文件索引:数组、二叉树、二叉排序树、平衡树、红黑树、B树、B+树
参考链接:https://www.bilibili.com/video/BV1mY4y1W7pS
数据结构可视化工具:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
问题引出:一般是什么原因导致从磁盘查找数据效率低?
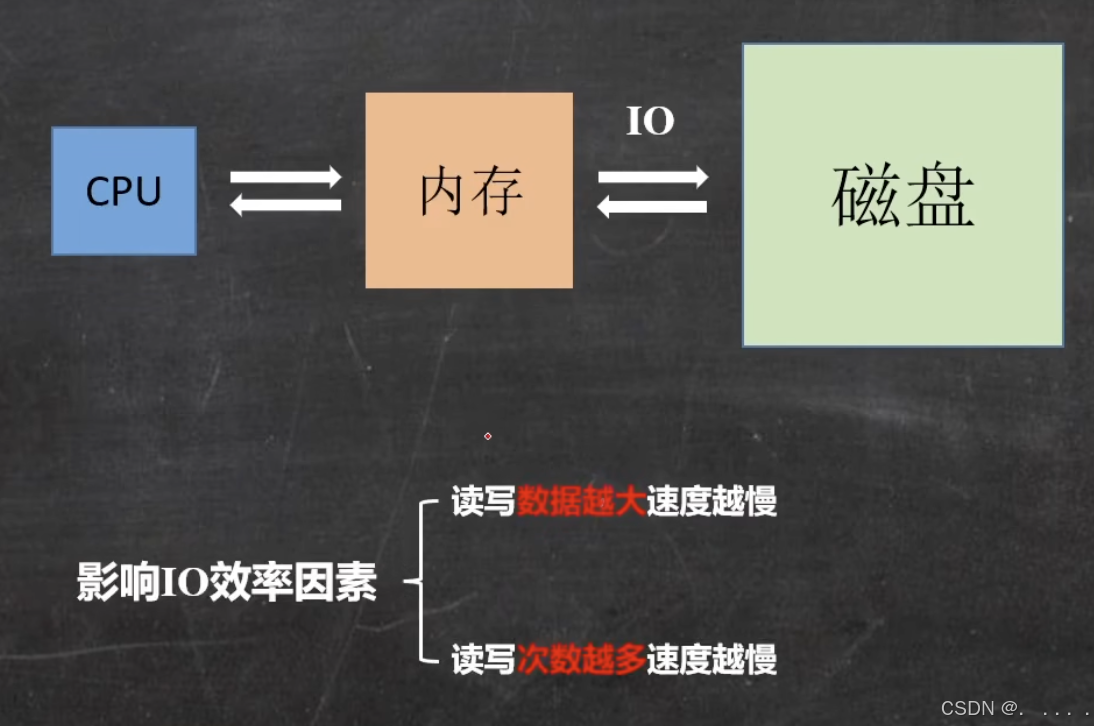
通过索引来更快的查询数据,那么如何设计文件系统的索引结构?
1. 线性的数据结构,比如数组
问题:查询效率为O(n),且如何涉及到插入和删除,效率很低。
2. 哈希表

问题:
1、hash冲突后,数据散列不均匀,产生大量线性查询,效率低。
2、等值查询可以,但是遇到范围查询,得挨个遍历,hash就不合适了。
考虑用树的结构
3. 二叉树
问题:二叉树是没有顺序的,依然需要每个节点都遍历
4. 二叉排序树或称为二叉查找树 BST
查找效率 O(log n)
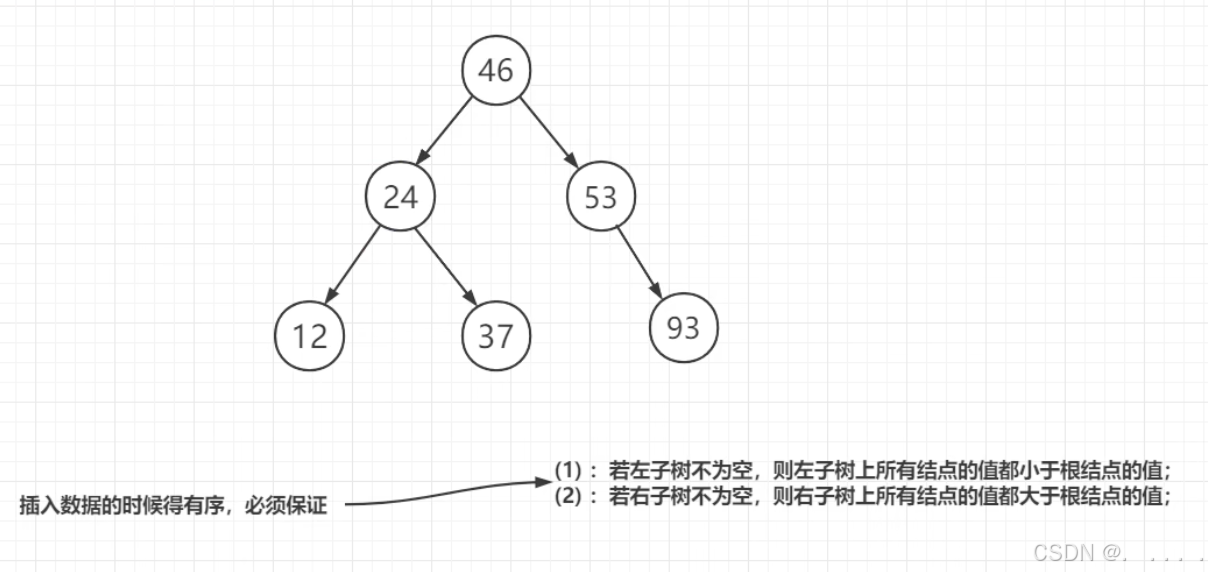
问题:假如插入顺序的时候是按照从小到大插入的,就会变成如下顺序结构,查询效率也会变成O(n)
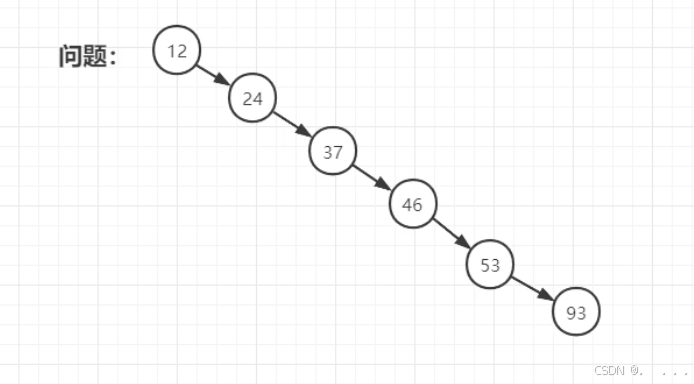
- 平均查找长度与树的高度有关
- 平均查找长度越小,查找速度越快,所以要让树尽可能的矮
5. 平衡二叉树 AVL:
什么是平衡二叉树?
1、平衡二叉树首先是二叉排序树
2、满足每个节点的平衡因子绝对值不大于1
参考链接:https://www.bilibili.com/video/BV1d7411u79x
为了解决二叉排序树极端情况变成线性结构,因此引入了平衡因子的概念,平衡因子其实就是一个数值,左子树的高度 - 右子树的高度 的绝对值。
比如:

如何构造平衡二叉树呢?参考如下教程:https://www.bilibili.com/video/BV1s64y157Vn
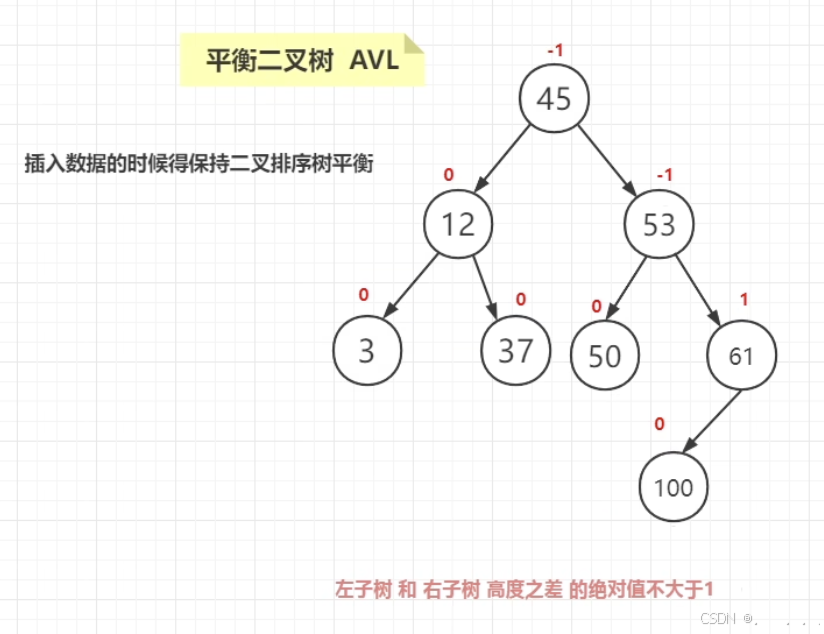
问题:用插入的成本来弥补查询的效率,但一旦出现插入的成本比查询操作多,就不划算了。
6. 红黑树
由于平衡二叉树的构造非常好性能,因此有了红黑树。
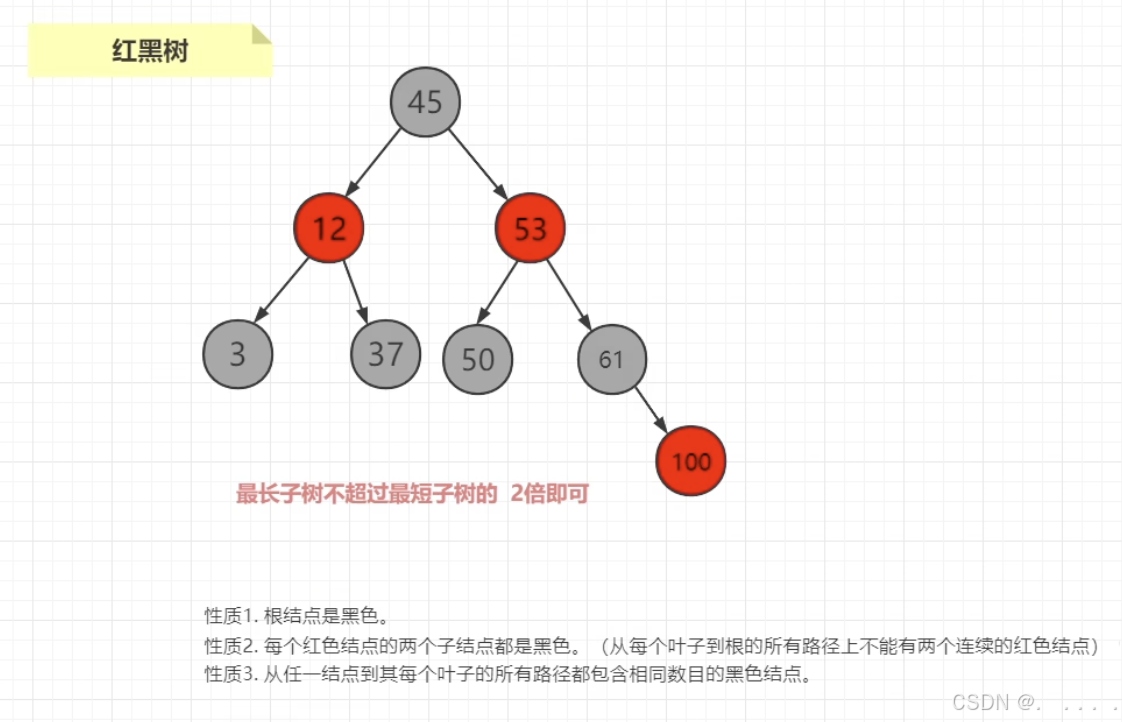
缺点:如果数据量特别大,树足够的深呢?那么查找效率还是会降低。
7. B树
注意B-Tree 其实是B树,中间的-是横杠,在国内翻译错了,但是有B+树。
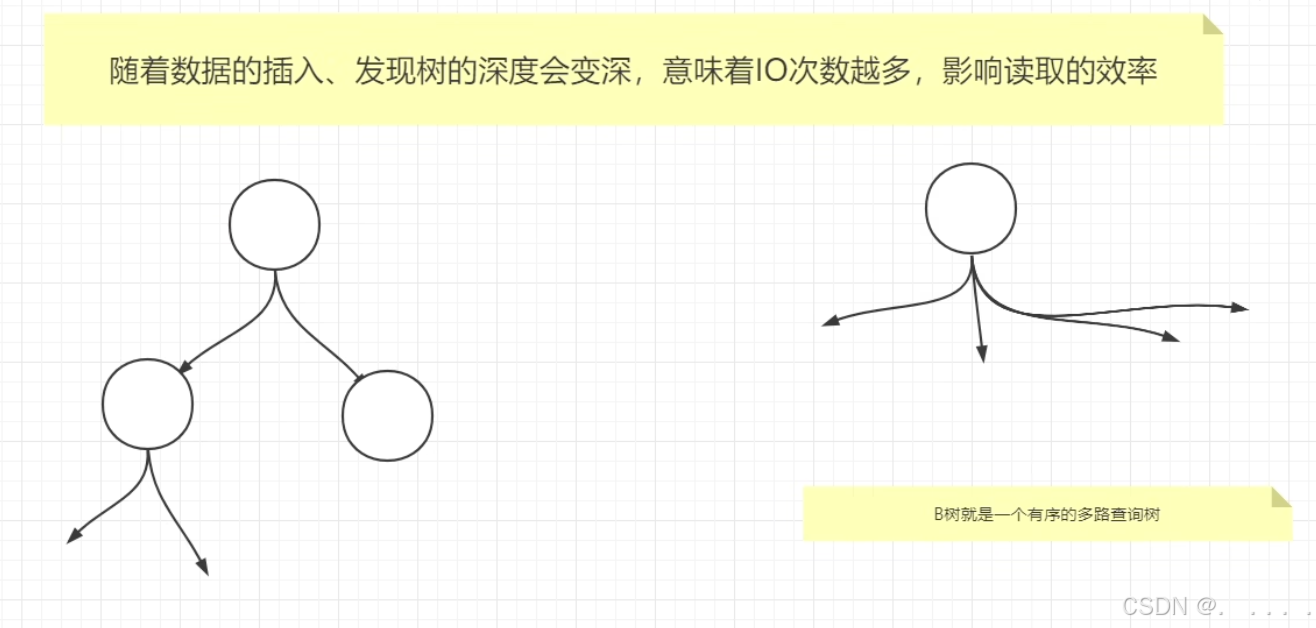
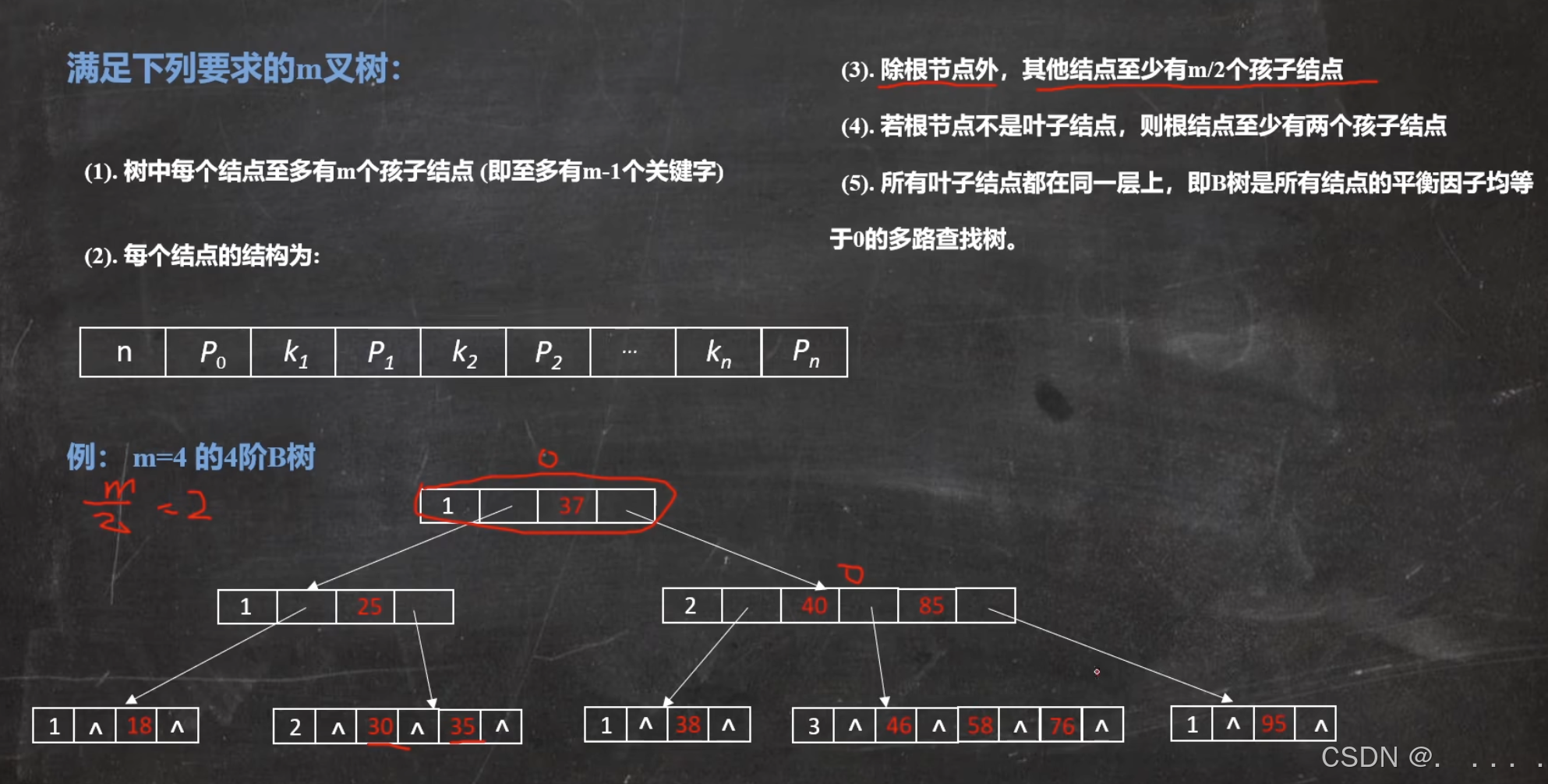
B树就是一个有序的多路查询树
8. B+树
非叶子节点只存记录和指针,叶子节点只存数据。这样能解决一下子从磁盘读取更多索引内容。