【算法设计与分析】实验——改写二分搜索算法,众数问题(算法分析:主要算法思路),有重复元素的排列问题,整数因子分解问题(算法实现:过程,分析,小结)
说明:博主是大学生,有一门课是算法设计与分析,这是博主记录课程实验报告的内容,题目是老师给的,其他内容和代码均为原创,可以参考学习,转载和搬运需评论吱声并注明出处哦。
要求:2.1和2.2为算法分析题,写出主要的算法即可。2.3-2.5为算法实现题,要求写出:实验名称、实验过程描述(包括程序代码、测试用例、实验结果分析)、实验小结(包括实验过程中遇到的问题及体会)。
2.1
设a[0:n-1]是一个有n个元素的数组,k(0<=k<=n-1)是一个非负整数。试设计一个算法将子数组a[0:k]与a[k+1,n-1]换位。要求算法在最坏情况下耗时O(n),且只用到O(1)的辅助空间。
主要算法思路:
原地将a[0:k]转置,然后将a[k+1,n-1]转置,最后将a[0:n-1]转置,得到的结果与换位结果一样。
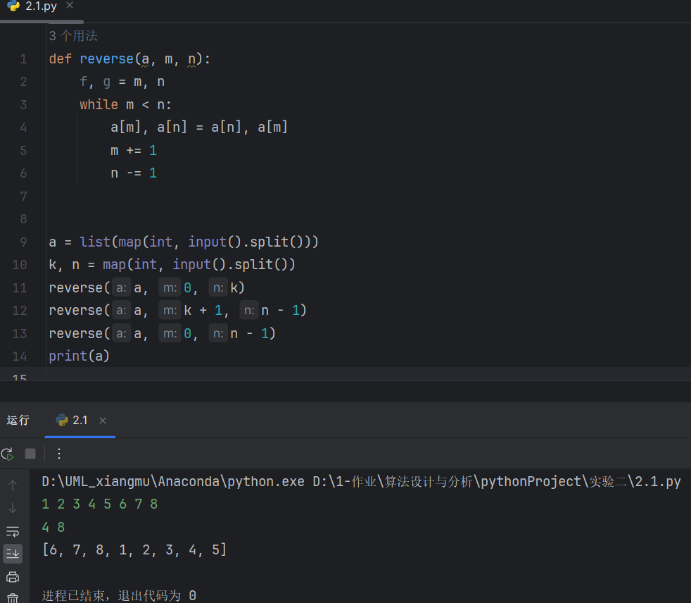
def reverse(a, m, n):f, g = m, nwhile m < n:a[m], a[n] = a[n], a[m]m += 1n -= 1a = list(map(int, input().split()))
k, n = map(int, input().split())
reverse(a, 0, k)
reverse(a, k + 1, n - 1)
reverse(a, 0, n - 1)
print(a)
2.2 改写二分搜索算法
设a[0 : n - 1]是已排好序的数组。请改写二分搜索算法,使得当搜索元素 x 不在数组中时,返回小于 x 的最大元素的位置 i 和大于 x 的最小元素位置 j。当搜索元素在数组中时,i 和 j 相同,均为 x 在数组中的位置。
主要算法思路:
正常进行二分查找算法。但不同的是函数的返回值为查找的边界,注意在最后一轮查找后左边界会比右边界大一个(如果没找到的话),所以要交换两个变量的位置即可满足题目要求。
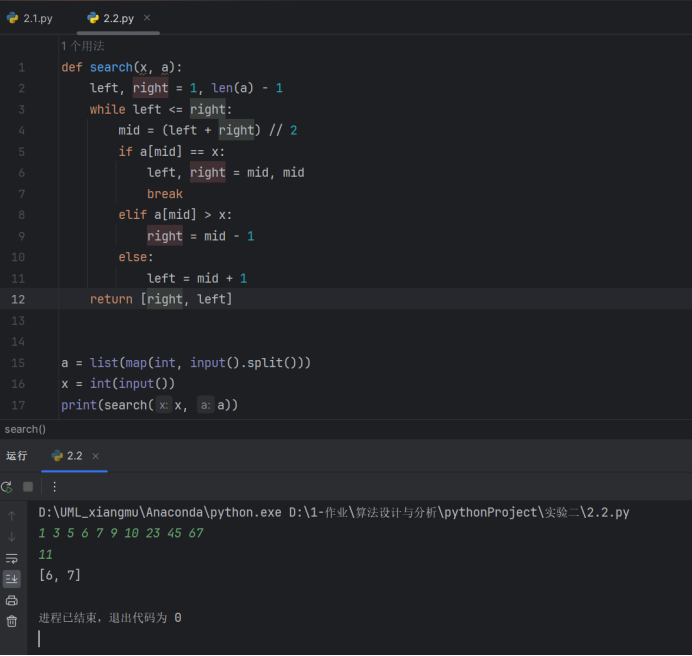
def search(x, a):left, right = 1, len(a) - 1while left <= right:mid = (left + right) // 2if a[mid] == x:left, right = mid, midbreakelif a[mid] > x:right = mid - 1else:left = mid + 1return [right, left]a = list(map(int, input().split()))
x = int(input())
print(search(x, a))
2.3 众数问题
问题描述:
给定含有n个元素的多重集合S,每个元素在S中出现的次数称为该元素的重数。多重集S中重数最大的元素称为众数。
例如,S={1,2,2,2,3,5}。
多重集S的众数是2,其重数为3。
编程任务:
对于给定的由n个自然数组成的多重集S,编程计算S 的众数及其重数。
数据输入:
输入数据由文件名为input.txt的文本文件提供。
文件的第1行多重集S中元素个数n;接下来的n 行中,每行有一个自然数。
结果输出:
程序运行结束时,将计算结果输出到文件output.txt中。输出文件有2 行,第1行给
出众数,第2行是重数。
程序代码,测试用例:
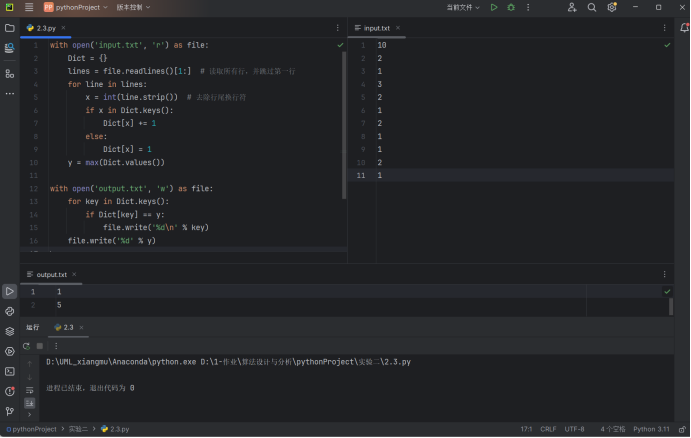
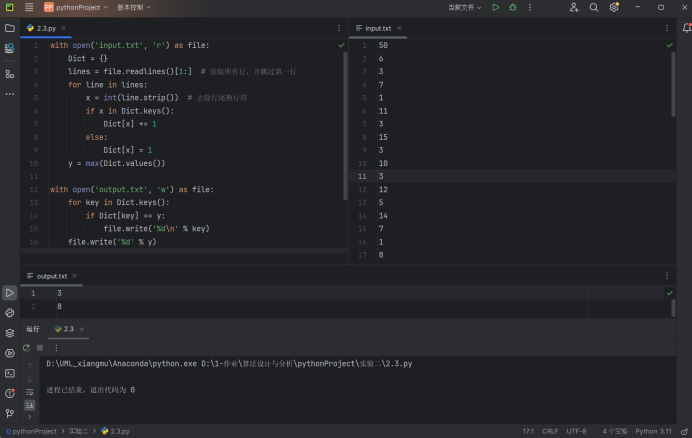
with open('input.txt', 'r') as file:Dict = {}lines = file.readlines()[1:] # 读取所有行,并跳过第一行for line in lines:x = int(line.strip()) # 去除行尾换行符if x in Dict.keys():Dict[x] += 1else:Dict[x] = 1y = max(Dict.values())with open('output.txt', 'w') as file:for key in Dict.keys():if Dict[key] == y:file.write('%d\n' % key)file.write('%d' % y)
题目中给出的两组测试用例分别得到的结果是[1,5]和[3,8],如下图所示
实验结果分析:
本次实验取得了预期的实验效果,正确的从input.txt读取数据并将结果写入output.txt。
本次算法和代码设计思路:用python中的一个字典来存放,字典的键为出现过的数字,字典的值为这个数字出现过的次数。读取文件时采用一行一行的读取,每次读取一个就在字典里面进行记录一次。后用max函数找出出现次数最大的值,最后遍历字典进行输出,并将结果写入文件。
时间复杂度:最好和最坏情况下的时间复杂度都是O(n),n为文件里数据的行数。
空间复杂度:最好情况下为O(1),所有元素都相同,最坏情况下为O(n),所有元素都不相同。
实验小结:
本次实验主要的困难在于对python语言中文件的读写操作不够熟悉;查询相关资料后掌握了python中文件读写操作的相关代码。
实验中还有两个需要注意的细节,一个是读取文件中的第一行代表的是接下来会有几行数据这可能在C或C++编程中有些用处,但python并不需要,所以可以采用切片的方式从第二行开始读取数据;还有一个点是读取到每一行的数据会包含一个换行符,可以用strip()函数去除,不然没办法正常转换为整型。
2.4 有重复元素的排列问题
问题描述:
设 R={ r1 , r2, …, rn }是要进行排列的n个元素。其中元素 r1 , r2 , , rn 可能相同。试设计一个算法,列出R的所有不同排列。
编程任务:
给定n以及待排列的n个元素。计算出这n个元素的所有不同排列。数据输入:
由文件input.txt 提供输入数据。文件的第1 行是元素个数n,1£n£500。接下来的1 行是待排列的n个元素。
结果输出:
程序运行结束时,将计算出的n 个元素的所有不同排列输出到文件output.txt 中。文件最后1 行中的数是排列总数。
程序代码,测试用例:
def sorting(a, flag):if len(a) == len(num):# print(a)res.append(a.copy())returnfor i in range(0, len(num)):# 当前元素被访问过if flag[i]:continue# 剪枝:相同元素需要按顺序加入elif i > 0 and num[i] == num[i - 1] and not flag[i - 1]:continue# 正常添加a.append(num[i])flag[i] = True# 进行递归sorting(a, flag)# 回溯a.pop()flag[i] = Falseres = []
with open('input.txt', 'r') as file:next(file) # 从第二行开始读num = list(file.readline().strip())# print(num)num.sort()# print(num)sorting([], [False]*len(num))
with open('output.txt', 'w') as file:for j in res:Str = ''.join(j)# print(Str)file.write(Str + '\n')file.write('%d' % len(res))
题目中给出的测试用例得到的结果是2520,如下图所示.代码如下图两段红框中所示
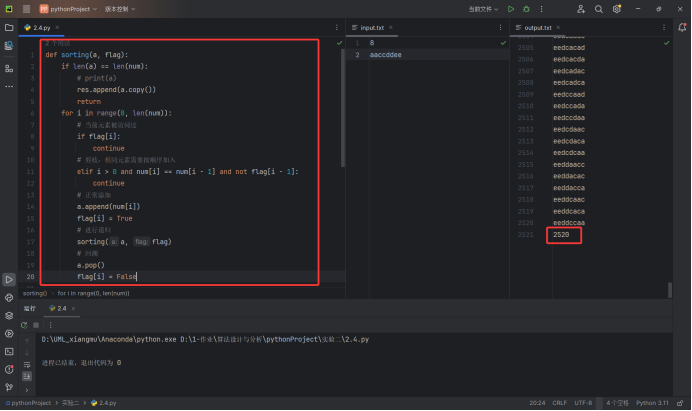
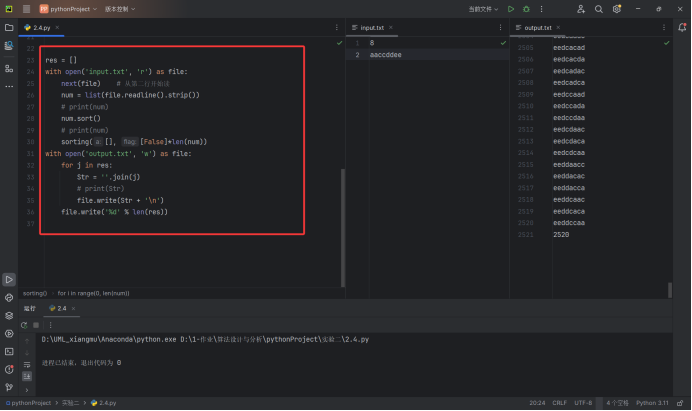
实验结果分析:
本次实验正确实现了列出有重复元素的所有无重复排序。
算法:本次算法涉及到两个重点,一是通过剪枝来避免有重复排序的情况,一是通过回溯来列出所有可能排列。主要是通过递归来生成可能序列,同时用回溯的方法来生成所有可能排列。剪枝是指,如果有两个相同的元素,一定确保第一个元素使用之后再使用第二个元素,也就是相同元素一定有一个出现的顺序,如果没有顺序就会有,[a(第一个),a(第二个)],[a(第二个),a(第一个)]这样重复的情况,所以在排序之前就要先按一定顺序进行排列,确保相同元素放在一起。
程序设计:本题我用python进行实现,传入函数两个数组,一个是生成的排序数组,一个是标志数组,标志该元素是否被引用。
时间复杂度:最坏情况下,每个元素都不相同,递归树有n!个叶子节点,每个叶子节点要O(n)时间复制到结果中,所以是O(n!×n)
实验小结:
我认为本次算法难度较大,我也是在上网查询相关算法题目和思路后理解掌握,编写本题代码。递归思路理解方面难度最大。
算法方面主要学到了用递归和回溯来遍历所有可能结果,用剪枝来避免重复情况。程序涉及方面复习到了用next()函数来跳过第一行,使用join()函数将列表转换为字符串,输出函数中可以使用“+”来添加内容。
2.5 整数因子分解问题问题描述:
大于1的正整数n可以分解为:n=x1*x2*…*xm。
例如,当n=12 时,共有8 种不同的分解式:
12=12;
12=6*2;
12=4*3;
12=3*4;
12=3*2*2;
12=2*6;
12=2*3*2;
12=2*2*3。
编程任务:
对于给定的正整数n,编程计算n共有多少种不同的分解式。
数据输入:
由文件input.txt给出输入数据。第一行有1 个正整数n (1≤n≤2000000000)。
结果输出:将计算出的不同的分解式数输出到文件output.txt。
程序代码,测试用例:
# 记录所有可能
# num = 1
# x表示要分解的数
def resolve(x, num):global resultif num == x:result += 1returnif num > x:returnfor i in range(x, 1, -1):if x % i == 0 and num * i <= x:num *= i# 递归resolve(x, num)# 回溯num %= iresult = 0
n = int(input())
resolve(n, 1)
print(result)
题目中给出的测试用例得到的结果是2520,如下图所示.代码如下图两段红框中所示
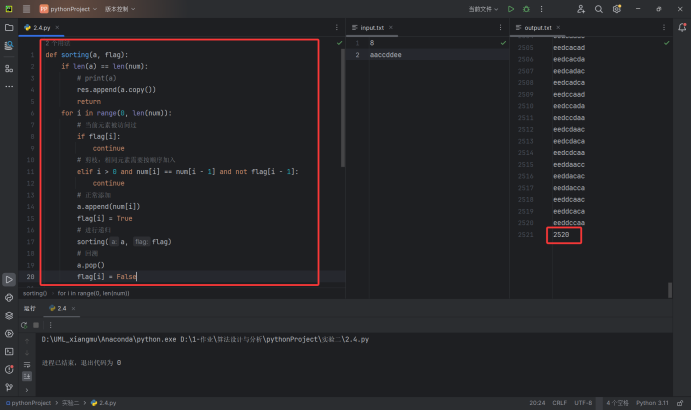
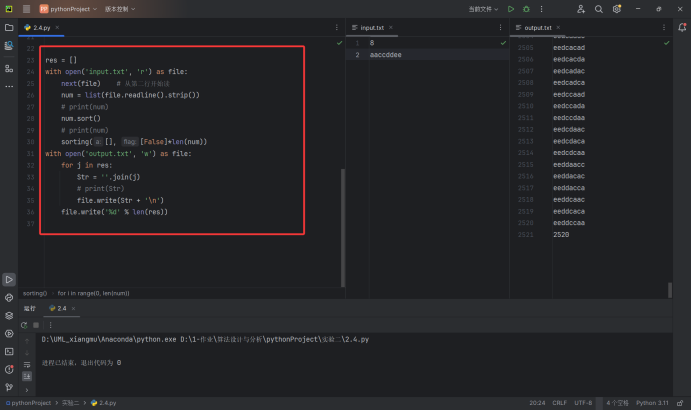
实验结果分析:
本次实验正确实现了列出有重复元素的所有无重复排序。
算法:本次算法涉及到两个重点,一是通过剪枝来避免有重复排序的情况,一是通过回溯来列出所有可能排列。主要是通过递归来生成可能序列,同时用回溯的方法来生成所有可能排列。剪枝是指,如果有两个相同的元素,一定确保第一个元素使用之后再使用第二个元素,也就是相同元素一定有一个出现的顺序,如果没有顺序就会有,[a(第一个),a(第二个)],[a(第二个),a(第一个)]这样重复的情况,所以在排序之前就要先按一定顺序进行排列,确保相同元素放在一起。
程序设计:本题我用python进行实现,传入函数两个数组,一个是生成的排序数组,一个是标志数组,标志该元素是否被引用。
时间复杂度:最坏情况下,每个元素都不相同,递归树有n!个叶子节点,每个叶子节点要O(n)时间复制到结果中,所以是O(n!×n)
实验小结:
我认为本次算法难度较大,我也是在上网查询相关算法题目和思路后理解掌握,编写本题代码。递归思路理解方面难度最大。
算法方面主要学到了用递归和回溯来遍历所有可能结果,用剪枝来避免重复情况。程序涉及方面复习到了用next()函数来跳过第一行,使用join()函数将列表转换为字符串,输出函数中可以使用“+”来添加内容。