DAY01:【ML 第三弹】基本概念和建模流程
1、机器学习基本概念
1.1 模型训练
- 模型评估指标:用于评估模型实际效果的数值型指标,如准确率
- 模型参数:对模型最终输出结果有影响的模型关键指标,如自变量加权求和汇总过程中的权重
- 模型训练:指通过不断的数据输入、模型参数得到有效调整的过程,此处模型参数的有效调整指的是调整之后能够提升模型表现
1.2 经典统计分析方法
线性回归模型是诞生于是统计学领域的一类模型,同时也是整个线性类模型大类的基础模型,是一类非常重要的统计学模型。
在经典统计学领域,线性回归模型拥有坚实的数学理论基础作为支撑,曾在很长一段时间内都是数理统计分析建模最通用的模型之一。值得一提的是,使用传统的统计学方法构建线性回归模型其实并不简单,如果要构建一个统计学意义的线性回归模型,则至少需要掌握随机变量的基本分布、变量相关性与独立性、方差分析等基本统计学知识,才能够上手构建线性回归模型。
在机器学习领域,由于机器学习的基本建模思路和流程和经典统计分析有很大区别,在构建线性回归模型时流程较为简单,外加线性回归模型本身可解释性较强,因此可以作为入门的第一个算法来学习。
从机器学习的角度出发,所谓线性回归,指的是自变量(特征)加权求和汇总求得因变量(标签)的过程。
例如, y = w 1 x 1 + w 2 x 2 y = w_1x_1+w_2x_2 y=w1x1+w2x2的计算过程,就是一个简单的线性回归。
1.3 数据集
1.3.1 数据与数据集
所谓数据,特指能够描绘某件事物的属性或者运行状态的数值,并且一个数据集由多条数据构成。
例如,鸢尾花数据,就是描述鸢尾花一般属性的数据集。
import numpy as np
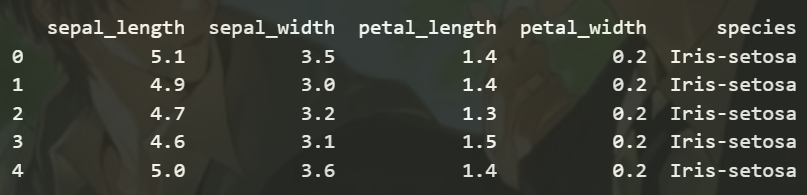
import pandas as pddf_iris = pd.read_csv('iris.csv')
print(df_iris.head())
-
运行结果:
-
数据集概述:
- 文件名为 iris.csv,包含了鸢尾花的相关信息
- 文件包含了150条鸢尾花的数据
- 数据集包含了鸢尾花的萼片长度( s e p a l _ l e n g t h sepal\_length sepal_length)、萼片宽度( s e p a l _ w i d t h sepal\_width sepal_width)、花瓣长度( p e t a l _ l e n g t h petal\_length petal_length)、花瓣宽度( p e t a l _ w i d t h petal\_width petal_width)以及鸢尾花的种类( s p e c i e s species species)
1.3.2 特征与标签
鸢尾花数据集中的每一列是所有描述对象的一项共同指标。其中,前四列分别描述了鸢尾花的四项生物学性状,而最后一列则描述了每一朵花所属类别。
如果上述表格的记录目的是通过记录鸢尾花的四个维度的不同属性的取值最终判别鸢尾花属于哪一类,则该数据集中的前四列也被称为数据集的特征( f e a t u r e s features features),而最后一列被称为数据集的标签( l a b e l s labels labels)。
据此,在实际建模过程中,当需要利用模型进行预测时,也是通过输入模型一些样本的特征(一些鸢尾花的四个特征取值),让模型进行每个样本的标签判别(判别每一朵花应该属于哪一类)。
但是,标签和特征,只是依据模型预测目标进行的、围绕数据集不同列进行的划分方式,如果模型的预测目标发生变化,则数据集的特征和标签也会发生变化。
例如,如果围绕鸢尾花数据集我们最终是进行每一朵花的花瓣宽( p e t a l w i d t h petal width petalwidth)的预测,则上述数据集中1、2、3、5列就变成了特征,第4列变成了标签。
因此,特征和标签本质上都是人工设置的。一般来说,标签列放在最后一列。
注意:数据集中的列也被称为字段,鸢尾花数据集中总共有5列,也就总共有5个字段。
1.3.3 连续变量和离散变量
随机变量有离散变量和连续变量之分。
连续变量,指的是随机变量能够取得连续数值。
例如,随机变量表示距离或者长度测算结果时,该变量就是连续性变量。
离散变量,指的是随机变量只允许取得离散的整数。
例如,随机变量用0/1表示性别。
注意:在传统统计分析领域,对于离散型变量,可细分为名义型变量和顺序性变量。
名义变量,指的是随机变量取得不同离散值时,取值大小本身没有数值意义,只有指代意义。例如,用0/1代表男女,则该变量没有1>0的数值意义。
顺序变量,则有大小方面的数值意义。例如,使用0/1/2代表高中/本科/研究生学历,则可用2>1>0来表示学习的高低之分。
1.4 模型类型
离散型变量和连续性变量在数理特征上有很大的区别。因此,对于预测类的机器学习建模来说,标签这一预测指标是连续型变量还是离散型变量,会对模型预测过程造成很大影响。
据此,围绕离散型标签进行建模预测,则称任务为分类预测任务,该模型为解决分类任务的分类( c l a s s i f i c a t i o n classification classification)模型,而如果是围绕连续型标签进行建模预测,则称该任务为回归预测任务,该模型为解决回归问题的回归( r e g r e s s i o n regression regression)模型。
import numpy as np
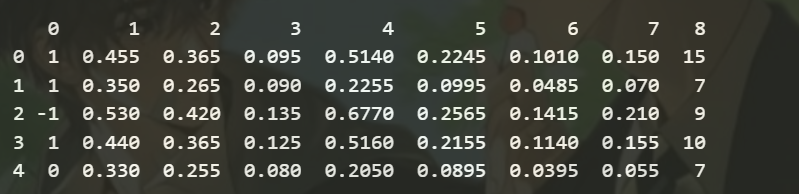
import pandas as pddf_abalone = pd.read_csv('abalone.txt', sep='\t', header=None)
print(df_abalone.head())
-
运行结果:
-
数据集概述:
| Name | Description |
|---|---|
| Gender | 性别,1为Male、-1为Femel、0为infant |
| Length | 最长外壳尺寸 |
| Diameter | 垂直于长度的直径 |
| Height | 带壳肉的高度 |
| Whole weight | 整体重量 |
| Shucked weight | 脱壳重量 |
| Viscera weight | 内脏的重量 |
| Shell weight | 壳的重量 |
| Rings | (年轮)年龄 |
print(df_abalone.columns)
print('--'*50)
df_abalone.columns = ['Gender', 'Length', 'Diameter', 'Height', 'Whole weight', 'Shucked weight', 'Viscera weight', 'Shell weight', 'Rings']
print(df_abalone.head())
df_abalone.to_csv('abalone.csv', index=False)
- 运行结果:
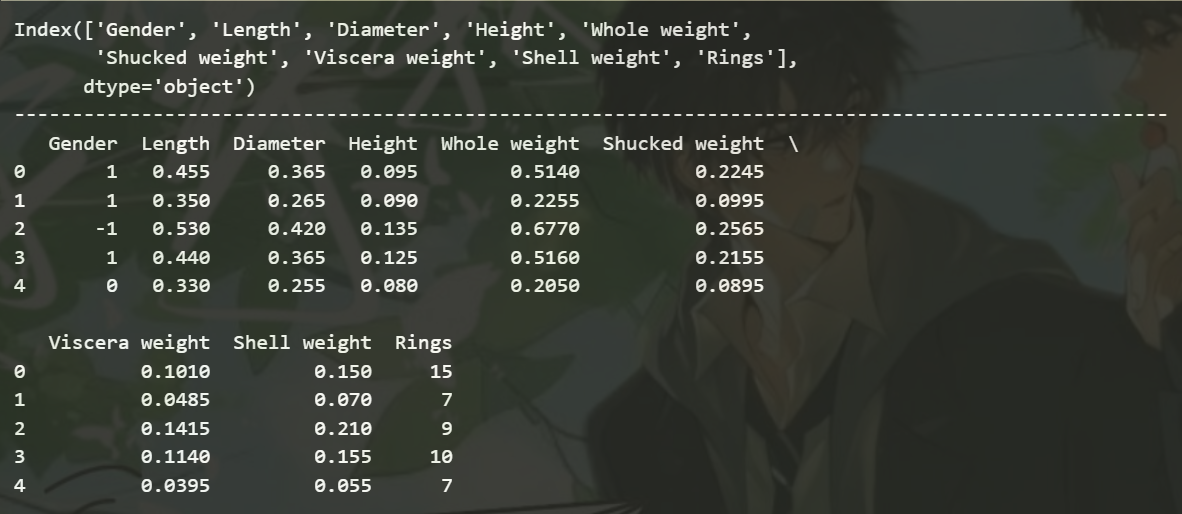
对于 a b a l o n e abalone abalone数据集来说, R i n g s Rings Rings是标签,围绕 R i n g s Rings Rings的预测任务是连续型变量的预测任务,因此是回归类问题。
2、线性回归模型建模准备与模型训练
2.1 建模准备
2.1.1 数据准备
线性回归是属于回归类模型,是针对连续型变量进行数值预测的模型,因此选用 a b a l o n e abalone abalone数据集进行建模。
| Whole weight | Rings |
|---|---|
| 1 | 2 |
| 3 | 4 |
2.1.2 模型准备
上述数据集是极端简化后的数据集,只有一个连续型特征和连续型标签,并且只包含两条数据。围绕只包含一个特征的数据所构建的线性回归模型,也被称为简单线性回归。简单线性回归的模型表达式为: y = w x + b y = wx + b y=wx+b
其中 x x x表示自变量,即数据集特征; w w w表示自变量系数,代表每次计算都需要相乘的某个数值; b b b表示截距项,代表每次计算都需要相加的某个数值;而 y y y表示因变量,即模型输出结果。
除了简单线性回归外,线性回归主要还包括多元线性回归和多项式回归两类。
多元线性回归用于解决包含多个特征的回归类问题,模型基本表达式为: y = w 1 x 1 + w 2 x + . . . + w n x n + b y = w_1x_1+w_2x+...+w_nx_n+b y=w1x1+w2x+...+wnxn+b
其中 x 1... n x_{1...n} x1...n表示 n n n个自变量,对应数据集的 n n n个特征, w 1... n w_{1...n} w1...n表示 n n n个自变量的系数, b b b表示截距。简单线性回归也是多元线性回归的一个特例。
多项式回归则是在多元线性回归基础上,允许自变量最高次项超过1次。例如, y = w 1 x 1 2 + w 2 x 2 + b y = w_1x_1^2+w_2x_2+b y=w1x12+w2x2+b
2.2 模型训练
2.2.1 参数调整
(1)模型训练与模型参数调整
模型训练,指的是对模型参数进行有效调整。模型参数是影响模型输出的关键变量。
| 数据特征 | 参数组 | 模型输出 | 数据标签 |
|---|---|---|---|
| Whole weight(x) | ( w , b ) (w,b) (w,b) | y ^ \hat y y^ | Rings(y) |
| 1 | (1, -1) | 0 | 2 |
| 3 | (1, -1) | 2 | 4 |
| 1 | (1, 0) | 1 | 2 |
| 3 | (1, 0) | 3 | 4 |
本例,模型包含两个参数 w 1 w_1 w1和 b b b,当参数取得不同值时,模型将输出完全不同的结果。而不同组的参数取值似乎也有“好坏之分”。当参数组取值为(1,0)时的模型输出结果,要比参数组取值为(1,-1)时输出结果更加贴近真实值。这就说明第二组参数要优于第一组参数。而“机器”在“学习”的过程,或者说模型训练过程,就是需要找到一组最优参数。
(2)模型评估指标和损失函数
- 模型评估指标
模型评估指标,指的是评估模型输出结果“好与坏”的标量计算结果,其最终结果一般由模型预测值 y ^ \hat y y^和真实值 y y y共同计算得出,而对于回归类问题,最重要的模型评估指标就是SSE——残差平方和。
残差平方和,指的是模型预测值 y ^ \hat y y^和真实值 y y y之间的差值的平方和。计算结果表示预测值和真实值之间的差距,结果越小表示二者差距越小,模型效果越好。SSE基本计算公式为: S S E = ∑ i = 1 n ( y ^ i − y i ) 2 SSE = \sum_{i=1}^{n}(\hat y_i-y_i)^2 SSE=i=1∑n(y^i−yi)2
其中n为样本数量。对应的,上述两组不同参数取值对应的模型残差平方和计算结果依次为:
S S E ( 1 , − 1 ) = ( 0 − 2 ) 2 + ( 2 − 4 ) 2 = 8 SSE_{(1,-1)} = (0-2)^2+(2-4)^2 = 8 SSE(1,−1)=(0−2)2+(2−4)2=8
S S E ( 1 , 0 ) = ( 1 − 2 ) 2 + ( 3 − 4 ) 2 = 2 SSE_{(1,0)} = (1-2)^2+(3-4)^2 = 2 SSE(1,0)=(1−2)2+(3−4)2=2
由此可见,第二组参数对应模型效果更好。据此,就找到了能够量化评估模型效果好坏的指标。
- 损失函数
有了模型评估指标之后,我们还需要将评估结果有效的反馈给模型,这时就需要引入另一个至关重要的概念:损失函数(Loss Function)。
模型评估指标是真实值和预测值的计算,模型的损失函数都是关于模型参数的函数。
损失函数本质上一个衡量模型预测结果和真实结果之间的差异的计算过程,例如,在SSE中如果带入模型参数,则就能构成一个SSE损失函数,基本计算过程如下:
| 数据特征 | 参数组 | 模型输出 | 数据标签 |
|---|---|---|---|
| Whole weight(x) | ( w , b ) (w,b) (w,b) | y ^ \hat y y^ | Rings(y) |
| 1 | (w, b) | w+b | 2 |
| 3 | (w, b) | 3w+b | 4 |
S S E L o s s ( w , b ) = ( y 1 − y ^ 1 ) 2 + ( y 2 − y ^ 2 ) 2 = ( 2 − w − b ) 2 + ( 4 − 3 w − b ) 2 SSELoss(w, b) = (y_1 - ŷ_1)^2 + (y_2 - ŷ_2)^2 = (2 - w - b)^2 + (4 - 3w - b)^2 SSELoss(w,b)=(y1−y^1)2+(y2−y^2)2=(2−w−b)2+(4−3w−b)2
由此可见,SSE和SSELoss的计算过程类似,那为何要区别损失函数和模型评估指标呢?
- 对于很多模型(尤其是分类模型)来说,模型评估指标和模型损失函数的计算过程并不一致。例如,准确率就很难转化为一个以参数为变量的函数表达式
- 模型评估指标和损失函数构建的目标不同,模型评估指标的计算目标是给模型性能一个标量计算结果,而损失函数的构建则是为了找到一组最优的参数结果
注意:除了SSE以外,常用的回归类问题的评估指标还有MSE(均方误差)和RMSE(均方根误差):
M S E = 1 n S S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 MSE = \frac{1}{n}SSE = \frac{1}{n}\sum_{i=1}^{n}(\hat y_i-y_i)^2 MSE=n1SSE=n1i=1∑n(y^i−yi)2
R M S E = M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 RMSE = \sqrt{MSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(\hat y_i-y_i)^2} RMSE=MSE=n1i=1∑n(y^i−yi)2
对应的,MSE和RMSE也有相对的损失函数。
损失函数的核心作用:搭建参数求解的桥梁,构建一个协助模型求解参数的方程,并通过损失函数的构建,将求解模型最优参数的问题转化为求解损失函数最小值的问题。
2.2.2 求解损失函数
(1)函数的可视化
为了更好的讨论损失函数(SSELoss)求最小值的过程,对于上述二元损失函数来说,可以将其展示在三维空间中,三维空间坐标分别为: w 、 b 、 S S E L o s s w、b、SSELoss w、b、SSELoss。
S S E L o s s ( w , b ) = ( y 1 − y ^ 1 ) 2 + ( y 2 − y ^ 2 ) 2 = ( 2 − w − b ) 2 + ( 4 − 3 w − b ) 2 SSELoss(w, b) = (y_1 - ŷ_1)^2 + (y_2 - ŷ_2)^2 = (2 - w - b)^2 + (4 - 3w - b)^2 SSELoss(w,b)=(y1−y^1)2+(y2−y^2)2=(2−w−b)2+(4−3w−b)2
import matplotlib as mpl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3Dx = np.arange(-1,3,0.05)
y = np.arange(-1,3,0.05)
w, b = np.meshgrid(x, y)
SSE = (2 - w - b) ** 2 + (4 - 3 * w - b) ** 2ax = plt.axes(projection='3d')
ax.plot_surface(w, b, SSE, cmap='rainbow')
ax.contour(w, b, SSE, zdir='z', offset=0, cmap="rainbow") #生成z方向投影,投到x-y平面
plt.xlabel('w')
plt.ylabel('b')
plt.show()
- 运行结果:
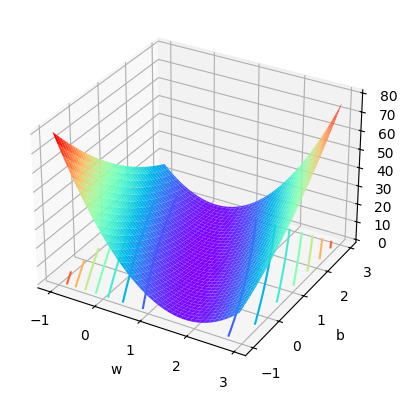
(2)函数的凹凸性
凸函数的一般定义:对于任意一个函数,如果函数f(x)上存在任意两个点, x 1 , x 2 x_1, x_2 x1,x2,且
f ( x 1 ) + f ( x 2 ) 2 > = f ( x 1 + x 2 2 ) \frac{f(x_1) + f(x_2)}{2} >= f(\frac{x_1 + x_2}{2}) 2f(x1)+f(x2)>=f(2x1+x2)
就判定这个函数是凸函数。而对于一个凸函数来说,全域最小值明显存在。
(3)最小二乘法
最小二乘法求解凸函数最小值的基本出发点:通过寻找损失函数导函数(或者偏导函数联立的方程组)为0的点,来求解损失函数的最小值。
注意:关于驻点、临界点、边界点和拐点的概念讨论:
从更严格的意义上来说,凸函数的最小值点是根据边界点和驻点(导数为0的点)决定,如果没有边界点且没有驻点,则函数没有最小值(例如 y = x y=x y=x);如果存在边界点,但没有驻点,则边界点的一侧就是最小值点;如果存在驻点(且左右两边单调性相反),则驻点就是最小值点。
驻点也可以说是临界点,但不是拐点,拐点特指左右两边函数凹凸性发生变化的点。
根据上述理论,使用最小二乘法求解SSELoss,即:
S S E L o s s = ( 2 − w − b ) 2 + ( 4 − 3 w − b ) 2 SSELoss=(2 - w - b)^2 + (4 - 3w - b)^2 SSELoss=(2−w−b)2+(4−3w−b)2
本质上就是在找到能够令损失函数偏导数取值都为零的一组 ( w , b ) (w,b) (w,b)。SSELoss的两个偏导数计算过程如下:
∂ S S E L o s s ∂ ( w ) = 2 ( 2 − w − b ) ∗ ( − 1 ) + 2 ( 4 − 3 w − b ) ∗ ( − 3 ) = 20 w + 8 b − 28 = 0 \begin{align} \frac{\partial{SSELoss}}{\partial{(w)}} & = 2(2-w-b)*(-1) + 2(4-3w-b)*(-3)\\ & = 20w+8b-28 \\ & = 0 \end{align} ∂(w)∂SSELoss=2(2−w−b)∗(−1)+2(4−3w−b)∗(−3)=20w+8b−28=0
∂ S S E L o s s ∂ ( b ) = 2 ( 2 − w − b ) ∗ ( − 1 ) + 2 ( 4 − 3 w − b ) ∗ ( − 1 ) = 8 w + 4 b − 12 = 0 \begin{align} \frac{\partial{SSELoss}}{\partial{(b)}} & = 2(2-w-b)*(-1) + 2(4-3w-b)*(-1)\\ & = 8w+4b-12 \\ & = 0 \end{align} ∂(b)∂SSELoss=2(2−w−b)∗(−1)+2(4−3w−b)∗(−1)=8w+4b−12=0
最终可得,损失函数最小值点为(1,1),即当 w = 1 , b = 1 w=1,b=1 w=1,b=1时模型损失函数计算结果最小、模型SSE取值最小、模型效果最好,此时SSE=0,线性回归模型计算结果为:
y = x + 1 y = x + 1 y=x+1
对比此前参数计算结果:
| 数据特征 | 参数组 | 模型输出 | 数据标签 |
|---|---|---|---|
| Whole weight(x) | ( w , b ) (w,b) (w,b) | y ^ \hat y y^ | Rings(y) |
| 1 | (1, -1) | 0 | 2 |
| 3 | (1, -1) | 2 | 4 |
| 1 | (1, 0) | 1 | 2 |
| 3 | (1, 0) | 3 | 4 |
至此,就完成了一个机器学习建模的完整流程。
3、机器学习建模流程
3.1 提出基本模型
例如,本节中尝试利用简单线性回归去捕捉一个简单数据集中的基本数据规律,这里的 y = w x + b y=wx+b y=wx+b就是提出的基本模型。值得注意的是,在提出模型时,往往会预设好一些影响模型结构或者实际判别性能的参数,如简单线性回归中的 w w w和 b b b。
3.2 确定损失函数
围绕建模的目标构建评估指标,并且围绕评估指标设置损失函数。
例如,本节中模型评估指标和损失函数的建模流程相同。值得注意的是,损失函数不是模型,而是模型参数所组成的一个函数。
3.3 根据损失函数性质,选择优化方法
损失函数既承载了优化的目标(让预测值和真实值尽可能接近),同时也是包含了模型参数的函数,当围绕目标函数求解最小值时,也就完成了模型参数的求解。这个过程本质上就是一个数学的最优化过程,求解目标函数最小值本质上也就是一个最优化问题,而要解决这个问题,就需要灵活适用一些最优化方法。当然,在具体的最优化方法的选择上,函数本身的性质是重要影响因素,也就是说,不同类型、不同性质的函数会影响优化方法的选择。在简单线性回归中,由于目标函数是凸函数,根据凸函数性质,选取了最小二乘法作为该损失函数的优化算法。
3.4 利用优化算法,求解损失函数
在确定优化方法之后,就能够借助优化方法对损失函数进行求解,当然大多数情况下都是求解损失函数的最小值。而伴随损失函数最小值点确定,也就找到了一组对应的损失函数自变量的取值,而改组自变量的取值也就是模型的最佳参数。
微语录:向着月亮出发,即使不能到达,也能站在群星之中。