python数据结构和算法(5)
插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的,个数加一的有序数据,算法适用于少量数据的排序
基本思想
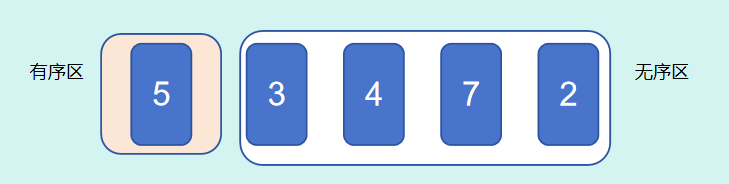
将未排序的数据序列逻辑拆分为两个序列,有序序列和无序序列,即前面是有序列,后面是无序序列,然后拿无序序列中的每个元素,插入到有序序列的合适位置
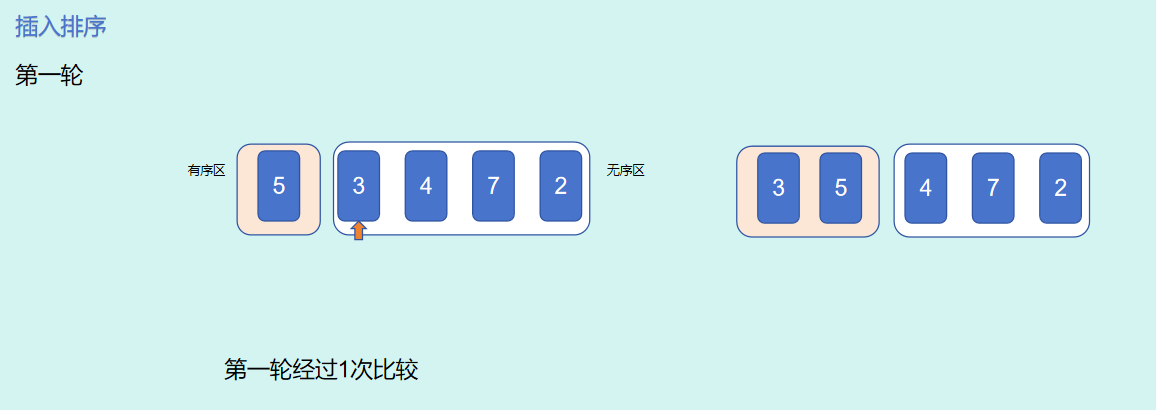
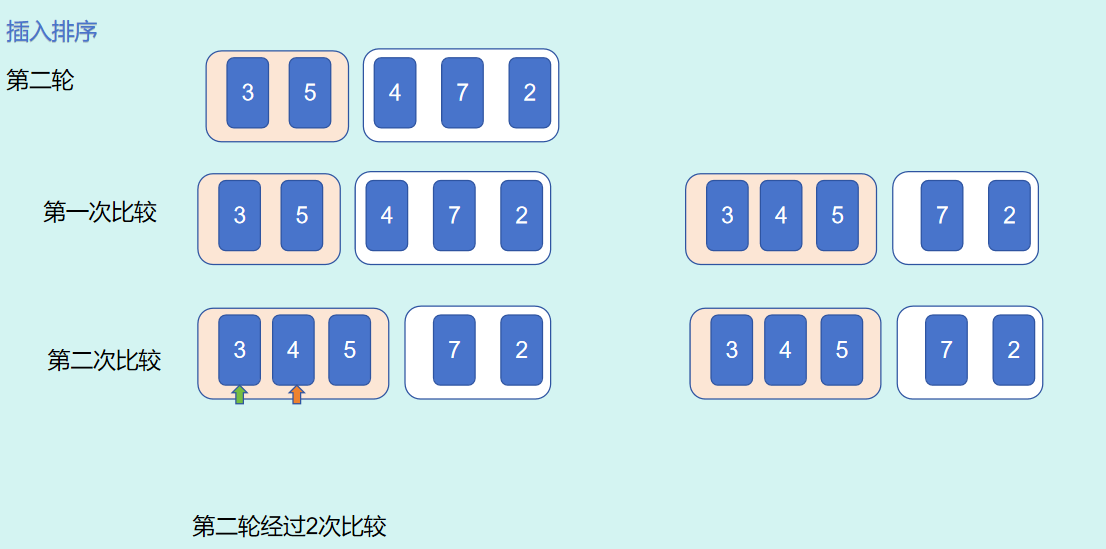
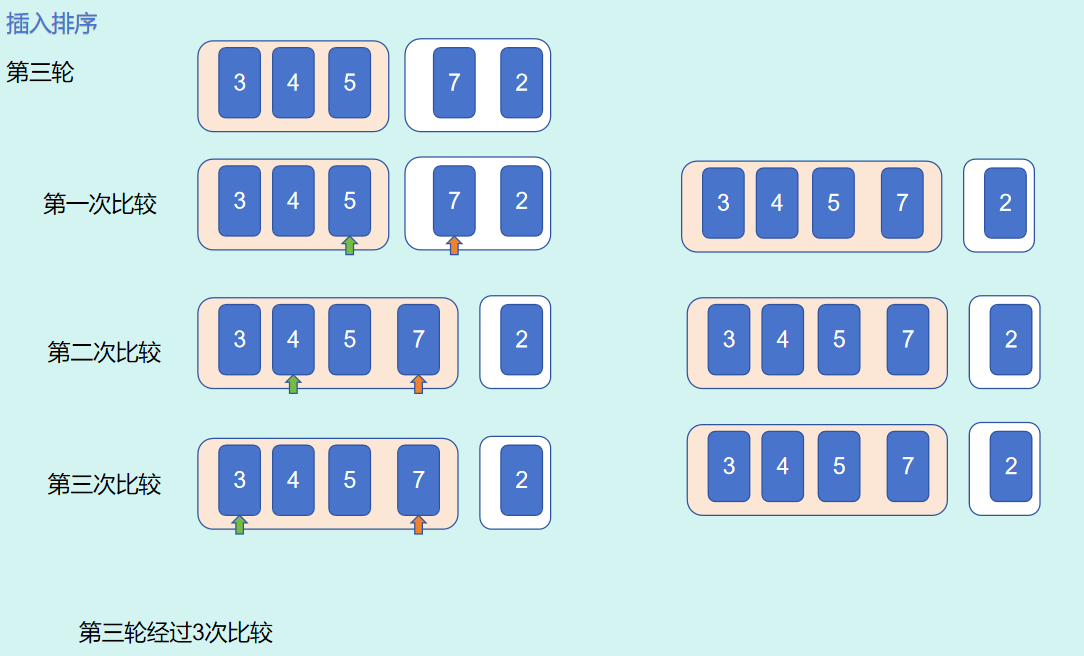
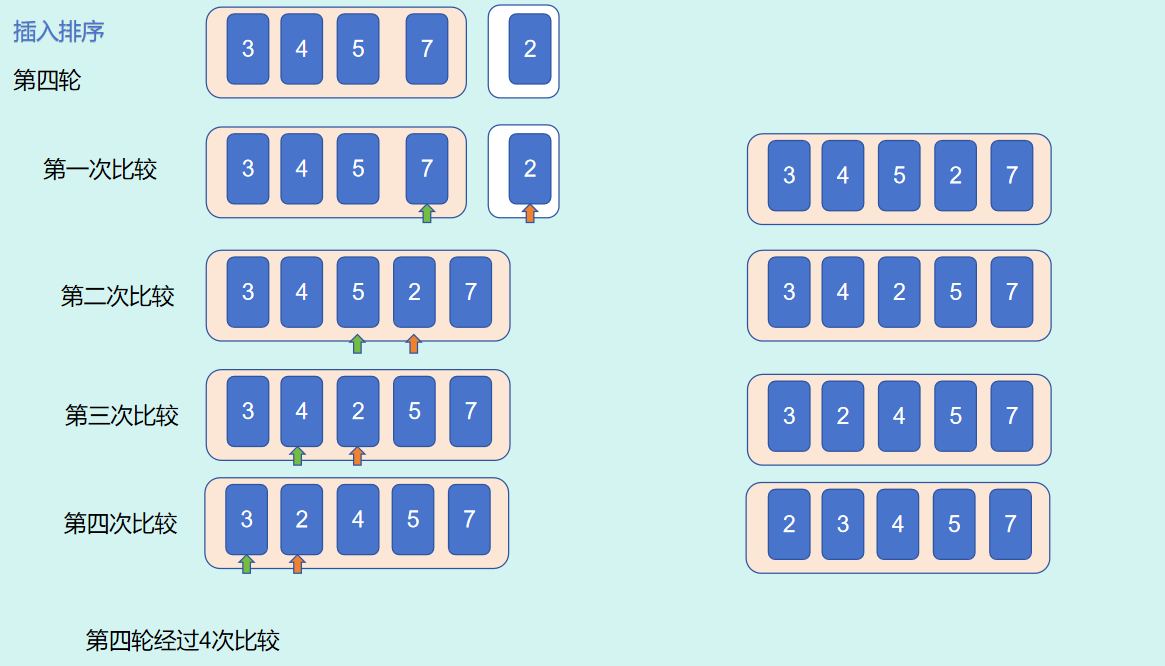

总结:5个数字进行插入排序,以变量
i代表轮数,则i的取值范围为1,2,3,4,即range(1,5),如果是n个元素进行插入排序,轮数i的取值范围为range(1,n);以变量j表示每轮比较的索引
第 1 轮i = 1,进行了 1 次比较,j的取值范围为0
第 2 轮i = 2,进行了 2 次比较,j的取值范围为1,0
第 3 轮i = 3,进行了 3 次比较,j的取值范围为2,1,0
第 5 轮i = 4,进行了 4 次比较,j的取值范围为3,2,1,0
j的最大取值范围为3,2,1,0,逐轮递增,并且每轮递减,即range(i,0,-1)
array = [5,3,4,7,2]
n = len(array)
for i in range(1,n):for j in range(i,0,-1):if array[j] < array[j-1]:temp = array[j]array[j] = array[j-1]array[j-1] = tempelse:break
快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一个部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
快速排序算法通过多次比较和交换来实现排序,其流程如下
- 首先设定一个分界值,通过该分界值将数组分成左右两部分
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组左边,此时,左边部分中各元素都小于或等于分界值,右边部分中各元素都大于或等于分界值
- 然后,左边和右边的数据可以独立排序,对于左侧的数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值,右侧的数据也做类似处理
- 重复上述流程,可以看出,这是一个递归定义,通过偶递归将左侧部分排序后,再递归排好右侧部分的顺序,当左、右两个部分个数据排序完成后,整个数据的排序也就完成了。
array = [5,8,2,1,9,6,7,4,3]def quick_sort(s_list,start,end):"""快速排序:param s_list: 列表:param start: 开始索引:param end: 结束索引:return: 无"""# 1.1 如果 start >= end,程序结束,说明排序完成if start >= end: return# 1.2 定义变量 left 和 right,分别表示 起始 和 结束 索引left = startright = end# 1.3 定义变量middle(mid) 表示分界值,假设:列表的第1个元素为分界值mid =s_list[start]# 1.4 具体的排序过程,只要 left < right 说明没有找完,则一直找while left < right:# 1.5 把分界值右边 比分界值小的数据放到分界值的左边# 1.5.1 如果 right 位置的值比分界值大,则 right -= 1while s_list[right] >mid and left < right:right -= 1# 1.5.2 如果right位置的值比分界值小,就赋值,即 把该值放到分界值的左边s_list[left] = s_list[right]# 1.6 把分界值左边,比分界值大的数据放到分界值的右边# 1.6.1 如果 left 位置的值比分界值小,则 left += 1while s_list[left] < mid and left < right:left += 1# 1.6.2 如果 left 位置的值比分界值大,就赋值,即 把该值放到分界值的右边s_list[right] = s_list[left]# 1.7 此时,说明left >= right,即 left索引的位置,就是分界值的位置s_list[left] = mid# 1.8 此时,说明本轮分界值位置都已确定,递归继续往下继续:分别对分界值的左边和右边的数据,做重复操作即可# 1.8.1 对分界值的左边的数据,做递归操作quick_sort(s_list,start,left-1) # 1.8.2 对分界值的右边的数据,做递归操作quick_sort(s_list,left+1,end)