大模型登《情报学报》!大模型驱动的学术文本挖掘!
武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所的陆伟、刘寅鹏、石湘、刘家伟、程齐凯、黄永和汪磊共同研究的《大模型驱动的学术文本挖掘——推理端指令策略构建及能力评测》在《情报学报》中发表。论文以学术文本挖掘任务为切入点,构建涵盖文本分类、信息抽取、文本推理和文本生成4个能力维度共6项任务的大模型学术文本挖掘专业能力评测框架。内容十分详细精彩,具体可阅读原文。
数据说明
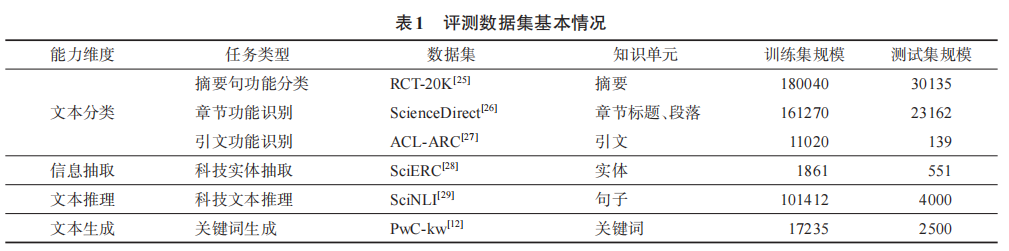
按 “能力 - 任务 - 指标” 划分为 3 层维度,包含 6 个评测数据集、总计 37747 条测试样本。
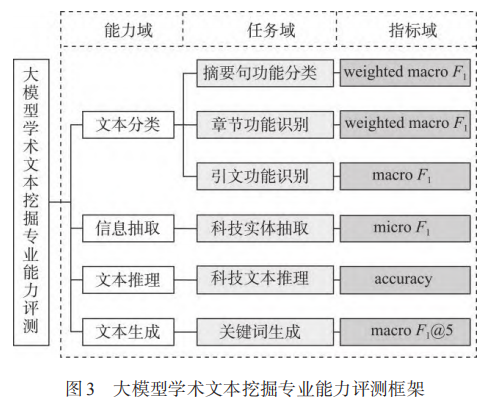
学术文本挖掘专业能力评测框架
能力维度
参照文本挖掘技术任务划分,从知识单元粒度和能力本质特征出发,将学术文本挖掘任务归纳为文本分类、信息抽取、文本推理和文本生成 4 个类别,其中文本分类侧重于大模型对学术文本中句子层级和段落层级知识单元的属性或关系判别能力,信息抽取关注大模型从非结构化或半结构化数据中提取词汇层级知识单元(如命名实体等)的结构化信息的水平,文本推理面向句子层级知识单元、考察大模型理解学术文本关键句之间隐含逻辑关系或事实的能力,文本生成则关注从现有知识单元中派生或重组出新知识单元的能力。
任务维度
遵循覆盖学术文本知识单元全粒度(包括关键词、句子、摘要、段落、章节、引文等)和有明确可信评测指标的原则,选取英文数据集作为评测基准。
指标维度
为消除人类主观偏见、确保低资源设定下指令引导的大模型与 “预训练 - 微调” 模型的可比较性,选择各类任务的典型指标。
参考文献
陆伟,刘寅鹏,石湘,等.大模型驱动的学术文本挖掘——推理端指令策略构建及能力评测[J].情报学报,2024,43(08):946-959.