高分辨率图像合成归一化流扩展
大家读完觉得有帮助记得关注和点赞!!!
1 摘要
我们提出了STARFlow,一种基于归一化流的可扩展生成模型,它在高分辨率图像合成方面取得了强大的性能。STARFlow的主要构建块是Transformer自回归流(TARFlow),它将归一化流与自回归Transformer架构相结合,并且最近在图像建模方面取得了令人印象深刻的成果。在这项工作中,我们首先确立了TARFlow在建模连续分布方面的理论普适性。在此基础上,我们引入了一系列架构和算法创新,从而显著增强了可扩展性:
(1)一种深浅设计,其中一个深层Transformer块捕获了模型的大部分容量,然后是几个浅层Transformer块,这些块计算成本低廉但贡献不可忽略;
(2)在预训练自编码器的潜在空间中进行学习,这证明比直接建模像素有效得多;
(3)一种新型引导算法,可显著提高样本质量。至关重要的是,我们的模型仍然是一个单一的端到端归一化流,允许在连续空间中进行精确的最大似然训练,而无需离散化。
STARFlow在类条件和文本条件图像生成方面均取得了具有竞争力的结果,其样本质量接近最先进的扩散模型。据我们所知,这是归一化流在这种规模和分辨率上的首次成功演示。
近年来,高分辨率文本到图像生成建模取得了显著进展,其中最先进的方法主要分为两个不同的类别。一方面,在连续空间中运行的扩散模型(Ho et al., 2020;Rombach et al., 2022;Peebles & Xie, 2023;Esser et al., 2024)在图像质量方面树立了新的基准。然而,它们对迭代去噪过程的依赖使得训练和推理在计算上都非常密集。另一方面,自回归图像生成方法(Yu et al., 2022;Sun et al., 2024;Tian et al., 2024)——受到大型语言模型(LLMs, Brown et al., 2020;Dubey et al., 2024)成功的启发——通过量化在离散空间中对图像进行建模,从而避免了这种低效率;然而,这种量化会带来严格的限制并对保真度产生不利影响。最近,出现了一种有希望的趋势,即探索直接在连续空间中应用自回归技术的混合模型(Li et al., 2024;Gu et al., 2024b;Fan et al., 2024)。然而,这两种范式固有的不同特性为有效的统一引入了额外的复杂性。
在本文中,我们将目光投向另一种建模方法——归一化流(NFs, Rezende & Mohamed, 2015; Dinh et al., 2016),这是一类基于似然的模型,在最近的生成式人工智能浪潮中受到的关注相对较少。我们首先考察TARFlow(Zhai et al., 2024),这是一个最近提出的模型,它将强大的Transformer架构与自回归流(AFs, Kingma et al., 2016; Papamakarios et al., 2017)相结合。虽然TARFlow在NFs作为建模原则的潜力方面表现出令人鼓舞的结果,但与其他方法(如扩散模型和离散自回归模型)相比,它是否能作为一种可扩展的方法执行仍然不清楚。为此,我们提出了STARFlow,这是一个生成模型系列,它首次表明NF模型可以成功地推广到高分辨率和大规模图像建模。我们首先通过展示多块AFs在建模连续分布方面的普遍性,对AFs为何能成为有能力的生成模型提供了一个理论上的见解。在此基础上,我们提出了一种新颖的深-浅架构。我们发现架构配置,例如,flows的数量以及每个flow的Transformer的深度和宽度,对模型的性能起着关键作用。虽然TARFlow(Zhai et al., 2024)建议在所有flows中均匀分配模型深度,但我们发现采用倾斜的架构设计是有益的,在这种设计中,我们将大部分模型参数分配给第一个AF块(即最接近先验的那个),然后是一些浅但不可忽略的块。重要的是,我们的模型仍然产生一个独立的归一化流框架,该框架支持在连续空间中进行端到端的最大似然训练,从而避免了离散模型固有的量化限制。我们不是直接在数据空间中操作,而是在预训练自编码器的潜在空间中学习AFs。至关重要的是,我们证明了NFs与压缩的潜在变量自然对齐——这是一个直观但至关重要的观察——与直接在像素上训练相比,这使得能够更好地对高分辨率输入进行建模,这在我们的实验中得到了验证。与TARFlow类似,噪声注入被证明是必不可少的:通过微调解码器,我们在有噪声的潜在变量上训练模型,同时简化了原始采样流程。此外,我们以更原则的方式重新审视了AFs的无分类器引导(CFG)算法,并提出了一种新的引导算法,该算法大大提高了图像质量,尤其是在文本到图像生成任务中的高引导权重下。
这些创新共同代表了 NF 模型在大型、高分辨率图像生成中的首次应用演示。我们的方法为传统的基于扩散和自回归的方法提供了一种可扩展且高效的替代方案,在类别条件图像和大规模文本到图像合成的基准测试中均实现了具有竞争力的性能。此外,我们的框架具有高度的灵活性,我们证明通过微调可以轻松实现有趣的设置,例如图像修复和基于指令的图像编辑。
2 预备知识
2.1 正则化流


2.2 自回归流和TARFlow




3 STARFlow
在本节中,我们提出了一种可扩展的Transformer自回归流(STARFlow),该方法推动了基于NF的高分辨率图像生成的前沿。我们首先在§3.1中从理论上确立了AF作为一种通用建模方法的表达能力,在此基础上,我们通过在几个关键方面改进TARFlow来提出我们的核心方法:(1)更好的架构配置(§3.2),(2)潜在空间学习的工作方案(§3.3)和(3)一种新颖的引导算法(§3.4)。学习和推理流程的示例如图4所示。
3.1 为什么TARFlows是强大的生成模型?
尽管经验结果证实TARFlow具有很强的竞争力(Zhai et al., 2024),但我们从建模的角度提出疑问——它们是否具有足够的表达能力来保证扩展。在此,我们声明:


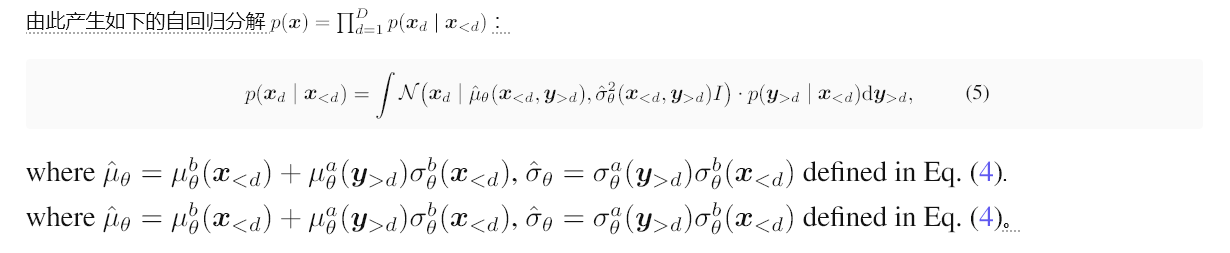
对于每个 d < D,我们有



3.2 提出的架构
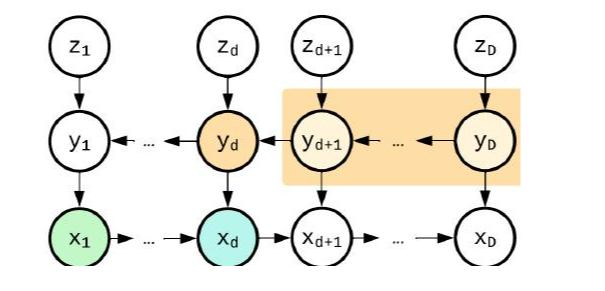
图 2:2-块 AFs 示例。
3.1 中的推导促使我们重新设计在实际计算预算内的可扩展 AF 架构,强调我们不需要大幅扩展流块的数量——实际上(即使 T = 2 通常也足够了)。然而,该评论并未解决如何最好地在这些块之间分配计算资源的问题。我们首先检查 TARFlow 中提出的架构配置,该配置建议为每个流分配相同大小的 Transformer 层。有趣的是,在我们复现的 TARFlow 结果中,我们发现最有效的计算(通过指导的视角衡量)集中在最上面的几个 AF 块中(参见示例图 3)。我们推测端到端训练驱动网络去利用 lay

图 3:从上到下,使用具有 8 个流块的 TARFlow 模型引导前 0、3、8 个流块。我们看到引导仅对前 3 个块有效。
噪声附近最近的样本表现出与扩散模型相反的行为。


3.3 迁移到潜在空间
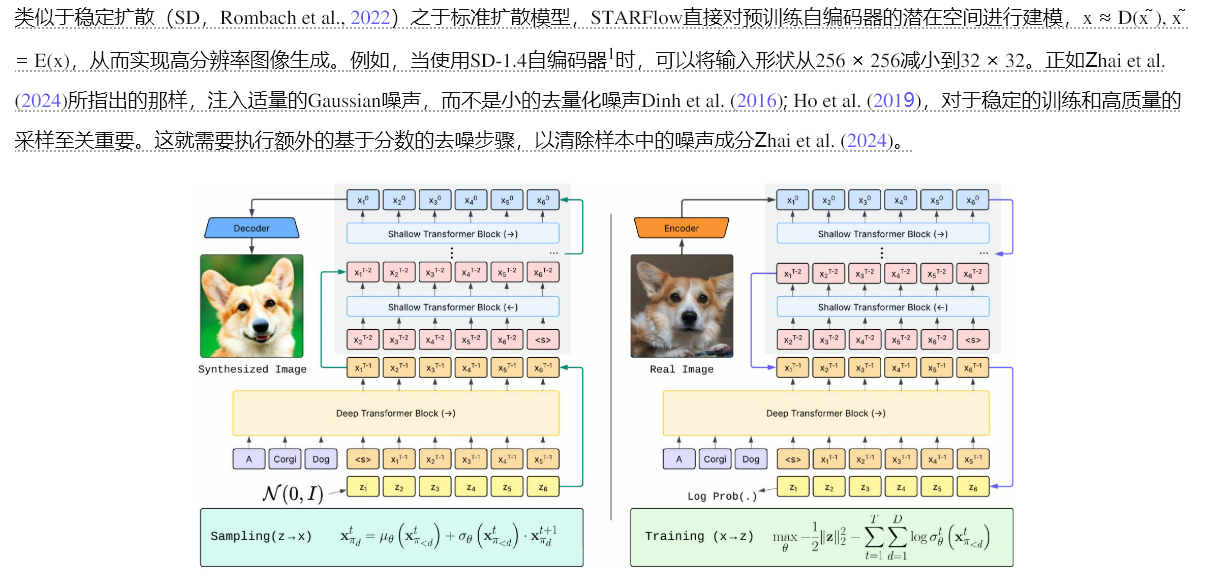
图4:本文提出的文本到图像生成模型的自回归推理(左)和平行训练(右)过程的说明。向上(绿色)和向下(紫色)的箭头表示如公式(2)所示的逆向和正向AF步骤。





3.4 重新审视自回归流的无分类器引导
无分类器引导(CFG)最初是为扩散模型引入的(Ho & Salimans, 2021),现已成为现代生成建模的基石,并在包括AR模型在内的各种架构中被证明是广泛有效的(Yu et al., 2022)。从高层次来看,CFG放大了条件预测和无条件预测之间的差异,从而鼓励了更强的模式寻求行为。

图 5: (a) 来自 TARFlow 的指导 (Zhai et al., 2024) (b) 提出的关于 ImageNet 256 ×256 的指导。


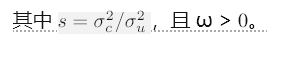
证明:详细推导见附录A。

3.5 应用
STARFlow 是一种通用的生成模型,它不仅可以在各种条件下生成多样化、高质量的图像,还可以自然地扩展到下游应用。我们展示了两个例子:图像修复和编辑。
无训练修复:我们首先将带掩码的图像映射到潜在空间,用高斯噪声替换掩码区域。然后执行反向采样,使用真实值恢复未掩码的像素。我们迭代地执行生成,直到获得最终的修复输出。
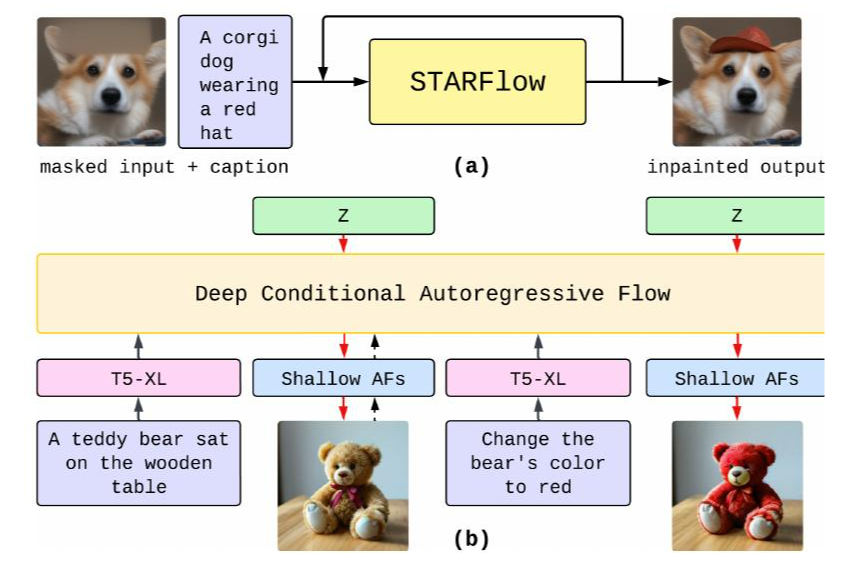
图 6:(a) 图像修复 (b) 交互式编辑。
交互式生成和编辑。我们在图像编辑数据集上对STARFlow进行微调(图6b),从而能够使用单个条件AF模型对生成和编辑进行联合建模。其可逆性还允许直接图像编码,使其适合交互式使用。

图 7:ImageNet 256 × 256 和 512 × 512 上 STARFlow 的随机样本(ω = 3.0)。
4 实验
4.1 实验设置
数据集 我们在类别条件和文本到图像生成任务上使用STARFlow进行实验。对于前者,我们在ImageNet-1K(Deng et al., 2009)上进行了实验,包括256 × 256和512 × 512的分辨率。对于文本到图像,我们展示了两种设置:一种是受限设置CC12M(Changpinyo et al., 2021),其中每张图像都附带一个合成标题,遵循(Gu et al., 2024a)。我们还展示了一个扩展设置,其中我们的模型使用CC12M训练了一个内部数据集,总共有约7亿个文本-图像对。
评估 与先前工作一致,我们报告了Fréchet Inception Distance (FID) (Heusel et al., 2017),以量化生成图像的真实性和多样性。对于文本到图像的生成,我们使用MSCOCO 2017 (Lin et al., 2014)验证集来评估这些模型的零样本能力。我们还在附录C中报告了额外的评估(例如,GenEval (Ghosh et al., 2023))。
模型与训练细节:我们按照Dubey等人(2024)的设置来实现所有模型,并使用RoPE(Su等人,2024)进行位置编码。默认情况下,我们将架构设置为d(N ) = 18(6),模型维度为2048 (XL);对于类别条件和文本到图像模型,则设置为24(6),维度为3096 (XXL)(§ 3.2),分别产生14亿和38亿个参数。由于STARFlow在压缩的潜在空间中运行,我们能够以p = 1的patch大小训练所有模型。对于文本到图像模型,我们使用T5-XL(Raffel等人,2020)作为文本编码器。为了展示我们方法的通用性,我们还训练了一个变体,其中深度块从预训练的LLM(在本例中为Gemma2 (Team et al., 2024))初始化,而无需额外的文本编码器。
所有模型均在 256 × 256 分辨率下,使用包含 4 亿张图片的全局批次大小为 512 的数据集进行预训练。高分辨率微调通过增加输入长度来实现。对于文本到图像模型,通过混合分辨率训练支持可变长度输入:图像被预先分类到 9 个形状桶中,并展平为序列以进行统一处理。详细设置请参见附录 B。
4.2 结果
与基线的比较。我们在类别条件ImageNet-256上对我们的方法进行了基准测试,并与离散和连续域中的扩散模型和自回归模型进行了比较(表1)。为了公平比较,我们使用相似的参数数量和原始架构(8个流,每个流8层,宽度1280)在像素空间中训练了一个TARFlow模型Zhai et al.(2024)。我们还

1. 一只燃烧的折纸鸽子位于一个黑暗房间的中央,地板上有一个五角星 (680x384);
2. 一个玻璃容器,包含一个微型雨林生态系统,配有微型瀑布、异国植物、小型动物(如青蛙和蝴蝶),玻璃反射来自附近窗户的光线 (680x384);
3. 一只英国短毛小猫在阳光照射的房间里玩毛线 (1024x1024);
4. 一只微笑的卡通狗坐在桌子旁,手边放着咖啡杯,房间燃起熊熊大火。 "没事," 狗安慰自己 (384x680);
5. 一只狞猫在冰冷的南极冰架上滑行的照片级写实特写 (1024x1024);
6. 一只苹果树下美丽的虎型宝可梦,卡通风格 (256x256);
7. 一朵完全由折纸制成的雏菊花,放置在极简主义背景前,展示折叠和工艺,高分辨率,工作室照明 (416x624);
8. 亚特兰蒂斯的详细绘画,具有复杂的细节和鲜艳的色彩 (256x256);
9. 嵌入冰冻时间中的气态珊瑚大都市,生动的水彩绽放 (384x680);
10. 一幅水彩画,描绘了春天里一片充满活力的花田,盛开着彩虹般的花朵 (256x256);
11. 一座灯塔向沿海雾气中发射彩虹光束,水彩插图,沐浴在黄金时段的光芒中 (336x784);
12. 机器人工程师在生物发光潮汐池旁边的柔和粉彩画,从上到下的视觉流动,倾斜-移位微型化效果,照片级8K细节 (576x456);
13. 用华丽金色框架装饰的粉笔粉彩人行道壁画,描绘了一只野牛 (512x512);
14. 一个红苹果放在蓝色桌子上,旁边是一杯水,低多边形3D艺术 (336x784)。
图 8:从 STARFlow 中选择的不同长宽比的样本,用于文本到图像的生成 (ω = 4.0)。图像分辨率按比例调整,以便于可视化。

图 9:使用 STARFlow 进行图像编辑的示例。给定输入图像和简单描述,我们的模型可以使用学习到的模型先验,根据各种指令无缝地编辑内容。
表 1:Class-cond ImageNet 256×256 (FID-50K)
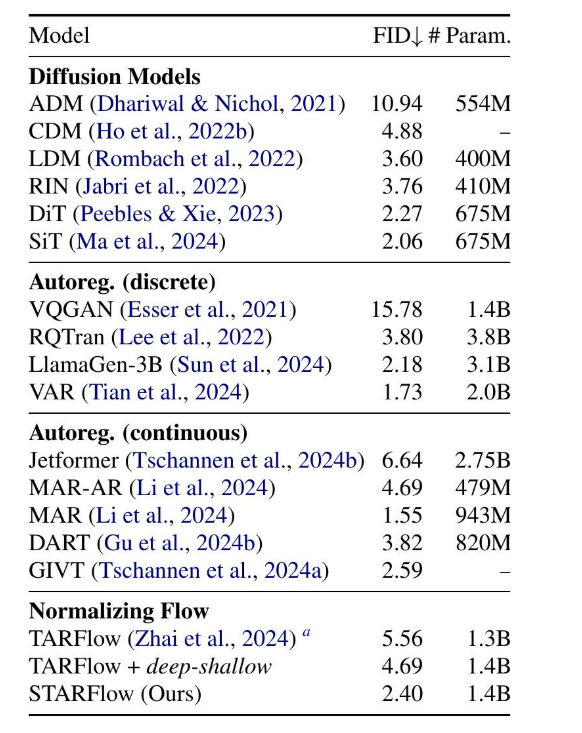
表 2: Class-cond ImageNet 512×512 (FID-50K)
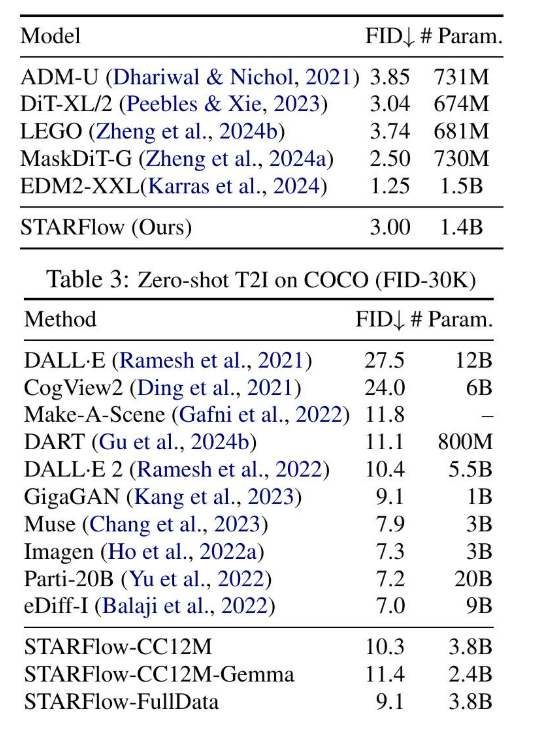
训练一个具有深度-浅层变体的模型,该模型与STARFlow相同,只是使用了线性缩放的像素输入。在NF模型中,深度-浅层架构始终优于标准设计,并且切换到潜在空间输入可带来进一步的增益。与其他基线相比,我们的方法取得了有竞争力的结果(表1和2)。请注意,ImageNet 256 × 256上的FID接近饱和,达到微调解码器的上限(详见附录B)。在COCO上的零样本评估(表3)显示了在文本条件生成方面的强大性能,表明NF也可以作为一种可扩展且具有竞争力的生成建模框架。
定性结果如图7和图8所示,分别展示了具有代表性的类别条件和文本条件生成结果。我们的方法能够生成各种宽高比的高分辨率图像,其感知质量与最先进的扩散模型和自回归方法相当。图9也突出了我们的模型对图像编辑的支持。更多的定性和交互式编辑结果见附录G,强调了我们输出的广泛性和保真度。
与扩散模型和自回归模型的比较:我们进一步将STARFlow与扩散模型和自回归(AR)模型进行比较,以分析训练动态。图10a展示了使用几乎相同架构的FID轨迹。虽然在4,096个样本上计算时,STARFlow与基线之间的FID差距较小,但当使用50,000个样本进行评估时,STARFlow始终在每个训练检查点上实现最低的FID。这表明STARFlow产生更多样化的输出,这可能无法通过较小的评估集完全捕获。
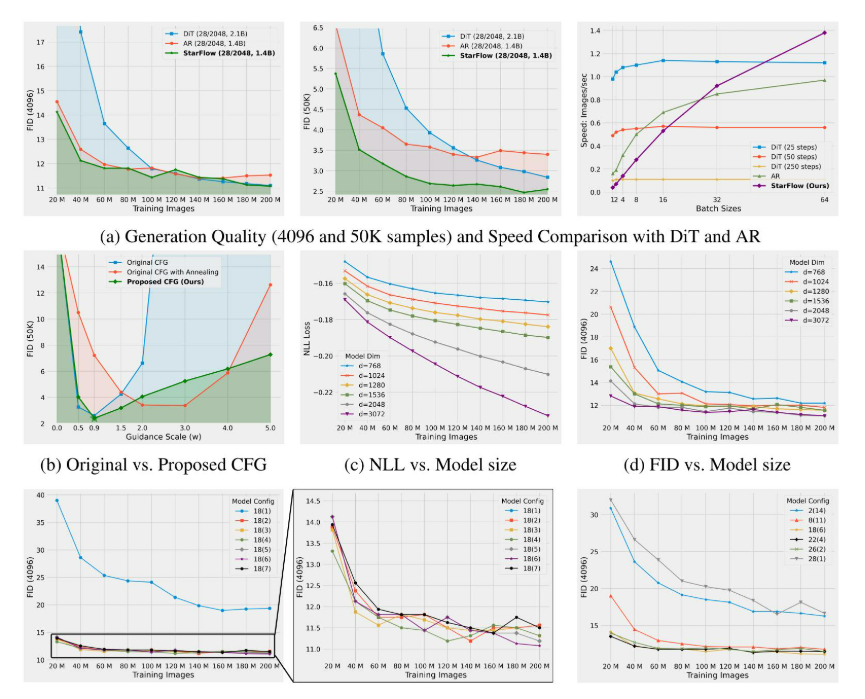
(e)改变深度块内层数的影响。(f)参数分配的消融实验。
图 10:综合消融实验结果
图10a还比较了扩散模型、AR模型和STARFlow模型在单个H100 GPU上的推理吞吐量。扩散模型的实际运行时间随其精炼步骤的数量线性增长——在最佳FID下约为250步——因此它是最慢的。相比之下,AR和STARFlow中的每一步都只是一个轻量级的前向传递,其每个token的成本都很低,从而允许吞吐量随着批次大小的增加而上升。当批次大小超过32时,STARFlow通过将指导限制在深层块并移除每个token的多项式采样循环,从而优于AR基线,产生了卓越的推理时可扩展性。
CFG策略的比较 如图10b所示,Zhai等人(2024)中使用的原始策略表现出明显的“下降-上升”行为:它在新提出的CFG相似的引导权重下实现了最佳FID,但随后随着您远离该最佳值而迅速下降。即使使用“退火技巧”(Zhai et al., 2024),性能在两种尺度上仍然会急剧下降。相比之下,我们提出的CFG不仅改进了原始策略的最佳点——无需额外技巧——而且更重要的是,在更广泛的引导权重范围内保持了几乎相同的质量,这为调整文本条件生成任务提供了更大的灵活性。
可扩展性分析:为了评估可扩展性,我们通过改变深度块的深度并在训练过程中跟踪性能来进行研究。图10c报告了负对数似然(NLL),图10d显示了在迭代过程中具有4096个样本的FID。这两个指标都表明,更深的模型收敛速度更快,并能获得更好的最终性能,这证明了容量的增加。
模型设计的消融实验:为了验证命题中的理论见解。1,我们研究了模型表达能力如何随着深度块中层数T的变化而变化。当T < 2时,性能急剧下降,而T ≥ 2的模型表现相似——与命题1一致。我们还在图10e和10f中消融了深度块的数量和深度,发现块深度比数量更重要,为架构设计提供了实践指导。10e和10f中消融了深度块的数量和深度,发现块深度比数量更重要,为架构设计提供了实践指导。
5 相关工作
连续归一化流、流匹配和扩散模型。归一化流(NFs)可以通过连续归一化流(CNFs)扩展到连续时间(Chen et al., 2018),它将变换建模为常微分方程。这放宽了对显式可逆映射的需求,并将雅可比矩阵的计算简化为迹(Grathwohl et al., 2018),尽管它需要有噪声的随机估计器(Hutchinson, 1989)。流匹配(Flow Matching)(Lipman et al., 2023)受到CNFs的启发,使用基于Tweedie引理的向量场(Efron, 2011)学习先验和数据之间的样本式插值。虽然CNFs和NFs通过可逆映射优化精确似然,但流匹配与扩散模型更接近,共享变分训练目标。
自回归模型 离散自回归模型,特别是大型语言模型(Brown et al., 2020;Dubey et al., 2024;Guo et al., 2025),通过扩展下一个token的预测,主导了现代生成式人工智能。缩放定律(Kaplan et al., 2020)表明,随着更多的数据和参数,可以获得可预测的收益。这些模型现在为领先的多模态系统提供动力,用于理解和生成(Liang et al., 2024;Sun et al., 2024;Tian et al., 2024;Li et al., 2025)。
为了克服量化造成的信息损失,最近的研究将AR建模扩展到连续空间,使用混合高斯模型(Tschannen et al., 2024a,b)或扩散解码(Li et al., 2024; Gu et al., 2024b; Fan et al., 2024)。混合方法也开始出现,统一了AR和扩散范式(Gu et al., 2024a; Zhou et al., 2024; OpenAI, 2024)。
6 结论与局限性
我们提出了STARFlow,这是第一个基于潜在变量的归一化流模型,可以扩展到高分辨率图像和大规模文本到图像的建模。我们的结果表明,归一化流是一种可扩展的生成建模方法,并且能够达到与强大的扩散模型和自回归模型基线相当的结果。
我们的工作也存在局限性。例如,为了简单起见,我们完全依赖于预训练的自编码器,但这使得潜在的联合潜在变量-NF模型设计问题仍未得到探索。此外,在这项工作中,我们主要关注训练高质量的模型,但这牺牲了未优化的推理速度。另外,我们的评估仅限于在标准基准上进行类别和文本条件的图像生成;该方法在多大程度上能推广到其他模态(例如,视频、3D场景)或更多样化的真实世界数据分布还有待观察。