YOLOv10改进|爆改模型|涨点|C2F引入空间和通道注意力模块暴力涨点(附代码+修改教程)
一、文本介绍
本文修改的模型是YOLOv10,YOLOv10无需非极大值抑制(NMS)进行后处理,其推理速度以及参数量上都优于现有的模型。C2f (Cross-Stage Partial-Connection with 2 convolutions) 模块是YOLOv6中引入的一种结构,其主要目的是在保持高效性的同时,增强特征融合能力。它通过将输入特征图拆分为两部分,一部分直接通过,另一部分经过一系列卷积操作后再与前者拼接,从而实现跨阶段的特征融合。尽管C2f在YOLOv6中表现出色,但多尺度目标检测仍然是一个核心挑战。在实际场景中,目标的大小差异巨大,从几十个像素的小目标到上千个像素的大目标都可能存在。这给模型带来了以下挑战:
- 小目标信息丢失: 经过多层卷积和下采样后,小目标的特征信息容易丢失,导致检测困难。
- 大目标特征冗余: 大目标包含的像素信息较多,如果模型不加区分地处理,可能会引入冗余,降低计算效率。
- 感受野与尺度不匹配: 不同尺度的目标需要不同大小的感受野才能有效提取特征。单一的感受野设计难以同时适应所有尺度。
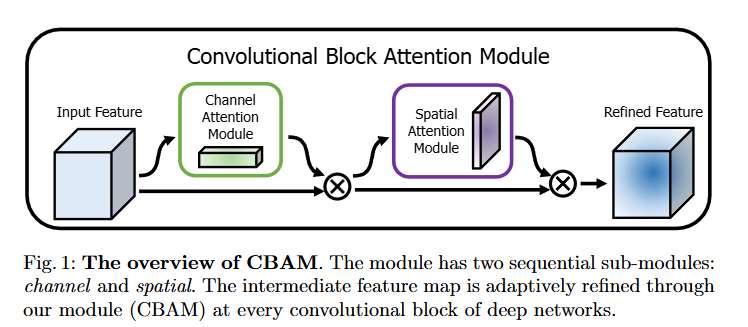
因此本文提出一种在C2F后面引入 CBAM(Convolutional Block Attention Module)空间和通道注意力模块,处理多尺度问题时,提升模型的性能和鲁棒性。(本文以YOLOv10为例,C2F在YOLOv6后的版本几乎都存在,可以在v6、v8等等yolo系列算法上修改)
YOLOv10论文地址:https://arxiv.org/pdf/2405.14458
C2F模块出处:https://arxiv.org/pdf/2209.02976
CBAM注意力模块论文:https://arxiv.org/pdf/1807.06521
二、模型图
模型架构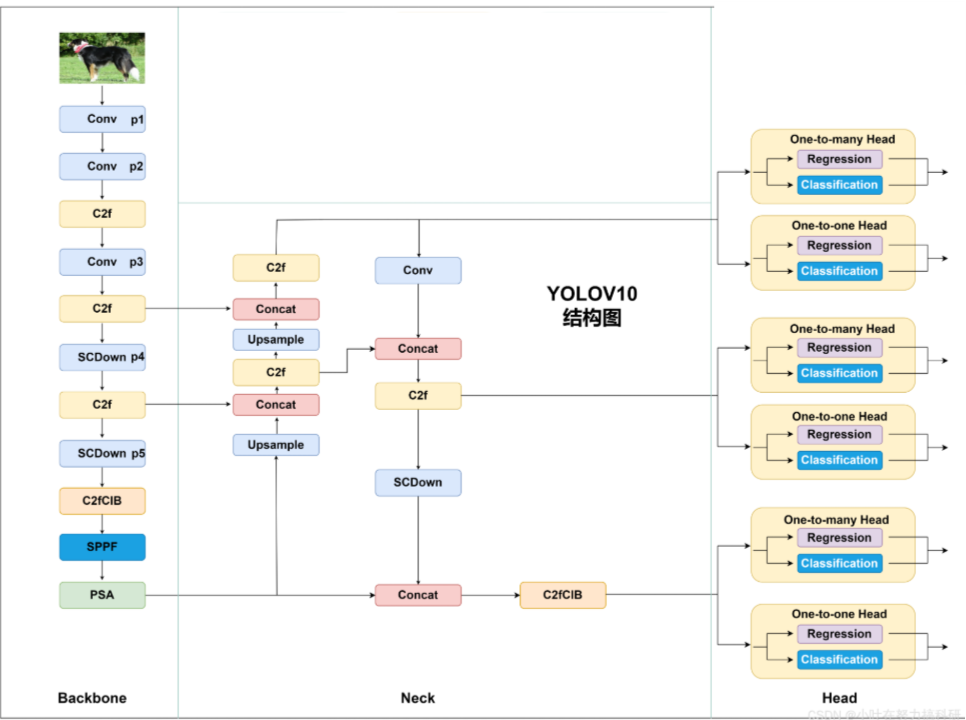
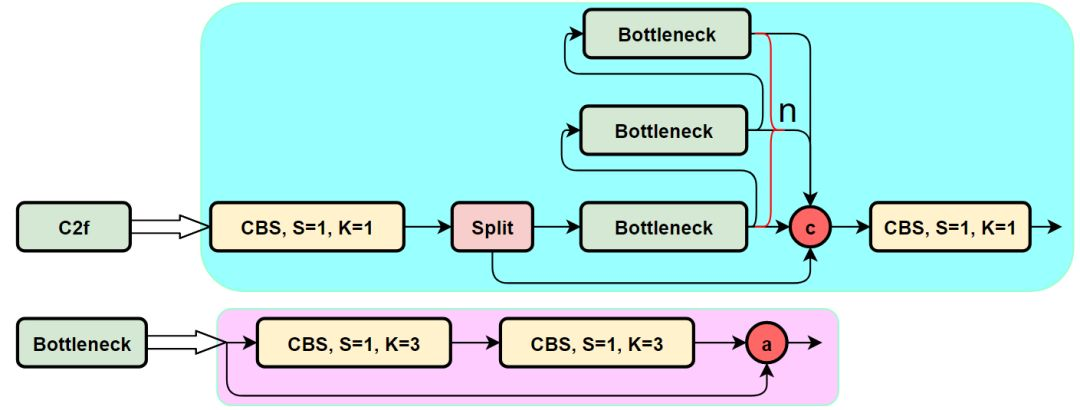
C2F模块:
CBAM模块:
三、核心代码
在block.py中追加CBAM模块的具体代码如下:
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),nn.ReLU(),nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))out = avg_out + max_outreturn self.sigmoid(out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out = torch.max(x, dim=1, keepdim=True)[0]x_cat = torch.cat([avg_out, max_out], dim=1)out = self.conv1(x_cat)return self.sigmoid(out)class CBAM(nn.Module):def __init__(self, in_planes, ratio=16, kernel_size=7):super(CBAM, self).__init__()self.ca = ChannelAttention(in_planes, ratio)self.sa = SpatialAttention(kernel_size)def forward(self, x):x = x * self.ca(x)x = x * self.sa(x)return x其次在C2F模块中加入CBAM注意力代码如下:
class C2f(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions, with integrated CBAM."""def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = False, g: int = 1, e: float = 0.5):"""Initialize a CSP bottleneck with 2 convolutions and an optional CBAM module.Args:c1 (int): Input channels.c2 (int): Output channels.n (int): Number of Bottleneck blocks.shortcut (bool): Whether to use shortcut connections.g (int): Groups for convolutions.e (float): Expansion ratio."""super().__init__()self.c = int(c2 * e)self.cv1 = Conv(c1, 2 * self.c, 1, 1)# 移除了原有的 self.cv2 初始化,现在它只在下方被初始化一次self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))# 在 Bottleneck 模块输出后和最终卷积前添加 CBAMself.cbam = CBAM((2 + n) * self.c) # CBAM作用于拼接后的特征self.cv2 = Conv((2 + n) * self.c, c2, 1) # 确保 cv2 只在这里初始化一次def forward(self, x: torch.Tensor) -> torch.Tensor:"""Forward pass through C2f layer with CBAM."""y_chunks = list(self.cv1(x).chunk(2, 1))bottleneck_outputs = []current_feature = y_chunks[-1]for m_block in self.m:current_feature = m_block(current_feature)bottleneck_outputs.append(current_feature)y_chunks.extend(bottleneck_outputs)concatenated_features = torch.cat(y_chunks, 1)# 应用 CBAM 到拼接后的特征attended_features = self.cbam(concatenated_features)return self.cv2(attended_features)def forward_split(self, x: torch.Tensor) -> torch.Tensor:"""Forward pass using split() instead of chunk(), with CBAM."""y = self.cv1(x).split((self.c, self.c), 1)y_chunks = [y[0], y[1]]bottleneck_outputs = []current_feature = y_chunks[-1]for m_block in self.m:current_feature = m_block(current_feature)bottleneck_outputs.append(current_feature)y_chunks.extend(bottleneck_outputs)concatenated_features = torch.cat(y_chunks, 1)attended_features = self.cbam(concatenated_features)return self.cv2(attended_features)不需要在其他部分进行修改非常暴力,这也是为一个很好的水论文创新点方法,修改简单。当然可以尝试其他注意力或卷积模块(有需要可以私聊)。
其他部分不需要做任何修改。
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv8.0n head
head:- [[4, 6, 10, 4], 1, SDI, [64]]- [[4, 6, 10, 6], 1, SDI, [128]]- [[4, 6, 10, 10], 1, SDI, [256]]- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 12], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 11], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 16], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[19, 22, 25], 1, v10Detect, [nc]] # Detect(P3, P4, P5)