6.9 Mysql面试题 索引相关
MySQL聚簇索引和非聚簇索引的区别是什么?
- 聚簇索引:
- 数据行按照索引值的顺序存储,索引叶子节点为数据行。
- 不需要额外步骤查找数据行。
- 通常是根据主键构建的,一个表一般只有一个聚簇索引,影响数据的物理存储位置。
- 避免额外的寻址开销,高效。
- 非聚簇索引:
- 叶子节点不包含完整的数据行,而是指向数据行的指针或主键值。
- 查到主键值后需要回表。
- 可以有多个。
- 效率较低。
MySQL主键是聚簇索引吗?

什么字段适合当主键
- 唯一性、不为空
- 有序递增
- 不建议使用业务数据作主键

查询数据时,到了B+树的叶子节点,之后的查找数据是如何做?
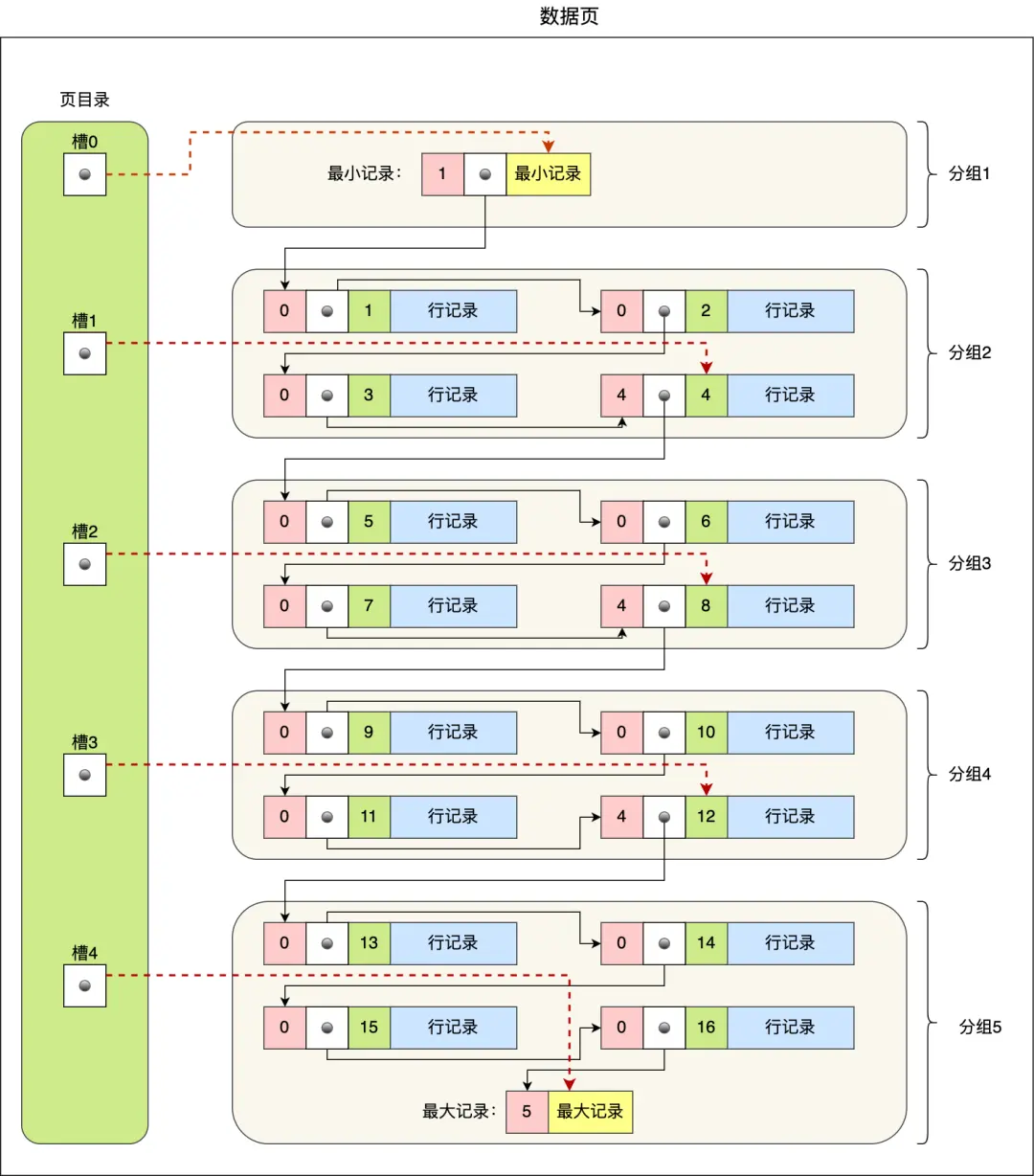
页目录就是由多个槽组成的,槽相当于分组记录的索引。我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录。
B+树的特点
- 所有叶子节点都在同一层,双向链表,适合范围查询。
- 非叶子节点存储键值,层高更少。
- 自平衡,良好的搜索性能。
B+ B区别
- 层高少;层高多,非叶子节点也存储数据
- 查询效率不稳定
- 双向链表
B+ Hash
哈希单点查询O(1)但不适合做范围查询
为什么MySql不用跳表
- 磁盘访问模式: 数据库索引通常存储在磁盘上。磁盘的特点是顺序访问远快于随机访问(尤其是传统机械硬盘)。B+树是专为磁盘设计的“矮胖”多叉树:
- 高扇出度(Fanout): 每个节点能存储大量键值(比如几百个),显著降低树的高度(通常只有3-4层)。查找任何记录最多只需要3-4次磁盘I/O。
- 磁盘块对齐: B+树节点的大小通常设计为等于或匹配磁盘块/页的大小(如4KB, 16KB),一次磁盘读取就能加载整个节点(包含很多键值)。
- 跳表的劣势:
- 指针开销大: 跳表需要存储多级前向指针(
next指针数组)。这些指针在磁盘上占用额外空间,降低了单个“块”内实际存储的键值数量。 - 访问局部性差: 跳表查找路径上的节点在磁盘上的物理位置可能是高度随机分散的。即使逻辑上是连续的,物理上也可能不连续。这意味着查找一个键可能需要多次随机磁盘I/O(最坏情况可能接近O(n)次I/O),在磁盘上这是性能杀手。
- 无法有效利用预读: 磁盘顺序预读(Read-Ahead)是提升性能的重要机制。B+树的顺序扫描(叶子节点链表)和范围查询能完美利用预读。跳表的随机访问模式无法有效利用预读。
- 指针开销大: 跳表需要存储多级前向指针(
联合索引的实现原理?
最左匹配原则
(a, b, c) a是全局有序的,bc是全局无序局部有序的
创建联合索引时需要注意什么?
建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
索引失效
- 左模糊匹配
- 联合索引不遵循最左
- 计算
- 函数
- or中有非索引
- 字符串和数字比较会发生隐式数据转换
如果一个列即使单列索引,又是联合索引,单独查它的话先走哪个?
- 查询成本
- 索引覆盖
索引优缺点
- 提高查询速度
- 占用空间大
- 创建索引和维护索引耗费时间,降低表增删改效率
怎么决定建立哪些索引?
- 唯一
- where
- group by order by
- 表中数据多
前缀索引
使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。
在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
索引优化详细讲讲
- 前缀索引优化:使用前缀索引是为了减小索引字段大小
- 覆盖索引优化:避免回表
- 主键索引自增:插入一条新记录,都是追加操作,不需要重新移动数据,减少页分裂
- 防止索引失效