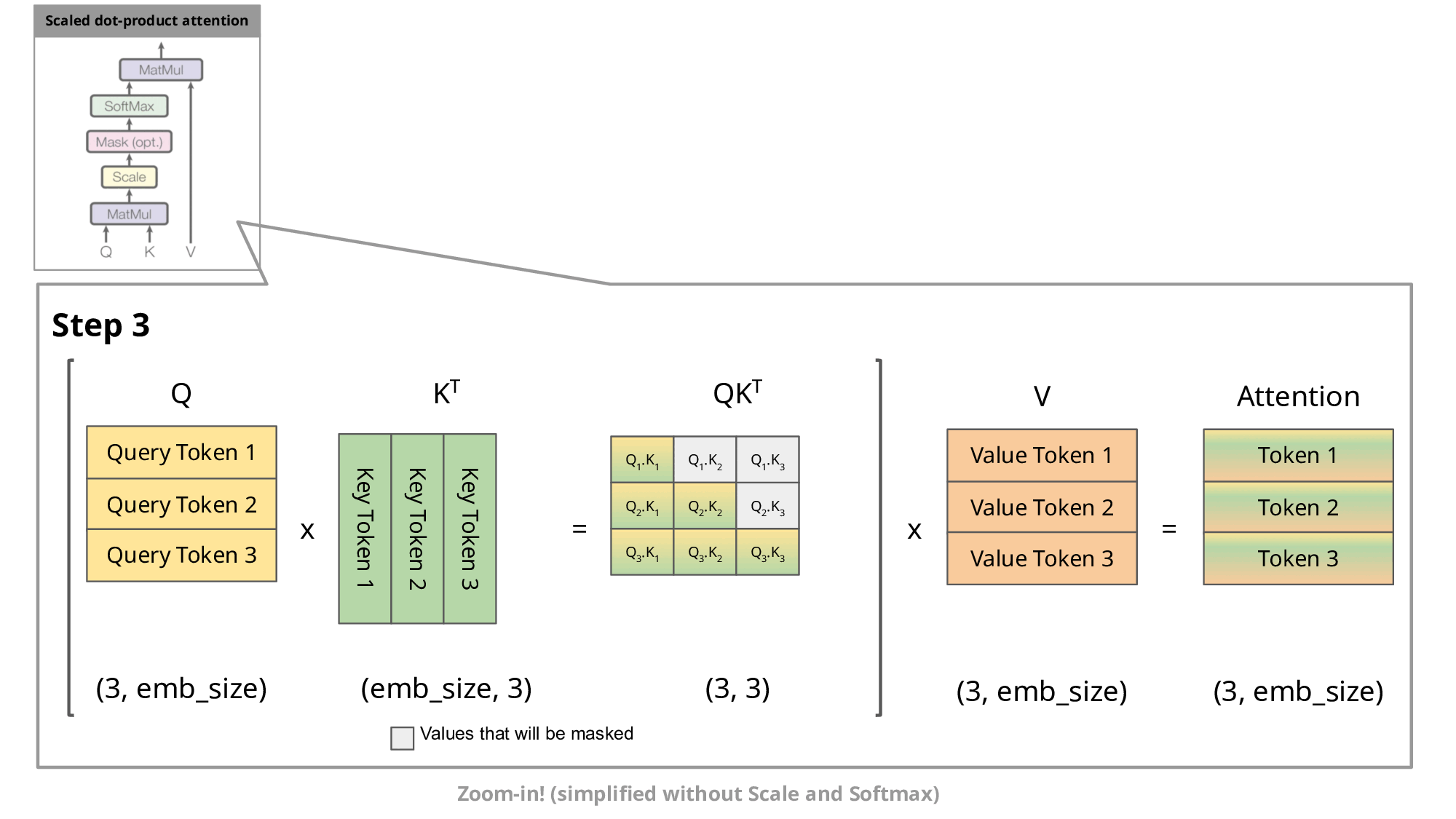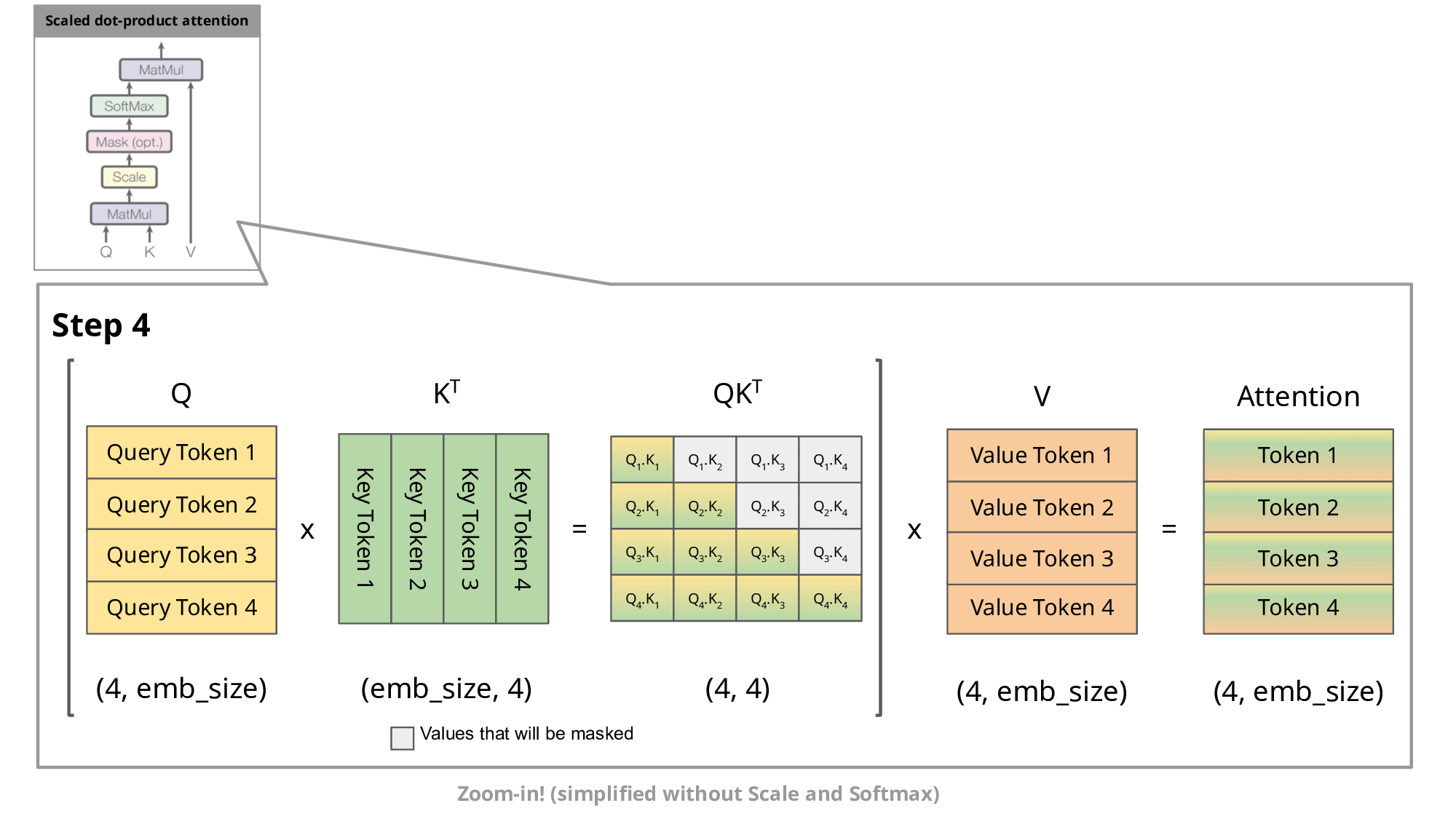
由于解码器是因果的(即,token的注意力仅取决于其先前的token),因此在每个生成步骤中,我们都在重新计算相同的先前token'注意力,而我们实际上只是想计算新token'的注意力。
这就是KV发挥作用的地方。通过缓存之前的密钥和值,我们可以专注于只计算新token的关注度。
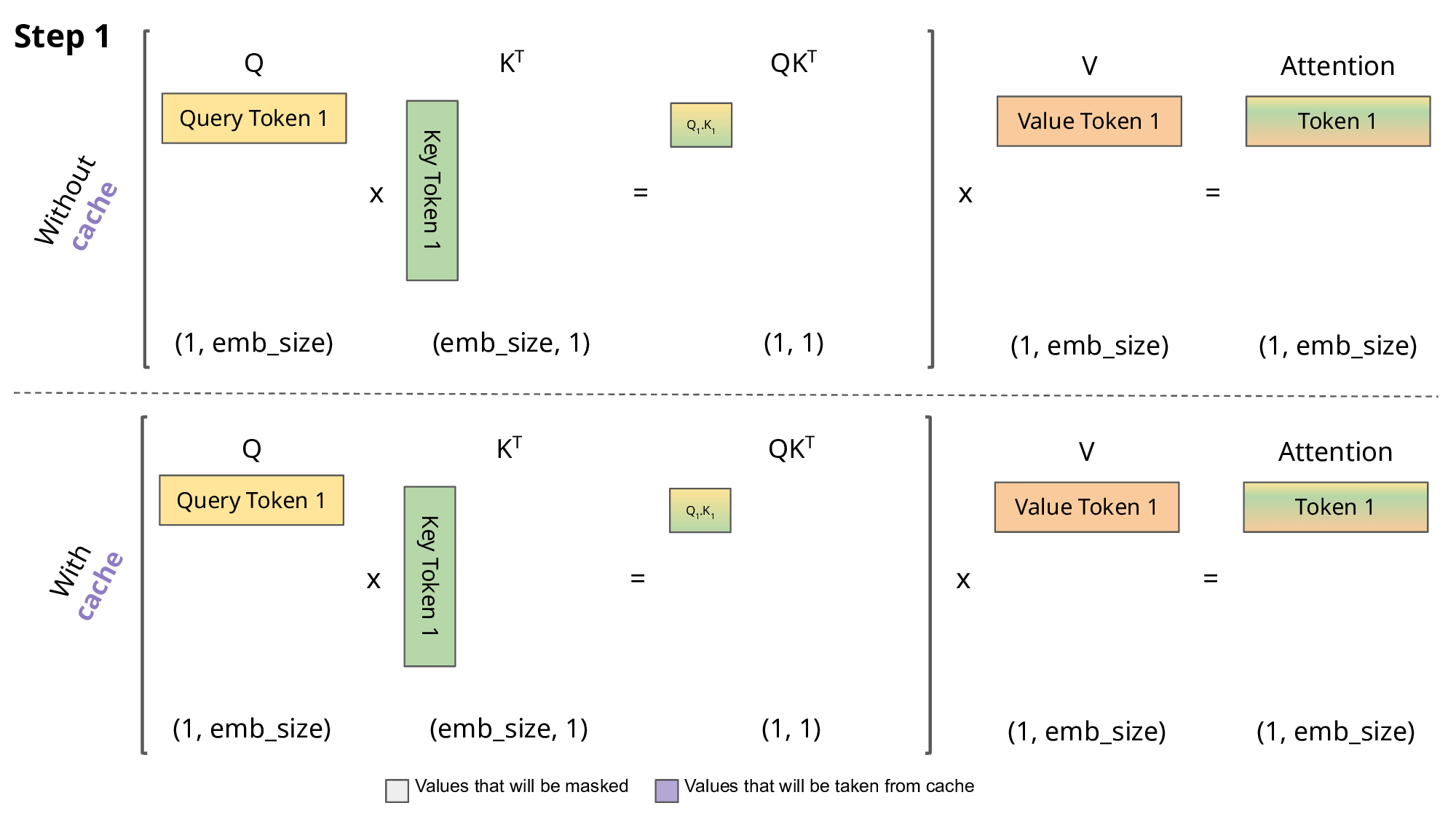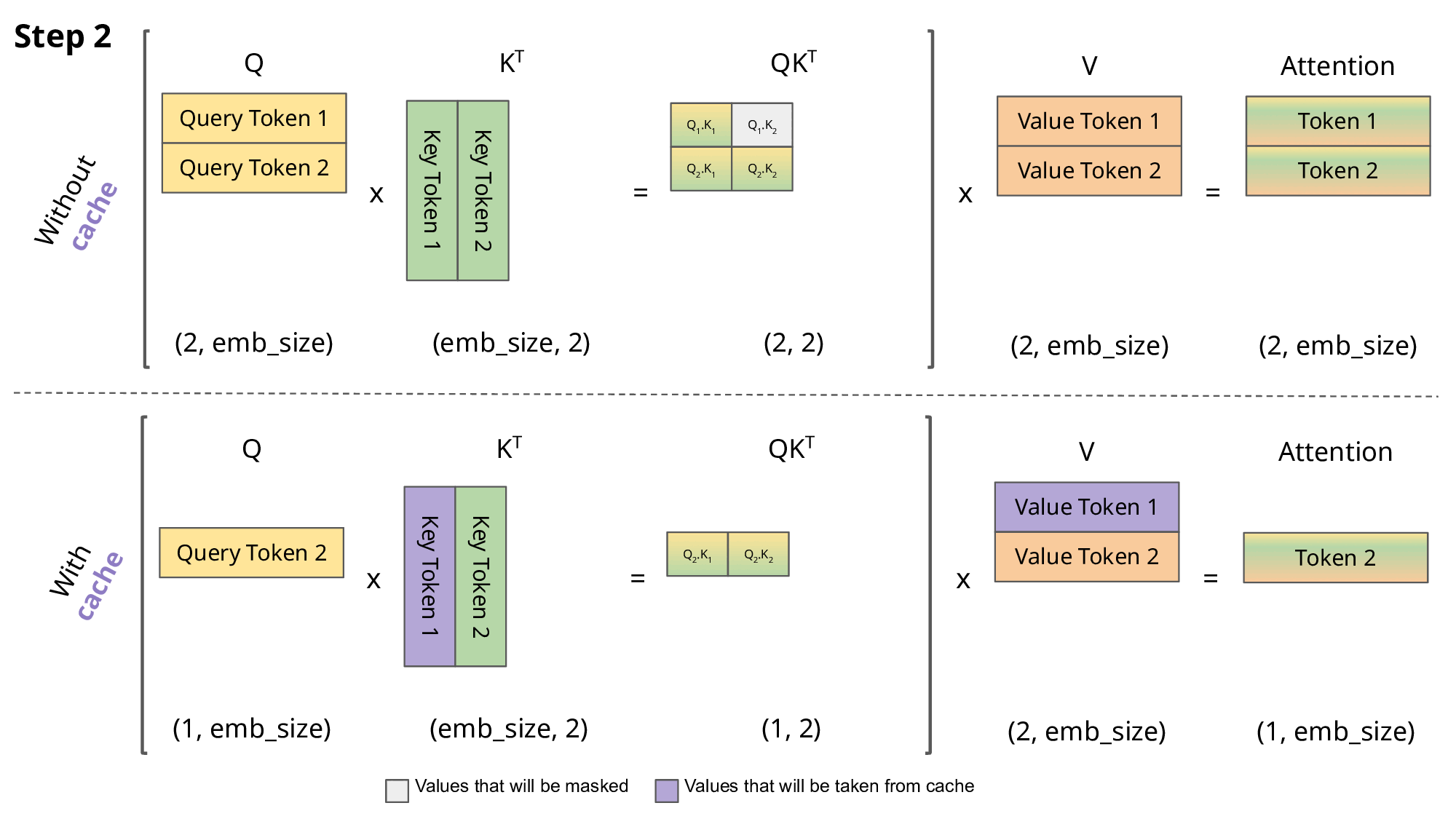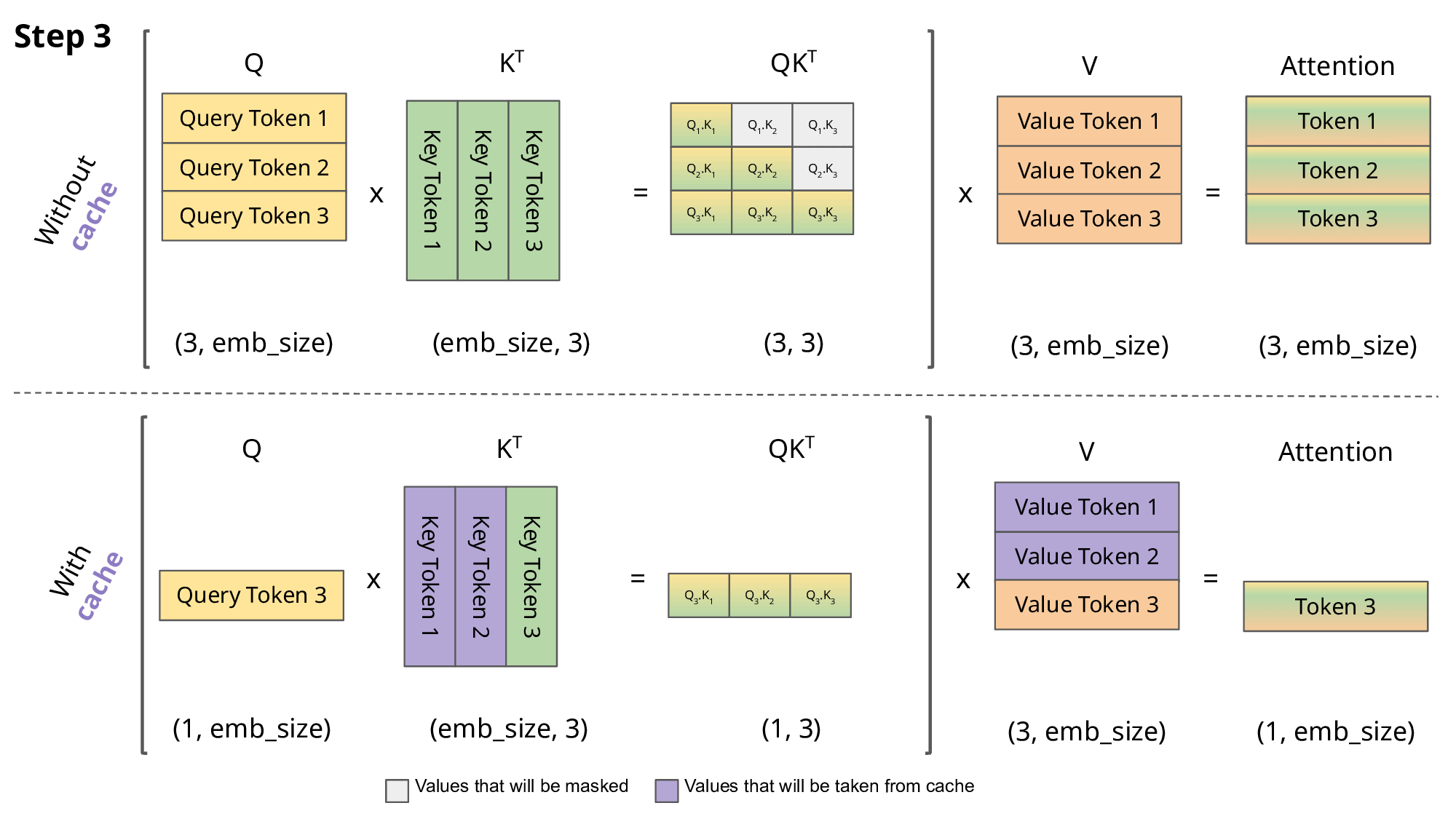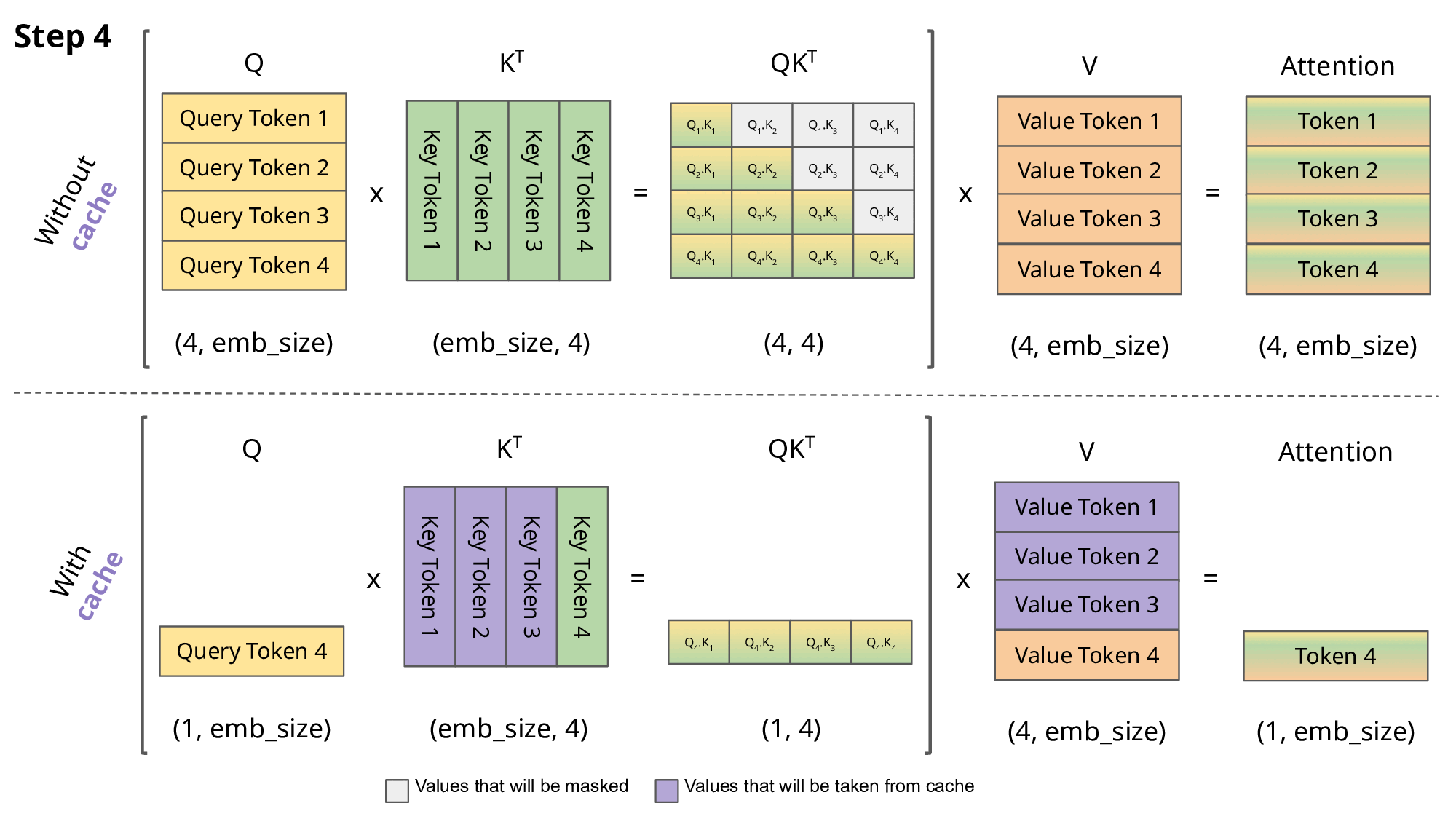
有和没有KV缓存的缩放点积注意力的比较。emb_size意味着嵌入大小。
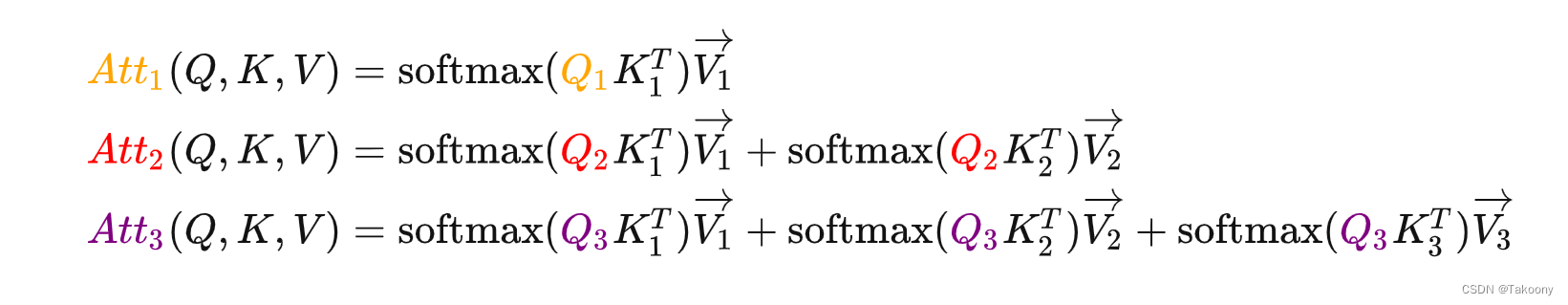
由于Causal Mask矩阵的存在,预测下一个token只与输入的最后一个token的QKV和历史token的KV有关;
如果没有Causal Mask,比如说是encoder架构,每次推理时每个token需要考虑所有输入的token,所以得到的注意力值都会变化,就不存在重复计算的情况。
优缺点是什么?
优点:如上图所示,使用KV缓存获得的矩阵要小得多,这导致矩阵乘法更快。
缺点:是它需要更多的 GPU VRAM 来缓存Key和Value状态。
跑跑看
让我们使用transformer🤗来比较GPT-2在有和没有KV缓存的情况下的生成速度。
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerdevice = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)for use_cache in (True, False):times = []for _ in range(10): # measuring 10 generationsstart = time.time()model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)times.append(time.time() - start)print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")在Google Colab notebook 使用Tesla T4 GPU ,这些是生成1000个新代币的平均和均方差时间:
使用KV缓存:11.885+-0.272秒
无KV缓存:56.197+-1.855秒再看个简化的 KV Cache 伪代码
class KVCache:def __init__(self, num_layers, num_heads, head_dim):self.cache = {layer: {'K': [], 'V': []}for layer in range(num_layers)}self.num_heads = num_headsself.head_dim = head_dimdef update(self, layer, K, V):"""将新 token 的 K 和 V 追加到缓存"""self.cache[layer]['K'].append(K) # 形状: (batch, heads, 1, head_dim)self.cache[layer]['V'].append(V) # 形状: (batch, heads, 1, head_dim)def get(self, layer):"""获取缓存的 K 和 V"""K = torch.cat(self.cache[layer]['K'], dim=2) # 形状: (batch, heads, seq_len, head_dim)V = torch.cat(self.cache[layer]['V'], dim=2) # 形状: (batch, heads, seq_len, head_dim)return K, Vdef attention_with_kv_cache(Q, K, V, kv_cache, layer):"""使用 KV Cache 的注意力计算"""# 更新缓存kv_cache.update(layer, K, V)# 获取完整的 K 和 VK_cached, V_cached = kv_cache.get(layer)# 计算注意力scores = torch.matmul(Q, K_cached.transpose(-1, -2)) / sqrt(Q.size(-1))weights = torch.softmax(scores, dim=-1)output = torch.matmul(weights, V_cached)return output
最后再举个例子来加深理解
想象你在写一封信,每写一个新词(token),都要参考前面已经写过的所有内容(token)。如果每次写一个新词都要从头重新看一遍之前写的全部内容,那就太慢了!
所以聪明的做法是:
✅ 把之前写过的内容,“记住”一些关键信息(Key 和 Value),这样往下写的时候就不用从头重看一遍了。
这就是 KV Cache 的作用:记录已经处理过的 token 的 Key 和 Value,避免重复计算。
那为什么只缓存 K 和 V,不缓存 Q 呢?
因为:
✅ Key 和 Value 是“过去的信息”:
它们是从输入或已经生成的文本中提取出来的,代表“以前说了什么”。这些信息一旦算出来就不会变,可以放心地保存下来。
就像你写信时已经写过的句子,内容不会变了,所以你可以把它们的关键信息记下来备用。
❌ Query 是“当前的问题”:
Query 是当前这个词要“关注”哪些过去的信息。它是根据当前这个新词动态生成的,每个词都不一样。
这就好比你现在要写的新词,你要思考:“我刚才说的是啥?” —— 这个“思考方式”(也就是 Query)是根据当前情况决定的,不能提前知道,也不能复用之前的。
总结成一句话:
KV Cache 不存 Q(Query),是因为 Q 是“当前”的东西,每个新词都要重新生成;而 K 和 V 是“过去”的东西,可以反复使用,值得缓存。
这样设计既能节省时间,又能减少计算资源的浪费,让大模型回复得更快!
其他参考:
1:https://www.zhihu.com/question/596900067/answer/3420479238