数据结构(8)树-二叉树
一、用二叉链表实现二叉树
堆的特性(完全二叉树)使得底层用数组来实现更加容易,而正常我们的二叉树肯定用链表就可以减少空间的浪费,在这里我们写的只是一般的树及其相关操作,因此就用二叉链表实现。
1.二叉树结点
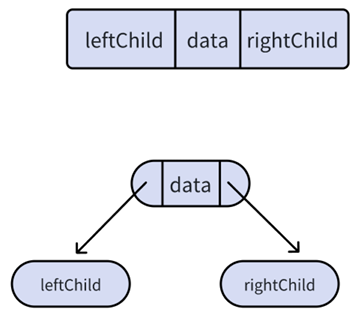
二叉链表所示,类似于链表,我们写二叉树的结构肯定是立足于结点,结点内容如上图所示:

data不用多解释,两个指针是因为指向的同样是二叉树的一个结点,所以给出的类型就是结点类型的指针。
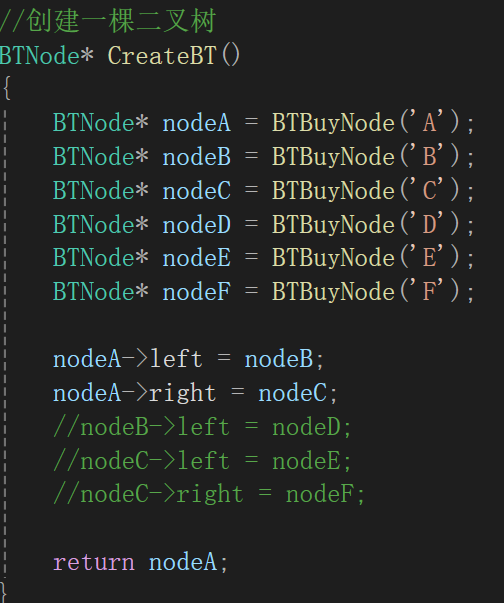
2.创建一棵二叉树
BuyNode方法不必多说:

接着就给出一棵二叉树:
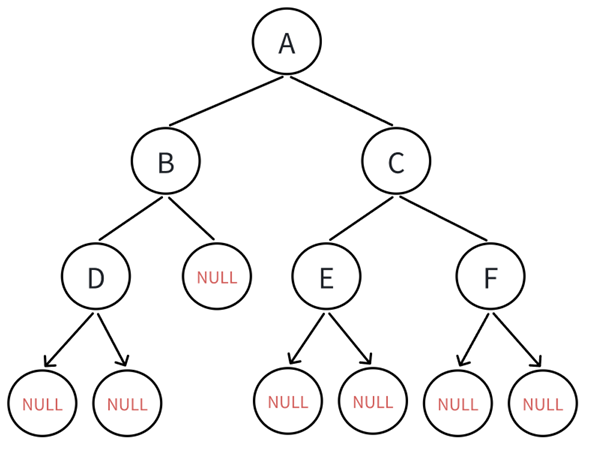
由于后面的操作都是基于这棵树,所以索性初始化的时候就按照这棵树来:

经测试符合要求。
二、二叉树相关操作
1.注意
二叉树,或者说我们这里一般的二叉树就不进行插入删除操作的实现,因为是在太复杂,就是说,一棵树的删除,你可以去删除任意的结点,比如说删除,free倒还好,free完以后二叉树的结构怎么办?或者说插入,任意位置都可以插入,插入以后结构怎么办,谁会知道。
这就是一般二叉树我们不做的操作,后面比如平衡树,左右子树高度差不能超过1,比如:
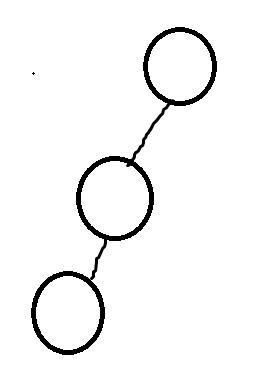
左子树深度为2,右子树深度为1,这么看好像不平衡一样,所以它的插入和删除都是有迹可循的,也就是结构的改变可以兼顾到,所以这里我们不做插入和删除操作。
2.二叉树的遍历
①概念及分类
我们后面的任意操作,比如查找,比如计算结点的总数等,光想想肯定都得遍历,所以这样就不得不学会遍历二叉树。
二叉树的遍历分为三种:先序遍历,中序遍历,后序遍历。
或者说先根遍历,中根遍历,后根遍历。
后面这种说法可能更适合理解这几种遍历的区别:
先根遍历,就是先遍历根结点,再遍历左子树,再遍历右子树(子树也是这样的规律)。(根左右)
中根遍历,就是先遍历左子树,再遍历根结点,再遍历右子树(子树也是这样的规律)。(左根右)
后根遍历,就是先遍历左子树,再遍历右子树,再遍历根结点(子树也是这样的规律)。(左右根)
不管哪种遍历方式,肯定是先左子树再右子树,这个毋庸置疑。
②先序遍历
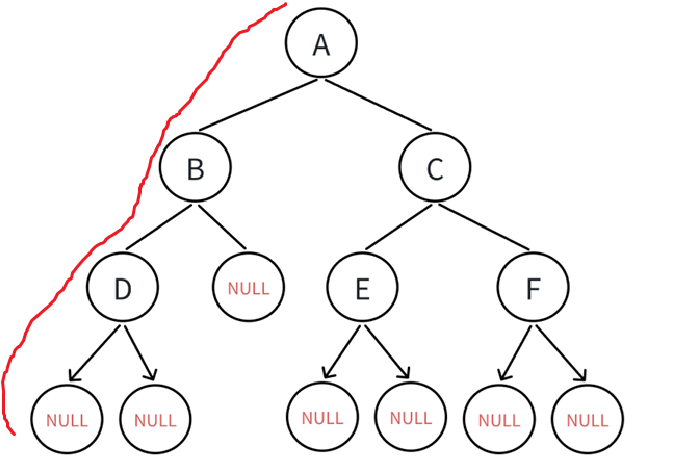
比如把我们创建的二叉树拿过来:
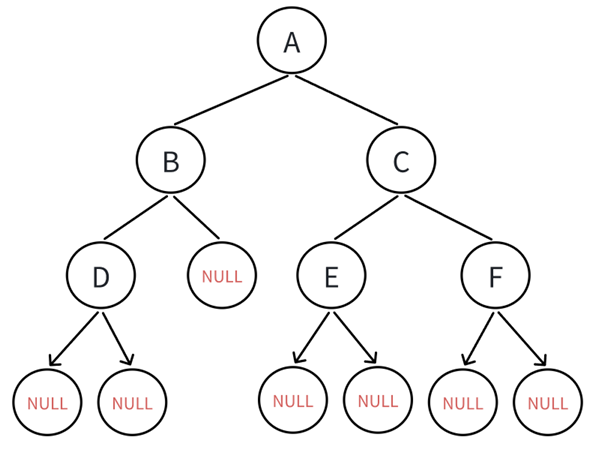
如果先序遍历就是(下面以红色表示向下寻找,绿色表示向上回溯):
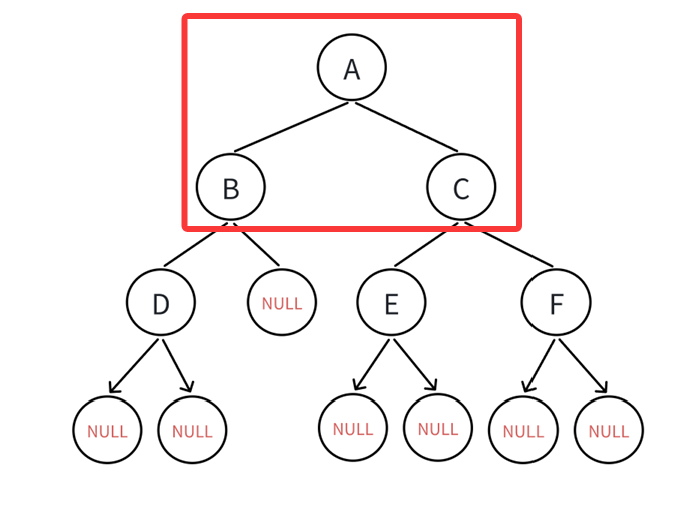
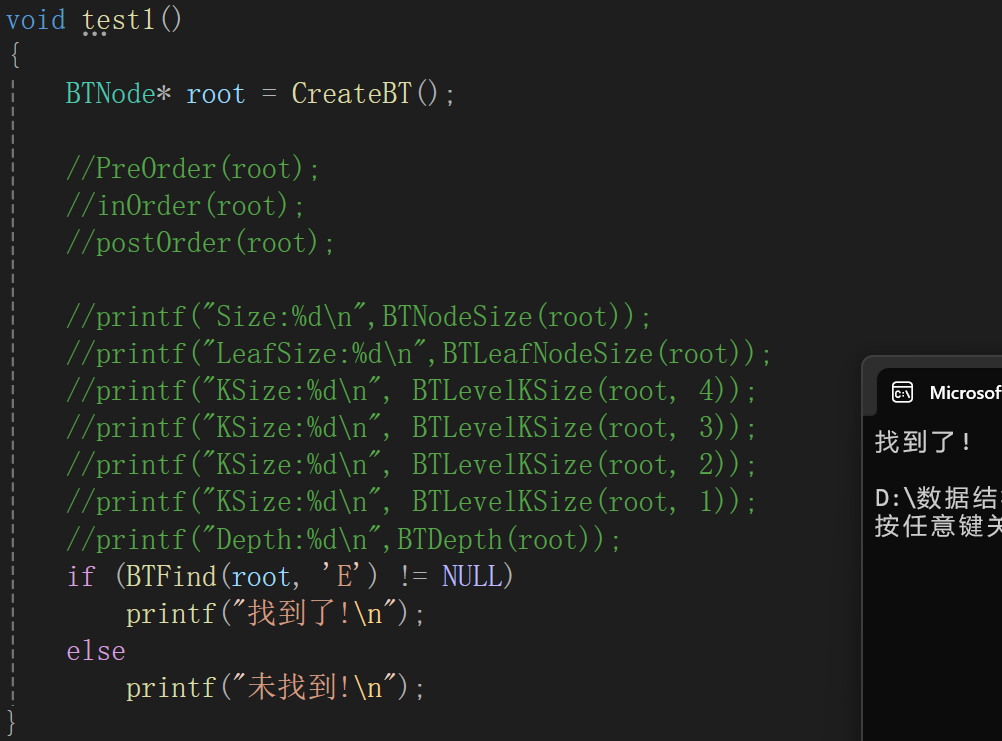
从二叉树的根结点开始,A为根,就先遍历A(根),再遍历左子树,当然,左子树也得按照先序遍历的顺序(根左右)来:
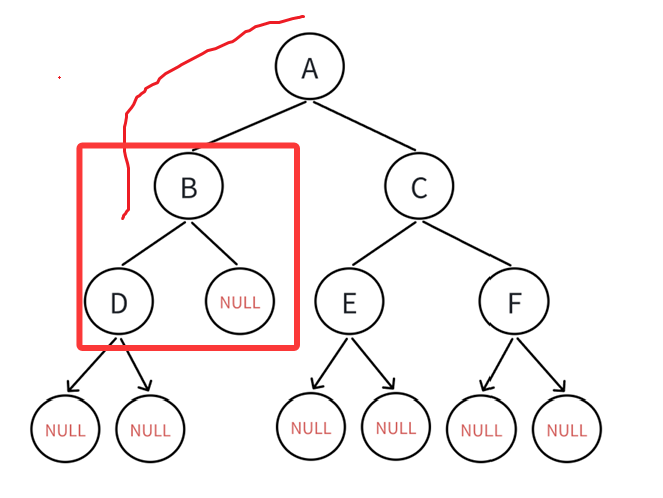
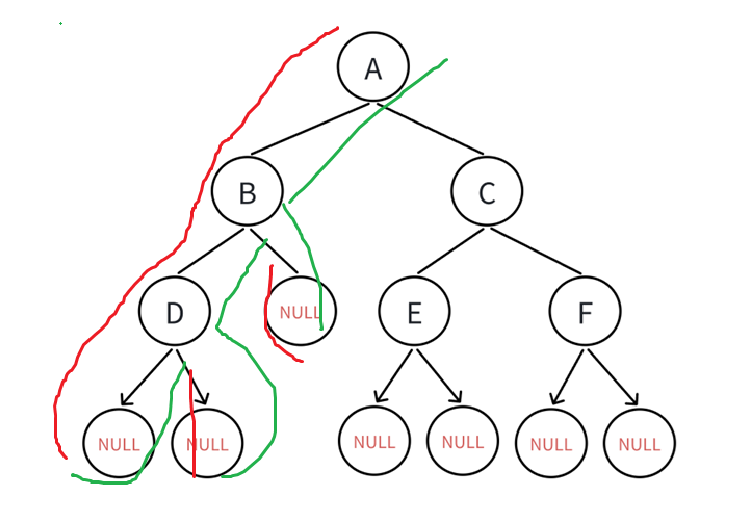
那接下来就是遍历B,有左子树,再转到左子树:
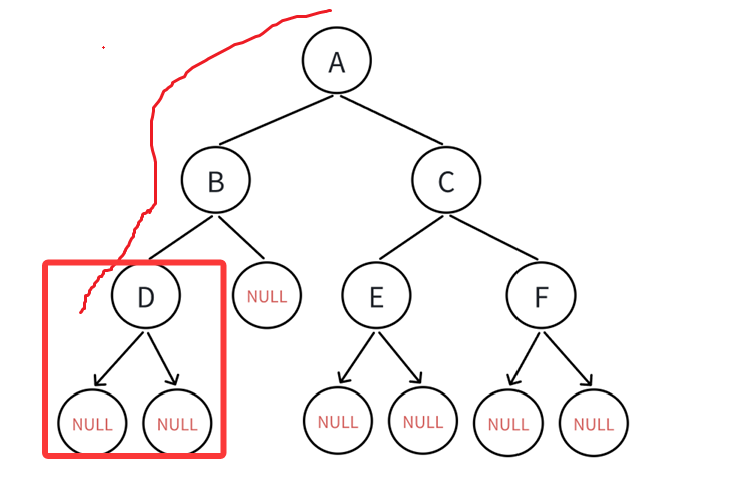
一样道理,遍历完B以后就继续找左子树:
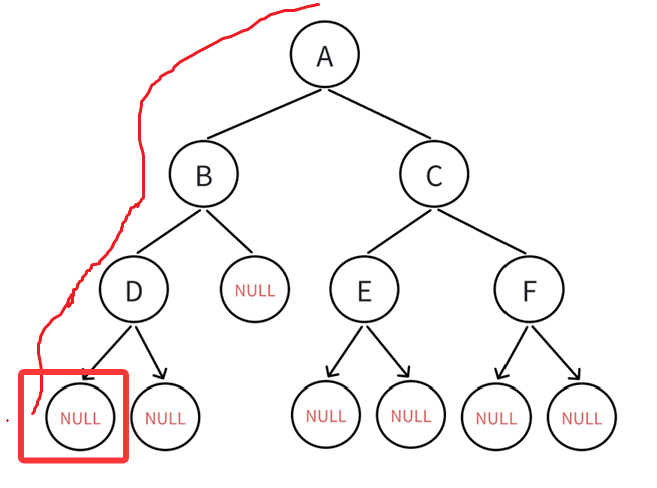
只不过这次遍历到空结点了,空结点报没有子树的,这个时候就该回溯到根结点,遍历右结点:
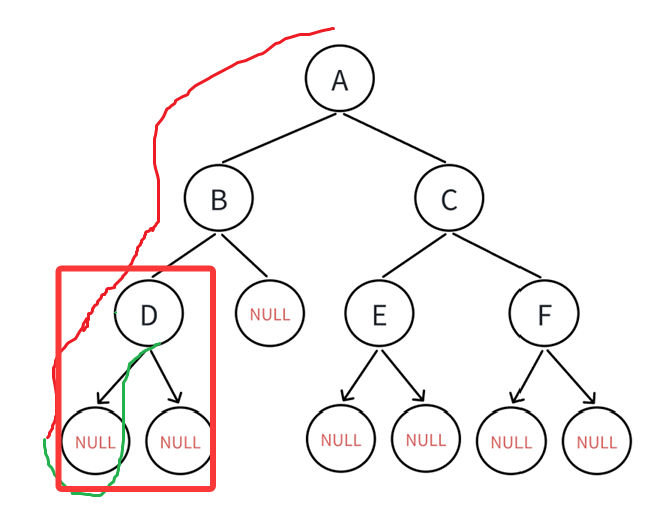
可见还是为空,那遍历完就该回溯:
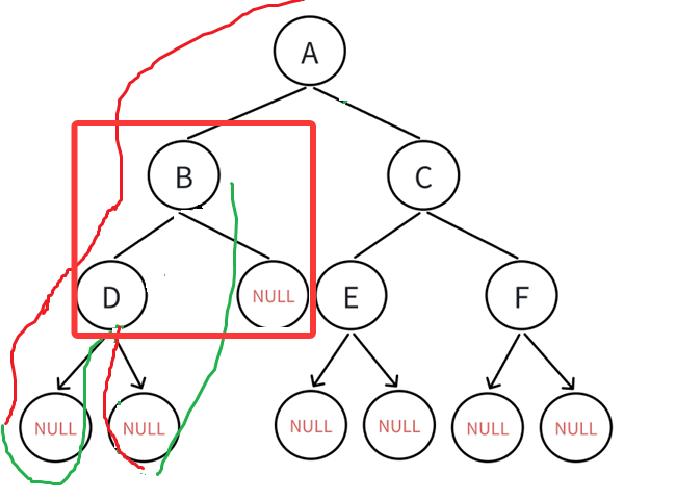
并且发现D的根左右都遍历过了,继续回溯,B的左子树遍历完毕,接下来就是B的右子树:
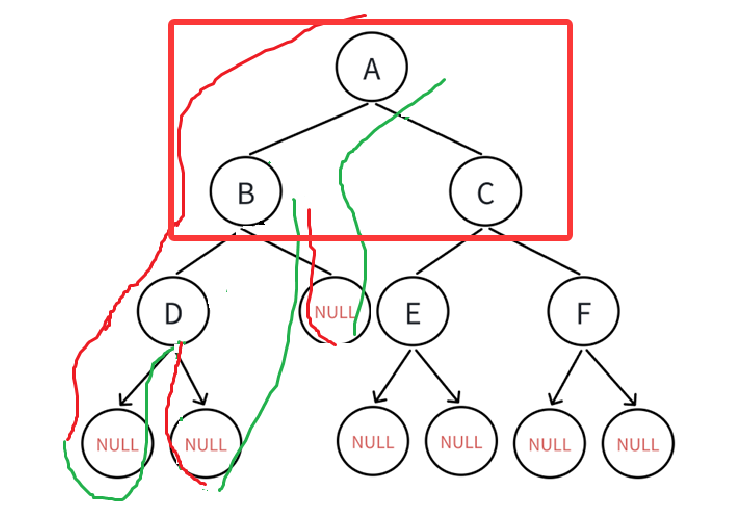
遍历完继续回溯,现在A(根),A的左子树都遍历完毕,接下来就是A的右子树,还是一样的道理,不再说了,直接给出最后的遍历顺序:

其中N表示NULL。
代码实现:

代码很简单,原因是使用了递归:递归使用是在情况相似,比如数列的前一项和后一项的递推公式,或者了解递推时举的阶乘的例子(每次都是*n-1);递归代码实现需要回溯,而我们二叉树遍历的思路很好的照应了这一点,即以某一结点为根结点,根结点自己都是NULL,那么肯定没有孩子,只能返回上次遍历根结点进行下次操作,这就是回溯;第一个printf遍历了根的数据,下面分别是以根的左结点为根展开的子树,实际操作和最开始根相同,所以运用递归,还有以根的右结点为根展开的子树,道理相同,借助函数画出图是这样的:
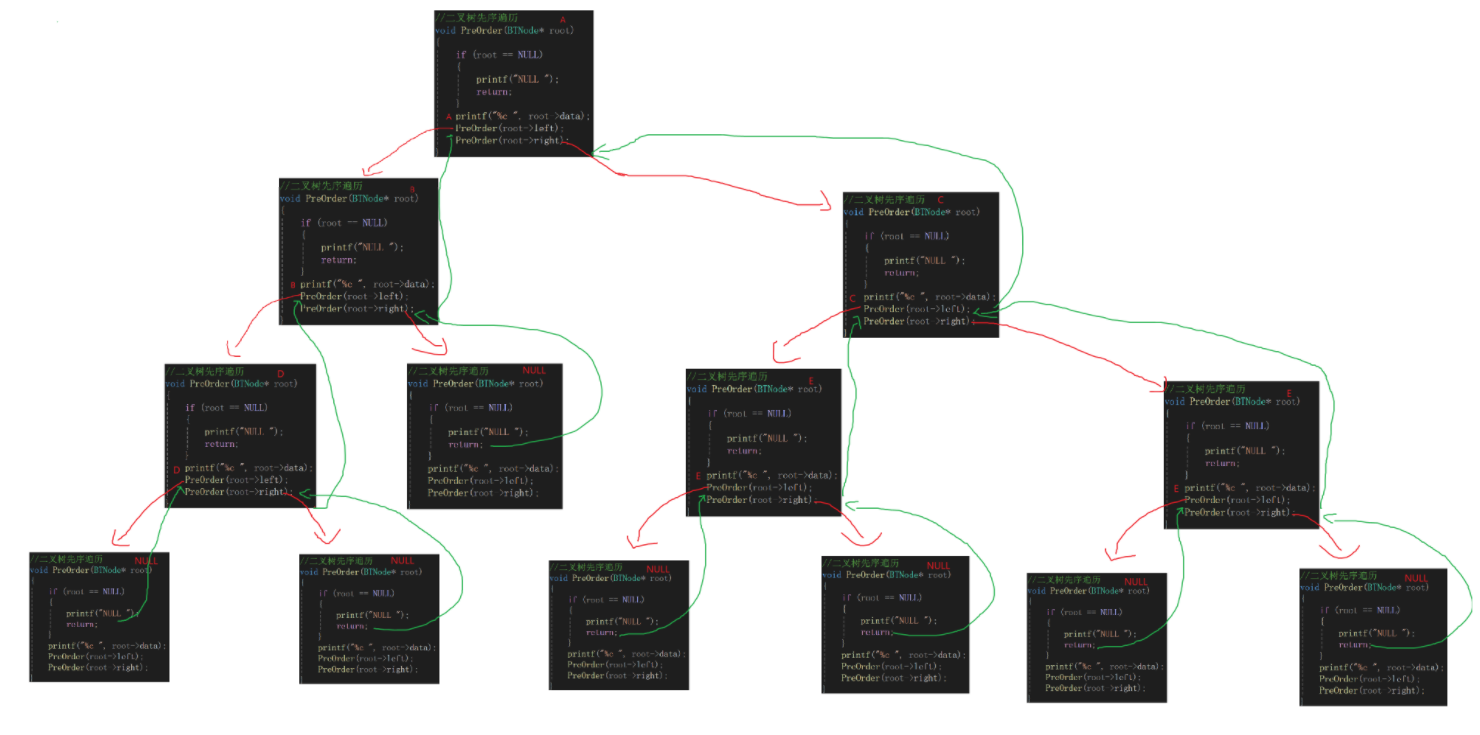
从右子树回来以后已经把所有递推的函数回归完毕,所以先序遍历结束,测试代码有:

③中序遍历
再解释一下中序遍历,后序遍历直接就给出了。
中序遍历实际上是左根右,也就是有左子树就疯狂往下找左子树,直到碰到NULL之后就回溯:
很明显直到碰到D的左子树的NULL才停止寻找,并且返回上一层根结点(D),所以遍历的结点就是N ,根左子树遍历完毕以后就是遍历根自己,也就是D,最后遍历右子树N,以D为根结点的B的左子树遍历完毕就遍历根本身,就是B,然后右子树N,又使以B为根结点A的左子树遍历完毕,在图上就是:
右子树同样要左右根,不再赘述,直接给出:

代码:

左根右已经体现,测试代码:

④后序遍历

代码:

测试代码:
 3.二叉树结点个数
3.二叉树结点个数
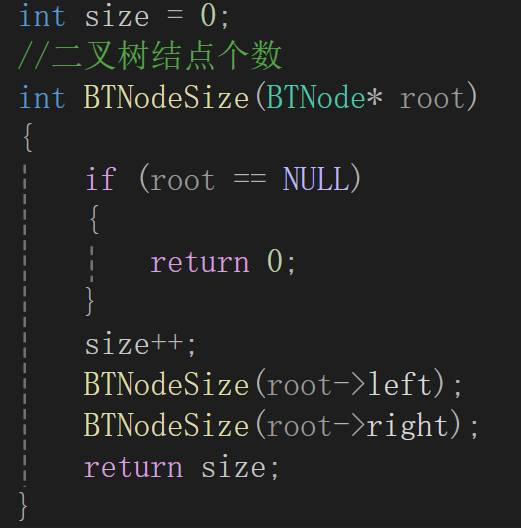
遍历的时候发现递归来遍历二叉树是真舒服,所以计算结点个数还是想想怎么往递归靠。
容易想到,每遍历到一个不为空的结点就++呗:

一弄懵逼了,一看就看出来哪错了,size我们在计算的时候,每创建一个函数栈帧,size都是重定义为0,是空返回0,不空返回1,但是新创建的函数栈帧的1并不会累加到这次展开的函数栈帧,如:
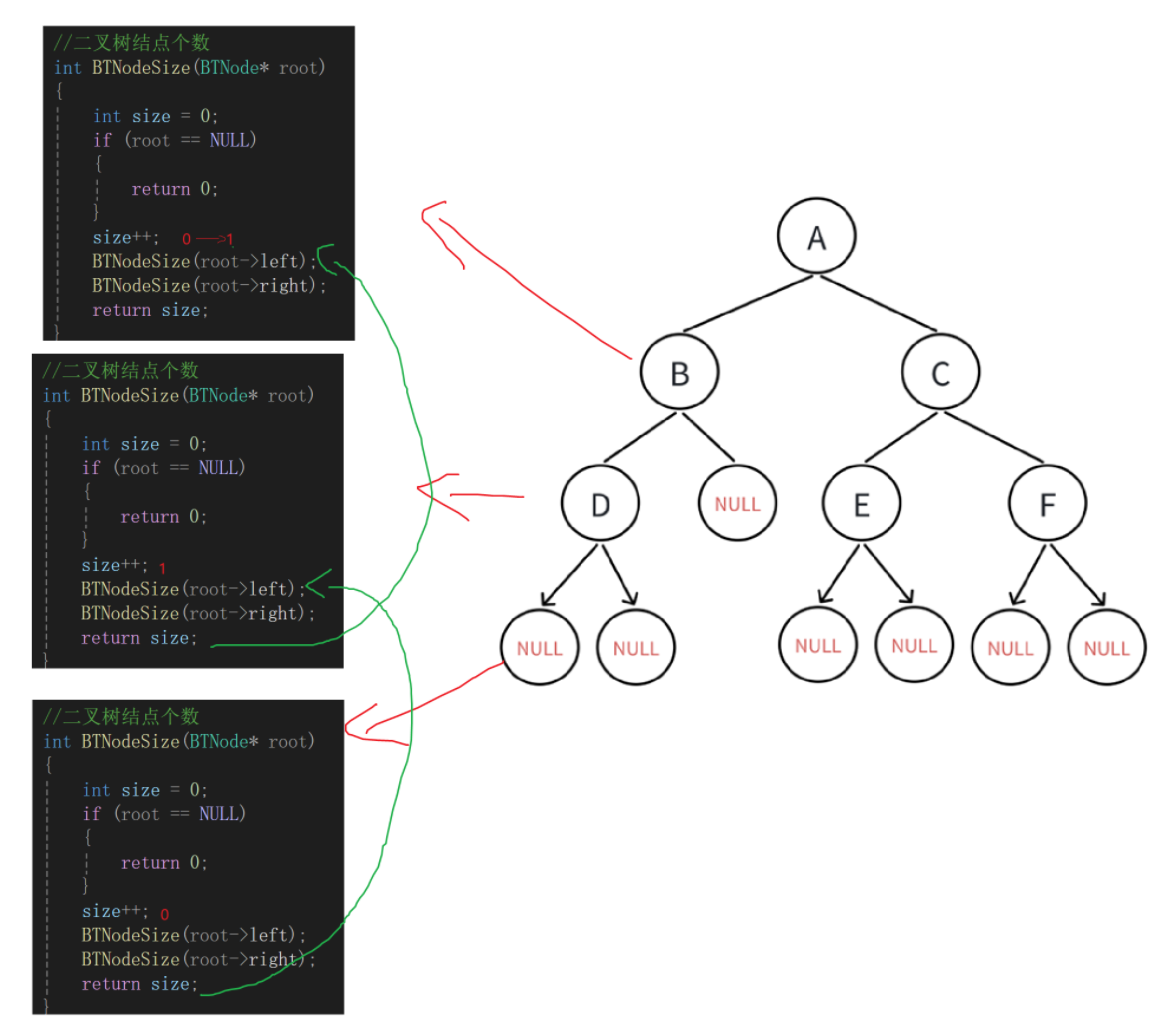
发现return并没有对size产生影响,因为size是局部变量,值的改变不改变原来的结果。
可能有的人就想说,干成全局变量(或者static修饰)不完了:
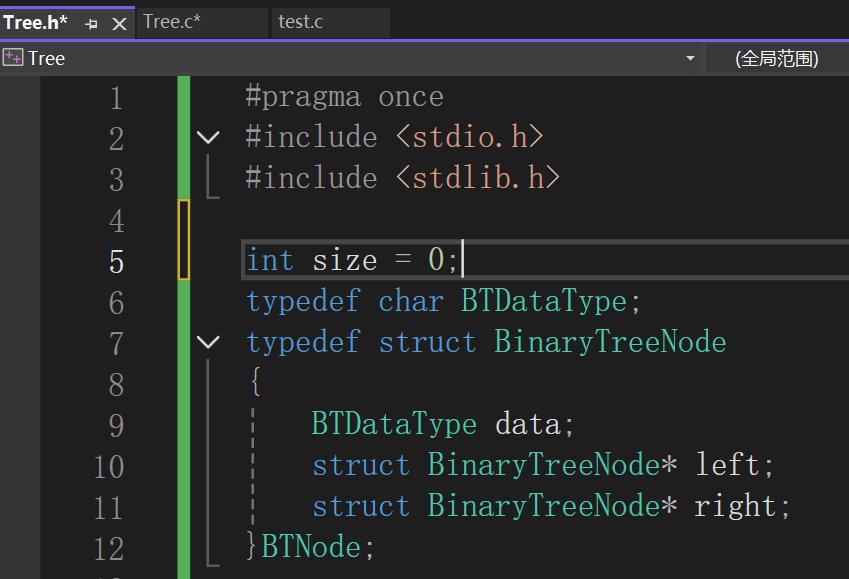
这时候再运行:
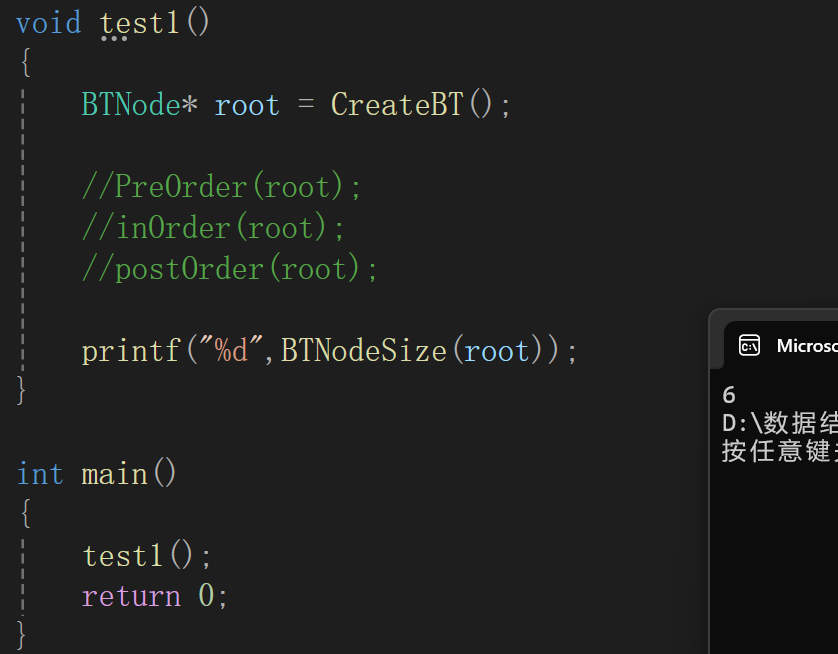
我可不说大功告成,全局变量每次都不变,所以如果多次调用:
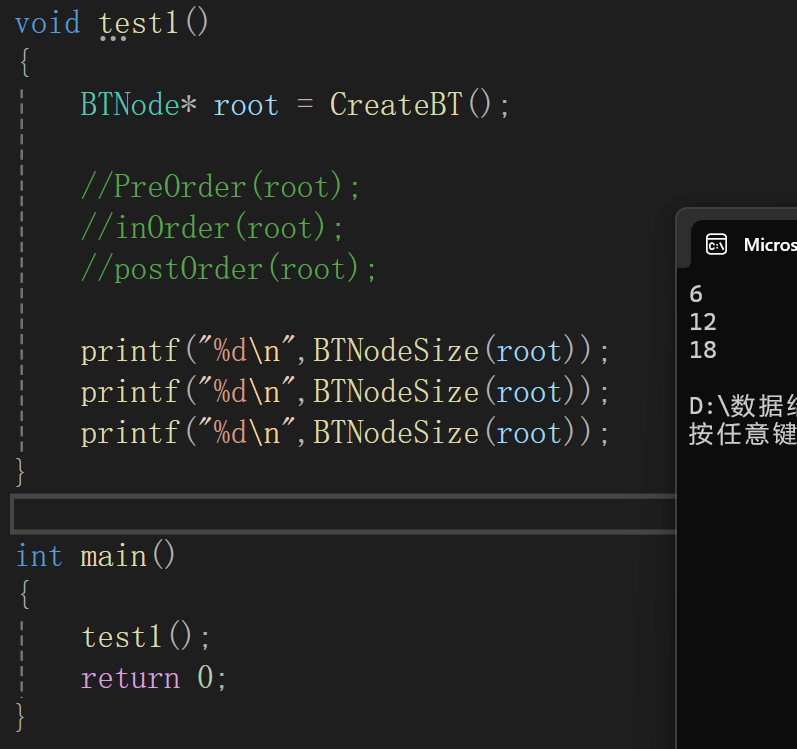
原因很简单,全局变量值不销毁,出函数也存在,除非手动置空,但是我们size放在实现文件里,很明显,在运用我们实现的操作前,用户并不知道还得手动置空,也不知道我们用的记录的变量是size,所以核心还是做到新创建的函数栈帧对原来的函数栈帧产生影响,因此就这么写:

当然,更简单的就是:

公式就是自己+左子树结点个数+右子树结点个数,其实还挺好理解的。
同样测试:
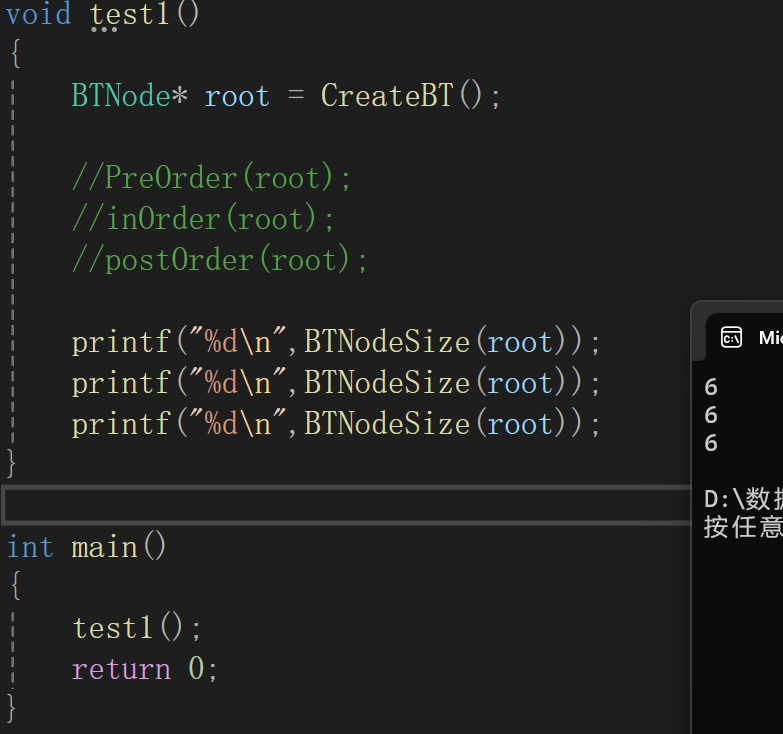
4.二叉树叶子结点个数
叶子结点是左孩子和右孩子全为空的结点(当然,自己不能为空才能解引用):
思路还是算左右子树叶子结点个数,当然,如果只有根结点的树就得返回1,刚好和找到不止只有根结点的二叉树判断条件相同,而且答案也符合要求。
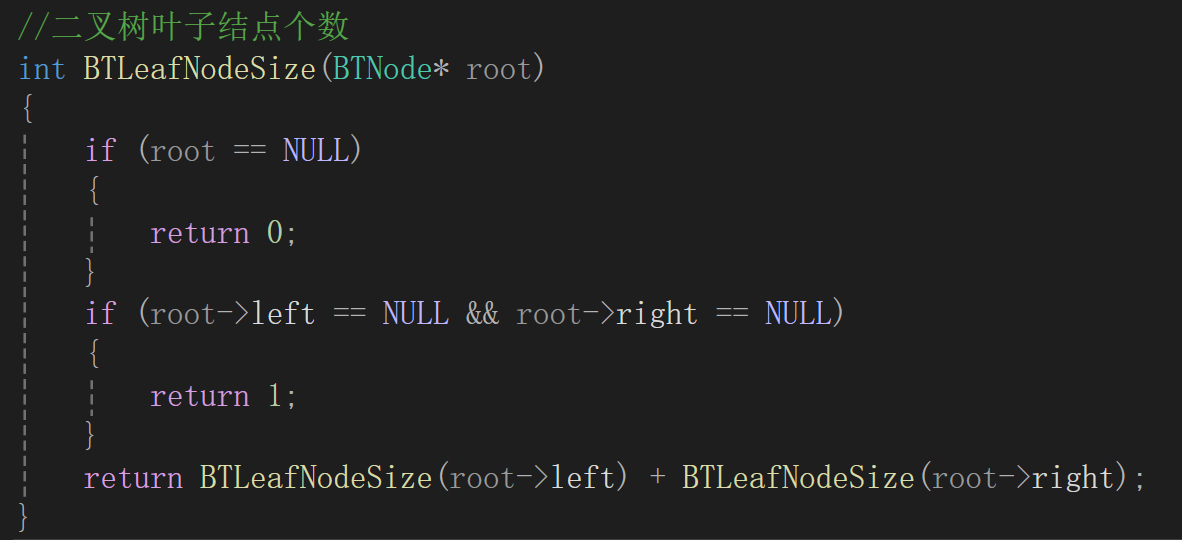
可以说体会到递归的强大了。
测试代码:
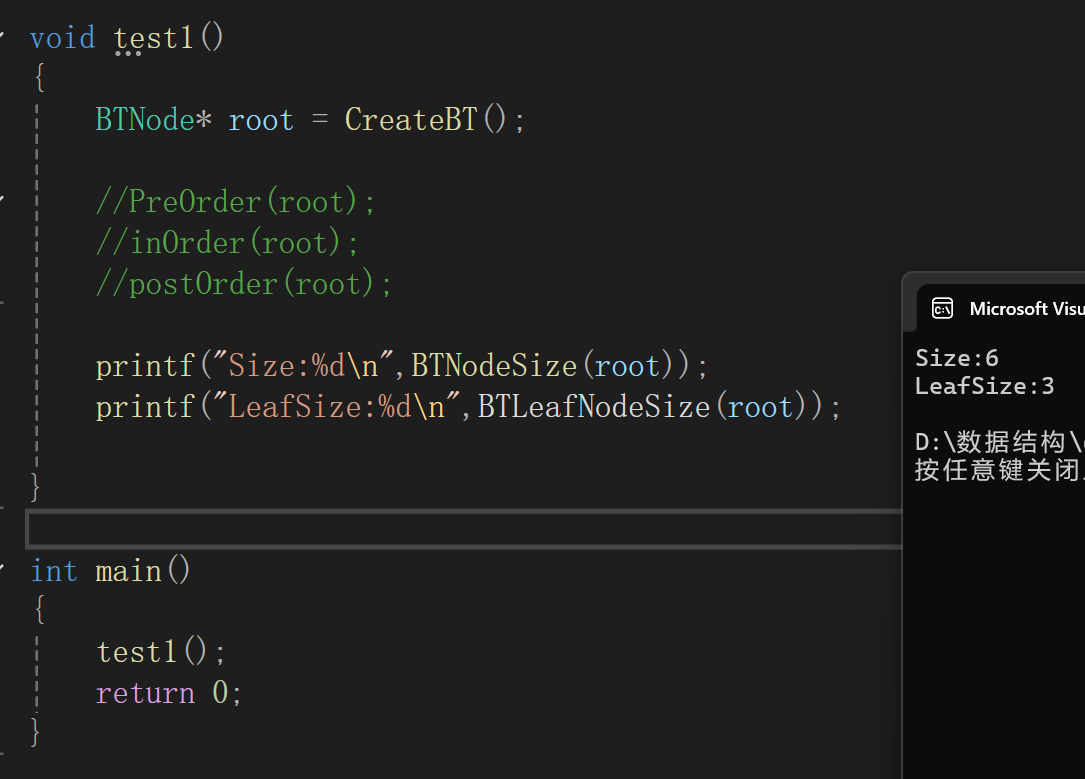
拉过来树:
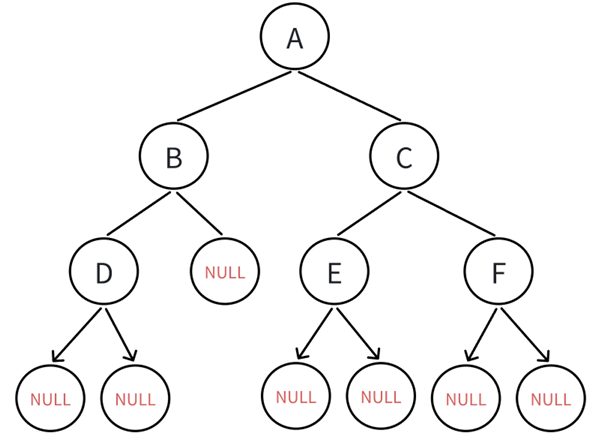
一点没毛病,完美。
5.二叉树第k层结点个数
第k层肯定得作为一个参数,则这个操作的实现至少两个参数,一个参数是树的根结点,一个参数是第k层,如何实现呢,比如第3层:
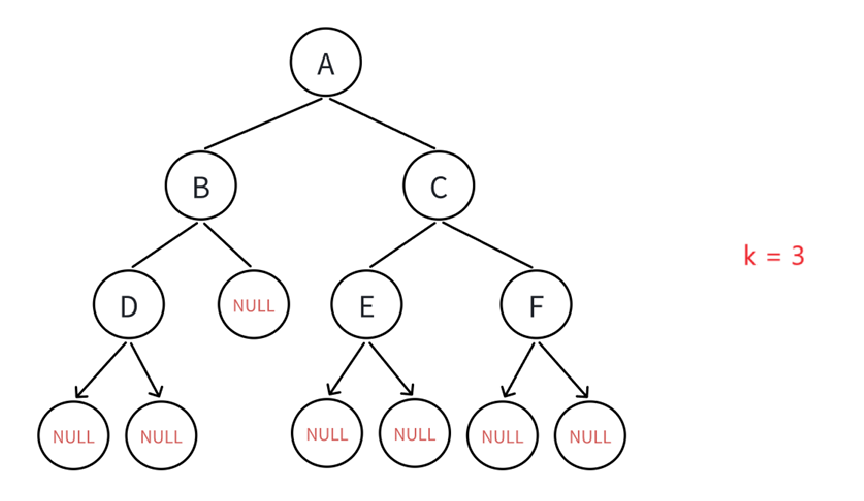
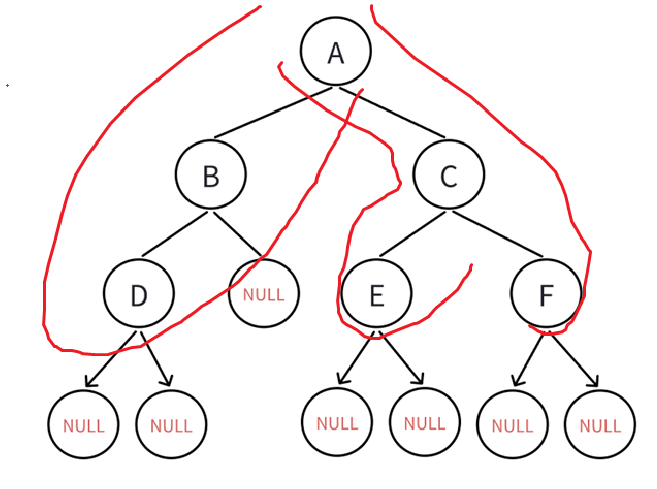
遍历顺序肯定无所谓了,甭管怎么遍历,反正最后你得给我计算出来第三层的所有非空结点个数,计数还是同理,每碰到一层让k--,直到k == 1说明已经到需要计数的层了,如果这个结点不为空返回1即可。
可见我们思路还是从最开始的树出发,计算左子树第k层结点个数,计算右子树第k层结点个数,判断到没到达第k层就看传过去的是不是1。
测试代码:
6.二叉树的高度/深度
其实查找深度基本上算是找那棵树的深度最大,一条路径遍历到底部的标志显然就是root->left == NULL&&root->right==NULL,说人话就是查找到一个子树的叶子结点为止,而且很重要的是最终肯定要取最大值,公式大概是根结点左子树深度与右子树深度最大值+1(因为根结点也要算上):

测试代码:
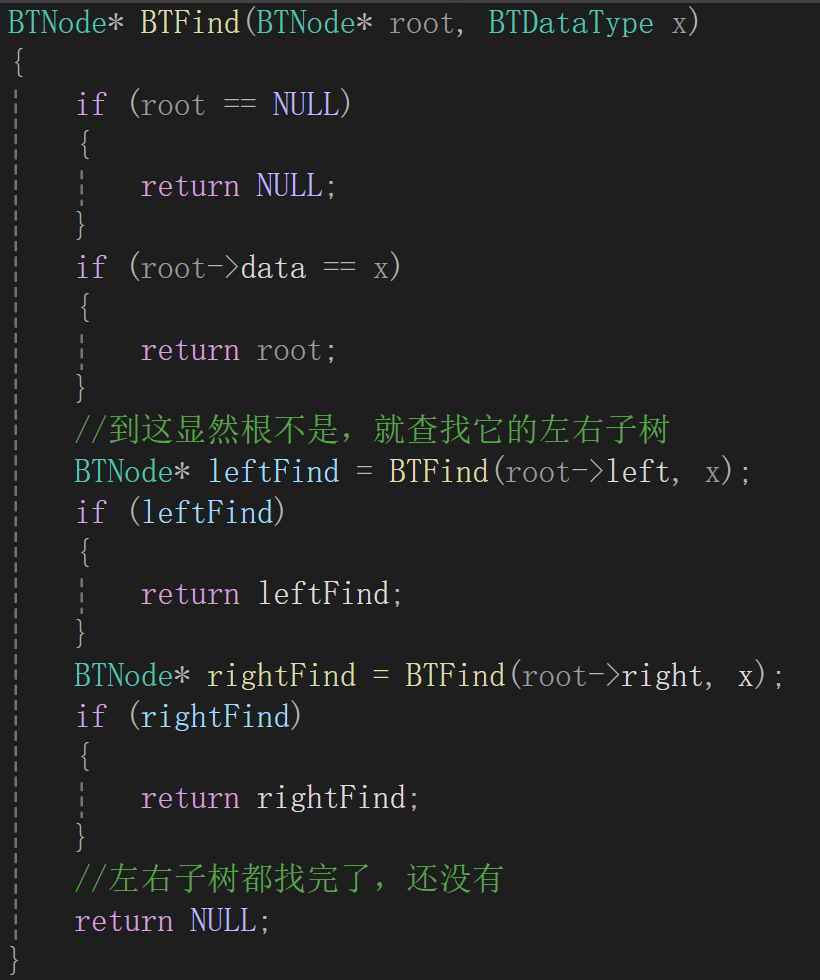
7.二叉树查找值为x的结点
还是说查找免不了遍历,遍历顺序其实想了想也没啥要求,反正查找到就返回,查找不到返回NULL,还是用递归的思路,根不是就查找子树,返回值很明显是二叉树结点类型:
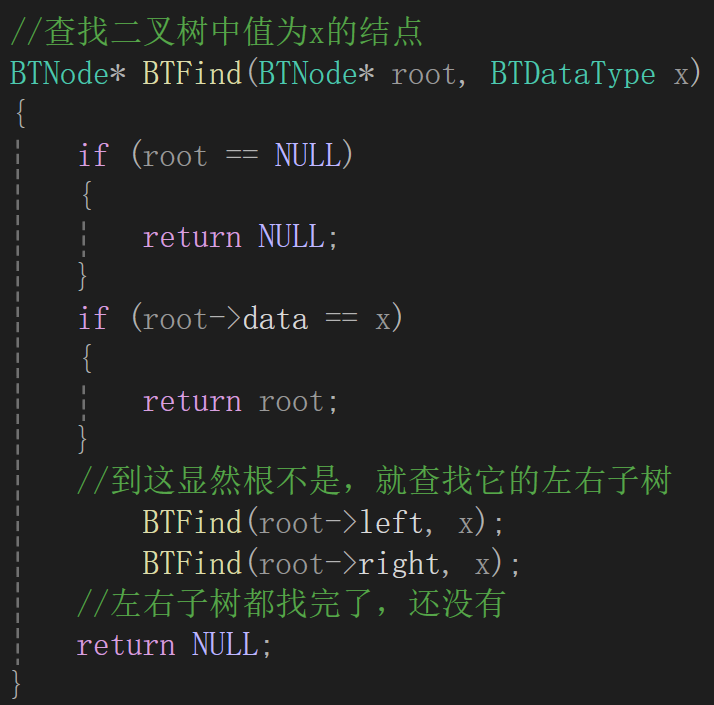
这么写倒是挺符合思路的,但是一测试:
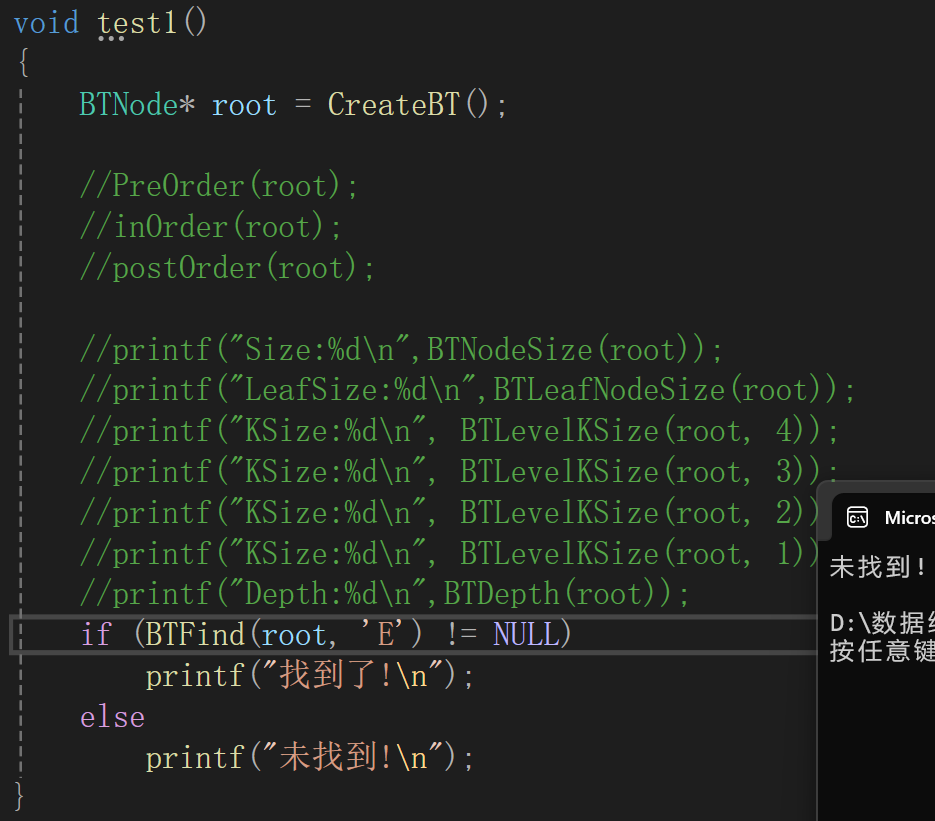
说明出bug了,但是我仔细想了想好像没啥毛病,索性直接就调试,由于递归的调试结果实在不好展示,就不再写了,大概就是只能一条路走到黑:
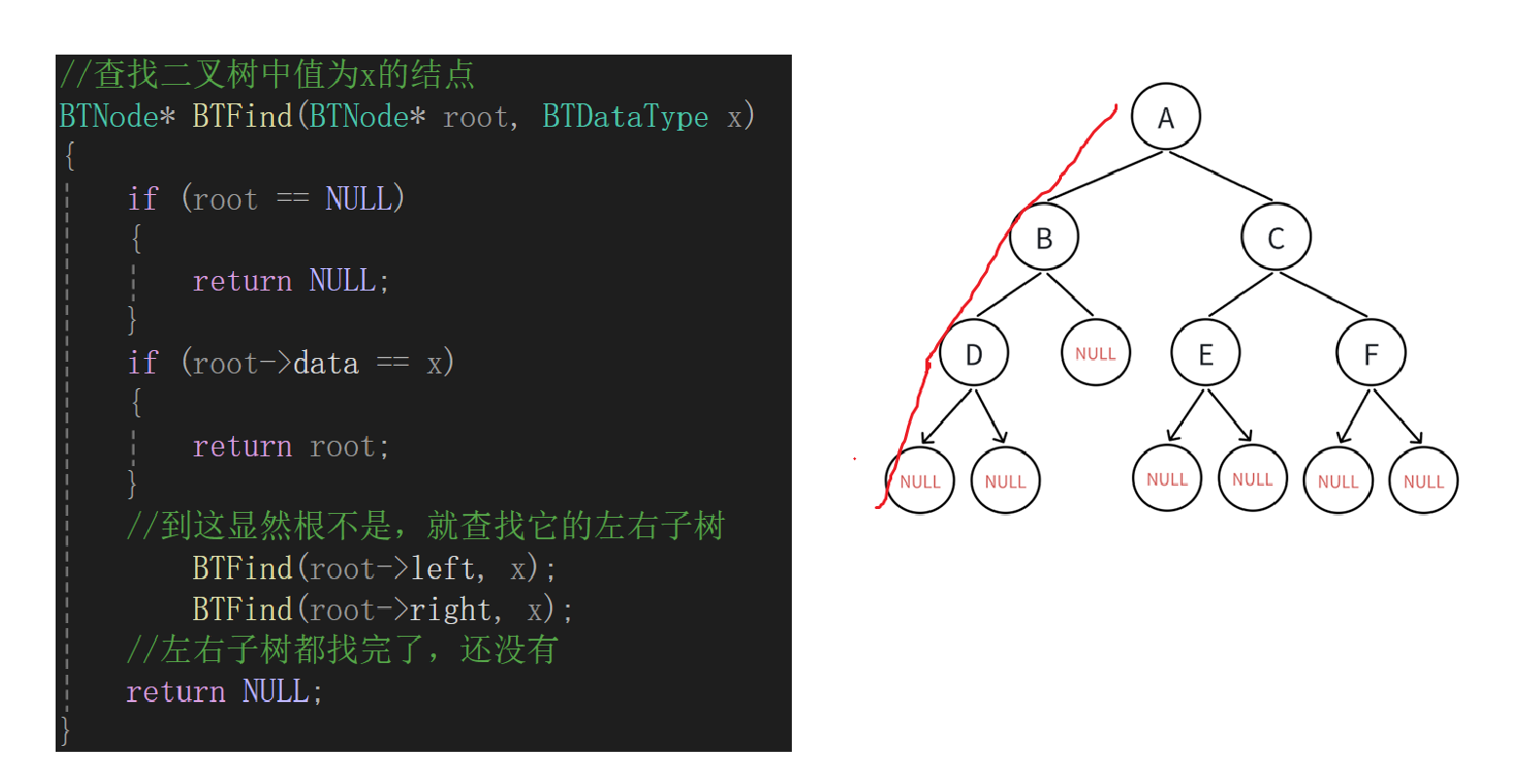
顺着这样的代码走下去,只能走二叉树最左边的那条路,如果遍历到空,直接return了,原因就在于第一次写出来的代码很明显根本没有递归出去,因为在左子树和右子树查找的过程中根本就没有管返回值,这样的话,并不是遍历完整棵树或者找到目标结点而停止递归。
观察到找到目标结点时指针非空,索性判断一下子树的返回值:
测试代码:
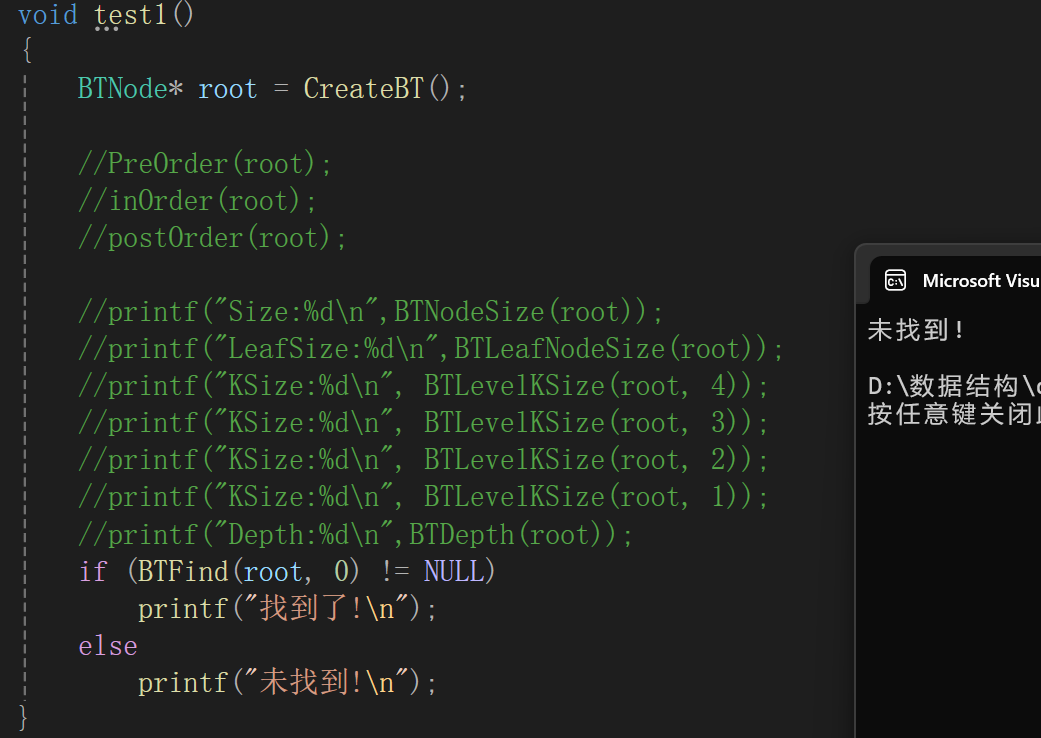
8.二叉树的销毁
遍历完二叉树的结点,一个一个free掉,不过这次可就要求顺序了,因为我们构建二叉树用的二叉链表,二叉链表只包含两个孩子的指针,也就是说,如果free掉根结点先,那么肯定就会把它的孩子结点给漏去,因此采用类似于后序遍历的方式,最后free根。
代码:
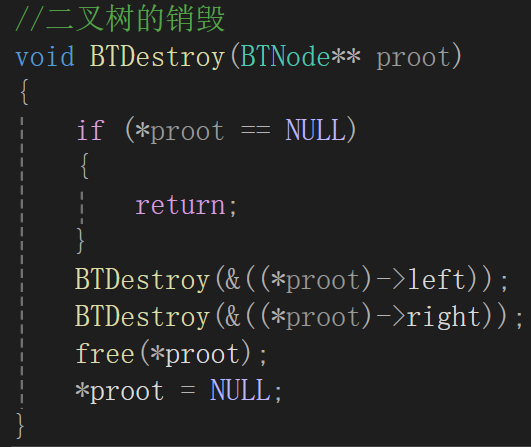
最需要注意的点就是,因为函数形参的改变要影响实参,那这里不能再传root存的二叉树根结点的值,而是传二叉树根结点的地址,以便于到时候通过这个二级指针proot可以真正修改掉一级指针root。
测试代码:
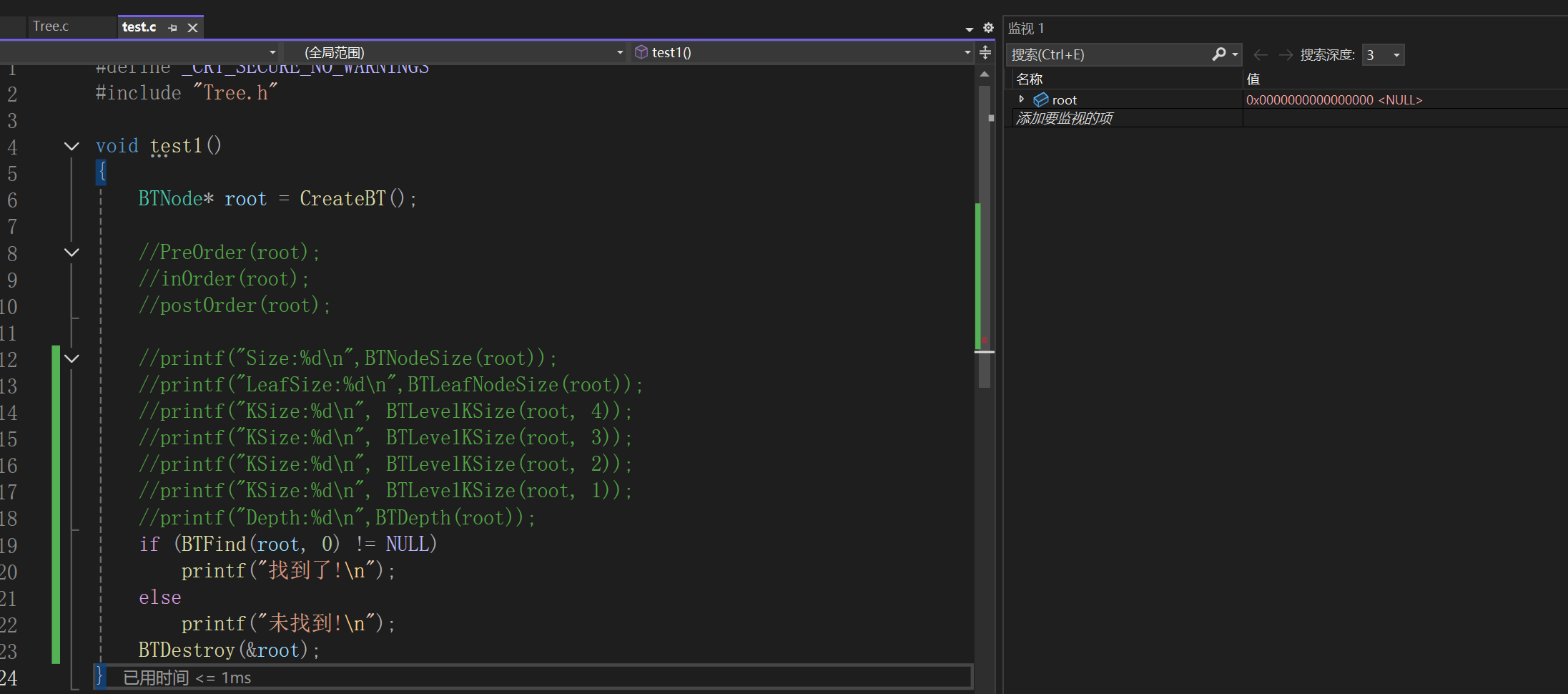
三、二叉树的特殊遍历及其应用
1.层序遍历
在二叉树相关操作中我们见识过了前中后序遍历二叉树,前中后代表的是根结点在左右子树遍历中的顺序,层序遍历正如这个名字,从上到下从左到右一层一层遍历二叉树的结点即可,仍然举上面的例子:
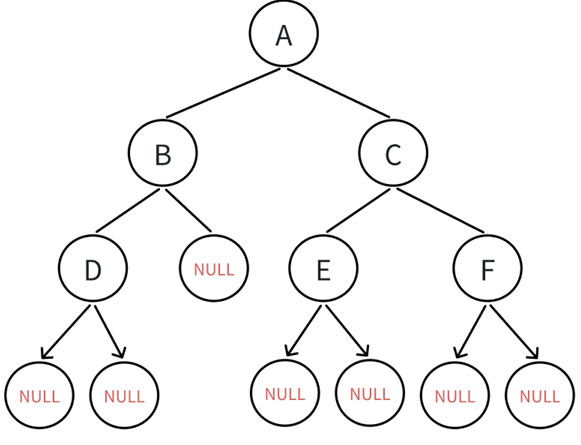
也就是说,层序遍历就是:ABCDEF
说着容易,写代码难,我们在上面做的那些都是借助递归,一条一条路去遍历,类似于这样:
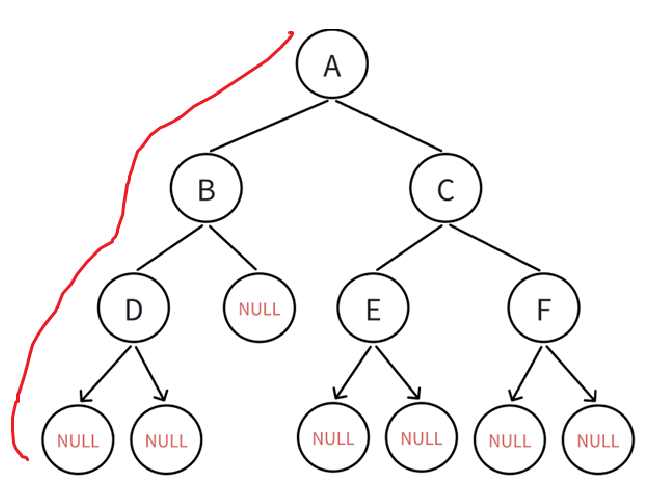
返回不再演示。
但是现在要做到这样:
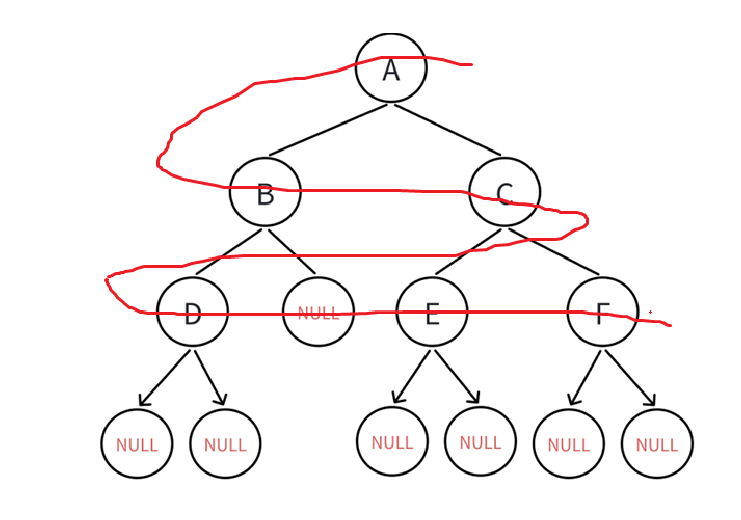
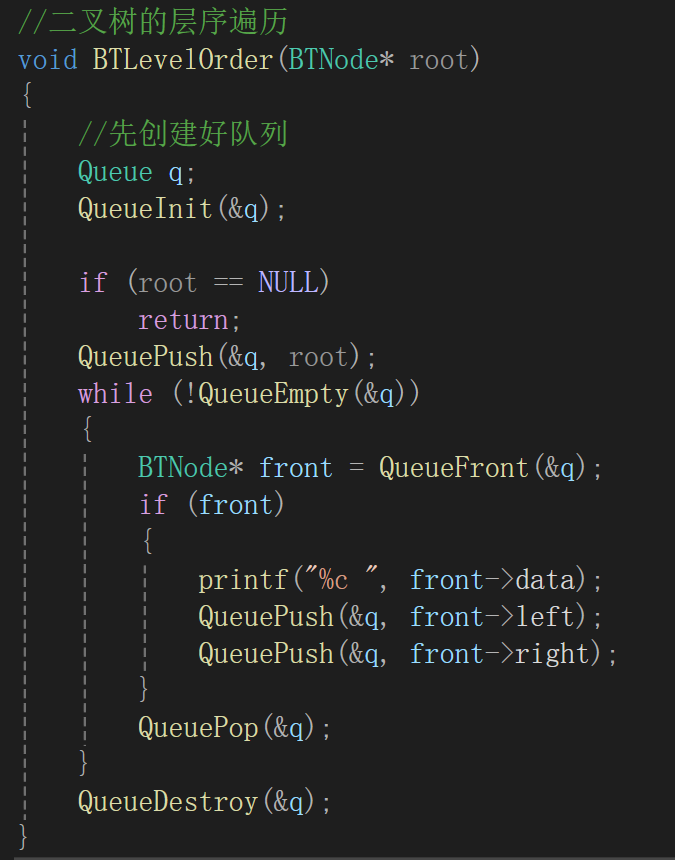
直接给出结论了,我们需要借助数据结构——队列。
简单回忆一下队列的特性,队尾进队头出,所以我们需要弄清楚什么顺序入队列和出队列才能做好层序遍历。
当然免不了把我们实现过的队列的代码拿过来:
需要修改的就是队列存放的元素类型,很明显,我们到时候遍历拿到的都是结点的地址,即BTNode类型的。
但由于typedef的特别,不能直接写BTNode,如果这么写了,编译器不知道你写的是什么(其实这一点我也不知道为什么,姑且认为编译器没那么智能,最会识别就是结构体算了)需要带上struct,写成struct编译器知道是重命名一个结构体变量才能老老实实的找和替换(改名前改名后都可以,即:struct BinaryTreeNode*或struct BTNode*,重点是struct关键字)。
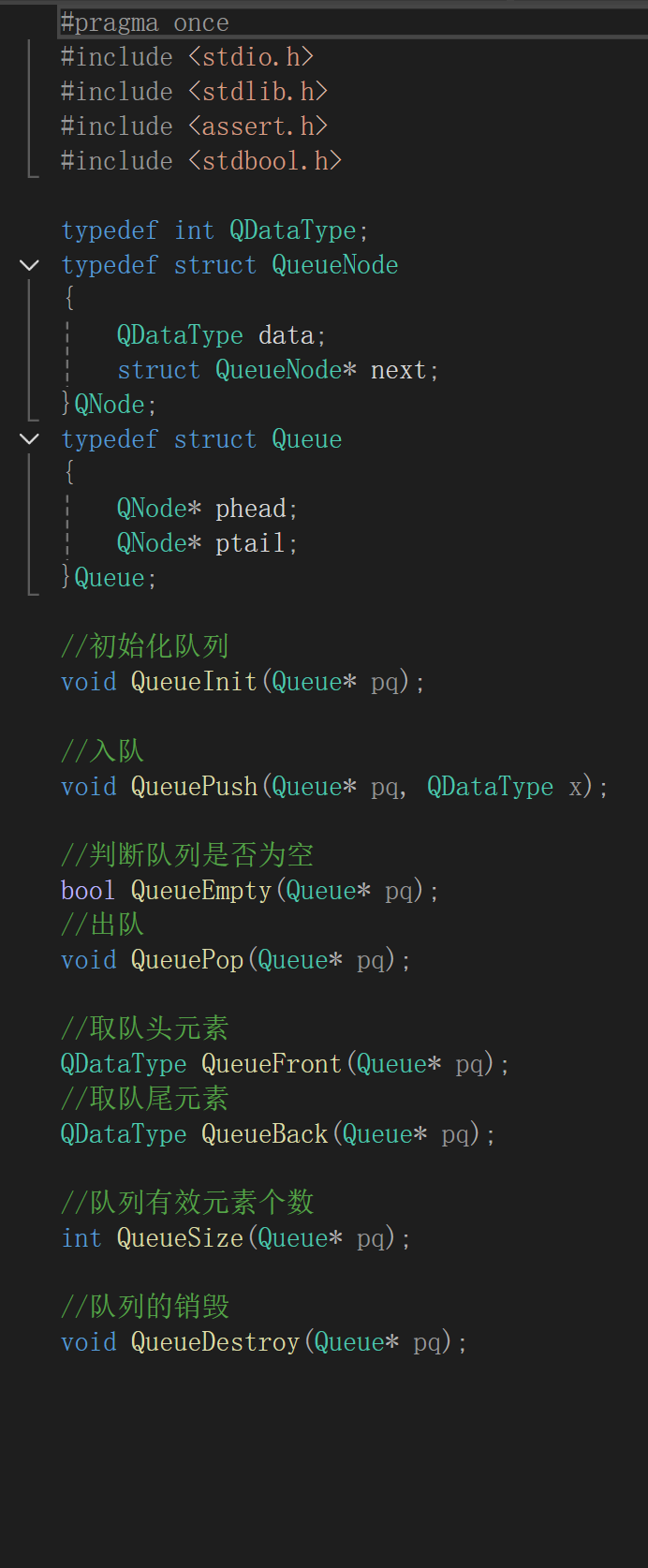
毋庸置疑的是,我们最开始肯定得让树的根结点入队列:
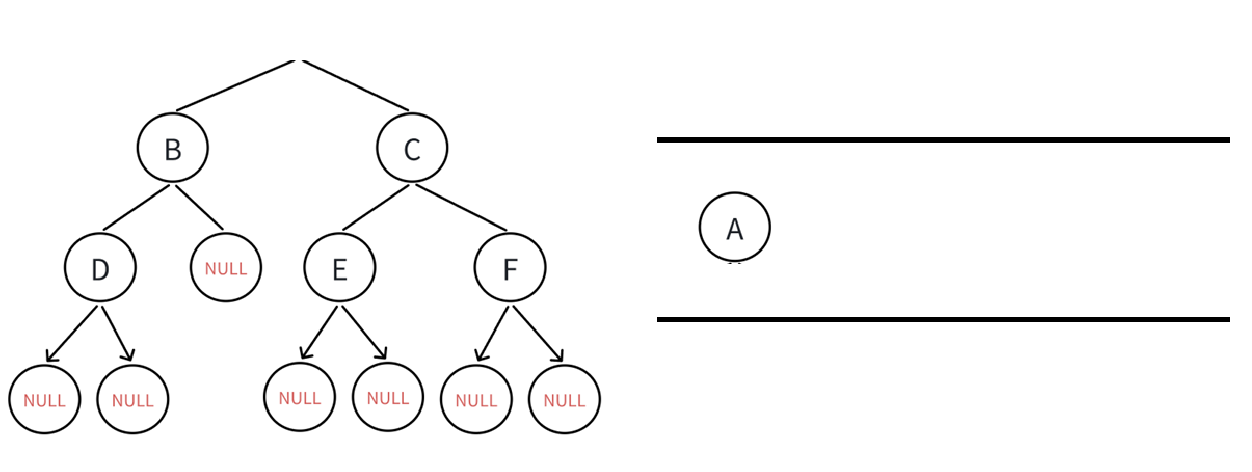
随后A可以访问到B C结点,我们如果不同时入,那么等A出队列直接就访问不到了,所以A出队列时应该按先左后右的顺序让它的孩子结点入队列:
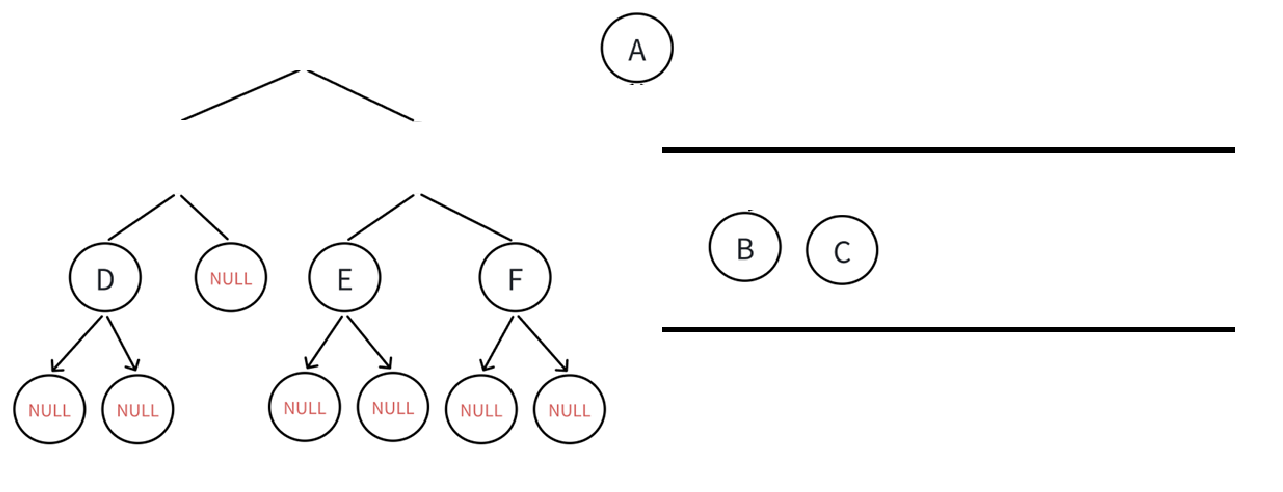
重复以上操作,即每次出队列的结点的孩子结点入队列:
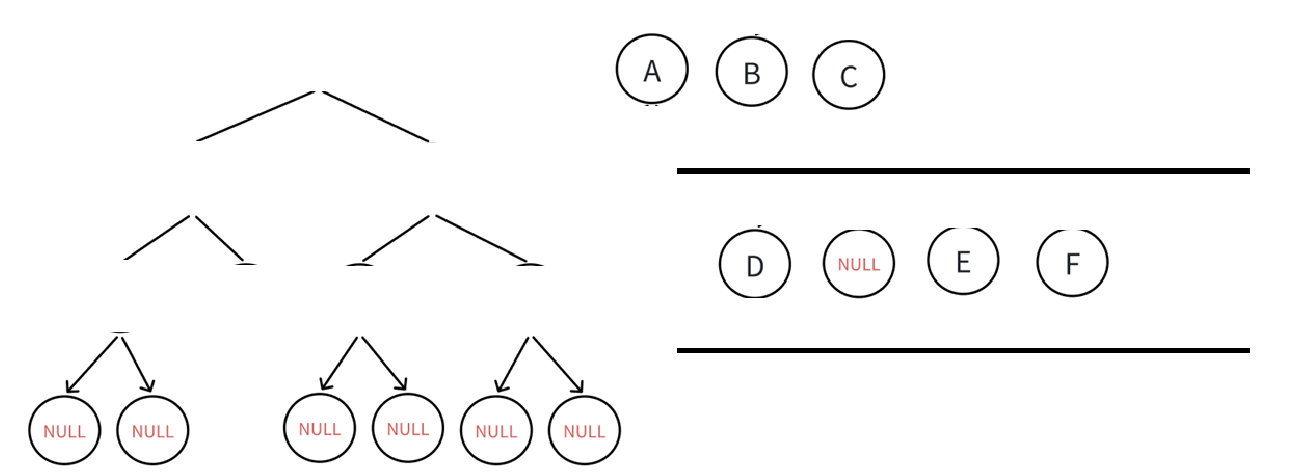
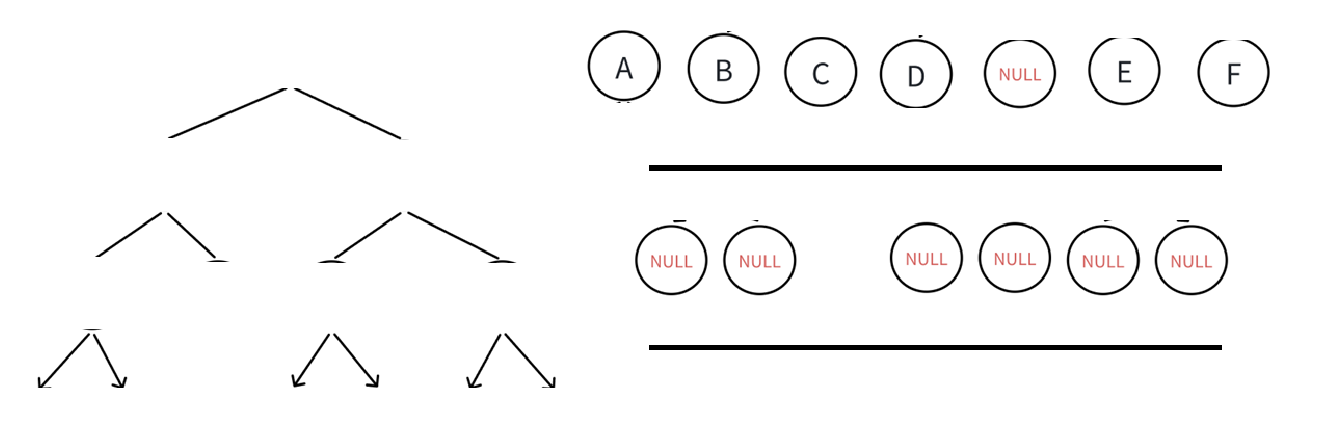
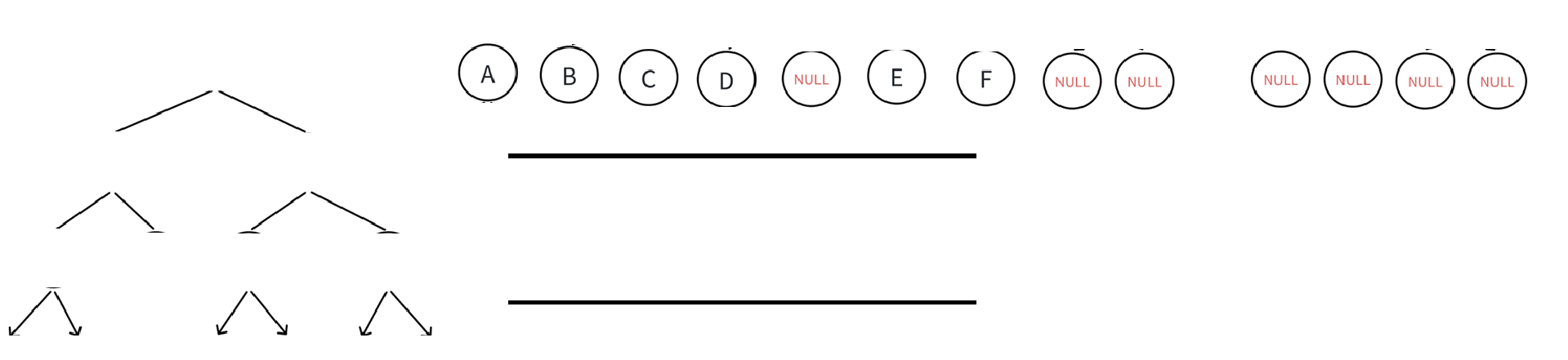
空不打印,空不解引用,直到队列里所有元素都出队列(或者说二叉树所有结点都入出队列以后)循环结束。
代码实现:
2.层序遍历思想的应用
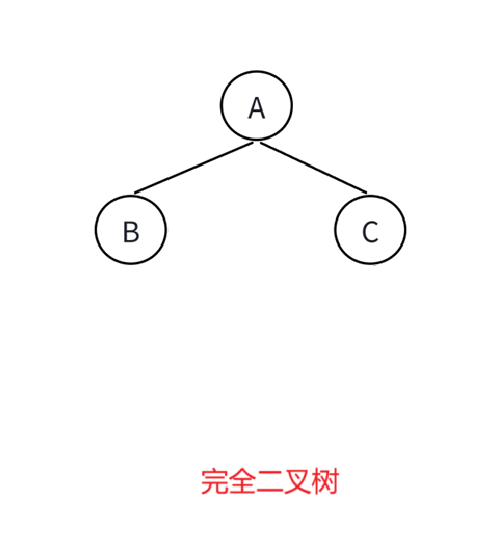
判读一棵二叉树是否为完全二叉树。
为什么要借用层序遍历呢?
完全二叉树是什么样的,答:除最后一层外所有结点与满二叉树相同(即全部填满),且最后一层与满二叉树一一对应(从左到右排列,没有间隔)。
由此我们判断的一个非常重要的标准就是一层一层遍历的时候有没有空档,如果有空不就证明不是完全二叉树,如果全部遍历完毕都没有空档,那么不就是完全二叉树来着。
当然,大致思路有了,还是画画图看看循环以及细节怎么解决:
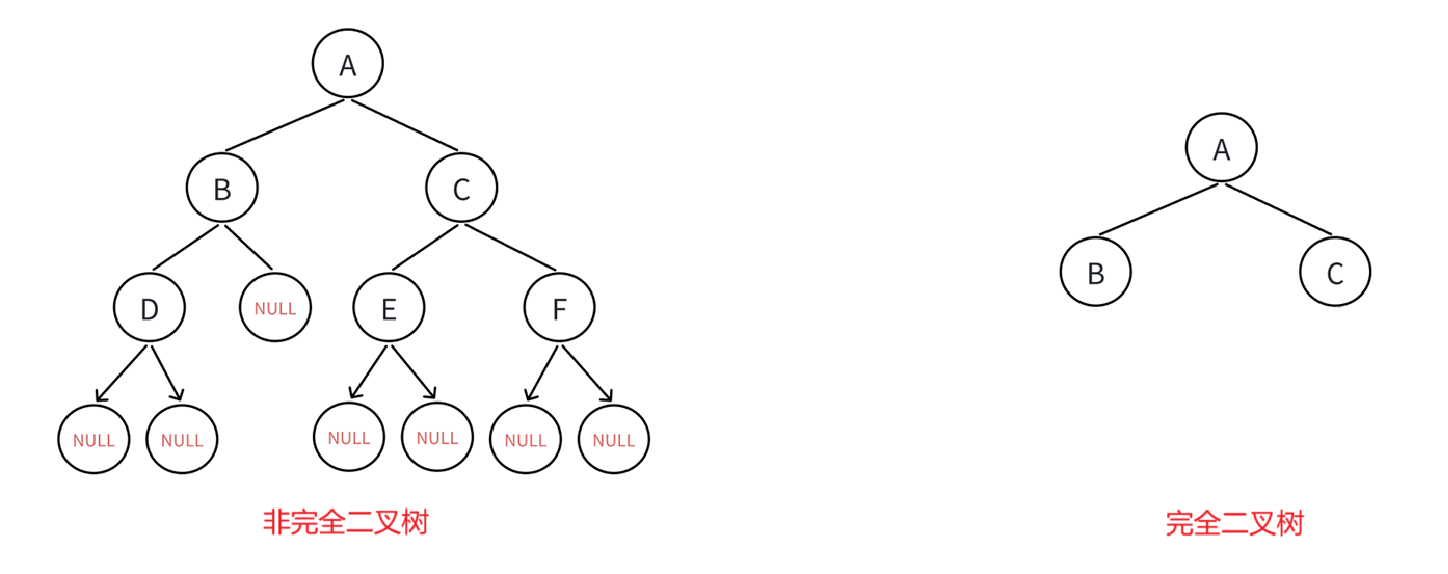
以此为例。
既然还是层序遍历,那么还是画个队列:
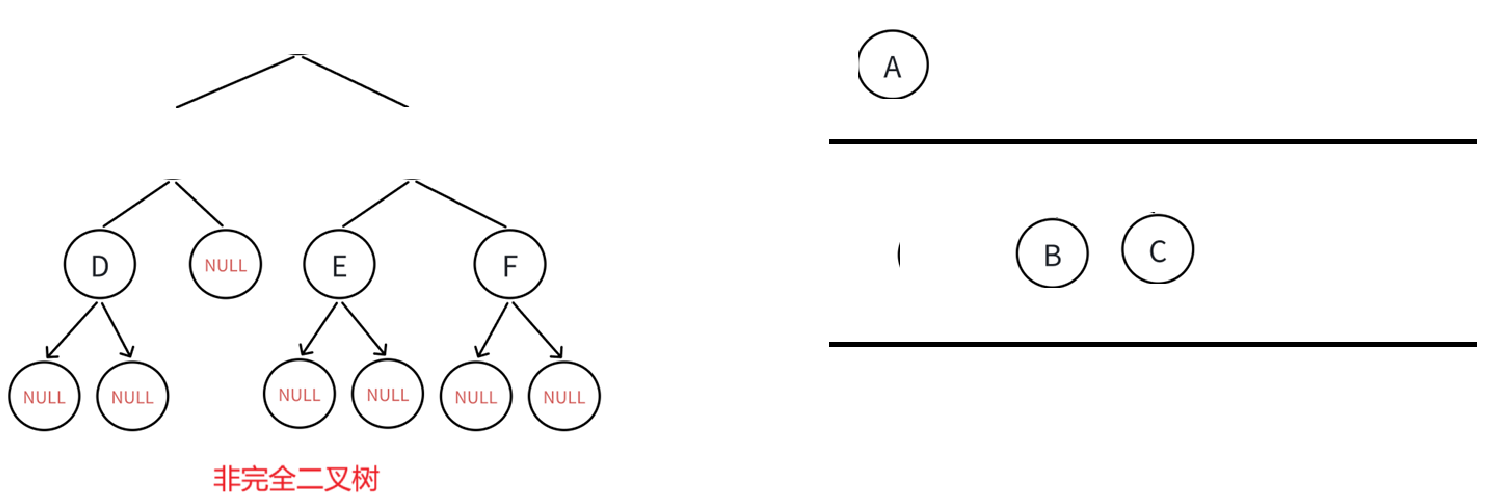
我们在上面已经分析过了,如果有空档就有可能是非完全二叉树,比如:
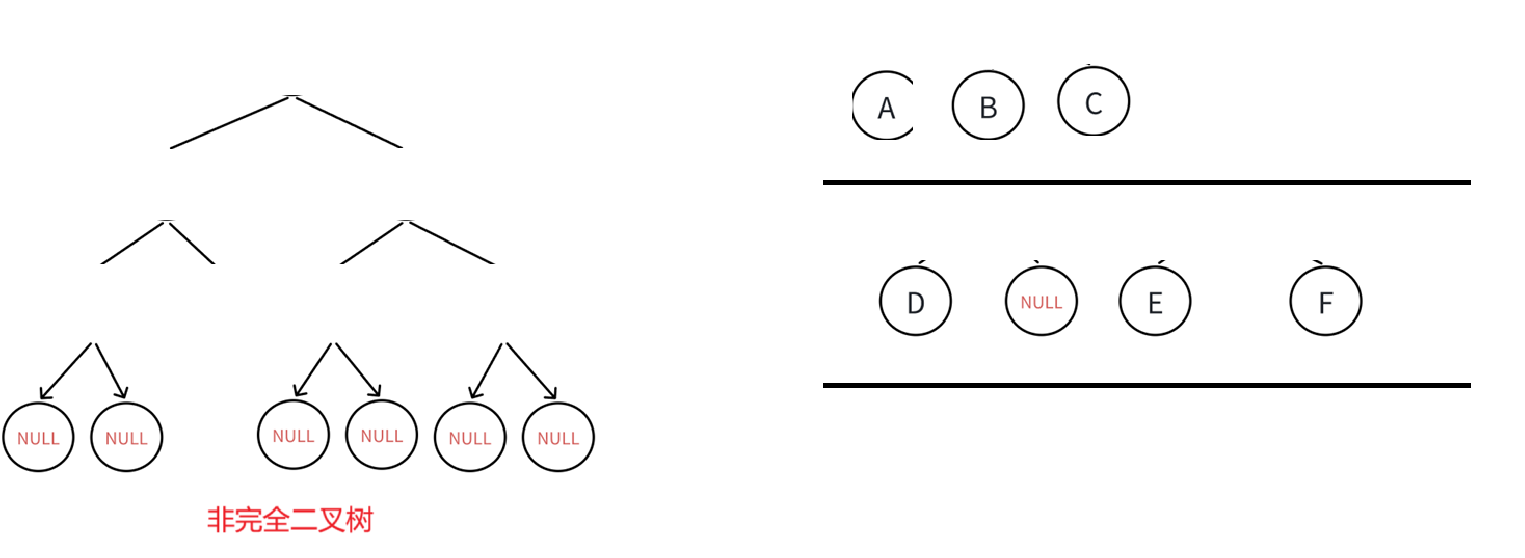
也就是当循环到碰见NULL结点就得小心了,达到第一次循环的目的,找到空结点,当然,肯定也得弄清楚什么时候发现的,层序遍历里我们出队列就会判断是否为空,所以答案呼之欲出了,一定是这样的情况:
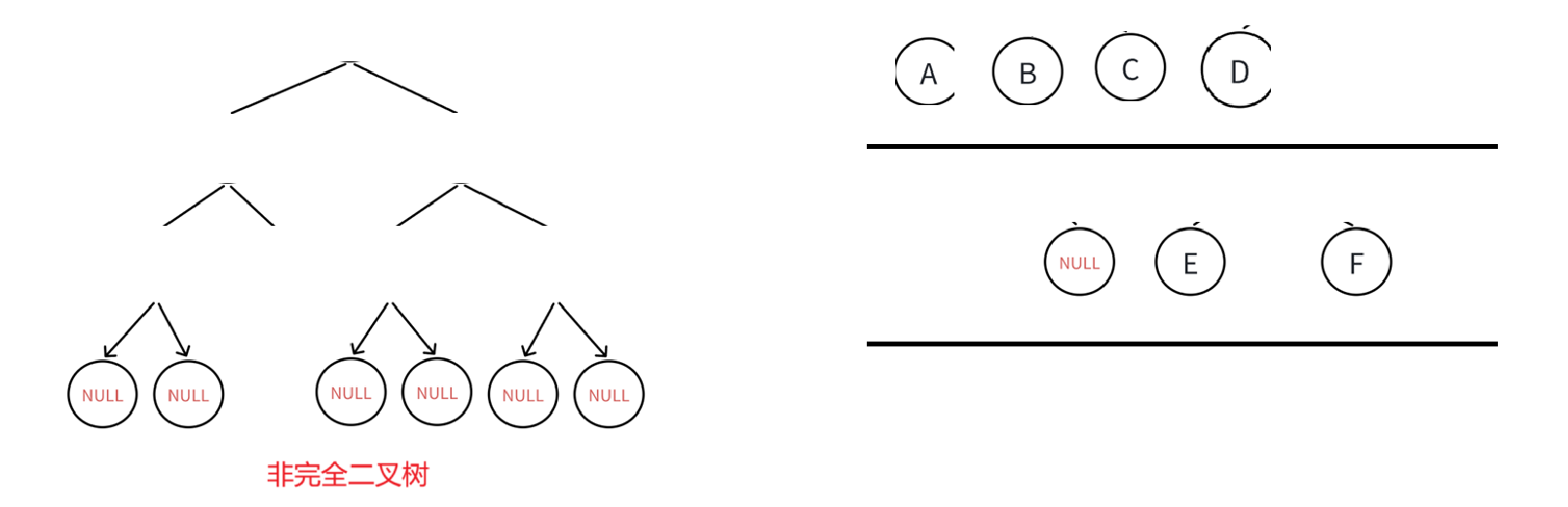
该出NULL肯定要检测,那这个时候就得结束循环了。
第二个循环其实也好想,如果NULL后全部都是NULL,那你没法挑人家毛病(上一个循环层序遍历完了所有非空的结点,即这个结点前每个结点都跟完全二叉树照应),但是如果你一旦空后面为非空,那不就有空档了,那不就不是完全二叉树了嘛。
所以代码:
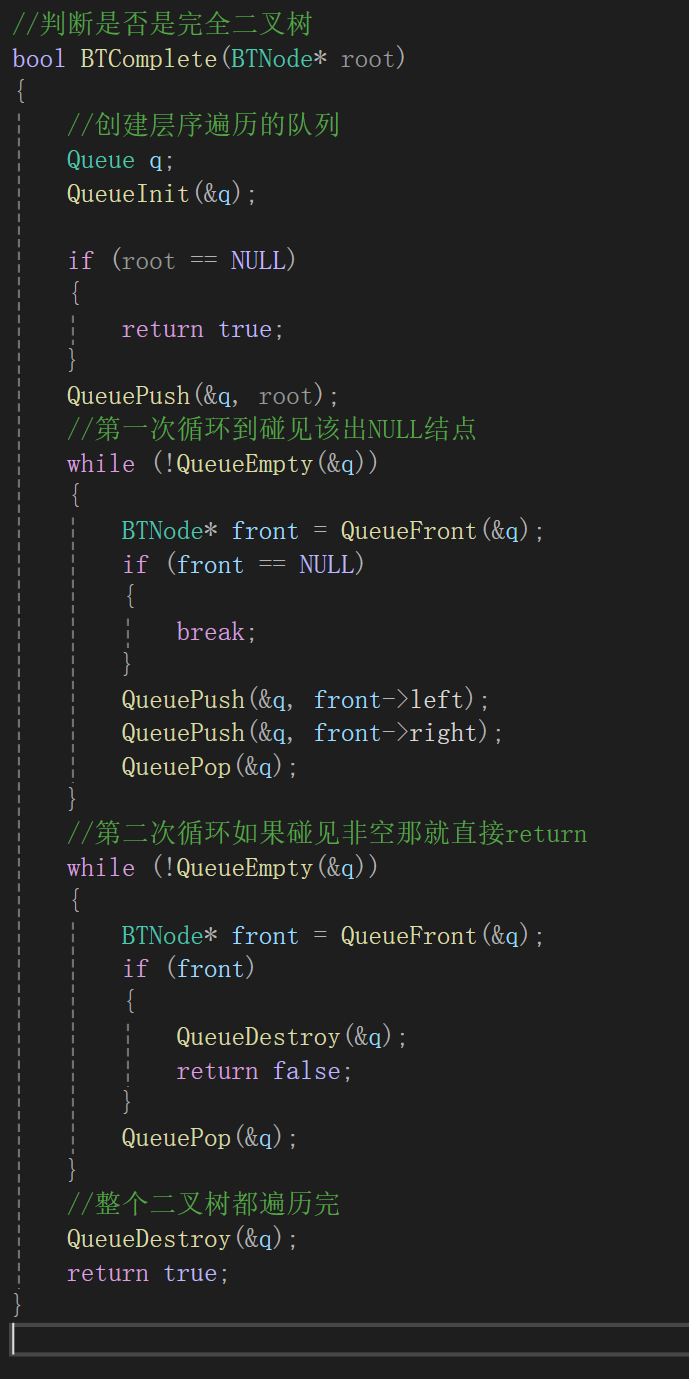
测试代码:
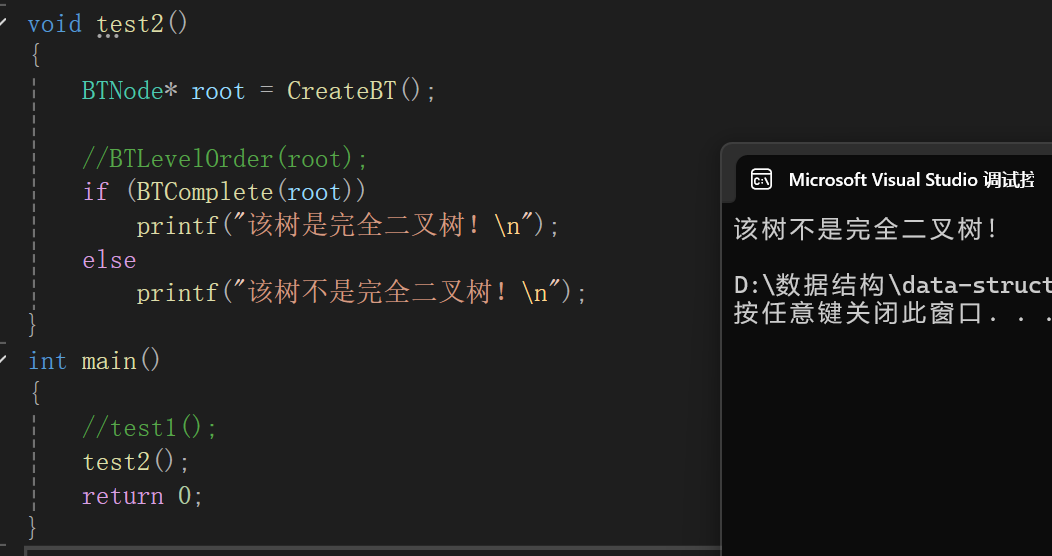
完全照应:
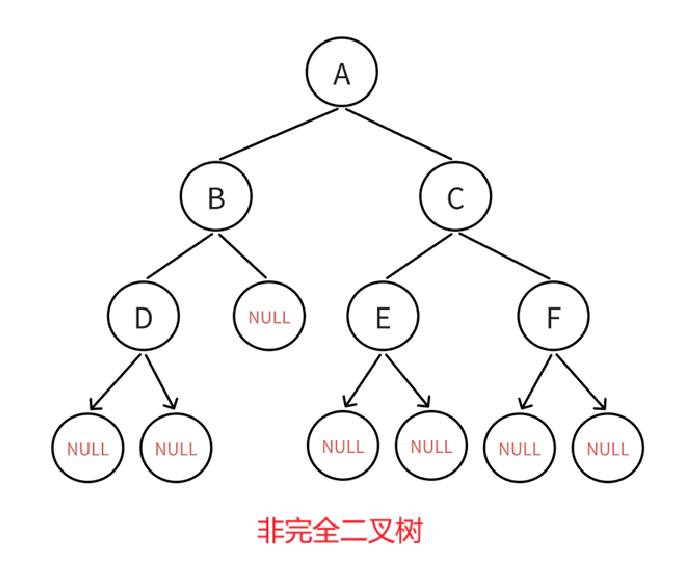
同样的代码,将树改成:
基础二叉树到此为止,之后做些oj题。