Python----目标检测(Ultralytics安装和YOLO-V8快速上手)
一、Ultralytics安装
网址:主页 -Ultralytics YOLO 文档
Ultralytics提供了各种安装方法,包括pip、conda和Docker。通过 ultralytics pip包安装最新稳定版本的YOLOv8,或克隆Ultralytics GitHub 存储库以获取最新版本。可以使用Docker在隔离的容器中执行包,避免本 地安装。
pip install ultralytics==8.2.28 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install git+https://github.com/ultralytics/ultralytics.git@main注意:ultralytics需要PyTorch支持。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
二、使用YOLOV8
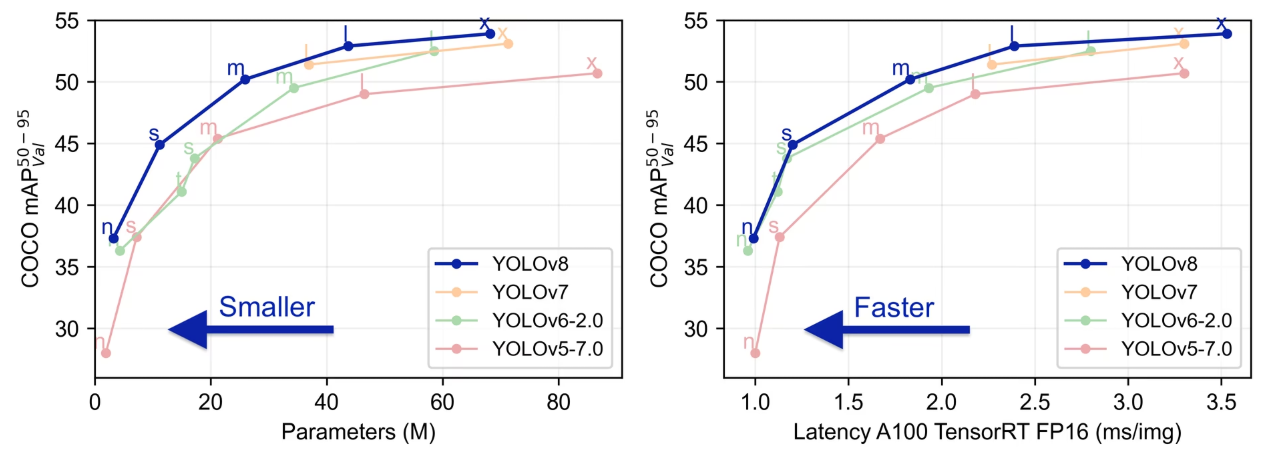
2.1、使用Ultralytics实现YOLOV8
Python接口使用户能够快速实现对象检测、分割和分类等功能。
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.pt") # 使用YOLOV8n模型
# 对图片列表进行批量推理
results = model(['./bus.jpg'])
#处理结果列表
for result in results:boxes = result.boxes # Boxes对象,用于存储边界框输出masks=result.masks #Masks对象,用于存储分割掩模输出keypoints = result.keypoints # Keypoints对象,用于存储姿态关键点输出probs=result.probs #Probs对象,用于存储分类概率输出result.show() #显示结果到屏幕上result.save(filename='result.jpg') #保存结果2.2、使用Ultralytics实现YOLOV8流式预测
import cv2
from ultralytics import YOLO
#加载YOLOV8模型
model=YOLO("yolov8n.pt")
# 打开视频文件
video_path = 'WH038.mp4'
# cap = cv2.VideoCapture(0)#调用摄像头
cap = cv2.VideoCapture(video_path)
# 遍历视频帧
while cap.isOpened():# 从视频中读取一帧success, frame= cap.read()if success:# 在帧上运行YOLOV8推理results = model(frame)# 在帧上可视化推理结果annotated_frame = results[0].plot()# 显示标注后的帧cv2.imshow("YOLOV8推理结果", annotated_frame)# 如果按下'q'键则退出循环if cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# 如果视频播放完毕,则退出循环break
# 释放视频捕获对象并关闭显示窗口
cap.release()
cv2.destroyWindow()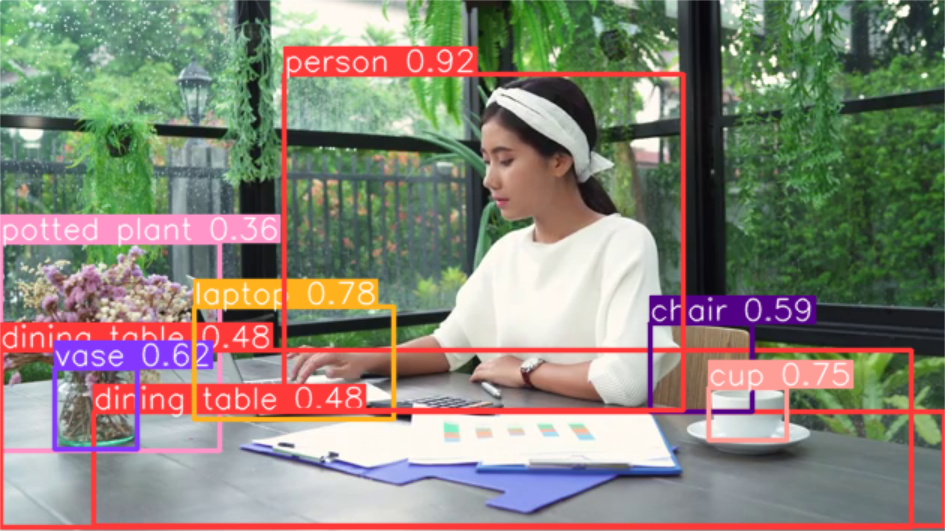
三、了解YOLOV8
3.1、检测 (COCO)
有关在 COCO 上训练的这些模型的使用示例,请参阅检测文档,其中包括 80 个预训练类。
| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
注意:
FLOPs (B) 表示 "Floating Point Operations per second in Billion",即每秒十亿次浮点运算。这个指标通常用于衡量一个模型在进行 推断或训练时的计算性能。浮点运算是指包括加法、减法、乘法、除法等 在内的基本数学运算,它们在深度学习模型中是非常常见的操作。
YOLOV8n 模型的 FLOPs (B) 值为 8.7,意味着在进行推断或训练时,该模 型每秒大约执行 8.7 亿次浮点数运算。
3.2、分割(COCO)
| 模型 | 尺寸 (像素) | mAPbox 50-95 | mAPmask 50-95 | 速度 CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
3.3、姿势 (COCO)
| 模型 | 尺寸 (像素) | 50-95 | mAPpose 50 | 速度 CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-姿势 | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-姿势 | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-姿势 | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-姿势 | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-姿势 | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
3.4、OBB (DOTAv1)
| 模型 | 尺寸 (像素) | mAPtest 50 | 速度 CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
3.5、分类 (ImageNet)
| 模型 | 尺寸 (像素) | acc top1 | acc top5 | 速度 CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) at 224 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 0.5 |
| YOLOv8s-cls | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 1.7 |
| YOLOv8m-cls | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 5.3 |
| YOLOv8l-cls | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 12.3 |
| YOLOv8x-cls | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 19.0 |
四、推理源
YOLOv8 可以处理不同类型的输入源进行推理,如下表所示。输入源包括 静态图像、视频流和各种数据格式。表中还标明了每种输入源是否可以在 流模式下使用参数 stream=True ✅.流模式有利于处理视频或实时流,因 为它会创建一个结果生成器,而不是将所有帧加载到内存中。
使用 stream=True 用于处理长视频或大型数据集,以有效管理内存。当 stream=False在这种情况下,所有帧或数据点的结果都会存储在内存中, 这可能会迅速累加,并导致大量输入出现内存不足错误。与此形成鲜明对 比的是 stream=True 利用生成器,它只将当前帧或数据点的结果保存在内 存中,从而大大减少了内存消耗并防止出现内存不足的问题
| 资料来源 | 论据 | 类型 | 说明 |
|---|---|---|---|
| 图像 | 'image.jpg' | str或Path | 单个图像文件。 |
| 网址 | 'https://ultralytics.com/images/bus.jpg' | str | 图片的URL。 |
| 截图 | 'screen' | str | 截图 |
| PIL | Image.open('im.jpg') | PIL.Image | 具有RGB通道的HWC格式。 |
| OpenCV | cv2.imread('im.jpg') | np.ndarray | 带有BGR频道的HWC 格式 uint8 (0-255)。 |
| numpy | np.zeros((640,1280,3)) | np.ndarray | 带有 BGR 频道的 HWC 格式 uint8 (0-255)。 |
| torch | torch.zeros(16,3,320,640) | torch.Tensor | 带RGB通道的BCHW格式 float32 (0.0-1.0)。 |
| CSV | 'sources.csv' | str或Path | 包含图像、视频或目录路径的CSV文件。 |
| 视频 | 'video.mp4' | str或Path | MP4和AVI等格式的视频文件 |
| 目录 | 'path/' | str或Path | 包含图像或视频的目录路径。 |
| 球体 | 'path/*.jpg' | str | 全局模式来匹配多个文件。使用*字符作为通配符。 |
| YouTube | 'https://youtu.be/LNWODJXcvt4' | str | YouTube 视频的URL。 |
| 流 | 'rtsp://example.com/media.mp4' | str | 流媒体协议(如RTSP、RTMP、TCP)的URL或IP地址。 |
| 多流 | 'list.streams' | str或Path | *.streams文本文件,每行一个流URL,即8个流将以8的批处理大小运行。 |
4.1、在图像文件上运行推理
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt") # 使用 "yolov8n.pt" 文件初始化 YOLO 模型。# 这将加载预先训练好的权重。# 定义图像文件的路径
source = "bus.jpg" # 指定要进行推理的图像文件名为 "bus.jpg"。# 在指定的图像源上运行推理
results = model(source) # 将图像传递给模型进行推理。# model(source) 返回一个 Results 对象列表,# 其中包含了模型对图像中目标的预测结果。4.2、通过 URL 对远程托管的图像或视频进行推理
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt") # 使用 "yolov8n.pt" 文件初始化 YOLO 模型。# 这将加载预先训练好的权重。# 定义图像文件的路径
source = "https://ultralytics.com/images/bus.jpg" # 在输入网址图片。# 在指定的图像源上运行推理
results = model(source) # 将图像传递给模型进行推理。# model(source) 返回一个 Results 对象列表,# 其中包含了模型对图像中目标的预测结果。4.3、在使用Python Imaging Library (PIL) 打开 的图像上运行推理
from PIL import Image
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt") # 使用 "yolov8n.pt" 文件初始化 YOLO 模型。# 这将加载预先训练好的权重。# 定义图像文件的路径
source = Image.open("bus.jpg")# 在指定的图像源上运行推理
results = model(source) # 将图像传递给模型进行推理。# model(source) 返回一个 Results 对象列表,# 其中包含了模型对图像中目标的预测结果。4.4、在使用 OpenCV 读取的图像上运行推理
import cv2
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt") # 使用 "yolov8n.pt" 文件初始化 YOLO 模型。# 这将加载预先训练好的权重。# 定义图像文件的路径
source = cv2.imread('bus.jpg')# 在指定的图像源上运行推理
results = model(source) # 将图像传递给模型进行推理。# model(source) 返回一个 Results 对象列表,# 其中包含了模型对图像中目标的预测结果。4.5、使用 RTSP、RTMP、TCP 和 IP 地址协议对远程流媒体源进行推理
如果在一个 *.streams 文本文件,则将运行批处理推理,即 8 个数据流将 以 8 的批处理大小运行,否则单个数据流将以 1 的批处理大小运行。
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt") # 使用 "yolov8n.pt" 文件初始化 YOLO 模型。# 这将加载预先训练好的权重。# 定义图像文件的路径
source = "rtsp://example.com/media.mp4"
source = "path/to/list.streams" # 在指定的图像源上运行推理
results = model(source) # 将图像传递给模型进行推理。# model(source) 返回一个 Results 对象列表,# 其中包含了模型对图像中目标的预测结果。五、推理论据
model.predict() 接受多个参数,这些参数可以在推理时传递,以覆盖默 认值:
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| source | str | 'ultralytics/assets' | 指定推理数据源。可以是图像路径、视频文件、目录 URL 或用于实时馈送的设备 ID。支持多种格式和来源,以灵活应用于不同类型的输入。 |
| conf | float | 0.25 | 设置检测最小置信阈值。如果检测到的对象置信度低于此阈值,则将不予考虑。调整此值有助于减少误报。 |
| iou | float | 0.7 | 非最大抑制 (NMS) 的 IoU(交并比)阈值。较高的数值可消除重叠方框,从而减少检测数量,这对于减少重复检测非常有用。 |
| imgsz | int 或 tuple | 640 | 定义用于处理的图像大小。可以是一个整数 (640) 或一个 (height, width) 元组。适当调整大小可以提高检测精度和处理速度。 |
| half | bool | False | 启用半精度 (FP16) 推理,可加快支持的 GPU 上的模型处理速度,同时将对精度的影响降至最低。 |
| device | str | None | 指定用于推理的设备(例如 'cpu' 或 'cuda:0')。允许用户选择 CPU、特定 GPU 或其他计算设备来执行模型。 |
| max_det | int | 300 | 每幅图像允许的最大检测次数。限制模型在单次推理中检测到的物体总数,以防止在密集场景中产生过多输出。 |
| vid_stride | int | 1 | 视频输入帧间距。允许跳过视频中的帧,以加快处理速度,但会牺牲时间分辨率。值为 1 时处理每一帧,值越大跳帧越多。 |
| stream_buffer | bool | False | 确定在处理视频流时,是否对所有帧进行缓冲 (True),或者模型是否应该返回最近的帧 (False)。用于实时应用。 |
| visualize | bool | False | 在推理过程中激活模型特征的可视化,从而深入了解模型“看到”了什么。这对于调试和模型解释非常有用。 |
| augment | bool | False | 可对预测进行测试时增强 (TTA),从而在牺牲推理速度的情况下提高检测的鲁棒性。 |
| agnostic_nms | bool | False | 启用与类别无关的非最大抑制 (NMS),可合并不同类别的重叠框。这在多类检测场景中非常有用,因为在这种场景中,类的重叠很常见。 |
| classes | list[int] | None | 根据一组类别 ID 过滤检测结果。只返回属于指定类别的检测结果。在多类检测任务中,该功能有助于专注于检测相关对象。 |
| retina_masks | bool | False | 如果模型存在高分辨率的分割掩膜,则使用高分辨率分割掩膜。这可以提高分割任务的掩膜质量,提供更精确的细节。 |
| embed | list[int] | None | 指定从中提取特征向量或嵌入的层。这对于聚类或相似搜索等下游任务非常有用。 |
| show | bool | False | 如果为 True,在一个窗口中显示带注释的图像或视频。有助于在开发或测试过程中提供即时视觉反馈。 |
可视化参数:
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| save | bool | False | 可将注释的图像或视频保存到文件中。这有助于记录、进一步分析或共享结果。 |
| save_frames | bool | False | 处理视频时,将单个帧保存为图像。这对提取特定帧或逐帧进行详细分析非常有用。 |
| save_txt | bool | False | 将检测结果保存在文本文件中,格式如下:[class] [x_center] [y_center] [width] [height] [confidence]。有助于与其他分析工具集成。 |
| save_conf | bool | False | 在保存的文本文件中包含置信度分数。增强了后期处理和分析的细节。 |
| save_crop | bool | False | 保存经过裁剪的检测图像。可用于数据集扩充、分析或创建特定物体的重点数据集。 |
| show_labels | bool | True | 在可视输出中显示每次检测的标签。让用户立即了解检测到的物体。 |
| show_conf | bool | True | 在标签旁显示每次检测的置信度得分。让人了解模型对每次检测的确定性。 |
| show_boxes | bool | True | 在检测到的物体周围绘制边框。对于图像或视频帧中物体的视觉识别和定位至关重要。 |
| line_width | None 或 int | None | 指定边界框的线宽。如果为 None,则根据图像大小自动调整线宽。提供可视化定制,使图像更加清晰。 |
六、图像和视频格式
6.1、图像
| 图像后缀 | 预测命令示例 | 参考资料 |
|---|---|---|
| .bmp | yolo predict source=image.bmp | 微软 BMP 文件格式 |
| .dng | yolo predict source=image.dng | Adobe DNG |
| .jpeg | yolo predict source=image.jpeg | JPEG |
| .jpg | yolo predict source=image.jpg | JPEG |
| .mpo | yolo predict source=image.mpo | 多画面对象 |
| .png | yolo predict source=image.png | 便携式网络图形 |
| .tif | yolo predict source=image.tif | 标签图像文件格式 |
| .tiff | yolo predict source=image.tiff | 标签图像文件格式 |
| .webp | yolo predict source=image.webp | WebP |
| .pfm | yolo predict source=image.pfm | 便携式浮图 |
6.2、视频格式
| 视频后缀 | 预测命令示例 | 参考资料 |
|---|---|---|
| .asf | yolo predict source=video.asf | 高级系统格式 |
| .avi | yolo predict source=video.avi | 音频视频交错 |
| .gif | yolo predict source=video.gif | 图形交换格式 |
| .m4v | yolo predict source=video.m4v | MPEG-4 第 14 部分 |
| .mkv | yolo predict source=video.mkv | 马特罗斯卡 |
| .mov | yolo predict source=video.mov | QuickTime 文件格式 |
| .mp4 | yolo predict source=video.mp4 | MPEG-4 第 14 部分 - 维基百科 |
| .mpeg | yolo predict source=video.mpeg | MPEG-1 第 2 部分 |
| .mpg | yolo predict source=video.mpg | MPEG-1 第 2 部分 |
| .ts | yolo predict source=video.ts | MPEG 传输流 |
| .wmv | yolo predict source=video.wmv | Windows 媒体视频 |
| .webm | yolo predict source=video.webm | WebM 项目 |
七、返回值
predict() 调用将返回一个 Results 。
from ultralytics import YOLO# 加载一个预训练的 YOLOv8n 模型
model = YOLO("yolov8n.pt")# 对单张图片 "bus.jpg" 进行推理
results = model("bus.jpg") # 返回一个 Results 对象的列表,因为只处理了一张图片,所以列表中只有一个元素# 对图片列表 ["bus.jpg", "zidane.jpg"] 进行批量推理
results = model(["bus.jpg", "zidane.jpg"]) # 返回一个 Results 对象的列表,列表中包含每个图片的推理结果boxes: ultralytics.engine.results.Boxes object
keypoints: None
masks: None
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
obb: None
orig_img: array([[[122, 148, 172],[120, 146, 170],[125, 153, 177],...,[157, 170, 184],[158, 171, 185],[158, 171, 185]],[[127, 153, 177],[124, 150, 174],[127, 155, 179],...,[158, 171, 185],[159, 172, 186],[159, 172, 186]],[[128, 154, 178],[126, 152, 176],[126, 154, 178],...,[158, 171, 185],[158, 171, 185],[158, 171, 185]],...,[[185, 185, 191],[182, 182, 188],[179, 179, 185],...,[114, 107, 112],[115, 105, 111],[116, 106, 112]],[[157, 157, 163],[180, 180, 186],[185, 186, 190],...,[107, 97, 103],[102, 92, 98],[108, 98, 104]],[[112, 112, 118],[160, 160, 166],[169, 170, 174],...,[ 99, 89, 95],[ 96, 86, 92],[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: 'D:\\目标检测\\bus.jpg'
probs: None
save_dir: 'runs\\detect\\predict3'
speed: {'preprocess': 6.001710891723633, 'inference': 35.00771522521973, 'postprocess': 5.001306533813477}]
Results对象具有以下属性:
| 属性 | 类型 | 说明 |
|---|---|---|
orig_img | numpy.ndarray | 原始图像的 numpy 数组。 |
orig_shape | tuple | 原始图像的形状,格式为(高、宽)。 |
boxes | Boxes, optional | 包含检测边界框的方框对象。 |
masks | Masks, optional | 包含检测掩码的掩码对象。 |
probs | Probs, optional | Probs 对象,包含分类任务中每个类别的概率。 |
keypoints | Keypoints, optional | 关键点对象,包含每个对象的检测关键点。 |
obb | OBB, optional | 包含定向包围盒的 OBB 对象。 |
speed | dict | 每幅图像的预处理、推理和后处理速度字典,单位为毫秒。 |
names | dict | 类名字典。 |
path | str | 图像文件的路径。 |
Results对象的方法:
| 方法 | 返回类型 | 说明 |
|---|---|---|
update() | None | 更新结果对象的方框、掩码和 probs 属性。 |
cpu() | Results | 返回包含 CPU 内存中所有张量的结果对象副本。 |
numpy() | Results | 返回结果对象的副本,其中所有张量均为 numpy 数组。 |
cuda() | Results | 返回包含 GPU 内存中所有张量的 Results 对象副本。 |
to() | Results | 返回带有指定设备和 dtype 上张量的 Results 对象副本。 |
new() | Results | 返回一个具有相同图像、路径和名称的新结果对象。 |
plot() | numpy.ndarray | 绘制检测结果。返回注释图像的 numpy 数组。 |
show() | None | 在屏幕上显示带注释的结果。 |
save() | None | 将注释结果保存到文件中。 |
verbose() | str | 返回每个任务的日志字符串。 |
save_txt() | None | 将预测结果保存到 txt 文件中。 |
save_crop() | None | 将裁剪后的预测保存到 save_dir/cls/file_name.jpg。 |
tojson() | str | 将对象转换为 JSON 格式。 |
7.1、Boxes
Boxes 对象可用于索引、操作和将边界框转换为不同格式。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")results = model("bus.jpg")
for i in results:print(i.boxes)
cls: tensor([ 5., 0., 0., 0., 11., 0.], device='cuda:0')
conf: tensor([0.8705, 0.8690, 0.8536, 0.8193, 0.3461, 0.3013], device='cuda:0')
data: tensor([[1.7286e+01, 2.3059e+02, 8.0152e+02, 7.6841e+02, 8.7054e-01, 5.0000e+00],[4.8739e+01, 3.9926e+02, 2.4450e+02, 9.0250e+02, 8.6898e-01, 0.0000e+00],[6.7027e+02, 3.8028e+02, 8.0986e+02, 8.7569e+02, 8.5360e-01, 0.0000e+00],[2.2139e+02, 4.0579e+02, 3.4472e+02, 8.5739e+02, 8.1931e-01, 0.0000e+00],[6.4347e-02, 2.5464e+02, 3.2288e+01, 3.2504e+02, 3.4607e-01, 1.1000e+01],[0.0000e+00, 5.5101e+02, 6.7105e+01, 8.7394e+02, 3.0129e-01, 0.0000e+00]], device='cuda:0')
id: None
is_track: False
orig_shape: (1080, 810)
shape: torch.Size([6, 6])
xywh: tensor([[409.4020, 499.4991, 784.2324, 537.8136],[146.6206, 650.8826, 195.7623, 503.2372],[740.0637, 627.9874, 139.5888, 495.4068],[283.0555, 631.5919, 123.3235, 451.6003],[ 16.1764, 289.8419, 32.2241, 70.3949],[ 33.5525, 712.4718, 67.1049, 322.9278]], device='cuda:0')
xywhn: tensor([[0.5054, 0.4625, 0.9682, 0.4980],[0.1810, 0.6027, 0.2417, 0.4660],[0.9137, 0.5815, 0.1723, 0.4587],[0.3495, 0.5848, 0.1523, 0.4181],[0.0200, 0.2684, 0.0398, 0.0652],[0.0414, 0.6597, 0.0828, 0.2990]], device='cuda:0')
xyxy: tensor([[1.7286e+01, 2.3059e+02, 8.0152e+02, 7.6841e+02],[4.8739e+01, 3.9926e+02, 2.4450e+02, 9.0250e+02],[6.7027e+02, 3.8028e+02, 8.0986e+02, 8.7569e+02],[2.2139e+02, 4.0579e+02, 3.4472e+02, 8.5739e+02],[6.4347e-02, 2.5464e+02, 3.2288e+01, 3.2504e+02],[0.0000e+00, 5.5101e+02, 6.7105e+01, 8.7394e+02]], device='cuda:0')
xyxyn: tensor([[2.1340e-02, 2.1351e-01, 9.8953e-01, 7.1149e-01],[6.0172e-02, 3.6969e-01, 3.0185e-01, 8.3565e-01],[8.2749e-01, 3.5211e-01, 9.9982e-01, 8.1082e-01],[2.7333e-01, 3.7573e-01, 4.2558e-01, 7.9388e-01],[7.9441e-05, 2.3578e-01, 3.9862e-02, 3.0096e-01],[0.0000e+00, 5.1019e-01, 8.2846e-02, 8.0920e-01]], device='cuda:0')| 名称 | 类型 | 说明 |
|---|---|---|
cpu() | 方法 | 将对象移动到 CPU 内存。 |
numpy() | 方法 | 将对象转换为 numpy 数组。 |
cuda() | 方法 | 将对象移动到 CUDA 内存。 |
to() | 方法 | 将对象移动到指定设备。 |
xyxy | Property (torch.Tensor) | 以 xyxy 格式返回方框。 |
conf | Property (torch.Tensor) | 返回方框的置信度值。 |
cls | Property (torch.Tensor) | 返回方框的类值。 |
id | Property (torch.Tensor) | 返回盒子的跟踪 ID(如果有)。 |
xywh | Property (torch.Tensor) | 以 xywh 格式返回方框。 |
xyxyn | Property (torch.Tensor) | 以 xyxy 格式返回按原始图像大小归一化的方框。 |
xywhn | Property (torch.Tensor) | 以 xywh 格式返回按原始图像大小归一化的方框。 |
xyxy | torch.Tensor \ | numpy.ndarray |
conf | torch.Tensor \ | numpy.ndarray |
cls | torch.Tensor \ | numpy.ndarray |
id | torch.Tensor \ | numpy.ndarray,可选 |
xywh | torch.Tensor \ | numpy.ndarray |
xyxyn | torch.Tensor \ | numpy.ndarray |
xywhn | torch.Tensor \ | numpy.ndarray |
xyxy (torch.Tensor | numpy.ndarray):格式为 [x1, y1, x2, y2] 的方 框。
conf (torch.Tensor | numpy.ndarray):每个方框的置信度得分。
cls (torch.Tensor | numpy.ndarray):每个方框的类标签:每个方框 的类标签。
id (torch.Tensor | numpy.ndarray,可选):每个方框的跟踪 ID(如 果有)。
xywh (torch.Tensor | numpy.ndarray):按要求计算的 [x, y, width, height] 格式的方框。
xyxyn (torch.Tensor | numpy.ndarray):归一化 [x1, y1, x2, y2] 方 框,相对于 orig_shape .
xywhn (torch.Tensor | numpy.ndarray):归一化的 [x、y、宽、高] 方框,相对于 orig_shape .
7.2、Masks
Masks 对象可用于索引、操作和将掩码转换为线段。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")results = model("bus.jpg")
for i in results:print(i.masks)
| 名称 | 类型 | 说明 |
|---|---|---|
cpu() | 方法 | 返回 CPU 内存中的掩码 tensor。 |
numpy() | 方法 | 以 numpy 数组形式返回掩码 tensor。 |
cuda() | 方法 | 返回 GPU 内存中的掩码 tensor。 |
to() | 方法 | 返回具有指定设备和 dtype 的掩码 tensor。 |
xyn | Property (torch.Tensor) | 以张量表示的标准化片段列表。 |
xy | Property (torch.Tensor) | 以张量表示的像素坐标线段列表。 |
7.3、Keypoints
Keypoints 对象可用于索引、处理和归一化坐标。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")results = model("bus.jpg")
for i in results:print(i.keypoints)
| 名称 | 类型 | 说明 |
|---|---|---|
cpu() | 方法 | 返回 CPU 内存中的关键点 tensor。 |
numpy() | 方法 | 以 numpy 数组形式返回关键点 tensor。 |
cuda() | 方法 | 返回 GPU 内存中的关键点 tensor。 |
to() | 方法 | 返回指定设备和 dtype 的关键点 tensor。 |
xyn | Property (torch.Tensor) | 以张量表示的标准化关键点列表。 |
xy | Property (torch.Tensor) | 以张量表示的像素坐标关键点列表。 |
conf | Property (torch.Tensor) | 返回关键点的置信度值(如果有),否则为空。 |
7.4、Probs
Probs 对象可用于索引、获取 top1 和 top5 分类指数和分数。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")results = model("bus.jpg")
for i in results:print(i.probs)
| 名称 | 类型 | 说明 |
|---|---|---|
cpu() | 方法 | 返回 CPU 内存中 probstensor 的副本。 |
numpy() | 方法 | 以 numpy 数组形式返回 probstensor 的副本。 |
cuda() | 方法 | 返回 GPU 内存中 probstensor 的副本。 |
to() | 方法 | 返回带有指定设备和 dtype 的 probstensor 的副本。 |
top1 | Property (int) | 置信度第 1 的索引。 |
top5 | Property (list[int]) | 置信度前 5 的索引。 |
top1conf | Property (torch.Tensor) | 返回第 1 名的置信度。 |
top5conf | Property (torch.Tensor) | 返回前 5 名的置信度。 |
7.5、OBB
OBB 指的是 "Oriented Bounding Box",即定向边界框。它是一种包围物 体的矩形框,与传统的边界框不同,OBB 可以沿着物体的方向进行旋转, 以更好地适应物体的实际形状和方向。 OBB 对象可用于索引、操作和将定向边界框转换为不同格式。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")results = model("bus.jpg")
for i in results:print(i.obb)
| 名称 | 类型 | 说明 |
|---|---|---|
cpu() | 方法 | 将对象移至 CPU 内存。 |
numpy() | 方法 | 将对象转换为 numpy 数组。 |
cuda() | 方法 | 将对象移至 CUDA 内存。 |
to() | 方法 | 将对象移动到指定设备。 |
conf | Property (torch.Tensor) | 返回方框的置信度值。 |
cls | Property (torch.Tensor) | 返回方框的类值。 |
id | Property (torch.Tensor) | 返回盒子的轨道 ID(如果有)。 |
xyxy | Property (torch.Tensor) | 以 xyxy 格式返回水平方框。 |
xywhr | Property (torch.Tensor) | 以 xywhr 格式返回旋转后的方框。 |
xyxyxyxy | Property (torch.Tensor) | 以 xyxyxyxy 格式返回旋转后的方框。 |
xyxyxyxyn | Property (torch.Tensor) | 以 xyxyxyxy 格式返回按图像大小归一化的旋转方框。 |
八、绘制结果
plot() 方法中的 Results 对象,将检测到的对象(如边界框、遮罩、关 键点和概率)叠加到原始图像上,从而实现预测的可视化。该方法以 NumPy 数组形式返回注释图像,便于显示或保存。
from ultralytics import YOLO# 加载模型
model = YOLO("yolov8n.pt") # 使用YOLOv8n模型# 对图片列表进行批量推理
results = model(['./bus.jpg']) # 返回结果对象的列表# 处理结果列表
for result in results:result.show() # 显示结果到屏幕上result.save(filename='result.jpg') # 保存结果
plot() 方法支持各种参数来定制输出
| 参数 | 类型 | 说明 | 默认值 |
|---|---|---|---|
conf | bool | 包括检测置信度分数。 | True |
line_width | float | 边界框的线宽。根据图像大小缩放,如果为 None。 | None |
font_size | float | 文字字体大小。与图像大小一致,如果为 None。 | None |
font | str | 文本注释的字体名称。 | 'Arial.ttf' |
pil | bool | 将图像作为 PIL 图像对象返回。 | False |
img | numpy.ndarray | 用于绘图的替代图像。如果为 None,则使用原始图像。 | None |
im_gpu | torch.Tensor | 经过 GPU 加速的图像,可更快地绘制遮罩图。形状:(1,3,640,640)。 | None |
kpt_radius | int | 绘制关键点的半径。 | 5 |
kpt_line | bool | 用线条连接关键点。 | True |
labels | bool | 在注释中包含类标签。 | True |
boxes | bool | 在图像上叠加边界框。 | True |
masks | bool | 在图像上叠加蒙版 | True |
probs | bool | 包括分类概率。 | True |
show | bool | 使用默认图像查看器直接显示注释图像。 | False |
save | bool | 将注释的图像保存到由 filename 指定的文件。 | False |
filename | str | 保存注释图像的文件路径和名称(如果有)。仅当 save 是 True 时使用。 | None |