Python Day40 学习(复习学习日志Day5-7)
重新对信贷数据集进行了填补空缺值的操作
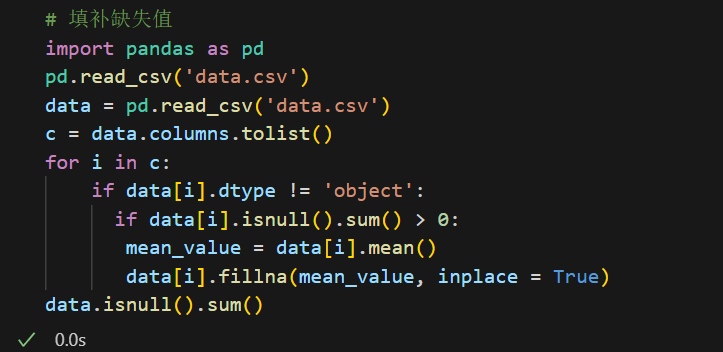
自己写的时候,还是出现了问题:
首先是忘记了要定义一下data, 通过data =pd.read_csv('data.csv')可以将读取到的数据保存到变量data中,方便后续进行数据分析。
其次,是漏掉了
c = data.columns.tolist()这行代码的作用是:把DataFrame的所有列名提取出来,转换成一个列表,赋值给变量c。
data.columns得到的是一个包含所有列名的Index对象。.tolist()方法把这个Index对象转换成普通的Python列表。- 这样,
c就是一个包含所有列名的列表,比如:['A', 'B', 'C', ...]。
这样做的好处是,后面可以用for i in c:来遍历每一列,方便批量处理每一列的数据。
复习日志Day5,Day6,Day7的内容
补充:关于括号中逗号的使用
在 pd.get_dummies(data, columns=['Home Ownership']) 这样的函数调用中,括号里的逗号是用来分隔不同的参数的。
详细解释
- 在 Python 的函数调用中,括号里可以传递多个参数,每个参数之间用逗号
,分隔。 - 比如:
函数名(参数1, 参数2, 参数3, ...) - 在
pd.get_dummies这个函数里:- 第一个参数
data是要处理的数据(DataFrame)。 - 第二个参数
columns=['Home Ownership']是一个关键字参数,指定要进行独热编码的列。
- 第一个参数
- 如果你还要加其他参数,比如
drop_first=True,也要用逗号分隔。
勘误:须先填补缺失值再进行独热编码
补充:关于drop_first = True

手写笔记复习



今日复习到这里,明日继续,加油!@浙大疏锦行