【AI学习】检索增强生成(Retrieval Augmented Generation,RAG)
1,介绍
出自论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》,RAG是权宜之计,通过RAG将问题简单化、精简化、剔除噪声,让LLM更容易理解、生成内容。RAG:检索增强技术=检索+生成(重排)。
1)场景
通过集成外部知识从而减少特定领域LLM幻觉问题,相比微调和强化学习陈本极低。
2,基本原理和架构
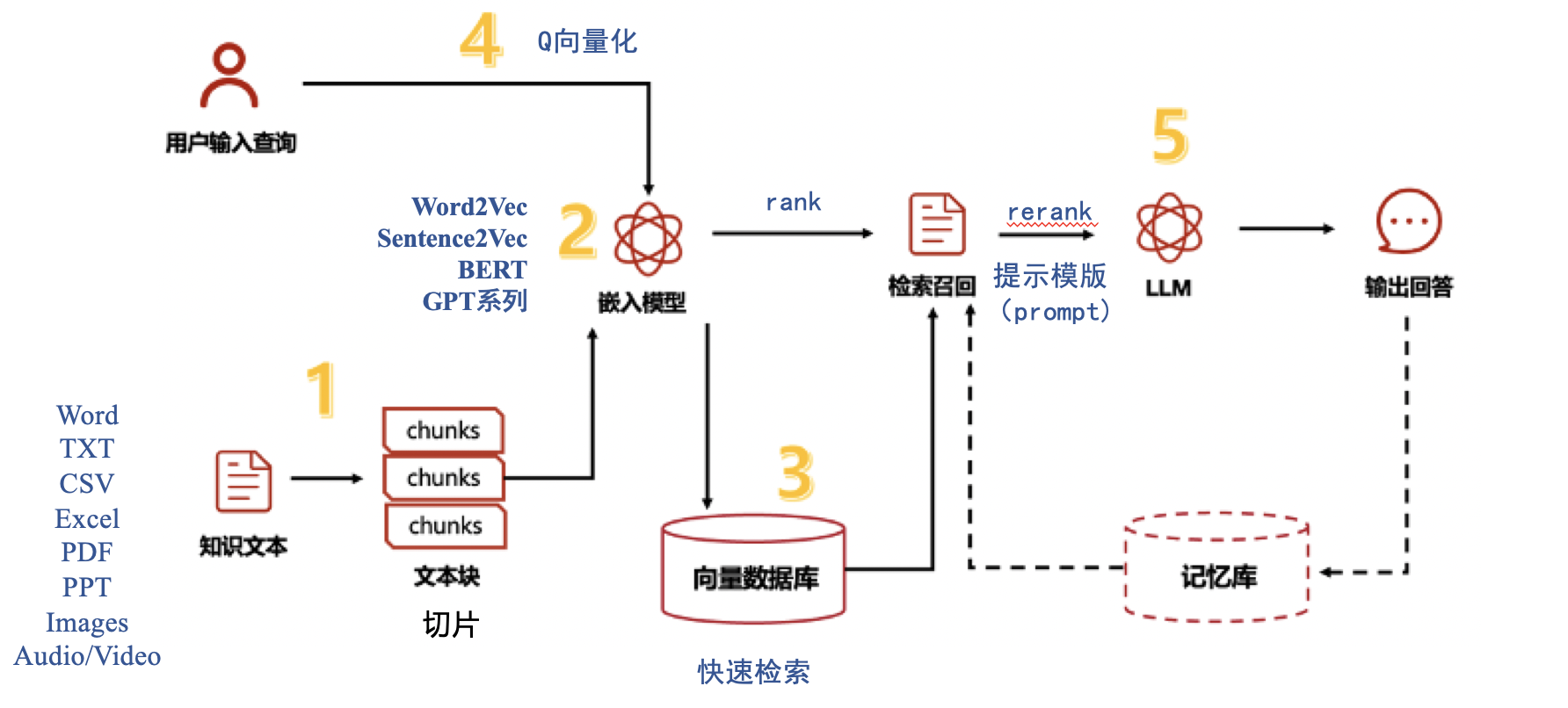
RAG系统可以分为检索和生成两个阶段:
1)检索过程
通过检索找到与用户查询密切相关的知识库(KB)内容:
1> 切片(Chunking,切块)
将文档划分为较小的、语义上有意义的片段;文档可以支持多模态(Word、TXT、CSV、Excel、PDF、PPT、Images、Audio/Video等)转换为文本,最终还是对文本进行处理。
太大数据检索准确率下降,太小丢失上下文信息,找到平衡点。分块方式:
- 固定大小分块(Fixed-size chunking)、
- 递归分块(Recursive chunking)、
- 基于文档(Document-based chunking)
文档有一定的格式如html或者带标题、 - 语义分块(Semantic chunking):
余弦定理。 - LLM分块
除此之外分块之前还会做一些数据清洗已提高RAG的准确率:冗余消除、专有名词、数据增强(同义词近义词翻译库)、用户反馈、过期文档。
2>创建嵌入(Create embeddings)
嵌入模型将每个信息块压缩为向量表示;常用的模型:
- Word2Vec
- Sentence2Vec
- BERT
- GPT系列
3>索引(Indexing)
将嵌入向量存入向量库中(键值对),从而实现高效且可扩展的搜索功能。
查询路由(Query Routing):根据查询的内容和意图将查询定向到特定流水线的技术,使 RAG 系统能够有效地处理各种场景。
4>相似性搜索(Similarity search,rank)
用户查询也通过相同的向量化过程转换为向量表示;同时去向量库中检索,这样用户查询就可以在相同的维度空间中进行比较。
计算用户查询嵌入与之前存入的文本块嵌入之间的相似性分数,返回相似度最高的几个信息。
2)生成过程
生成过程将检索到的信息与用户查询结合,形成增强的查询,通过prompt(提示模板)组合后传递给LLM查询、润色,以生成丰富上下文的响应。
5>Reranker 模型(重排序)
Reranker 是信息检索系统中的核心组件,用于对初步筛选的候选结果进行重新排序,以提升最终输出的相关性和用户体验。
a)原理
- 特征融合
结合文本 / 内容特征(如关键词匹配)、用户行为特征(如点击率)、上下文特征(如时间、地理位置)等多维度数据。
利用嵌入向量(如用户和物品的 Embedding)计算语义相似度。 - 排序函数
通过机器学习模型(如逻辑回归、树模型、深度学习)学习样本对(Query - 文档对)的排序规则。
常用损失函数:Pairwise Loss(如 RankNet)、Listwise Loss(如 LambdaMART)。 - 反馈机制
结合离线评估(NDCG、MAP)和在线反馈(A/B 测试)优化模型。
b)场景
| 模型类型 | 代表算法 / 模型 | 特点 |
|---|---|---|
| 传统模型 | LambdaMART、RankNet | 基于梯度提升树或神经网络,依赖人工特征工程。 |
| 深度学习模型 | BERT-Pairwise、ESIM | 利用预训练语言模型捕捉复杂语义关系,支持端到端训练。 |
| 交互式模型 | DSSM、双塔模型 | 通过用户与物品的交互行为学习联合嵌入空间,适用于推荐系统。 |
| 多模态模型 | MM-Ranker(文本 + 图像) | 融合多模态特征(如商品图片与描述),提升跨模态场景排序效果。 |
c)常见模型/算法
- 搜索引擎
对搜索结果进行精排,如 Google 的 RankBrain。 - 推荐系统
电商平台(如亚马逊)的商品推荐、社交媒体的内容流排序。 - 广告系统
优化广告与用户查询的匹配度,提升点击率(CTR)和转化率(CVR)。 - 问答系统
对候选答案进行置信度排序,筛选最优解。
3,RAG流水线组件
- 嵌入模型
嵌入用户查询;
提取用户文档md、word、纯文本,通过数据清晰和降噪,转换文档为要素;
文档分块, - 向量数据库
从向量数据库中检索相关文档信息块; - 提示模板
将检索内容填充到LLM提示中; - LLM
答案生成。