hadoop伪分布式配置(单机)
前言
伪分布式模式(Pseudo-Distributed Mode)是Hadoop的一种运行模式,适用于模拟一个小规模的集群环境,主要用于开发和测试。
伪分布式模式是指在单台机器上模拟多台服务器的工作环境,Hadoop的守护进程(如NameNode、DataNode、JobTracker、TaskTracker等)都在同一台机器上运行,但相互独立。
设置Hadoop参数的主要方式是配置一系列由Hadoop守护进程和客户端读取的配置文件,如之前提及的hadoop-env.sh,还包括core-site.xml、hdfs- site.xml、mapred-site.xml、log4j.properties、taskcontroller.cfg等,伪分布式需要修改四个文件,修改的顺序没有特殊要求
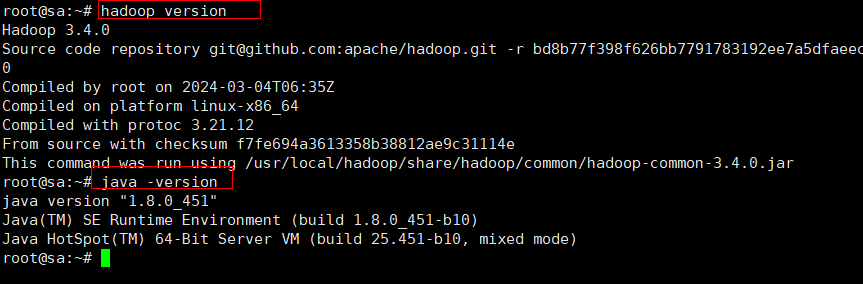
环境要求:jdk1.8,hadoop3.4 ,将java和hadoop环境加入系统环境变量中
部署
一、配置ssh公私钥
Hadoop 的启动和管理(如 start-dfs.sh、start-yarn.sh)需要 主节点(Master)通过 SSH 远程登录到所有工作节点(Workers) 来启动守护进程(如 DataNode、NodeManager)。
ssh localhost #此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码,本机root密码
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权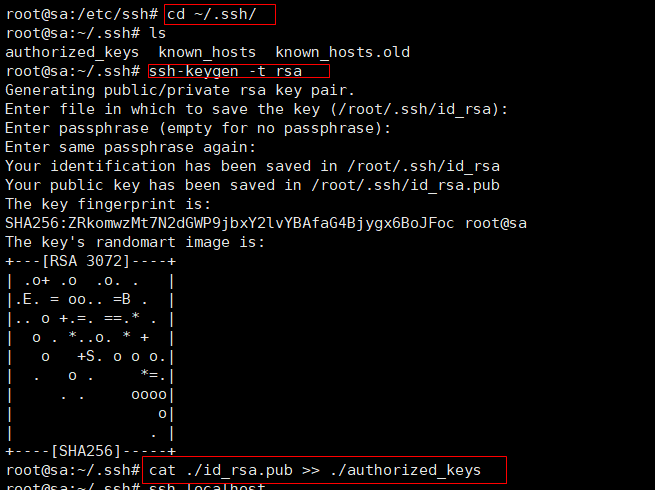
二、修改hadoop的配置文件
1. 查看jdk和hadoop的版本,要先将jdk和hadoop下载在本地
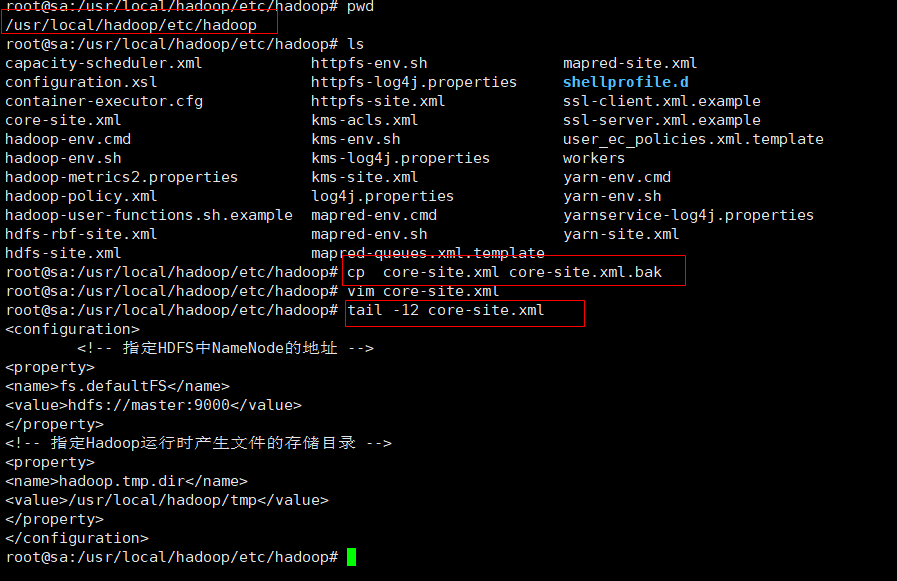
2. core-site.xml是Hadoop集群的核心配置文件,包含 了 Hadoop 全局级别的配置设置。配置该文件
常见配置
cd /usr/local/hadoop/cd etc/hadoop/pwdcp core-site.xml core-site.xml.bak #防止文件写入错误vim core-site.xml #文件内容
<configuration><!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>tail -12 core-site.xml
3. hdfs-site.xml 是 HDFS 的特定配置文件,包含了与HDFS 相关的配置设置。配置该文件。
vim hdfs-site.xml
#文件内容,加在文章末尾</property>
<!-- 指定Hadoop名称节点主机配置 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name><value>master:50090</value>
</property>tail -12 hdfs-site.xml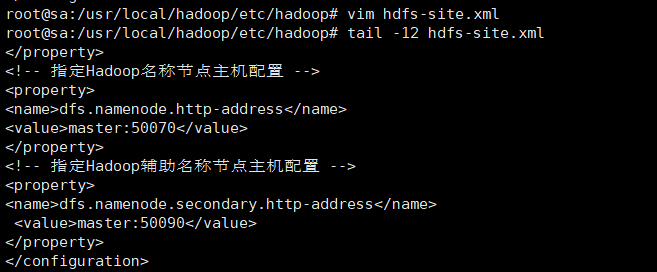
4.配置文件, yarn-site.xml是YARN的配置文件,它包含了YARN的各种配置信息,如ResourceManager的地址、NodeManager的资源配置、日志级别、任务调度器等。
常见配置:
vim yarn-site.xml
#文件内容
<!-- Site specific YARN configuration properties --><!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>tail -12 yarn-site.xml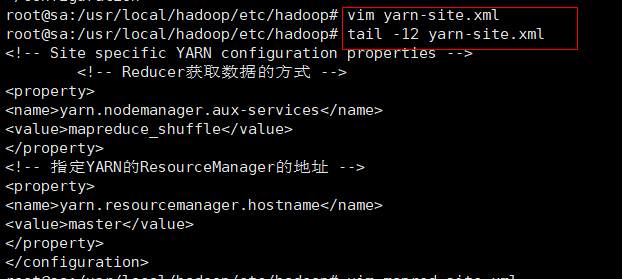
5. 配置文件,mapred-site.xml是Apache Hadoop中用于配置MapReduce框架的文件。
常见配置:
Hadoop2.X并没有像1.X提供mapred-site.xml文件,需要将样本文件复制为可使用的配置文件:
Ømv mapred-site.xml.template mapred-site.xml ,Hadoop3.X已经提供mapred-site.xml文件,本文所使用的为hadoop3.x。
Ømapreduce.jobtracker.address:指定 JobTracker 的地址和端口号。
Ømapreduce.framework.name:指定 MapReduce 框架的实现。对于 Hadoop 2.x,通常使用 YARN 作为资源管理器,因此设置为 yarn
Ømapreduce.map.memory.mb 和mapreduce.reduce.memory.mb:分别设置 Map 和Reduce 任务的内存大小(以 MB 为单位)
Ømapreduce.map.java.opts 和mapreduce.reduce.java.opts:设置 Map 和Reduce 任务的 JVM 选项。
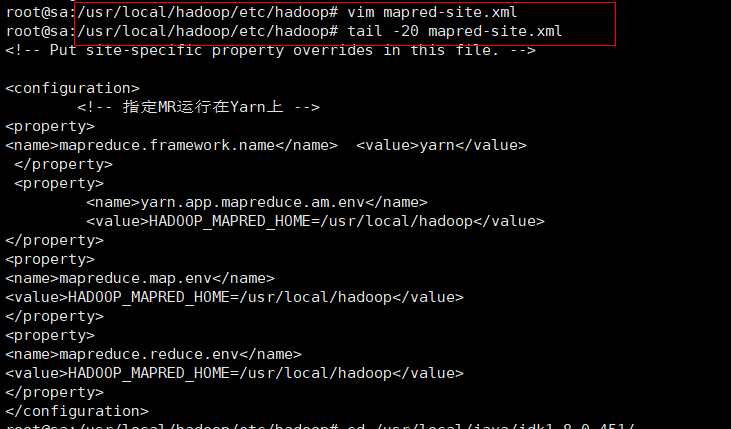
vim mapred-site.xml
#文件内容<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name> <value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>tail -20 mapred-site.xml
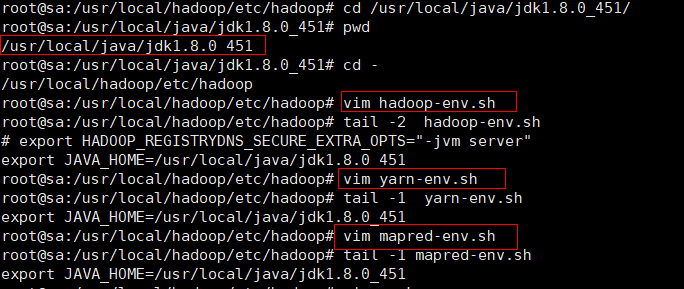
6、分别在以下3个配置文件(hadoop-env.sh和yarn-env.sh、mapred-env.sh)的最末尾添加java的环境变量。
6.1 hadoop-env.sh文件包含以下主要环境变量:
cd /usr/local/java/jdk1.8.0_451/
pwd
cd -
vim hadoop-env.sh
tail -1 hadoop-env.sh
#文件内容,在配置文件最末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_451
vim yarn-env.sh
tail -1 yarn-env.sh
#文件内容,在配置文件最末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_451
vim mapred-env.sh
tail -1 mapred-env.sh
#文件内容,在配置文件最末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_451
7. 编辑hadoop文件下的worker文件。通过在workers文件中列出这些节点的主机名或IP地址,可以控制哪些节点参与集群中的数据处理任务。
#修改workers,添加主机
sudo vim usr/local/hadoop/etc/hadoop/workers
#删除其中默认的localhost,改为master
#注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
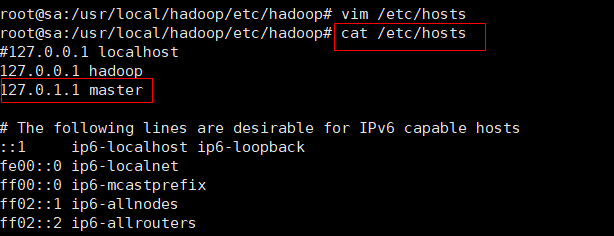
8. 配置hosts文件
vim /etc/hosts
cat /etc/hosts
#文件内容
#127.0.0.1 localhost
127.0.0.1 hadoop
127.0.1.1 master #主要修改这一行# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
9. 定义root用户操作,将hadoop的环境变量添加到系统当中,定义root用户操作hdfs namenode等服务
#定义root用户操作hdfs namenode等服务,
vim /etc/profile
#将以下内容写入配置文件profile末尾,并让修改后的文件生效。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#保存退出后,运行source /etc/profile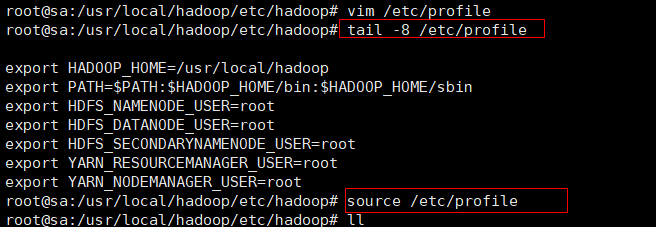
三、格式化hadoop
更改配置并保存后,格式化HDFS的NameNode,在这一步之前,如果hdfs-site.xml中
dfs.namenode.name.dir属性指定的目录不存在,格式化命令会自动创建;如果存在,请确保其权限设置正确,此时格式操作会清除其内部所有的数据并重新建立一个新的文件系统:
# /usr/local/hadoop/bin/hdfs namenode -format
/usr/local/hadoop/bin/hdfs namenode -format #格式化操作
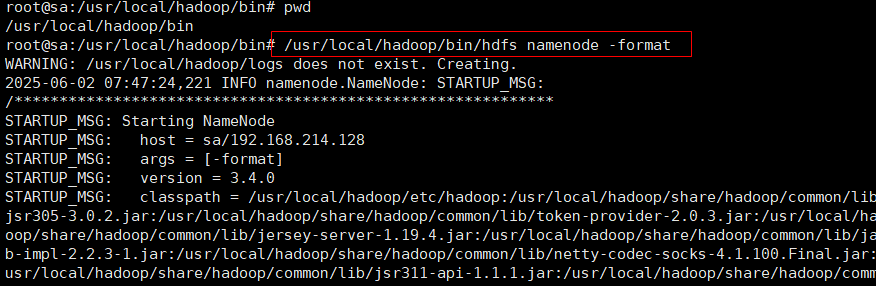
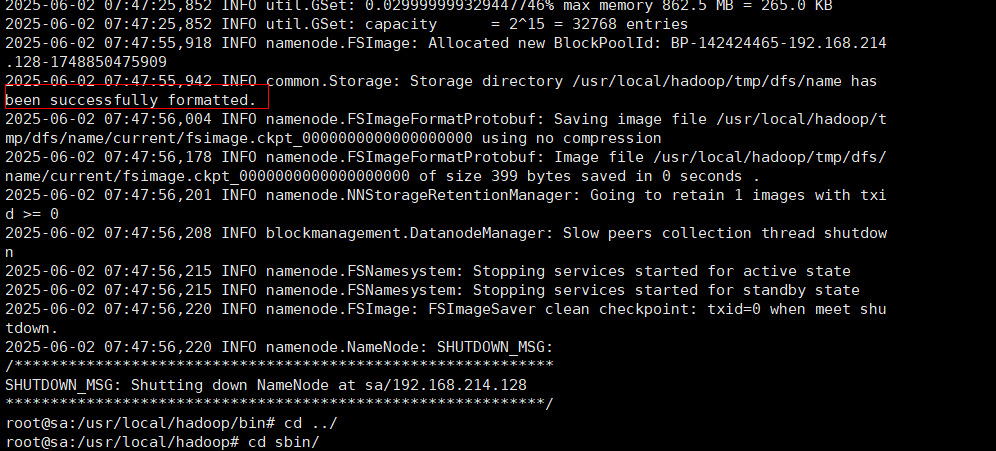
查看格式化是否成功:
四、启动hadoop进程
#启动前需要配置完成上述所有配置,并确认ssh免密登陆已配置完毕
/usr/local/hadoop/sbin
start-dfs.sh
start-yarn.sh
#或者使用以下命令
start-all.sh或./start-all.sh #PS:真实环境中,最好不要使用start-all.sh启动服务
jps #查看到如下进程则成功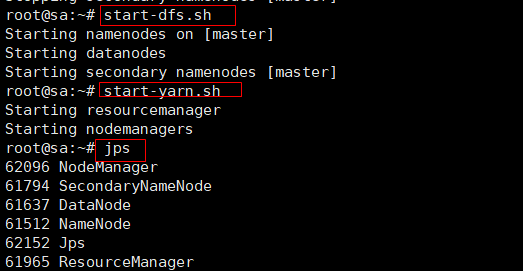
五、验证hadoop
1. 在HDFS中创建用户目录
hdfs dfs -mkdir -p /user/root #使用[用户名]登陆,并完成上述操作,必须/user/后跟对应
的[用户名]
hdfs dfs -mkdir input #创建input目录,用于输入数据
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input #将所需的xml配置文件复制到input中
#如果系统之前运行过hadoop,则需要删除output目录
hdfs dfs -rm -r output
#运行实例,需要先进入hadoop的文件夹下
cd /usr/local/hadoop
#然后输入如下命令
hadoop jar ./share/hadoop/mapreduce/hadoop- mapreduce-examples-*.jar wordcount input output
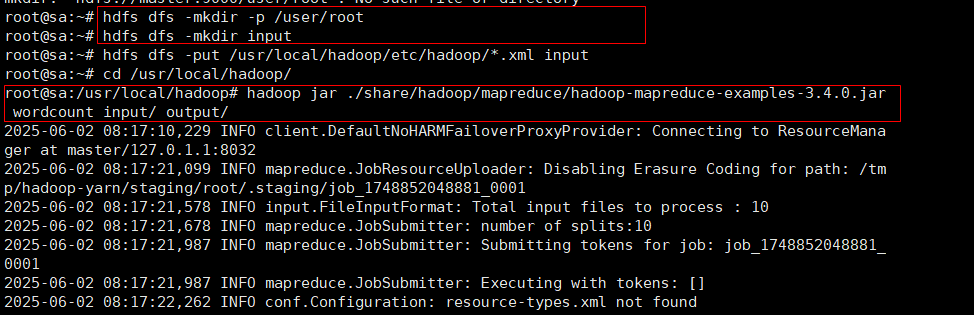
2、查看运行结果
hdfs dfs -ls ./output
hdfs dfs -cat output/*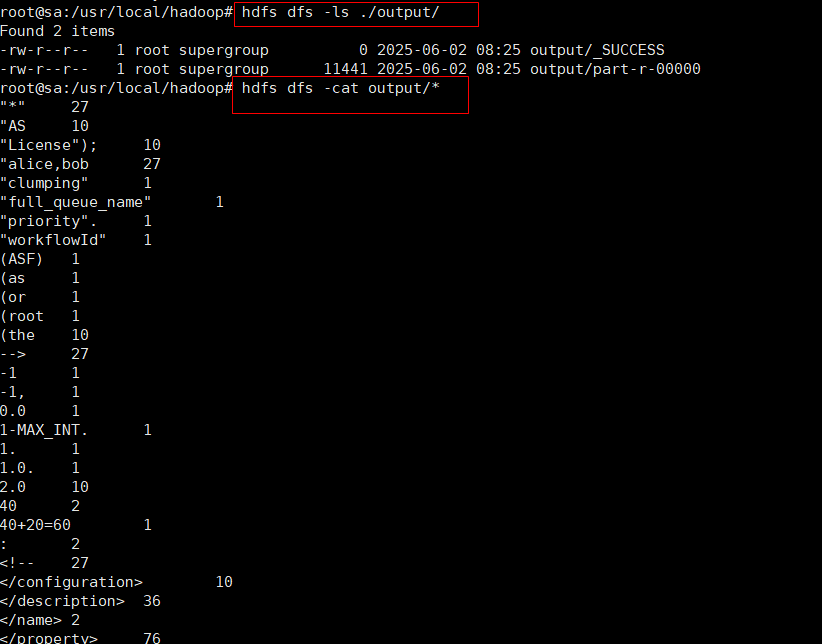
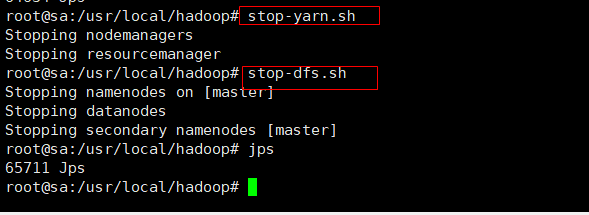
五、关闭hadoop集群
#若需关闭集群,在主机上输入相应关闭的命令。启动集群是先hdfs后yarn,关闭集群是先yarn后hdfs。须在
安装目录的/etc/hadoop目录下
stop-yarn.sh
stop-dfs.sh